Tenstorrent虫洞分析:挑战英伟达的新玩家?
Posted OneFlow深度学习框架
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tenstorrent虫洞分析:挑战英伟达的新玩家?相关的知识,希望对你有一定的参考价值。

袁进辉——Tenstorrent由于“硅仙人”Jim Keller的加入和其别具一格的架构设计而备受关注。2021年6月,Tenstorrent 的主创Drago Ignjatovic 和Davor Capalija在Linley Group做了题为《Tenstorrent: Scale-Out-First Microarchitecture for Efficient AI Training》的演讲(https://www.youtube.com/watch?v=Id3enIOAY2Q&t=8s),分享了Tenstorrent的技术理念、产品和愿景,分析师Dylan Patel对这场报告做了剖析,我认为这是一份很有价值的内容,故翻译到中文社区希望更多同仁看到。
本文作者在文末声称,Tenstorrent解决了英伟达还没有解决的横向扩展(scale out)问题。我并不同意这个观点。事实上,今天几乎所有的深度学习软件都是围绕英伟达GPGPU生态而开发,在这个生态里,像OneFlow这样的分布式深度学习框架扮演了Tenstorrent厂内自研的用来解决place和route的编译器,分布式深度学习框架加上英伟达的硬件体系(GPGPU, RDMA网络)已经完成了Tenstorrent所描绘的图景,只是软件框架是由外部厂商完成。
Tenstorrent和GPU在软硬件生态上殊途同归。不过,Tenstorrent针对AI的需求放弃了一些通用性,专用性更强,最终实际效果只能拭目以待。
我一直在思考深度学习领域软硬件特定架构的终态。4年前在一篇文章中写过一些设想,可以说Tenstorrent的设计非常符合那时提出的设想。解决问题的思路和底层抽象也非常吻合,某种程度上,Tenstorrent可以理解为用硬件实现了OneFlow里的Actor系统。
作者 | Dylan Patel
编译 | OneFlow社区
(本文已获编译授权,原文:
https://semianalysis.com/tenstorrent-wormhole-analysis-a-scale-out-architecture-for-machine-learning-that-could-put-nvidia-on-their-back-foot/)
作为最重要的人工智能初创公司之一,Tenstorrent受到了媒体的许多关注。许多关注的背后,除了因为大有前景的硬件和软件设计,还有半导体领域传奇人物Jim Keller的加入。从Tenstorrent公司成立之初,Jim就是投资人,那时他还在特斯拉工作。从特斯拉离职后,Jim加入英特尔,最终在2021年初加入Tenstorrent担任首席技术官,并进入公司董事会。
Tenstorrent采用的是一种独特的将硬件和软件紧密结合的方式。硬件专门为任务设计,但软件也不是非常复杂,整个软件栈只有大约50,000行代码。与大多数其它需要定制开发流程的AI专用集成电路(ASIC)不同,Tenstorrent的适应性和灵活性非常强,同时支持所有主流工具链、框架和运行时。因此,英伟达的最大优势———极易开发,正在受到挑战。
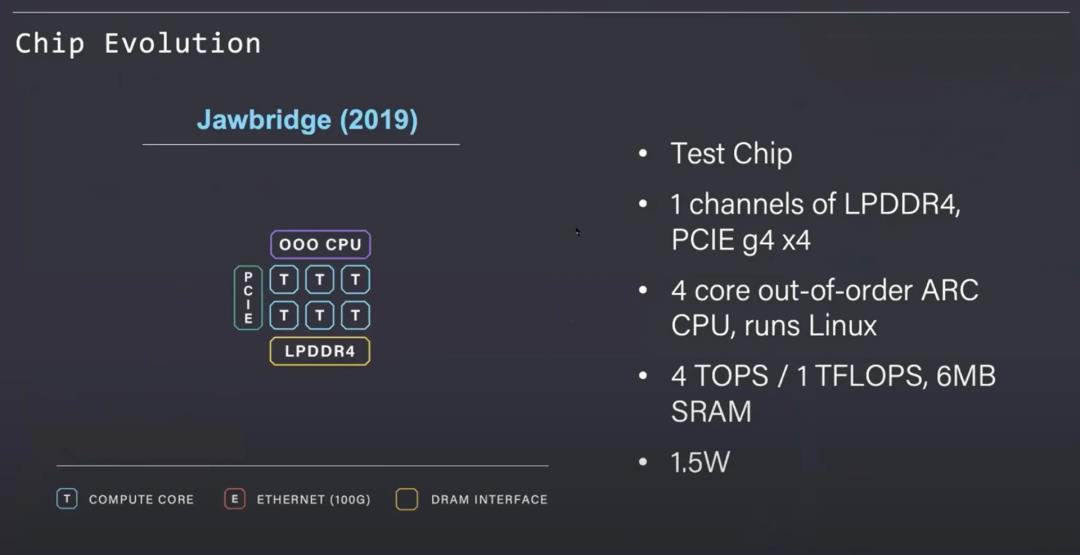
为了了解他们的架构和虫洞处理器(Wormhole processor),我们先来了解一下该公司之前的产品。Jawbridge是一款小型测试芯片,作为架构的概念验证而开发。其中有一系列Tenstorrent设计的Tensix处理核,通过厂内自研片上网络(NOC)连接。这与许可的I/O块(如LPDDR内存控制器和PCIe root)相结合。片上CPU内核可以管理工作负载并运行Linux。
Jawbridge芯片非常小,功耗要求非常低。在当时有限预算的情况下,Tenstorrent制作了这款芯片,验证了他们声称的能耗和性能。基于这一概念验证的支持,Tenstorrent能够筹集更多资金来扩展到下一代产品。

GraySkull是下一代演进的商业产品。该芯片有128个Tensix核,非常重要的NOC可大幅扩展,IO也更大。该芯片基于格芯(GlobalFoundries)的12nm工艺,尺寸为620mm^2。Tenstorrent还准备将A0硅推向市场,这也是他们设计能力的一个强有力证明。这意味着,他们设计芯片的路子是正确的,并且在第一次流片中没有发现错误。即使对于AMD、苹果、英特尔、英伟达等经验丰富的团队来说,这一成就也是非常罕见、值得庆祝的事。
GraySkull是一款65W芯片,但PCIe扩展卡是75W。这意味着,它无需任何额外的辅助电源,就可以轻松地插入现有服务器。在完成流片和取样后,Tenstorrent能够筹集到更多资金来制作下一代芯片。

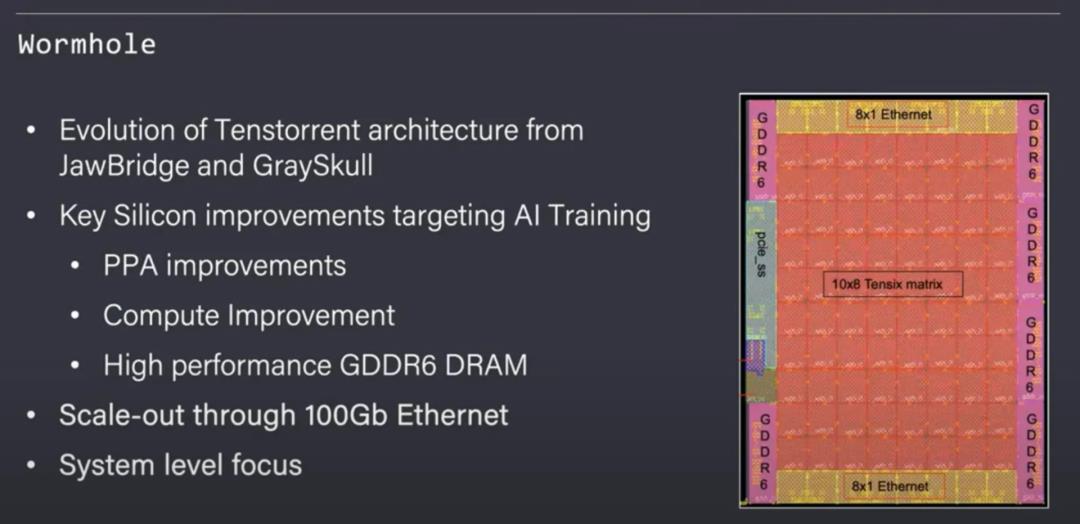
接下来就是虫洞,它是一个670mm^2的晶粒,也是基于格芯的12nm工艺。尽管同一节点的硅面积和利用率略有增加,但Tenstorrent能够显著地扩展性能、IO和可扩展性。除了性能更高、耗电量更大之外,与以前设计的最大不同之处在于,虫洞增加了16个带有100Gb以太网的端口。以太网端口使得许多芯片连接在一起,以扩展到大型AI网络。

除了通过以太网进行扩展,每个Tensix核都得到了大幅升级。每核都拥有更多SRAM,可以执行更复杂的数学和SIMD指令。虫洞有一个192位GDDR6内存总线,能够提供384GB/s的内存带宽。尽管矩阵运算的性能提高了两倍,内存带宽提高了近3倍,并且虫洞有1.6TB的网络交换容量,但虫洞芯片的功率仅增加了一倍,即150W。
Tenstorrent在同样的12nm工艺技术上实现了这些目标,晶粒面积增加了不到10%。他们巧妙地将片上网络(NOC)设计为通过以太网端口进行扩展,不需要为芯片间通信专门开发软件就可以扩展AI训练。

AI训练工作负载的的复杂性在不断飙升。OpenAI声称,训练最强大网络所需的计算量每3个半月就能翻一番。Facebook最近宣布,他们最新的深度学习推荐系统有12万亿个参数,这远超OpenAI预测的趋势。训练这些网络不仅需要服务器,还需要整个AI专用服务器机架。轻松扩展到大规模网络的能力是Tenstorrent虫洞的一个关键优势。
虫洞芯片将提供两种版本。一种是可以轻松插入服务器的PCIe插卡。如果客户在AI训练方面有诸多问题,将会希望购买这一版本的产品,这发挥了该芯片可以承受已知的以太网网络功能的能力。
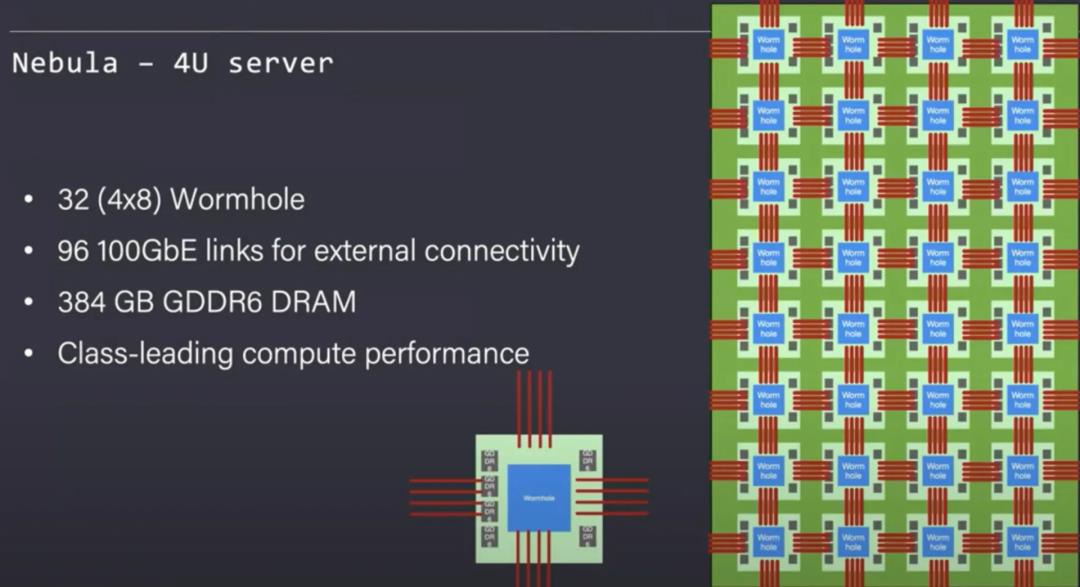
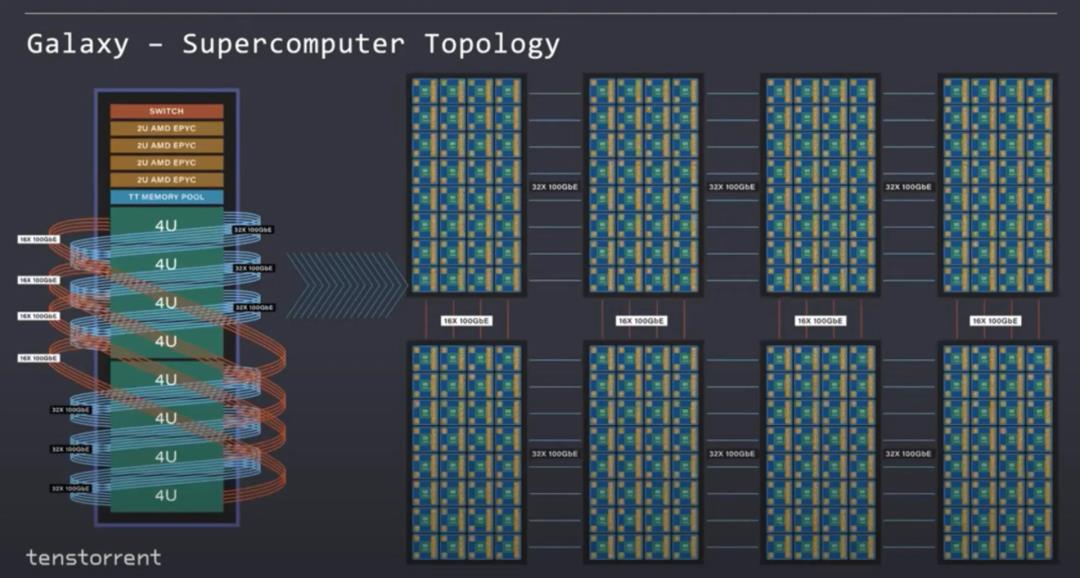
Tenstorrent设计了Nebula作为基础构件,它是一个4U服务器机箱,可以装入32个虫洞芯片,这些芯片内部连接成一个完整的网格,能够以透明的方式轻松地将这个网格扩展到远远超出单个服务器的范围。

乐趣不止于此。Tenstorrent还展示了Galaxy,这是在一个扩展的网格中连接的8个Nebulas。该机架还包含4台AMD Epyc服务器和一个共享内存池。机架提供大于3TBs的GDDR6和256Gb的外部以太网链路。通用的AMD Epyc服务器和内存池连接到以太网。
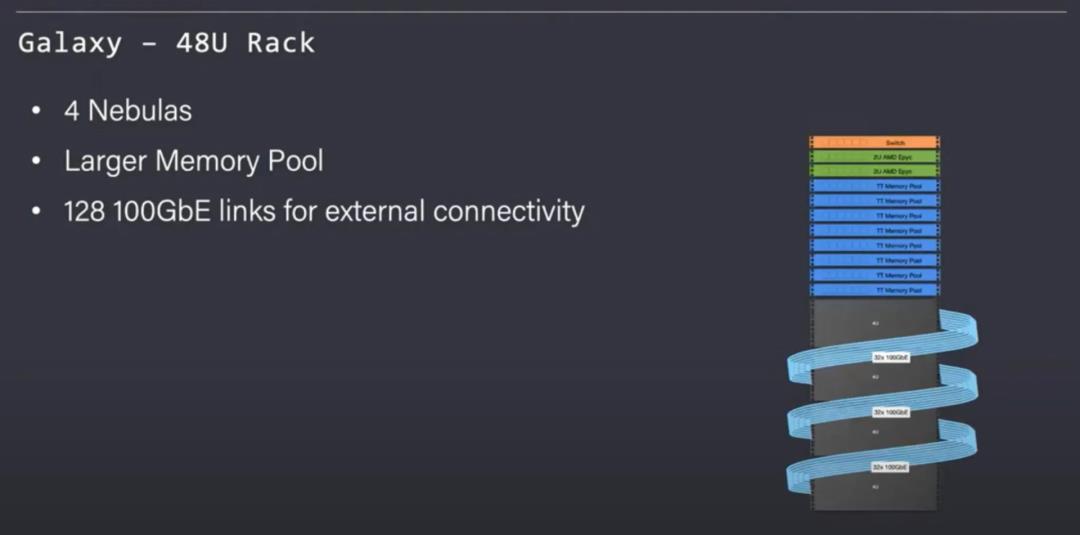
Tenstorrent认识到不是所有AI的工作负载都是同质的。他们提供了一个机架级别的服务器产品,其计算能力只有虫洞的一半。
AMD Epyc服务器的数量也减少了一半。这种对计算的权衡是为了换取更大的内存池,每个机架都有8倍的内存,这种类型的配置更适合内存密集度更高的模型,例如深度学习推荐系统。
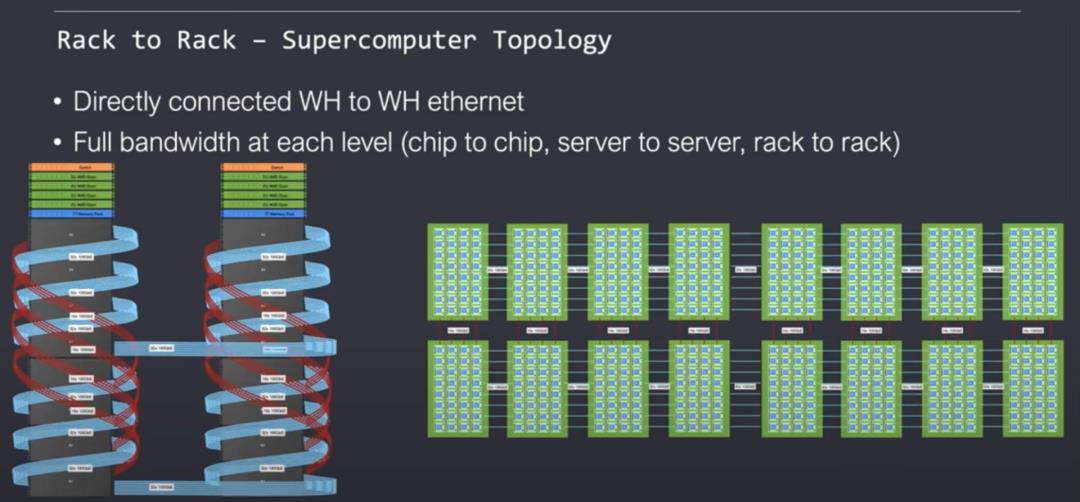
横向扩展能力还并不止于此。Tenstorrent支持机架组件连接在一个二维网格,关键是用软件来处理横向扩展的问题。对于软件来说,这个网络看起来像是一个由Tensix核组成的大型同质网络。片上网络可以透明地扩展到许多机架的服务器,而不需要再对软件进行重写。
从理论上讲,这个网络可以扩展到无限大,同时带宽保持一致。这种拓扑结构不需要使用许多昂贵的以太网交换机,因为虫洞上的片上网络本身就是一个交换机。
每个服务器顶部的交换机只用于将这些服务器连接到外部世界,而不是在网络内部。英伟达的解决方案需要转换到8 GPU以上的规模,代价巨大,超过16 GPU的规模需要使用更昂贵的英伟达网卡和交换机。
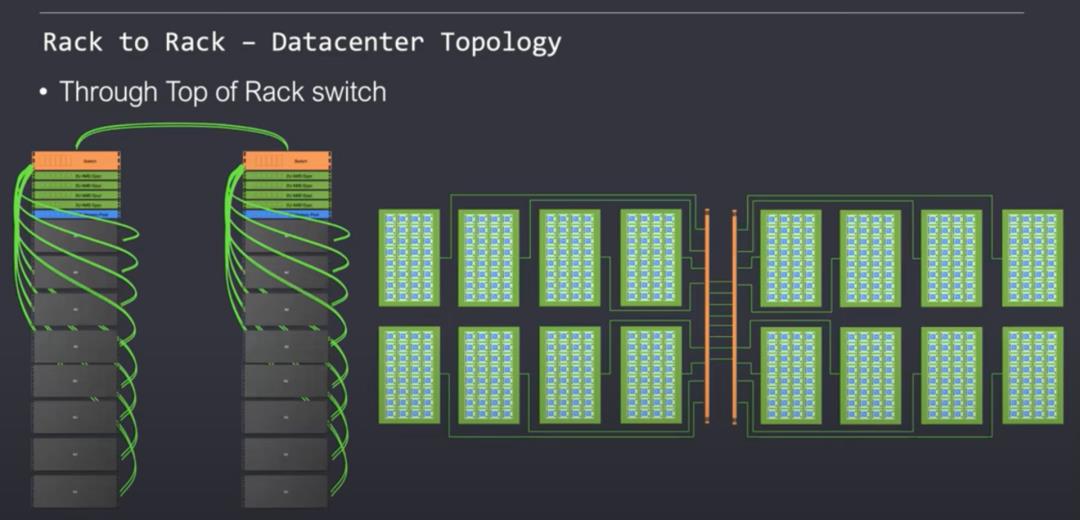
Tenstorrent支持多种拓扑,每一种都各有优缺点。许多数据中心都完全支持经典的叶脊模型。尽管网络性能不同,片上NOC仍然可以很干净地扩展而不会停滞。Tenstorrent完全支持灵活性和多租户体系结构。

虫洞没有严格的层次结构,因而也比较灵活。在带宽、延迟和编程层次方面,横向扩展服务器倾向于有一个芯片内、芯片间、服务器间和机架间通信的层次结构。Tenstorrent声称已经发现了一个秘密武器,可以让这些不同级别的延迟和带宽不影响软件。尽管虫洞很灵活,芯片利用率仍然很高。但对于他们是如何干净利落地做到这一点的,当然可以持怀疑态度。
编译器和模型设计者花了很多时间试图解决横向扩展的问题,而Tenstorrent却声称他们有解决这一问题的灵丹妙药。编译器和研究人员看到的是“无限的处理核流(infinite stream of cores)”。他们不需要把模型交给网络。正因如此,机器学习研究人员不再受束缚,如果需要的话,他们可以将模型扩大到数万亿个参数。由于这种灵活性,可以很容易在以后增加网络规模。
横向扩展问题很难,对于定制AI芯片而言尤其如此。即使是在横向扩展硬件领域领先的英伟达,也在迫使大量的模型开发者应对这些严格的带宽、延迟和编程层次。如果Tenstorrent要自动化这个任务、解决这一问题的说法是真的,那么他们已经颠覆了这个行业。

为了理解他们是如何做到这一点的,我们需要回顾一下过去的横向扩展训练。从历史上看,为了在CPU集群之间纵向扩展,可以使用一个大的batch size并在集群之间进行分割。这会产生一个聚合批次的中心参数服务器。由于带宽限制,这并没有很好地纵向扩展。
接下来,带有Allreduce和更高性能带宽的GPU集群提高了扩展性。这仍然有局限性,除了增加batch size和在集群中划分(Sharding)数据之外,还有一些早期尝试将其他类型的并行性结合起来。

最大的局限性是batch size不能过大。如果你继续增加batch size,模型无法将收敛并实现高精度。对于较大模型,DRAM容量成为一个约束,因为整个模型要在所有节点上进行复制。中间计算甚至不再适合在片上SRAM中进行,这需要大量的DRAM带宽来存储这些中间体。DRAM的大小和带宽增加的影响是每个节点的成本大幅上升。这种扩展方法对于小型模型很有效,但对于大型模型,很快就不再具有成本效益。

随着更大的模型开始发挥作用,用于有效扩展的库开始出现。用户现在可以跨服务器集群地指定和组合模型、流水,以及基于参数划分的数据并行。
本质上,用户会跨节点拆分网络的模型和层。这允许模型继续扩展,因为它们不需要在每个节点内复制整个模型。这种扩展模式的最大问题是必须手动完成。研究人员必须选择将相应的层映射到相应硬件并控制数据流。
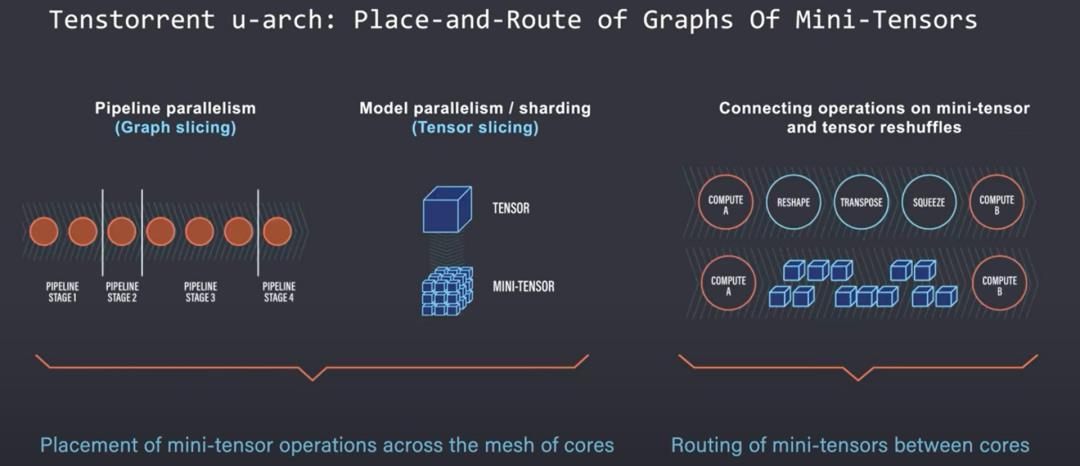
在扩展模型时,需要在各个节点和硬件单元上对模型层进行切片和映射。除了流水并行性,单个张量操作也可能变得太大,以至于单个张量核心硬件单元无法单独执行。这些在一个节点上的张量操作也需要由研究人员手动切分成微张量。
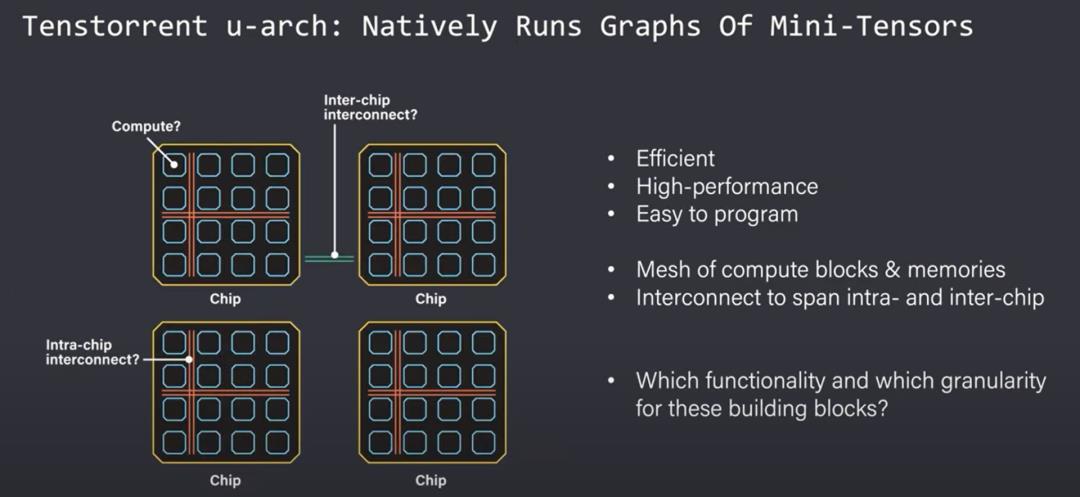
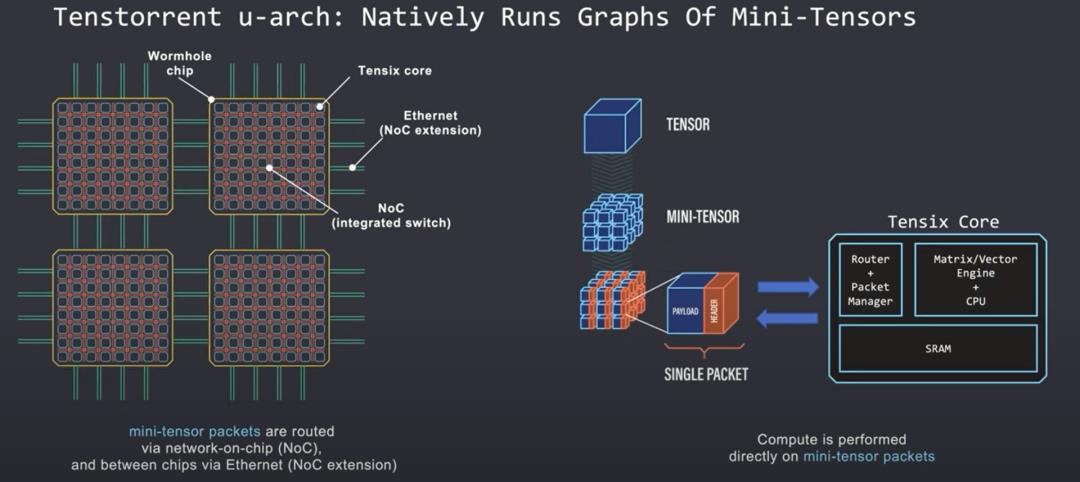
Tenstorrent 的目标是创建一个可以摆放(place)、路由和执行迷你张量操作图的架构。迷你张量被理解为 Tenstorrent 架构原生支持的数据类型。
这意味着研究人员不必为张量切片而烦恼。每个微张量被当作一个单独的数据包处理,这些数据包有一个数据有效负载和一个包头(header),用于在核心网格内识别和路由数据包。
Tensix 内核直接在这些迷你张量数据包上完成计算,每个内核都包括一个路由器、数据包管理器以及大量的 SRAM。路由器和数据包管理器同步处理,并将计算包发送到通过以太网在片上或片外的网格互联线上。

从软件的角度来看,数据包的传输在整个内核网格中看起来是一致的。在同一芯片和不同芯片上的内核之间发送数据包看似相同,因为每个芯片和 NOC 本身就像一个交换机,迷你张量数据包可以沿着内核网格路由到它下一个需要去的内核。

迷你张量数据包有5个关键基元,用于在核心之间进行移动数据包的推进/弹出(push/pop)。复制、收集、分散和随机洗牌也可用于单播(Unicast)或多播(Multicast),取决于图中的消费者或生产者关系。
可以手动将原语(Primitives)组合在一起,以构建原生的迷你张量图。对于大多数人来说,更简单的方法是使用可以接收 PyTorch 输出的编译器。编译器会将输出降低到由这些原语组成的图形中,然后可以在硬件上零开销地运行。
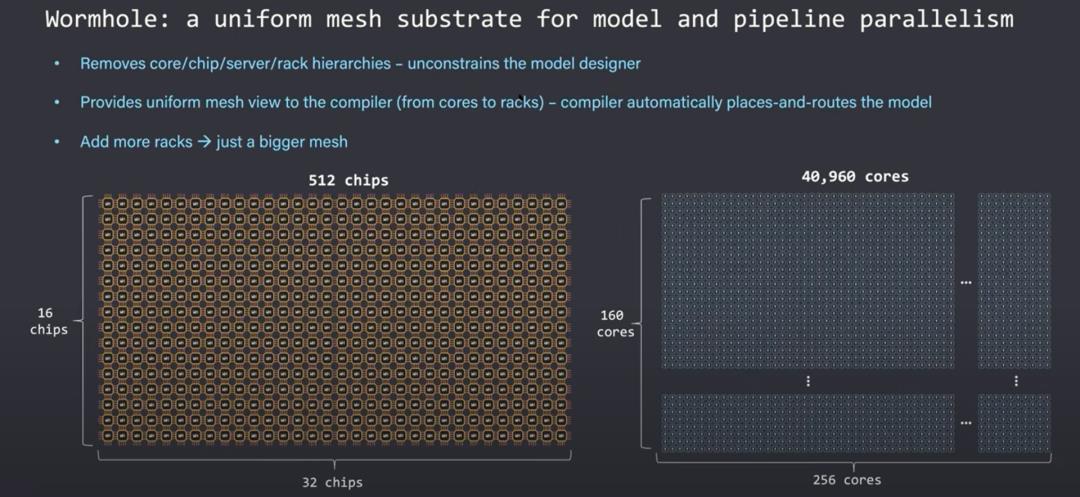

尽管包含许多芯片、服务器和虫洞芯片机架,但软件本身好像只看到由计算核心构成的网格。
严格的层次结构被移除,解除了模型开发人员的约束。编译器会根据网络拓扑自动地在网络中有效放置和路由迷你张量,而不会让模型开发人员烦恼。增加更多服务器可以扩展网格并允许模型毫无顾虑地向外扩展。
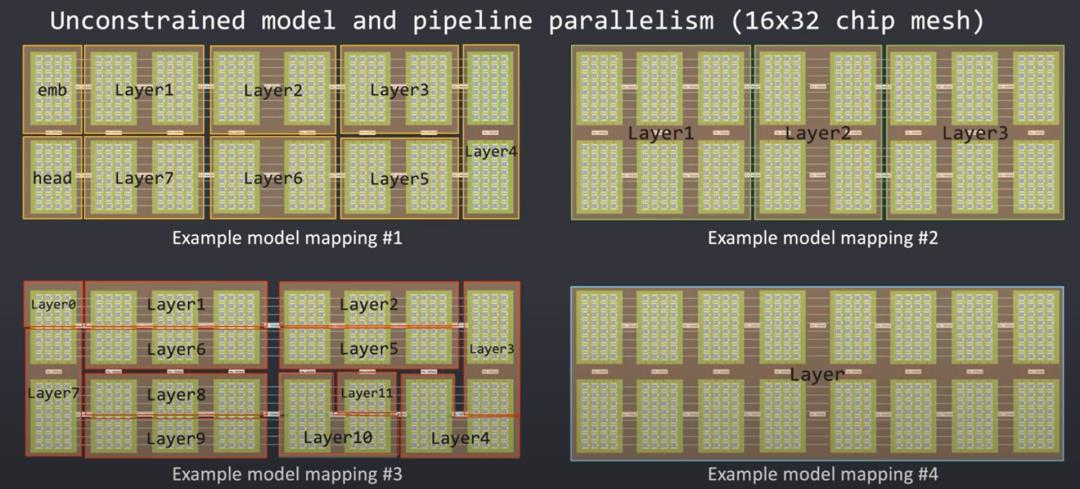
这些边界(Boundaries)允许大量模型流水并行。网络中的层可以使用任意数量的资源来匹配计算需求。不需要大量计算的层可以使用一半服务器或一半芯片,但是另一个需要大量计算的层可以跨机架延伸实用。
第4个示例表明,如果网格足够大,甚至可以跨服务器机架延伸单个层。编译器会看到网格的大小,并根据它们的大小映射到层,无论内核网格有1个芯片还是跨多服务器机架的10000个芯片。
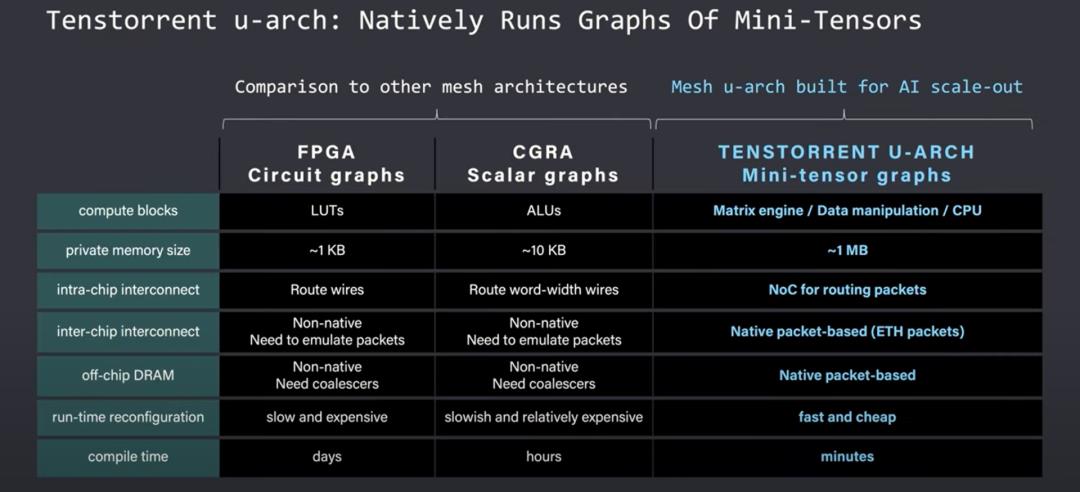
与其他网格架构相比,Tenstorrent 网格更大且更具可扩展性。FPGA网格处于非常精细化的水平,需要大量时间来手动调整。CGRA网格能运行标量图,但它们仍然有许多限制因素。Tenstorrent 在其矩阵引擎中有多个浮点运算和更大的内存。
NOC、数据包管理器和路由器智能地处理芯片内和芯片间的通信,让模型开发人员专注于这个拼图(puzzle)的其他部分。这使得它可以更有效地扩展AI工作负载,同时也更容易开发。

如果他们的主张得到证实,Tenstorrent 已经取得了真正神奇的成就。他们强大的虫洞芯片可以通过集成以太网端口扩展到许多芯片、服务器和机架,而无需任何软件开销。编译器会看到一个无限的内核网格,没有任何严格的层次结构。这使得模型开发人员在大规模机器学习模型的扩展训练中不用担心图切片或张量切片。
作为人工智能硬件和软件领域的领导者,英伟达还没有接近解决这个问题。他们提供库、SDK和优化帮助,但他们的编译器无法自动执行此操作。我们怀疑 Tenstorrent 编译器能否完美地在AI网络中的层放置和路由到核心网格,同时避免网络拥塞或瓶颈。这些类型的瓶颈在网状网络中很常见。
如果他们真的在没有软件开销的情况下解决了扩展AI问题,那么所有AI训练硬件都将面临严峻挑战。由于易用性的大幅提升,每一个研究大模型的研究人员都会迅速涌向 Tenstorrent Wormhole 和未来的硬件。
其他人都在看
欢迎下载体验OneFlow新一代开源深度学习框架:GitHub - Oneflow-Inc/oneflow: OneFlow is a performance-centered and open-source deep learning framework. https://github.com/Oneflow-Inc/oneflow/
https://github.com/Oneflow-Inc/oneflow/

以上是关于Tenstorrent虫洞分析:挑战英伟达的新玩家?的主要内容,如果未能解决你的问题,请参考以下文章