MySQL还能这样玩---第四篇之分区原理
Posted 大忽悠爱忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL还能这样玩---第四篇之分区原理相关的知识,希望对你有一定的参考价值。
分区原理
本节为分区高级篇,主要针对分区底层原理进行介绍,建议不了解分区概念的先看下面的分区入门篇:
本节内容主要参考: innodb技术内幕,高性能mysql,深入浅出mysql,和其他一些官方和网上资料
InnoDB逻辑存储结构
个人认为如果想要理解分区的原理,还是需要先大体理解一下InnoDB存储引擎的结构,才能更好的理解我下面要讲的分区原理;
首先要先介绍一下InnoDB逻辑存储结构和区的概念,它的所有数据都被逻辑地存放在表空间,表空间又由段,区,页组成。
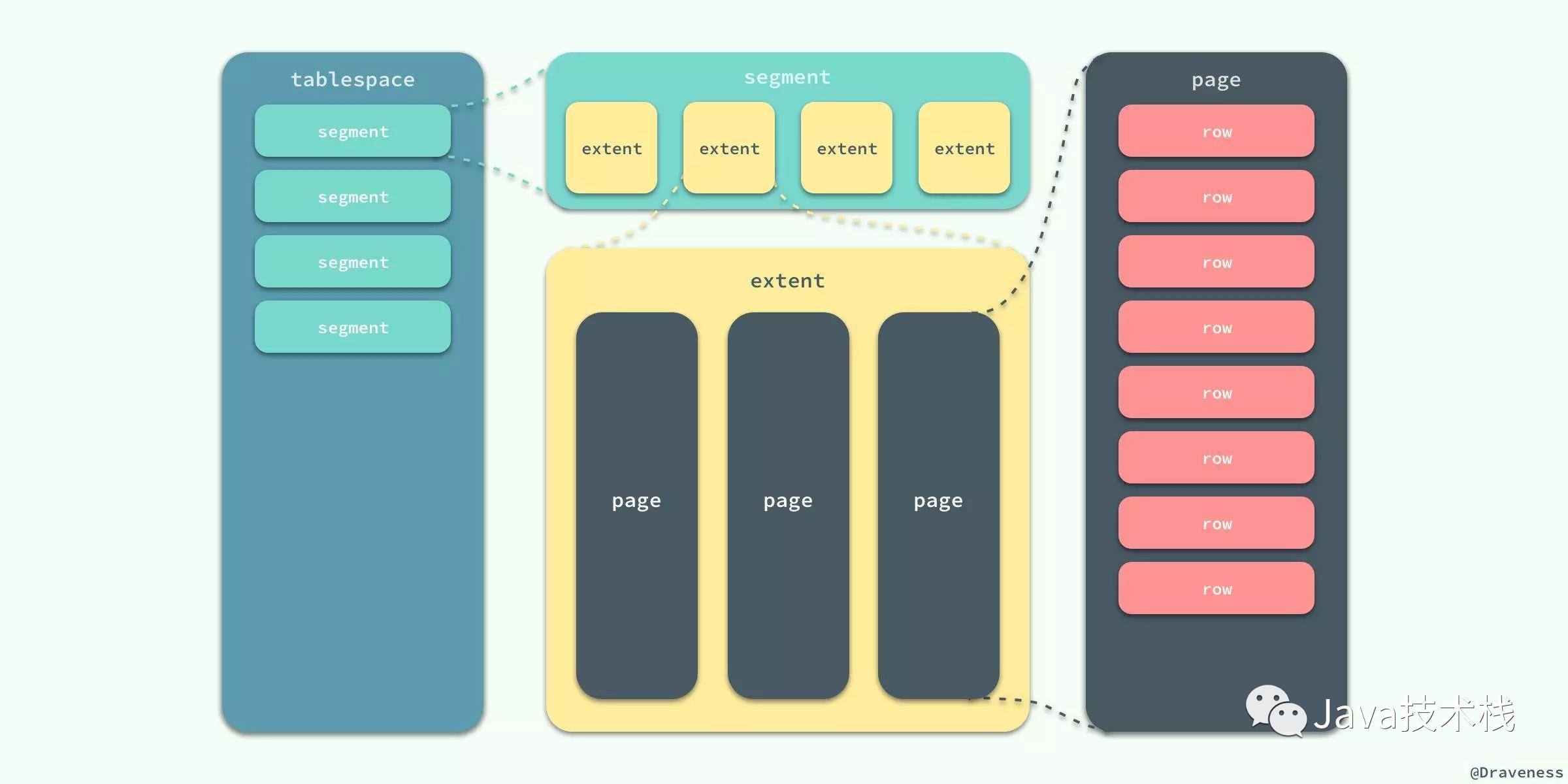
段
- 段就是上图的
segment区域,常见的段有数据段、索引段、回滚段等,在InnoDB存储引擎中,对段的管理都是由引擎自身所完成的。
区
- 区就是上图的
extent区域,区是由连续的页组成的空间,无论页的大小怎么变,区的大小默认总是为1MB。 - 为了保证区中的页的连续性,
InnoDB存储引擎一次从磁盘申请4-5个区,InnoDB页的大小默认为16kb,即一个区一共有64(1MB/16kb=16)个连续的页。 - 每个段开始,先用32页(
page)大小的碎片页来存放数据,在使用完这些页之后才是64个连续页的申请。这样做的目的是,对于一些小表或者是undo类的段,可以开始申请较小的空间,节约磁盘开销。
页
- 页就是上图的
page区域,也可以叫块。页是InnoDB磁盘管理的最小单位。默认大小为16KB,可以通过参数innodb_page_size来设置。 - 常见的页类型有:数据页,undo页,系统页,事务数据页,插入缓冲位图页,插入缓冲空闲列表页,未压缩的二进制大对象页,压缩的二进制大对象页等。
分区原理图
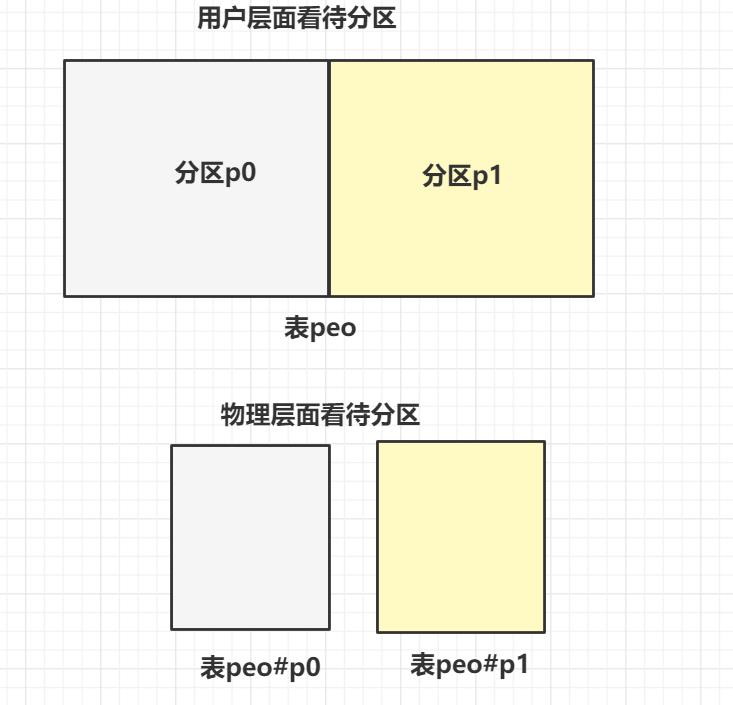
分区是指将同一表中不同行的记录分配到不同的物理文件中,几个分区就有几个.idb文件.
mysql数据库的分区是局部分区索引,一个分区中既存了数据,又放了索引。也就是说,每个区的聚集索引和非聚集索引都放在各自区的(不同的物理文件)。目前MySQL数据库还不支持全局分区。


分区使用场景
分区的主要目的是将数据按照一个比较粗的粒度分布在不同的表中,这样可以将相关数据存放在一起,另外,如果想一次批量删除整个分区的数据,也会变得非常方便。
常见的分区使用场景如下:

分区限制

分区表的原理
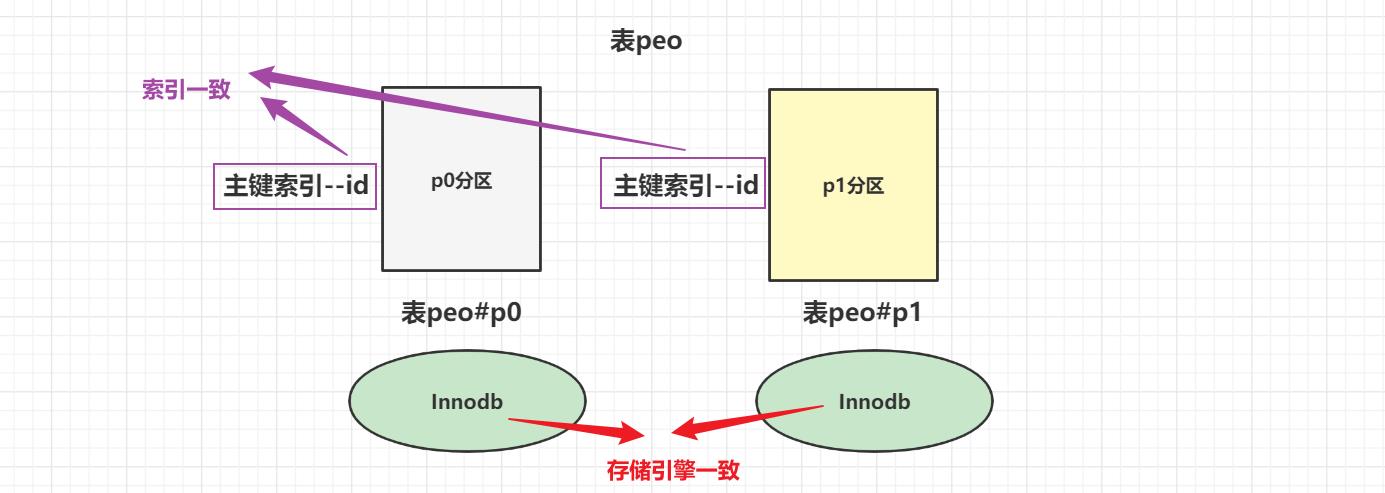

分区表上的操作按照下面的操作逻辑进行:


每个操作前,都需要锁住所有分区,直到找到当前操作是对哪个分区进行操作时,才会解锁

如何使用分区表


上面这段总结一下: 在数据量很大的情况下,索引的优势就显得很小了。我们可以通过分区并且每个分区上建立索引的方式来加速大数据量的查询。
保证大数据量可扩展性,通常有以下两个选择

分区陷阱
分区高效的前提是查询都能够过滤掉很多额外的分区,分区本身并不会带来很多额外的代价。
NULL值陷阱

不同分区对于NULL值的处理有所不同,range分区会把null值当做最小值放入第一个分区中,这点与上面所讲的情况相同,需要注意
其他陷阱


分区表的一些其他限制:

查询优化
分区的最大优点就是k优化器可以根据分区函数来过滤掉一些分区。但是过滤分区很重要的一点在于WHERE条件中带入分区列,有时候看似多余也需要带上,这样就可以让优化器能够过滤掉无需访问的分区,如果没有这些条件,MySQL就需要让对于存储引擎访问这个表的所有分区。
使用EXPLAIN PARTITION可以观察优化器是否执行了分区过滤



以上是关于MySQL还能这样玩---第四篇之分区原理的主要内容,如果未能解决你的问题,请参考以下文章