从零开始手写Tomcat的教程4节---Tomcat默认连接器
Posted 大忽悠爱忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从零开始手写Tomcat的教程4节---Tomcat默认连接器相关的知识,希望对你有一定的参考价值。
从零开始手写Tomcat的教程4节---Tomcat默认连接器
- Tomcat默认连接器
- Connector接口
- HttpConnector类
- HttpProcessor类
- Request对象
- Response对象
- 处理请求
- BootStrap类
- SimpleContainer类
- 解析连接
- 解析请求
- 解析头部
- 总结
Tomcat默认连接器
本节我们来分析一下tomcat 4中默认连接器的源码
注意: 本节所讲的连接器是指Tomcat 4中的默认连接器,虽然该连接器已经弃用,被另一个运行速度更快的连接器—Coyote—取代,但它仍然是一个不错的学习工具
一个 Tomcat 连接器必须符合以下条件:
- 必须实现接口 org.apache.catalina.Connector。
- 必须创建请求对象,该请求对象的类必须实现接口 org.apache.catalina.Request。
- 必须创建响应对象,该响应对象的类必须实现接口 org.apache.catalina.Response。
Tomcat4 的默认连接器类似于上节的简单连接器。它等待前来的 HTTP 请求,创建 request和 response 对象,然后把 request 和 response 对象传递给容器(上节只是交给响应的处理器Processor处理)。
连接器是通过调用接口org.apache.catalina.Container 的 invoke 方法来传递 request 和 response 对象的。
Tomcat 4的默认连接器使用了很多技巧进行优化,例如: 使用了一个对象池来避免频繁创建对象带来的性能损耗,其次,在很多地方,Tomcat 4的默认连接器使用了字符数组来代替字符串。
Tomcat 4的默认连接器实现了HTPP 1.1 新特性,因此我们从Http 1.1新特性讲起,这是理解后文默认连接器为何要如此写的重点:
Http 1.1 新特性
持久连接

说白了就是复用连接,能少创建连接就少创建一点
块编码
Content-Length 字段
一个TCP连接现在可以传送多个回应,势必就要有一种机制,区分数据包是属于哪一个回应的。这就是Content-length字段的作用,声明本次回应的数据长度。
Content-Length: 3495
上面代码告诉浏览器,本次回应的长度是3495个字节,后面的字节就属于下一个回应了。
在1.0版中,Content-Length字段不是必需的,因为浏览器发现服务器关闭了TCP连接,就表明收到的数据包已经全了。
使用Content-Length字段的前提条件是,服务器发送回应之前,必须知道回应的数据长度。
对于一些很耗时的动态操作来说,这意味着,服务器要等到所有操作完成,才能发送数据,显然这样的效率不高。更好的处理方法是,产生一块数据,就发送一块,采用"流模式"(stream)取代"缓存模式"(buffer)。
因此,1.1版规定可以不使用Content-Length字段,而使用"分块传输编码"(chunked transfer encoding)。只要请求或回应的头信息有Transfer-Encoding字段,就表明回应将由数量未定的数据块组成。
Transfer-Encoding: chunked
每个非空的数据块之前,会有一个16进制的数值,表示这个块的长度。最后是一个大小为0的块,就表示本次回应的数据发送完了。下面是一个例子。
HTTP/1.1 200 OK
Content-Type: text/plain
Transfer-Encoding: chunked
25
This is the data in the first chunk
1C
and this is the second one
3
con
8
sequence
0
状态码100的使用

Connector接口

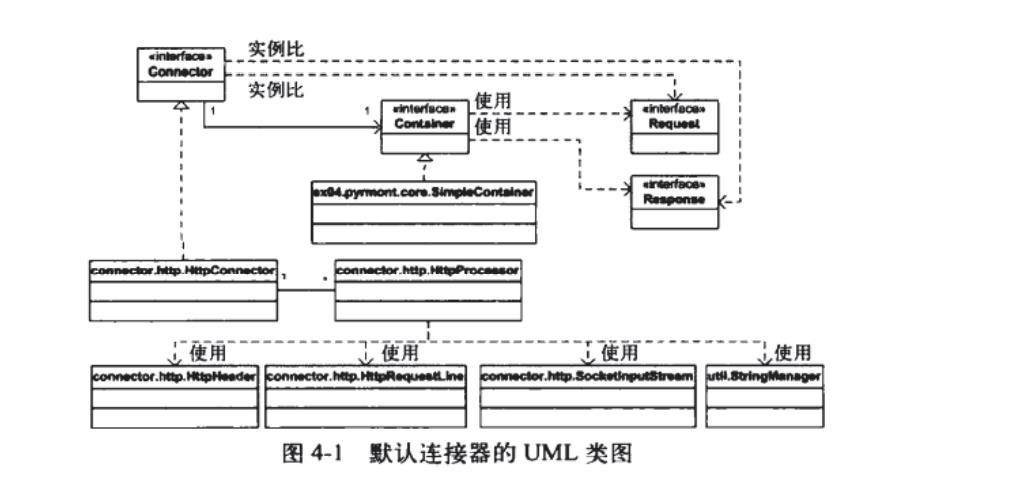
功能组件大白话图解:
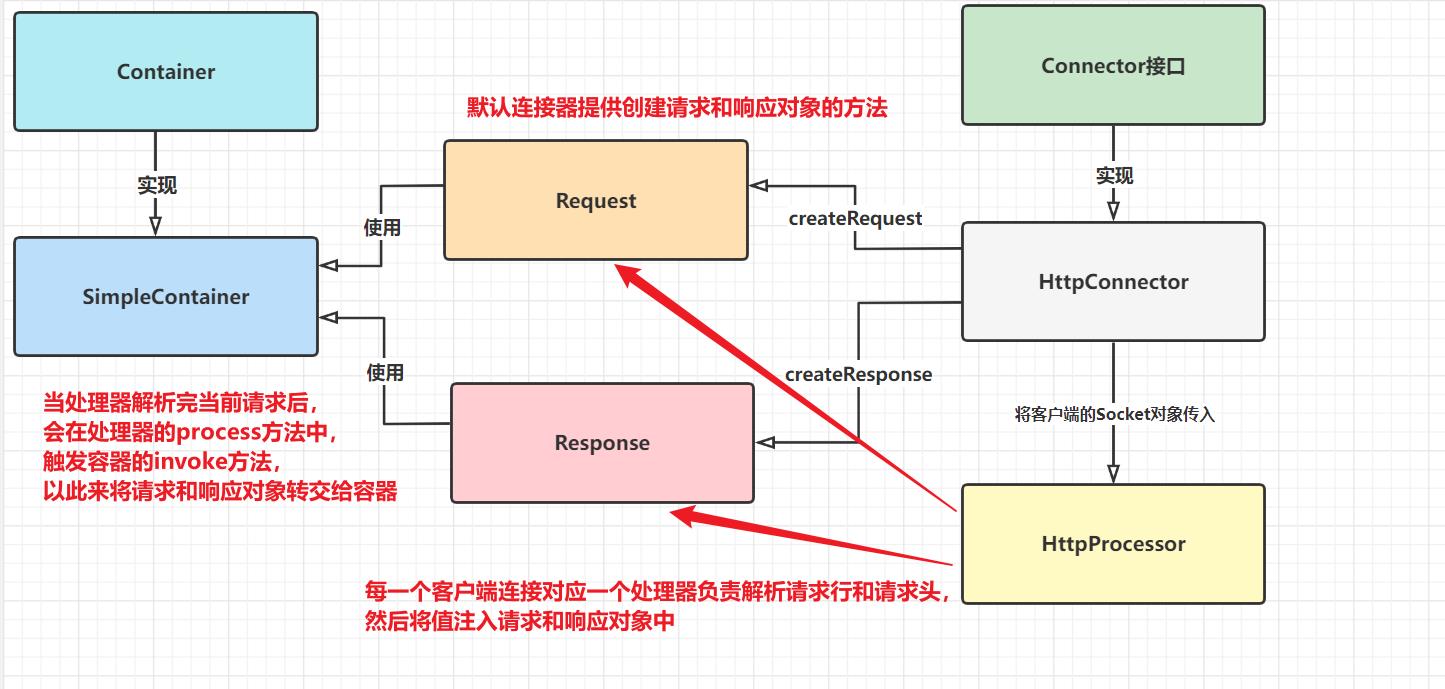
这张图现在可能看上去比较懵逼,后面等我讲完本节,大家再回头看一下,会发现豁然开朗
HttpConnector类

创建服务器套接字

其实就是绑定端口号,设置连接队列大小,然后创建ServerSocket对象
维护HttpProcessor实例



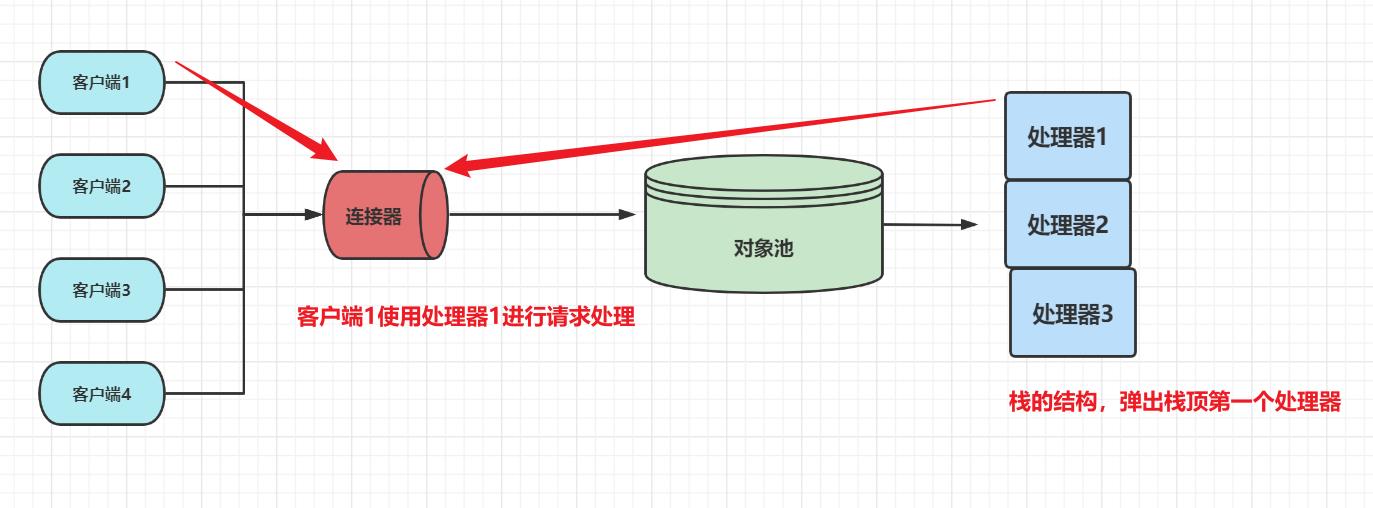
提供Http请求服务


HttpConnector拿到客户端连接后,会去栈里面看看还存不存在可用处理器

提前剧透:每一个HttpProcessor都在各自的线程中运行
public void run()
while (!stopped)
Socket socket = null;
try
socket = serverSocket.accept();//等待用户请求,阻塞
catch (AccessControlException ace)
continue;
catch (IOException e)
//省略
continue;
HttpProcessor processor = createProcessor(); //从池中获取处理器实例
if (processor == null)
try
socket.close();
catch (IOException e)
;
continue;
processor.assign(socket); //将请求的socket交给得到的处理器实例中
HttpProcessor类



看一下recycle方法:

注意:连接器拥有处理器池的所有权,而不是处理器自己拥有,因此上面调用的是connector.recycle(this)
public void run()
while (!stopped)
Socket socket = await(); //阻塞,直到用户请求到来获取到这个处理器才被唤醒
if (socket == null)
continue;
try
process(socket); //处理用户请求
catch (Throwable t)
log("process.invoke", t);
connector.recycle(this); //连接器回收处理器
重点


这个实现有很意思,也非常值得我们学习,下面来看一下的源码:
synchronized void assign(Socket socket)
while (available) //avaiable默认是false,,第一次执行时跳过while
try
wait();
catch (InterruptedException e)
this.socket = socket; //将从池中获取到的HttpProcessor实例中的socket变量赋值
available = true;
notifyAll();//唤醒线程。
private synchronized Socket await()
while (!available) //默认是false,所以进入循环阻塞,因为处理器实例没有socket信息,
try
wait();
catch (InterruptedException e)
Socket socket = this.socket; //得到了socket
available = false; //重新进入阻塞
notifyAll();
if ((debug >= 1) && (socket != null))
log(" The incoming request has been awaited");
return (socket);
用户请求到来,得到了用户的 socket,调用 assign 方法,因为 avaiable 默认是 false,所以跳过 while 需要,将 socket 放入获取到的处理器实例中,同时将 avaiable 设为 true,唤醒线程,此时 await 方法中的 wait 方法被唤醒了,同时因为 avaliable 为 true,跳出循环,将 avaiable 设为 false 重新进入阻塞,得到用户的返回用户的 socket,最后就能够通过 process 处理请求了。
疑问:
为什么 await 需要使用一个本地变量(socket)而不是返回实例的 socket 变量呢?
- 因为这样一来,在当前 socket 被完全处理之前,实例的 socket 变量可以赋给下一个前来的 socket。
为什么 await 方法需要调用 notifyAll 呢?
- 这是为了防止在 available 为 true 的时候另一个 socket 到来。在这种情况下,连接器线程将会在 assign
方法的 while 循环中停止,直到接收到处理器线程的 notifyAll 调用。
Request对象
默认连接器里 HTTP 请求对象实现org.apache.catalina.Request 接口。这个接口被类RequestBase 直接实现了,也是 HttpRequest 的父接口。最终的实现是继承于 HttpRequest 的HttpRequestImpl。像第 3 节的一样,有几个 facade 类:RequestFacade 和 HttpRequestFacade。需要注意的是,这里除了属于 javax.servlet和 javax.servlet.http 包的类,前缀 org.apache.catalina 已经被省略了。对HTTP响应对象也是类似的。
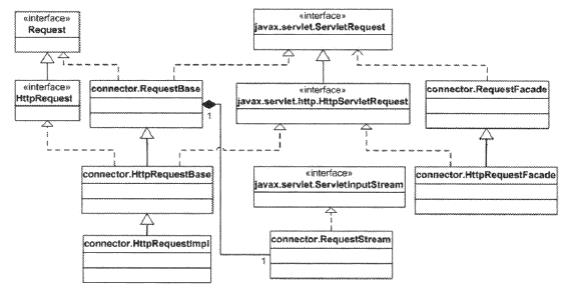
看了上面的类继承图,我们应该要学习一下Tocmat的继承体系的设计思想,例如:RequestBase类承担着两个接口公共属性的基础类, HttpRequestBase类也是,承担着RequestBase和HttpRequest类的公共属性
还有就是之前提过的外观对象的引入,对客户端隐藏了部分特殊方法,防止客户端强制转换进行调用
Response对象
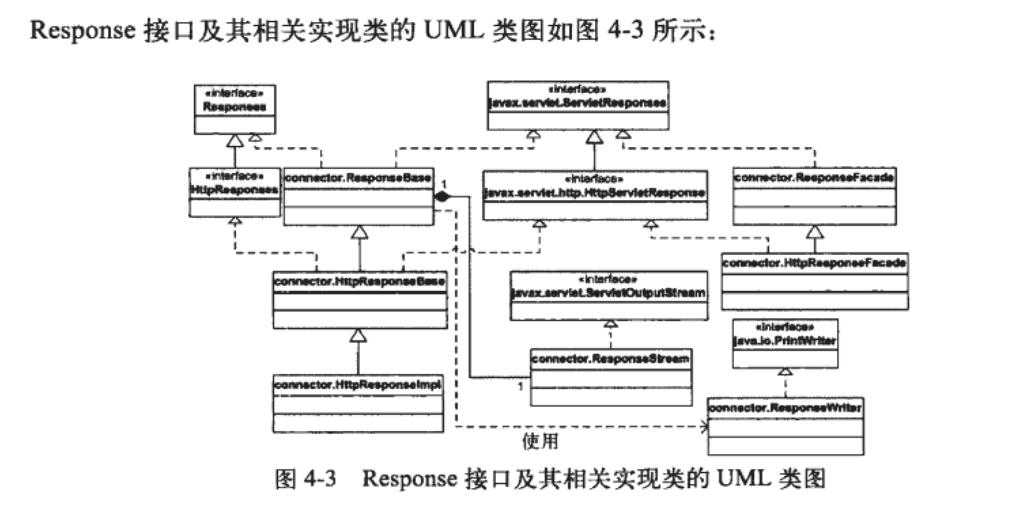
处理请求
和第3节的一样,有一个 SocketInputStream 实例用来包装套接字的输入流。注意的是,SocketInputStream 的 构 造 方 法 同 样 传 递 了 从 连 接 器 获 得 的 缓 冲 区 大 小 , 而 不 是 从HttpProcessor 的本地变量获得(第3节中是指定的2048)。这是因为对于默认连接器的用户而言,HttpProcessor 是不可访问的。通过传递 Connector 接口的缓冲区大小,这就使得使用连接器的任何人都可以设置缓冲大小。
SocketInputStream input = null;
OutputStream output = null;
// Construct and initialize the objects we will need
try
input = new SocketInputStream(socket.getInputStream(),
connector.getBufferSize());
catch (Exception e)
log("process.create", e);
ok = false;
process 方法使用布尔变量 ok 来指代在处理过程中是否发现错误,从代码中可以看到一旦catch到错误,就会设为false 并使用布尔变量finishResponse 来指代 Response 接口中的 finishResponse 方法是否应该被调用。
boolean ok = true;
boolean finishResponse = true;
另外, process 方法也使用了布尔变量 keepAlive,stopped 和 http11。 keepAlive 表示连接 是否是持久的, stopped 表示 HttpProcessor 实例是否已经被连接器终止来确认 process 是否也应该停止,http11 表示 从 web 客户端过来的 HTTP 请求是否支持 HTTP 1.1。
然后,有个 while 循环用来保持从输入流中读取,直到 HttpProcessor 被停止,一个异常被抛出或者连接给关闭为止。
while (!stopped && ok && keepAlive)
//....
在 while 循环的内部,process 方法首先把 finishResponse 设置为 true,并获得输出流,并对请求和响应对象做些初始化处理。
如果初始化过程都catch到错误,解析连接和头部就不用做了,所以抛错时ok会设为false
//初始化请求和响应对象
request.setStream(input);
request.setResponse(response);
output = socket.getOutputStream();
response.setStream(output);
response.setRequest(request);
((HttpServletResponse) response.getResponse()).setHeader
("Server", SERVER_INFO);
接着,process 方法通过调用 parseConnection,parseRequest 和 parseHeaders 方法开始解析前来的 HTTP 请求,这些方法将在这节的后面讨论。
parseConnection(socket);
parseRequest(input, output);
if (!request.getRequest().getProtocol()
.startsWith("HTTP/0"))
parseHeaders(input);
parseConnection 方法获得协议的值,像 HTTP0.9, HTTP1.0 或 HTTP1.1。
如果协议是 HTTP1.0,keepAlive 设置为 false,因为 HTTP1.0 不支持持久连接。
如果在 HTTP 请求里边找到 Expect: 100-continue 的头部信息,则 parseHeaders 方法将把 sendAck 设置为 true。
如果协议是 HTTP1.1,并且 web 客户端发送头部 Expect: 100-continue 的话,通过调用ackRequest 方法它将响应这个头部。它将会测试组块是否是允许的。
getProtocol()获取的协议值是在parseConnection时设置的
ackRequest 方法测试 sendAck 的值,并在 sendAck 为 true 的时候发送下面的字符串:HTTP/1.1 100 Continue\\r\\n\\r\\n
if (http11)
// Sending a request acknowledge back to the client if
// requested.
ackRequest(output);
// If the protocol is HTTP/1.1, chunking is allowed.
if (connector.isChunkingAllowed())
response.setAllowChunking(true);
在解析 HTTP 请求的过程中,有可能会抛出异常。任何异常将会把 ok 或者 finishResponse设置为 false。
在解析过后,process 方法把请求和响应对象传递给容器的 invoke 方法:
((HttpServletResponse) response).setHeader
("Date", FastHttpDateFormat.getCurrentDate());
if (ok)
connector.getContainer().invoke(request, response);
BootStrap类
public final class Bootstrap
public static void main(String[] args)
HttpConnector connector = new HttpConnector();
SimpleContainer container = new SimpleContainer();
connector.setContainer(container);
try
connector.initialize();
connector.start();
System.in.read();
catch (Exception e)
e.printStackTrace();
SimpleContainer是什么? 它实现了Container接口,通过HttpConnector解析出请求和响应后传递给容器
容器通过请求和响应对象获得servletName,负责servlet的加载执行,第4节只是简单实现了invoke方法,其他方法未实现。
对应前面几节的ServletProcessor.java
所以为什么要有Container呢,就是将servlet加载执行过程分离出来,当然实际不止那么简单。
SimpleContainer类
public class SimpleContainer implements Container
public void invoke(Request request, Response response) throws IOException,
ServletException
String servletName = ((HttpServletRequest) request).getRequestURI();
servletName = servletName.substring(servletName.lastIndexOf("/") + 1);
URLClassLoader loader = null;
try
URL[] urls = new URL[1];
URLStreamHandler streamHandler = null;
File classPath = new File(WEB_ROOT);
String repository = (new URL("file", null,
classPath.getCanonicalPath() + File.separator)).toString();
urls[0] = new URL(null, repository, streamHandler);
loader = new URLClassLoader(urls);
catch (IOException e)
System.out.println(e.toString());
Class myClass = null;
try
myClass = loader.loadClass(servletName);
catch (ClassNotFoundException e)
System.out.println(e.toString());
Servlet servlet = null;
try
servlet = (Servlet) myClass.newInstance();
servlet.service((HttpServletRequest) request,
(HttpServletResponse) response);
catch (Exception e)
System.out.println(e.toString());
catch (Throwable e)
System.out.println(e.toString());
接着,如果 finishResponse 仍然是 true,则响应对象的 finishResponse 方法和请求对象的finishRequest 方法将被调用,并且结束输出。 (只要能够正常解析就是true,状态码是在执行servlet过程中修改的,默认是200)
finishResponse处理的是判断响应状态,如果是正常的,则setHeader(“Connection”, “close”); 否则会将错误写到到页面上,可以自己查看代码
finishRequest主要就是关闭HttRequest中的流
if (finishResponse)
//...
response.finishResponse();
//...
request.finishRequest();
while 循环的最后一部分检查响应的 Connection 头部是否已经在 servlet 内部设为 close,或者协议是 HTTP1.0.如果是这种情况的话,keepAlive 设置为 false。同样,请求和响应对象接着会被回收利用。
进入这两个方法,可以看到其实就是将HttpRequestImpl.java和它的基类HttpRquestBase等类的实例变量还原到原来的值,这样在下次请求如果再从处理器池中拿到这个处理器时,保证里面的请求和响应对象是初始值。
if ( "close".equals(response.getHeader("Connection")) )
keepAlive = false;
// End of request processing
status = Constants.PROCESSOR_IDLE;
// Recycling the request and the response objects
request.recycle();
response.recycle();
在这个场景中,如果 keepAlive 是 true 的话,while 循环将会在开头就启动。因为在前面的解析过程中和容器的 invoke 方法中没有出现错误,或者 HttpProcessor 实例没有被停止。否则,shutdownInput 方法将会调用,而套接字将被关闭.
try
shutdownInput(input);
socket.close();
shutdownInput 方法检查是否有未读取的字节。如果有的话,跳过那些字节。
解析连接
parseConnection 方法从套接字中获取到网络地址并把它赋予 HttpRequestImpl 对象。
它也检查是否使用代理并把套接字赋予请求对象。
private void parseConnection(Socket socket)
throws IOException, ServletException
((HttpRequestImpl) request).setInet(socket.getInetAddress());
if (proxyPort != 0)
request.setServerPort(proxyPort);
else
request.setServerPort(serverPort);
request.setSocket(socket);
解析请求
parseRequest 方法是第 3 节中类似方法的完整版本。如果你阅读过上一节,你通过阅读这个方法应该可以理解这个方法是怎么运行的。
解析头部
默认链接器的 parseHeaders 方法使用包 org.apache.catalina.connector.http 里边的HttpHeader 和 DefaultHeaders 类。类 HttpHeader 指代一个 HTTP 请求头部。类 HttpHeader 不是像第3节那样使用字符串,而是使用字符数据用来避免昂贵的字符串操作。类 DefaultHeaders是一个 final 类,在字符数组中包含了标准的 HTTP 请求头部
下面是DefaultHeaders.java部分代码
static final char[] AUTHORIZATION_NAME = "authorization".toCharArray();
static final char[] ACCEPT_LANGUAGE_NAME = "accept-language".toCharArray();
static final char[] COOKIE_NAME = "cookie".toCharArray();
static final char[] CONTENT_LENGTH_NAME = "content-length".toCharArray();
parseHeaders 方法包含一个 while 循环,可以持续读取 HTTP 请求直到再也没有更多的头部可以读取到。
while 循环首先调用请求对象的 allocateHeader 方法来获取一个空的 HttpHead 实例,如果看这个方法,发现HttpRequestImpl中以HttpHeader数组形式保存,如果,默认规定头部大小为10个,如果超过,则通过复制给新数组实现新Header对象的分配。
这个实例被传递给SocketInputStream 的 readHeader 方法。
HttpHeader header = request.allocateHeader();
// Read the next header
input.readHeader(header);
假如所有的头部都被已经被读取的话, readHeader 方法将不会赋值给 HttpHeader 实例,这个时候 parseHeaders 方法将会返回。
if (header.nameEnd == 0)
if (header.valueEnd == 0)
return;
else
throw new ServletException
(sm.getString("httpProcessor.parseHeaders.colon"));
如果存在一个头部的名称的话,这里必须同样会有一个头部的值:String value = new String(header.value, 0, header.valueEnd); 接下去,像第 3 节那样, parseHeaders 方法将会把头部名称和 DefaultHeaders 里边的名称做对比。
注意的是,这样的对比是基于两个字符数组之间,而不是两个字符串之间的。
if (header.equals(DefaultHeaders.AUTHORIZATION_NAME))
request.setAuthorization(value);
else if (header.equals(DefaultHeaders.ACCEPT_LANGUAGE_NAME))
parseAcceptLanguage(value);
//...
总结
本节可学习技巧如下:
- 对象池复用对象技术
- 组件解耦合思想
- 继承关系的设计
- 从零开始手写Tomcat的教程12节----StandardContext