高性能计算网络,RoCE vs. InfiniBand该怎么选?
Posted Hardy晗狄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高性能计算网络,RoCE vs. InfiniBand该怎么选?相关的知识,希望对你有一定的参考价值。


高性能计算网络平台解决方案(技术细节参考:从高性能计算(HPC)技术演变解析方案、生态和行业发展趋势),能够解决物探高性能计算中,基于GPU的程序必须调用 IB栈,而传统TCP/IP 堆栈应用无法支撑高性能计算网络通信的问题。
ROCE v2架构解决方案逐渐被客户接受(参考:详解RoCE网络技术和RoCE网络技术和实现方式), 生态和应用不断成熟,同时网络传输效率和可靠性也得到加强,通过ROCE v2 技术的运营降低了主机CPU消耗。

HPC是指利用聚集起来的计算能力来处理标准工作站无法完成的数据密集型计算任务,例如勘探业务中所需要的仿真、建模和渲染等。我们在处理各种计算问题时常常遇到这样的情况:由于需要大量的运算,一台通用的计算机无法在合理的时间内完成工作,或者由于所需的数据量过大而可用的资源有限,导致根本无法执行计算。
HPC方法通过使用专门或高端的硬件,或是将多个单元的计算能力进行整合,能够有效地克服这些限制。将数据和运算相应地分布到多个单元中,这就需要引入并行概念。
不同类型的建模问题具有不同的可并行程度。以参数化扫描为例,这种问题求解多个具有独立的几何、边界条件或材料属性的相似的模型,几乎可以完全并行计算。具体的实现方法是为将每一个模型设置分配给一个计算单元。这类问题非常适合并行计算,因此通常称为“易并行问题”并行问题对集群中的网络速度和延迟非常敏感。(在其他情况下,由于网络速度不够快,无法有效处理通信,很可能导致速度减慢。)因此,可以将通用硬件连接起来,加快这类问题的计算速度。
传统网络中 TCP/IP 堆栈随着网络接入带宽的增长,对 CPU 的消耗越来越高,HPC 网络通常采用 RDMA 技术对网络减少TCP/IP 堆栈对计算节点 CPU 的消耗,降低网络传输延时。
RDMA 允许在两台服务器的内存之间直接转移数据(参考:详解RDMA架构和技术原理、谈谈高性能RDMA网络优势和实践和深入浅出全面解析RDMA),而无需任何一台服务器的 CPU 参与(也称为零拷贝网络),因此可实现更高效的通信。这种处理在支持 RDMA 的网络接口卡(NIC)上进行,并且会避开TCP/IP 堆栈,因而加快数据转移。如此,就可以直接将数据传送到目标服务器上的远程内存中,降低用于其他处理的服务器的 CPUI/O 工作负载。
传统的IB交换体系架构(参考:Infiniband架构和技术实战、InfiniBand高速互连网络设计的研究和200G HDR InfiniBand有啥不同?)利用了 RDMA 技术技术,通过业界最小的转发延时,为 HPC 提供高性能低延时的网络平台,但 Infinband交换机有自己的独立架构体系和协议(IB 协议和规范):
-
1. 必须和支持 IB 协议的设备进行互联。
-
2.Infinband 体系相对封闭,难以替换。
-
3. Infinband 体系和传统网络对接需要单独的网关。
对于在整体 HPC 计算平台中,存在这大量对延时并非绝对敏感的应用,而以昂贵的 IB 交换端口来承载数目众多的这些应用无形中增加了企业的计算成本、维护成本、管理成本,制约了 HPC 整体系统的扩展。从业界以太网络基于10G/25G/40G/100G 带宽增长的趋势的发展趋势来看,随着计算规模的不断扩增,原有很多基于 IB 建立的网络无论从带宽介质形态,端口密度等都需要扩容,对于非延时绝对要求的 HPC 应用接入,都倾向于采用以太网替换原有 IB 交换机以降低成本。
RoCE 规范在以太网上实现了 RDMA 功能,ROCE 需要无损网络,RoCE的主要优势在于它的延迟较低,因此可提高网络利用率;同时它可避开TCP/IP 并采用硬件卸载,因此 CPU 利用率也较低。
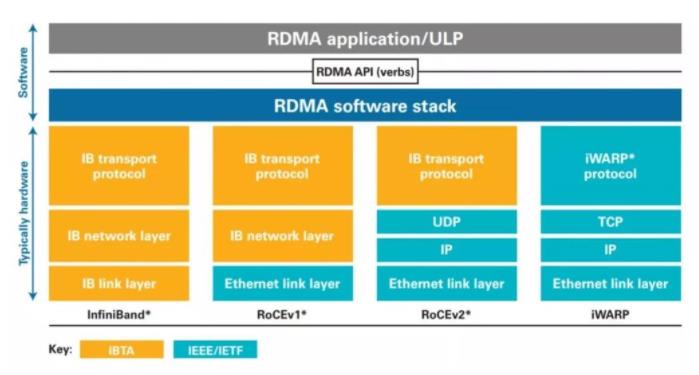
新 RoCEv2 标准可实现 RDMA 路由在第三层以太网网络中的传输。RoCEv2 规范将用以太网链路层上的 IP 报头和 UDP 报头替代 InfiniBand 网络层。这样,就可以在基于 IP 的传统路由器之间路由 RoCE。
-
RoCE v1协议:基于以太网承载 RDMA,只能部署于二层网络,它的报文结构是在原有的 IB架构的报文上增加二层以太网的报文头,通过 Ethertype 0x8915 标识 RoCE 报文。
-
RoCE v2协议:基于 UDP/IP 协议承载 RDMA,可部署于三层网络,它的报文结构是在原有的 IB 架构的报文上增加UDP头、IP 头和二层以太网报文头,通过 UDP 目的端口号 4791 标 识 RoCE 报文。RoCE v2 支持基于源端口号 hash,采用 ECMP 实现负载分担,提高了网络的利用率。
利用这项创新,业界就能够满足企业内日益增长的高性能和横向扩展架构需求。RoCEv2 可帮助其实现融合路径的持续性并提供高度密集的数据中心,同时为基于 IB 的应用移植,提供了快速迁移的方式,减少了开发工作量,提高了用户部署应用和迁移应用的效率。
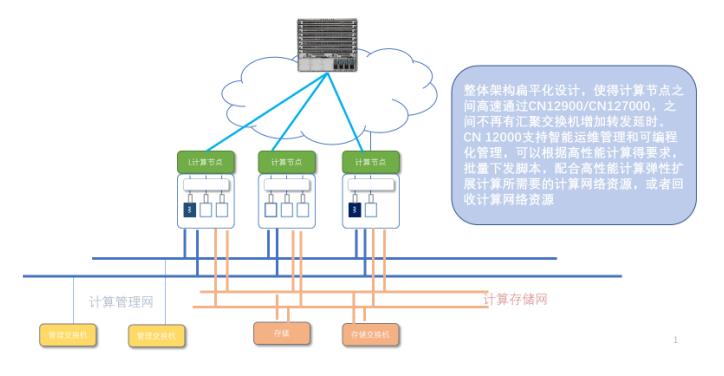
国内华为、浪潮、华三等主流网络厂商都支持RoCE网络方案。以浪潮为例,典型方案采用CN12000 接入核心,形成三张网:计算网、管理网、存储网,在计算网实现高密度,高转发,配合主机实现 RDMA 关键技术的运用,实现基于 IB 协议开发的高性能应用平滑迁移到更低成本的以太交换网络中来。
网络高性能产品的支持,极大简化了高性能网络架构,并降低了多级架构层次造成的延时,为关键计算节点接入带宽的平滑升级提供有力支撑。采用 RoCEv2 标准作为核心,通过对计算节点 RoCEv2、DCE/DCB 的支持,消除了程序移植带来的复杂性和额外的工作量,降低了计算节点 TCP/IP 堆栈对主机 CPU 的消耗。
核心网络通过PFC/RoCE等技术的支撑,使得高性能计算网络具备更高的开放性,在没有降低计算效率的前提下,降低了整个高性能集群平台建设的成本。
各位看官,今天的内容分享完毕,深入技术细节及解决方案,请参考:
或者获取全店资料打包,后续免费获取全店所有新增和更新。

转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师全店铺技术资料打包”相关电子书(37本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“全店铺技术资料打包(全)”,后续可享全店内容更新“免费”赠阅,价格仅收198元(原总价350元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。

以上是关于高性能计算网络,RoCE vs. InfiniBand该怎么选?的主要内容,如果未能解决你的问题,请参考以下文章