什么是元数据(MetaData)及?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是元数据(MetaData)及?相关的知识,希望对你有一定的参考价值。
了解元数据,可以看下下面这篇文章,是一个90后的小美女写的,通俗易懂。\\x0d\\x0a\\x0d\\x0a近几年,随着90后群体逐步迈入职场,逐渐出现在社会大众的视野当中。本文出自一名90后美女程序员之手,他们是极具个性的一代,他们这代技术人的新奇想法,正是现代企业需要的创新源泉?\\x0d\\x0a\\x0d\\x0a关于作者:\\x0d\\x0a\\x0d\\x0a龚菲普元信息大数据产品部90后美女程序员\\x0d\\x0a\\x0d\\x0a公司大数据治理正做得风生水起,各种核心产品在国内市场数一数二,终极大BOSS们将数据治理方面的经验总结成文章,篇篇干货,堪称经典。(有兴趣的同学可以看下公众号的历史文章,不过据说有一批干货文章还没发表出来,敬请期待)。作为尚未正式入职的小菜鸟,我也只能在极浅的层面发表一些我自己的看法?\\x0d\\x0a\\x0d\\x0a我将文章分为两大部分,第一部分介绍元数据概念,第二部分从几个方面说明元数据管理的应用,最后一部分总结一下元数据的重要性,仅代表我的一些个人观点,还请各位前辈们不要见笑。\\x0d\\x0a\\x0d\\x0a一、元数据什么鬼?\\x0d\\x0a\\x0d\\x0a我入职的时候刚好赶上公司的元数据产品升级换代,同事们的研发气氛正火热,作为新入职菜鸟,总得先了解一下元数据概念,不然日后怎么和小伙伴们愉快地玩耍,于是查找国内外相关材料:\\x0d\\x0a\\x0d\\x0a一段时间之后有了一些知识积累,才发现用“关于数据的数据”来给元数据下定义确实再准确不过了,但同时也略微抽象,新人难于快速理解,待到上周我们数据治理专家从心理学的角度来阐述元数据之后,我终于也算理解了元数据到底是个啥,今天也算是站在“巨人”的肩膀上,用一种更简单的方式来回答“元数据究竟是什么”这个问题?\\x0d\\x0a\\x0d\\x0a元数据是关于数据的描述,存储着关于数据的信息,为人们更方便地检索信息提供了帮助。咦?检索信息?小蝌蚪找妈妈的过程也是一个检索信息的过程,是不是看懂这个故事就能懂元数据是什么了?\\x0d\\x0a\\x0d\\x0a池塘里有一群小蝌蚪,他们看见鲤鱼妈妈在教小鲤鱼捕食,就迎上去,问:“鲤鱼阿姨,我们的妈妈在哪里?”\\x0d\\x0a\\x0d\\x0a此时蝌蚪们意识到,不对啊,我们的数据库里不是应该存在着一张Mother表吗,但是蝌蚪们竟然对这张表一无所知,不知道有什么字段,也不知道各个字段对应的具体数值:\\x0d\\x0a\\x0d\\x0a鲤鱼妈妈说:“你们的妈妈有四条腿,宽嘴巴。你们到那边去找吧!”\\x0d\\x0a\\x0d\\x0a鳄鱼笑着说:“你们的妈妈有两只大眼睛,披着绿衣裳。你们到那边去找吧!”?\\x0d\\x0a\\x0d\\x0a乌龟笑着说:“我不是你们的妈妈,你们的妈妈肚皮是白的,到前面去找吧。”?\\x0d\\x0a\\x0d\\x0a青蛙听了“各各”地笑起来,说“唉!傻孩子,我就是你们的妈妈呀”\\x0d\\x0a\\x0d\\x0a整个过程可以看成是Mother这张表逐步完善的过程,数据来源分别是鲤鱼妈妈、鳄鱼妈妈和乌龟妈妈,如下图所示:\\x0d\\x0a\\x0d\\x0a对蝌蚪们最终获取到的信息进行进一步抽象,就可以形成一种“元数据”,该元数据描述了Mother这张表的结构:\\x0d\\x0a\\x0d\\x0a刚才不是说元数据能为检索信息提供帮助吗,那是不是也说明元数据能为小蝌蚪找妈妈提供帮助?我们将在第二部分试着对这个故事进行改编,详细介绍小蝌蚪利用元数据快速找到妈妈的过程。\\x0d\\x0a\\x0d\\x0a二、元数据管理的应用\\x0d\\x0a\\x0d\\x0a通常一款元数据管理工具应具备元模型设计、元数据采集、元数据分析、数据地图展现等核心功能,我们试着改编小蝌蚪找妈妈这个故事,在改编的过程中理解这几个核心功能,前提是我们假设所有动物共同构成了一个庞大的数据体系,小蝌蚪们Mother的具体数据已经存在于此体系之中(鲤鱼系统、鳄鱼系统、乌龟系统)。\\x0d\\x0a\\x0d\\x0a1、元模型设计\\x0d\\x0a\\x0d\\x0a先解释一下元模型。如果说元数据是对数据的描述,那么元模型就是对元数据的描述,是对元数据的进一步抽象,三者的关系如下图所示:\\x0d\\x0a\\x0d\\x0a再讲一下元模型设计的过程。首先获取到系统中的所有元数据,将这些元数据汇总并进行合理规划,进一步抽象成元模型,从一定角度来说,可以把这个抽象的过程看成元模型设计的过程。\\x0d\\x0a\\x0d\\x0a元模型定义了各种元数据的结构以及元数据之间的关系,是元数据管理的基础,也就是说,如果我们想用元数据帮助小蝌蚪找妈妈,需要先设计出合理的元模型。下图是我试着给它们设计出的元模型(对于企业来说,真正的元模型设计过程非常复杂,受多方面因素影响):\\x0d\\x0a\\x0d\\x0a我们认为小蝌蚪的妈妈(Mother)由若干个属性(Property)组成,每个属性的名称用Name表示,每个属性的类型用Type表示。\\x0d\\x0a\\x0d\\x0a现在元模型有了,下一步就是按照这个设计好的元模型采集小蝌蚪们需要的元数据信息,也就是我们常说的元数据采集。\\x0d\\x0a\\x0d\\x0a2、元数据采集\\x0d\\x0a\\x0d\\x0a设计好元模型之后,元数据管理工具能通过全自动的方式采集到企业所需要的元数据,在这个故事中,按照我设计好的元模型,元数据管理工具的元数据采集结果应该如下图所示:\\x0d\\x0a\\x0d\\x0a小蝌蚪们拿着这份元数据再去针对性地检索关于妈妈的信息,就能一步到位,将目标直接锁定到青蛙,整个故事将因元数据的出现而成功改写。\\x0d\\x0a\\x0d\\x0a说明:在真实的企业数据环境中,数据与元数据是已经存在于系统之中的,元数据管理就是根据企业现有的元数据设计出适合企业的元模型,然后将系统之中的元数据按照元模型集中汇总并关联到一起,达到企业对数据统一管理与应用的目的。\\x0d\\x0a\\x0d\\x0a3、元数据分析\\x0d\\x0a\\x0d\\x0aa、血缘分析\\x0d\\x0a\\x0d\\x0a假设动物园园长慢羊羊正管理着整个动物园的数据信息,有一天园长发现自己这里有个数据不对,需要找出错误数据的提供者并追究责任,那么这个错误数据来自于哪个动物家庭呢?挨家挨户去敲门核对数据显然不够高效,元数据管理工具的血缘分析功能会自动帮助园长分析这个错误数据的上游路径,比如这个数据是由鲤鱼妈妈交给鳄鱼妈妈,鳄鱼妈妈再提交给园长的,那么此时园长只需要去敲鲤鱼和鳄鱼家的门就可以了。\\x0d\\x0a\\x0d\\x0ab、影响分析\\x0d\\x0a\\x0d\\x0a数据终于更正了,此时园长需要及时提醒大家这个数据的更正信息,只需要通知这个数据影响到的动物家庭就可以了,这让园长十分苦恼,整个动物园的数据传递这么复杂,怎么判断哪个家庭会受到这个数据的影响呢,元数据管理工具的影响分析功能会分析出这个数据的影响范并能用可视化的方式展现出来,园长只需要通知受影响的动物家庭就可以了。\\x0d\\x0a\\x0d\\x0ac、数据地图展现\\x0d\\x0a\\x0d\\x0a随着动物园规模的日益扩大,入住的动物种类日益增多,有一天园长想了解动物园的整体情况,有多少动物家庭,哪个家庭和哪个家庭比较要好,哪个家庭和哪个家庭又从来没有联系,此时元数据管理工具的数据地图可以帮助园长获取到他想要的信息,数据地图展现功能可以通过可视化的方式,让园长对整个动物园的情况了如指掌,帮助它更好地观察整个动物园的情况。\\x0d\\x0a\\x0d\\x0a三、元数据的重要性\\x0d\\x0a\\x0d\\x0a在大数据时代的背景下,数据即资产,元数据实现了信息的描述和分类的格式化,从而为机器处理创造了可能,它能帮助企业更好地对数据资产进行管理,理清数据之间的关系。元数据管理是企业提升数据质量的基础,也是企业数据治理中的关键环节。元数据管理不当,信息很容易被丢失,进而不能对业务进行有效支撑,企业内部业务人员要识别相关信息就会变得十分困难,最终用户也将失去对数据的信任。\\x0d\\x0a\\x0d\\x0a写在最后:\\x0d\\x0a\\x0d\\x0a公司正在研发针对企业级用户的数字化企业云平台,并且全面公开研发文档与技术细节,由我担任的群主的微信讨论群也会对架构设计过程进行公开,欢迎对此感兴趣的前辈和朋友入群,与我们共同讨论,共商“云”是。感兴趣或者想学习相关技术,可在百度中搜EAii了解。 参考技术A元数据(Meta Data)是关于数据的数据,当人们描述现实世界的现象时,就会产生抽象信息,这些抽象信息便可以看作是元数据,元数据主要用来描述数据的上下文信息。
通俗的来讲,假若图书馆的每本书中的内容是数据的话,那么找到每本书的索引则是元数据,元数据之所以有其它方法无法比拟的优势,就在于它可以帮助人们更好的理解数据。
发现和描述数据的来龙去脉,特别是那些即将要从OLTP系统上升到DW/BI体系建设的企业,元数据可以帮他们形成清晰直观的数据流图,元数据是数据管控的基本手段。
元数据是为了提升共享、重新获取和理解企业信息资产的水平,元数据是企业信息管理的润滑剂,不对元数据进行管理或管理不得当。
信息将被丢失或处于隐匿状态而难以被用户使用,数据集成将十分昂贵,不能对业务进行有效支撑。终端用户要识别相关的信息将十分困难,最终用户将失去对数据的信任。
扩展资料
元数据分类
元数据管理的范围将涵括数据产生、数据存储、数据加工和展现等各个环节的数据描述信息,帮助用户理解数据来龙去脉、关系及相关属性。按其描述对象的不同可以划分为三类元数据:技术元数据、业务元数据和管理元数据。这三种元数据的具体描述如下:
1、技术元数据 技术元数据是描述数据系统中技术领域相关概念、关系和规则的数据,主要包括对数据结构、数据处理方面的特征描述,覆盖数据源接口、数据仓库与数据集市存储、ETL、OLAP、数据封装和前端展现等全部数据处理环节;
2、业务元数据 业务元数据是描述数据系统中业务领域相关概念、关系和规则的数据,主要包括业务术语、信息分类、指标定义和业务规则等信息;
3、管理元数据 管理元数据是描述数据系统中管理领域相关概念、关系和规则的数据,主要包括人员角色、岗位职责和管理流程等信息。
参考资料来源:百度百科-元数据
Java注解和注解解析器深耕,架构师必会
本文将介绍学习元数据->元注解->运行时注解->编译时注解处理器->自定义框架Demo
什么是元数据(metadata)
元数据由metadata译来,所谓的元数据就是“关于数据的数据”,更通俗的说就是描述数据的数据,对数据及信息资源的描述性信息.比如说一个文本文件,有创建时间,创建人,文件大小等数据,这都可以理解为是元数据.
在java中,元数据以标签的形式存在java代码中,它的存在并不影响程序代码的编译和执行,通常它被用来生成其它的文件或运行时知道被运行代码的描述信息。java当中的javadoc和注解都属于元数据.
什么是注解(Annotation)?
注解是从java 5.0开始加入,可以用于标注包,类,方法,变量等.比如我们常见的@Override,再或者Android源码中的@hide,@systemApi,@privateApi等
对于@Override,多数人往往都是知其然而不知其所以然,今天我就来聊聊Annotation背后的秘密,开始正文.
元注解
元注解就是定义注解的注解,是java提供给我们用于定义注解的基本注解.在java.lang.annotation包中我们可以看到目前元注解共有以下几个:
@Retention
@Target
@Inherited
@Documented
@interface
下面我们将集合@Override注解来解释着5个基本注解的用法.
@interface
@interface是java中用于声明注解类的关键字.使用该注解表示将自动继承java.lang.annotation.Annotation类,该过程交给编译器完成.
因此我们想要定义一个注解只需要如下做即可,以@Override注解为例
public @interface Override
需要注意:在定义注解时,不能继承其他注解或接口
@Retention
@Retention:该注解用于定义注解保留策略,即定义的注解类在什么时候存在(源码阶段 or 编译后 or 运行阶段).该注解接受以下几个参数:RetentionPolicy.SOURCE,RetentionPolicy.CLASS,RetentionPolicy.RUNTIME,其具体使用及含义如下:
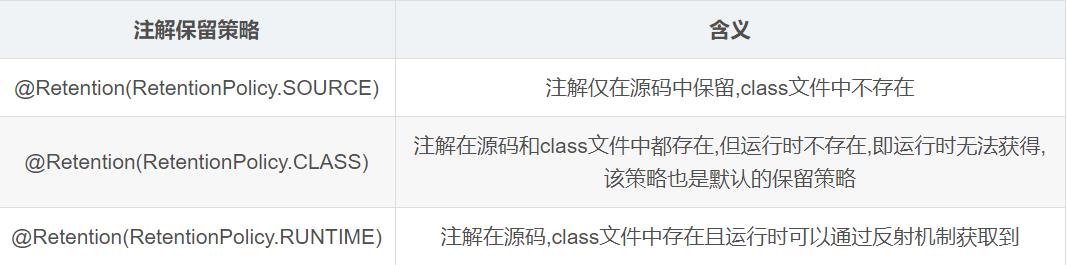
来看一下@Override注解的保留策略:
@Retention(RetentionPolicy.SOURCE)public @interface Override
这表明@Override注解只在源码阶段存在,javac在编译过程中去去掉该注解.
@Target
该注解用于定义注解的作用目标,即注解可以用在什么地方,比如是用于方法上还是用于字段上,该注解接受以下参数:

以@Override为例,不难看出其作用目标为方法:
@Target(ElementType.METHOD)public @interface Override
到现在,通过@interface,@Retention,@Target已经可以完整的定义一个注解,来看@Override完整定义:
@Target(ElementType.METHOD)@Retention(RetentionPolicy.SOURCE)public @interface Override
@Inherited
默认情况下,我们自定义的注解用在父类上不会被子类所继承.如果想让子类也继承父类的注解,即注解在子类也生效,需要在自定义注解时设置@Inherited.一般情况下该注解用的比较少.
@Documented
该注解用于描述其它类型的annotation应该被javadoc文档化,出现在api doc中.
比如使用该注解的@Target会出出现在api说明中.
@Documented@Retention(RetentionPolicy.RUNTIME)@Target(ElementType.ANNOTATION_TYPE)public @interface TargetElementType[] value();
借助@Interface,@Target,@Retention,@Inherited,@Documented这五个元注解,我们就可以自定义注解了,其中前三个注解是任何一个注解都必备具备的.
自定义注解
格式:
public @interface 注解名 定义体定义体就是方法的集合,每个方法实则是声明了一个配置参数.方法的名称作为配置参数的名称,方法的返回值类型就是配置参数的类型.和普通的方法不一样,可以通过default关键字来声明配置参数的默认值.需要注意:
此处只能使用public或者默认的defalt两个权限修饰符配置参数的类型只能使用基本类型(byte,boolean,char,short,int,long,float,double)和String,Enum,Class,annotation对于只含有一个配置参数的注解,参数名建议设置中value,即方法名为value配置参数一旦设置,其参数值必须有确定的值,要不在使用注解的时候指定,要不在定义注解的时候使用default为其设置默认值,对于非基本类型的参数值来说,其不能为null.
像@Override这样,没有成员定义的注解称之为标记注解.
注解处理器
上面我们已经学会了如何定义注解,要想注解发挥实际作用,需要我们为注解编写相应的注解处理器.根据注解的特性,注解处理器可以分为运行时注解处理和编译时注解处理器.运行时处理器需要借助反射机制实现,而编译时处理器则需要借助APT来实现.
无论是运行时注解处理器还是编译时注解处理器,主要工作都是读取注解及处理特定注解,从这个角度来看注解处理器还是非常容易理解的.
注解处理器是(Annotation Processor)是javac的一个工具,用来在编译时扫描和编译和处理注解(Annotation)。你可以自己定义注解和注解处理器去搞一些事情。一个注解处理器它以Java代码或者(编译过的字节码)作为输入,生成文件(通常是java文件)。这些生成的java文件不能修改,并且会同其手动编写的java代码一样会被javac编译。看到这里加上之前理解,应该明白大概的过程了,就是把标记了注解的类,变量等作为输入内容,经过注解处理器处理,生成想要生成的java代码。
运行时注解处理器(不建议使用)
熟悉java反射机制的同学一定对java.lang.reflect包非常熟悉,该包中的所有api都支持读取运行时Annotation的能力,即属性为@Retention(RetentionPolicy.RUNTIME)的注解.
在java.lang.reflect中的AnnotatedElement接口是所有程序元素的(Class,Method)父接口,我们可以通过反射获取到某个类的AnnotatedElement对象,进而可以通过该对象提供的方法访问Annotation信息,常用的方法如下:
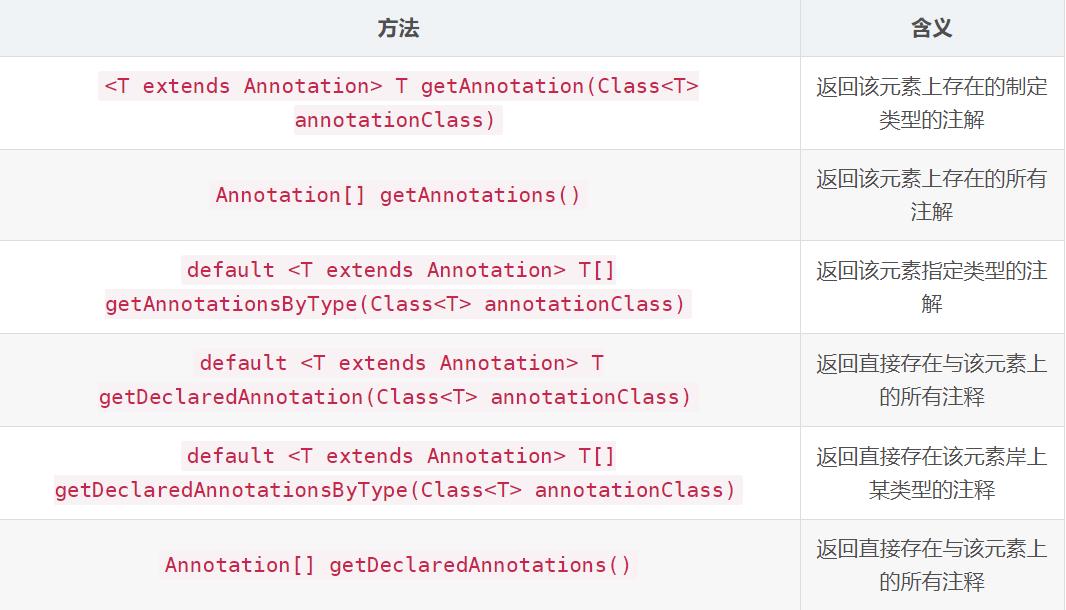
运行时注解处理器的编写本质上就是通过反射获取注解信息,随后进行其他操作。编译一个运行时注解处理器就是这么简单。运行时注解通常多用于参数配置类模块。
编译时注解处理器
不同于运行时注解处理器,编写编译时注解处理器(Annotation Processor Tool).
APT用于在编译时期扫描和处理注解信息.一个特定的注解处理器可以以java源码文件或编译后的class文件作为输入,然后输出另一些文件,可以是.java文件,也可以是.class文件,但通常我们输出的是.java文件.(注意:并不是对源文件修改).如果输出的是.java文件,这些.java文件回合其他源码文件一起被javac编译.
你可能很纳闷,注解处理器是到底是在什么阶段介入的呢?好吧,其实是在javac开始编译之前,这也就是通常我们为什么愿意输出.java文件的原因.
注解最早是在java 5引入,主要包含apt和com.sum.mirror包中相关mirror api,此时apt和javac是各自独立的。从java 6开始,注解处理器正式标准化,apt工具也被直接集成在javac当中。
我们还是回到如何编写编译时注解处理器这个话题上,编译一个编译时注解处理主要分两步:
1、继承AbstractProcessor,实现自己的注解处理器
2、注册处理器,并打成jar包
首先来看一下一个标准的注解处理器的格式:
public class MyAnnotationProcessor extends AbstractProcessor@Overridepublic Set<String> getSupportedAnnotationTypes()return super.getSupportedAnnotationTypes();@Overridepublic SourceVersion getSupportedSourceVersion()return super.getSupportedSourceVersion();@Overridepublic synchronized void init(ProcessingEnvironment processingEnv)super.init(processingEnv);@Overridepublic boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv)return false;

编写一个注解处理器首先要对ProcessingEnvironment和RoundEnvironment非常熟悉。接下来我们一览这两个类的风采.首先来看一下ProcessingEnvironment类:
public interface ProcessingEnvironmentMap<String,String> getOptions();//Messager用来报告错误,警告和其他提示信息Messager getMessager();//Filter用来创建新的源文件,class文件以及辅助文件Filer getFiler();//Elements中包含用于操作Element的工具方法Elements getElementUtils();//Types中包含用于操作TypeMirror的工具方法Types getTypeUtils();SourceVersion getSourceVersion();Locale getLocale();
Element
element表示一个静态的,语言级别的构件。而任何一个结构化文档都可以看作是由不同的element组成的结构体,比如XML,JSON等。
对于java源文件来说,Element代表程序元素:包,类,方法都是一种程序元素,他同样是一种结构化文档:
package com.closedevice; //PackageElementpublic class Main //TypeElementprivate int x; //VariableElementprivate Main() //ExecuteableElementprivate void print(String msg) //其中的参数部分String msg为TypeElement


TypeMirror
这三个类也需要我们重点掌握:
DeclaredType代表声明类型:类类型还是接口类型,当然也包括参数化类型,比如Set<String>,也包括原始类型
TypeElement代表类或接口元素,而DeclaredType代表类类型或接口类型。
TypeMirror代表java语言中的类型.Types包括基本类型,声明类型(类类型和接口类型),数组,类型变量和空类型。也代表通配类型参数,可执行文件的签名和返回类型等。TypeMirror类中最重要的是getKind()方法,该方法返回TypeKind类型,为了方便大家理解,这里附上其源码:
public enum TypeKindBOOLEAN,BYTE,SHORT,INT,LONG,CHAR,FLOAT,DOUBLE,VOID,NONE,NULL,ARRAY,DECLARED,ERROR, TYPEVAR,WILDCARD,PACKAGE,EXECUTABLE,OTHER,UNION,INTERSECTION;public boolean isPrimitive()switch(this)case BOOLEAN:case BYTE:case SHORT:case INT:case LONG:case CHAR:case FLOAT:case DOUBLE:return true;default:return false;
简单来说,Element代表源代码,TypeElement代表的是源码中的类型元素,比如类。虽然我们可以从TypeElement中获取类名,TypeElement中不包含类本身的信息,比如它的父类,要想获取这信息需要借助TypeMirror,可以通过Element中的asType()获取元素对应的TypeMirror。
然后来看一下RoundEnvironment,这个类比较简单,一笔带过:
public interface RoundEnvironmentboolean processingOver();//上一轮注解处理器是否产生错误boolean errorRaised();//返回上一轮注解处理器生成的根元素Set<? extends Element> getRootElements();//返回包含指定注解类型的元素的集合Set<? extends Element> getElementsAnnotatedWith(TypeElement a);//返回包含指定注解类型的元素的集合Set<? extends Element> getElementsAnnotatedWith(Class<? extends Annotation> a);
Filer
Filer用于注解处理器中创建新文件,由于Filer用起来实在比较麻烦,后面我们会使用javapoet简化我们的操作.
打包注解处理器的时候需要一个特殊的文件 javax.annotation.processing.Processor 在 META-INF/services 路径下
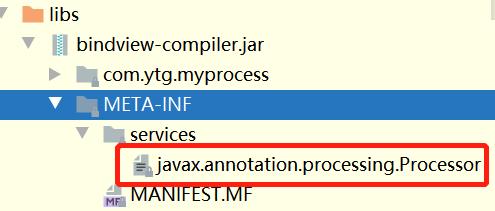
新建项目必要配置:
//javapoet代码生成框架implementation 'com.squareup:javapoet:1.8.0'//注解处理器implementation 'com.google.auto.service:auto-service:1.0-rc6'annotationProcessor 'com.google.auto.service:auto-service:1.0-rc6'
编译时注解demo示例地址:https://gitee.com/yutg/apt.git
项目结构
--apt-demo----bindview-annotation(Java Library)//注解定义----bindview-api(Android Library)//定义SDK接口方法----bindview-compiler(Java Library)//注解处理器相关操作及生成java文件----app(Android App)
以上是关于什么是元数据(MetaData)及?的主要内容,如果未能解决你的问题,请参考以下文章