Java基础 -- IO流深 / 浅拷贝
Posted CodeJiao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java基础 -- IO流深 / 浅拷贝相关的知识,希望对你有一定的参考价值。
1. IO流
1.1 Java 中 IO 流分类
- 按照流的流向分,可以分为输入流和输出流;
- 按照操作单元划分,可以划分为字节流和字符流;
- 按照流的角色划分为节点流和处理流。
Java Io流共涉及40多个类,这些类看上去很杂乱,但实际上很有规则,而且彼此之间存在非常紧密的联系, Java I0流的40多个类都是从如下4个抽象类基类中派生出来的。
- InputStream / Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。
- OutputStream / Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
按操作方式分类结构图:
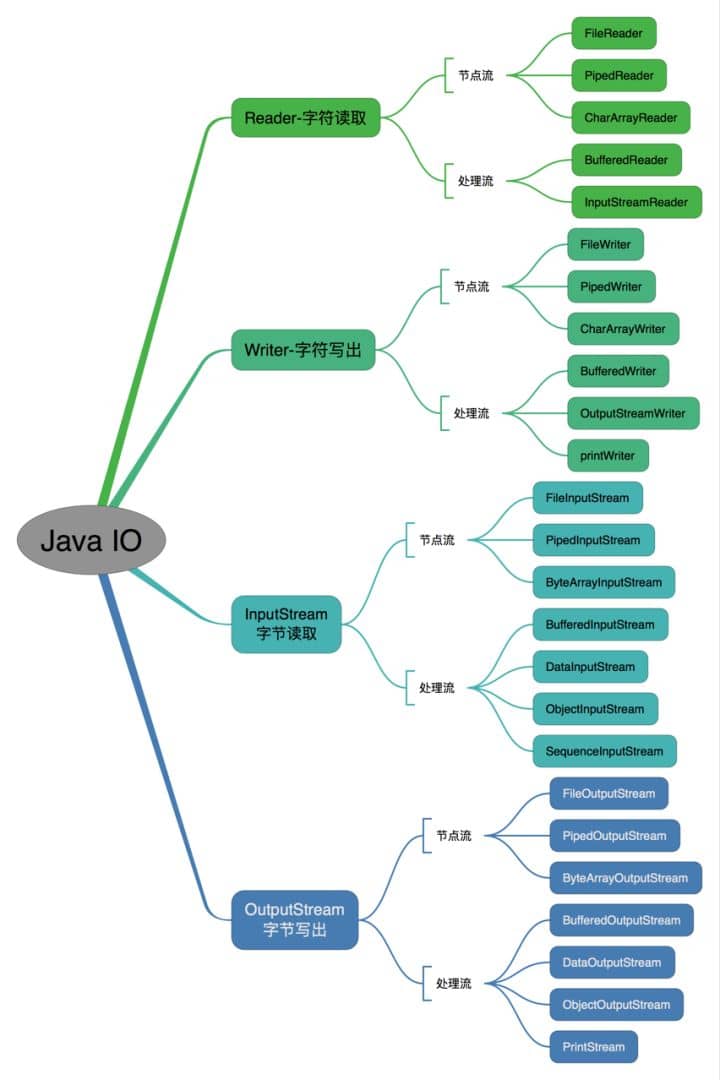
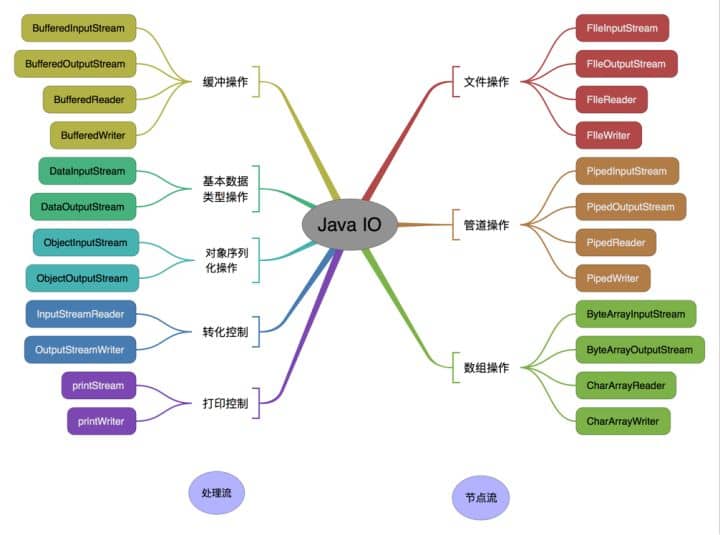
按操作对象分类结构图:
1.2 既然有了字节流,为什么还要有字符流
问题本质想问:不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?
- 字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
1.3 BIO,NIO,AIO 有什么区别

2. 深 / 浅拷贝
- 浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。
- 深拷贝:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。
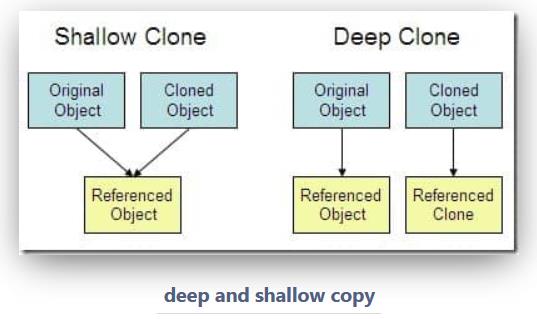
深拷贝和浅拷贝最根本的区别在于是否真正获取一个对象的复制实体,而不是引用。
假设B复制了A,修改A的时候,看B是否发生变化:
如果B跟着也变了,说明是浅拷贝(修改堆内存中的同一个值)
如果B没有改变,说明是深拷贝(修改堆内存中的不同的值)
- 浅拷贝(shallowCopy)只是增加了一个指针指向已存在的内存地址,
- 深拷贝(deepCopy)是增加了一个指针并且申请了一个新的内存,使这个增加的指针指向这个新的内存。
- 深拷贝是指源对象与拷贝对象互相独立,其中任何一个对象的改动都不会对另外一个对象造成影响。
- 使用深拷贝的情况下,释放内存的时候不会因为出现浅拷贝时释放同一个内存的错误。
2.1 浅拷贝实例
2.1.1 测试1 直接赋值
public class Student
private String name;
public Student(String name)
this.name = name;
public String getName()
return name;
public void setName(String name)
this.name = name;
public static void main(String[] args)
Student student1 = new Student("Tom");
Student student2 = student1;
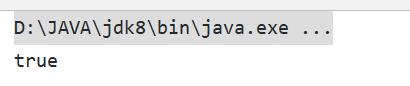
// 因为是指向同一个地址 所以结果必然是相同的
System.out.println(student1 == student2);
2.1.2 测试2 改变源对象的值
public class Student
private String name;
public Student(String name)
this.name = name;
public String getName()
return name;
public void setName(String name)
this.name = name;
public static void main(String[] args)
Student student1 = new Student("Tom");
Student student2 = student1;
student1.setName("Jack");
System.out.println(student2.getName());
运行结果:

2.2 深拷贝实例
这是用于深拷贝的测试类
public class Student
private String name;
public Student(String name)
this.name = name;
public String getName()
return name;
public void setName(String name)
this.name = name;
2.2.1 方法一: 构造函数
@org.junit.Test
public void constructorCopy()
// 被克隆的类
Student xiaoMing = new Student("小明");
// 调用构造函数时进行深拷贝
Student cloneStudent = new Student(xiaoMing.getName());
System.out.println(xiaoMing == cloneStudent); // false
2.2.2 方法二: 重载clone()方法
Object类有个clone()的拷贝方法,不过它是protected类型的,我们需要重写它并修改为public类型。除此之外,子类还需要实现Cloneable接口来告诉JVM这个类是可以拷贝的。
让我们修改一下Student类,实现Cloneable接口,使其支持深拷贝。
Student.java
public class Student implements Cloneable
private String name;
public Student(String name)
this.name = name;
public String getName()
return name;
public void setName(String name)
this.name = name;
// 重写克隆方法
@Override
public Student clone() throws CloneNotSupportedException
return (Student) super.clone();
测试:
@org.junit.Test
public void coneableCopy() throws CloneNotSupportedException
// 被克隆的类
Student xiaoMing = new Student("小明");
Student cloneStudent = xiaoMing.clone();
System.out.println(xiaoMing == cloneStudent);
2.2.3 方法三:Apache Commons Lang序列化
Java提供了序列化的能力,我们可以先将源对象进行序列化,再反序列化生成拷贝对象。但是,使用序列化的前提是拷贝的类(包括其成员变量)需要实现Serializable接口。Apache Commons Lang包对Java序列化进行了封装,我们可以直接使用它。
第一步:导入依赖
pom.xml
<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-lang3 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version>
</dependency>
第二步:让我们修改一下Student类,实现Serializable接口,使其支持序列化。
public class Student implements Serializable
private String name;
public Student(String name)
this.name = name;
public String getName()
return name;
public void setName(String name)
this.name = name;
测试:
@org.junit.Test
public void coneableCopy() throws CloneNotSupportedException
// 被克隆的类
Student xiaoMing = new Student("小明");
// 使用Apache Commons Lang序列化进行深拷贝
Student copyStudent = (Student) SerializationUtils.clone(xiaoMing);
System.out.println(xiaoMing == copyStudent);

2.2.4 方法四:Gson
Gson可以将对象序列化成JSON,也可以将JSON反序列化成对象,所以我们可以用它进行深拷贝。
第一步:导入依赖
pom.xml
<!-- https://mvnrepository.com/artifact/com.google.code.gson/gson -->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.5</version>
</dependency>
第二步: 修改一下Student类,实现Serializable接口,使其支持序列化。同上
测试:
@org.junit.Test
public void coneableCopy() throws CloneNotSupportedException
// 被克隆的类
Student xiaoMing = new Student("小明");
// 使用Gson序列化进行深拷贝
Gson gson = new Gson();
Student copyStudent = gson.fromJson(gson.toJson(xiaoMing), Student.class);
System.out.println(xiaoMing == copyStudent);

2.2.5 方法五: Jackson序列化
Jackson与Gson相似,可以将对象序列化成JSON,明显不同的地方是拷贝的类(包括其成员变量)需要有默认的无参构造函数
第一步:导入依赖
pom.xml
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.12.3</version>
</dependency>
第二步:让我们修改一下Student类,实现默认的无参构造函数,使其支持Jackson。
Student.java
package com.tian.pojo;
import java.io.Serializable;
/**
* ClassName: Student
* Description:
*
* @author Tianjiao
* @date 2021/5/30 18:12
*/
public class Student implements Serializable
private String name;
// 实现无参构造方法
public Student()
public Student(String name)
this.name = name;
public String getName()
return name;
public void setName(String name)
this.name = name;
测试:
@org.junit.Test
public void coneableCopy() throws CloneNotSupportedException, JsonProcessingException
// 被克隆的类
Student xiaoMing = new Student("小明");
// 使用Jackson序列化进行深拷贝
ObjectMapper objectMapper = new ObjectMapper();
Student copyStudent = objectMapper.readValue(objectMapper.writeValueAsString(xiaoMing), Student.class);
System.out.println(xiaoMing == copyStudent);
2.2.6 小结
| 深拷贝方法 | 优点 | 缺点 |
|---|---|---|
| 构造函数 | 1. 底层实现简单 2. 不需要引入第三方包 3. 系统开销小 4. 对拷贝类没有要求,不需要实现额外接口和方法 | 1. 可用性差,每次新增成员变量都需要新增新的拷贝构造函数 |
| 重载clone()方法 | 1. 底层实现较简单 2. 不需要引入第三方包 3. 系统开销小 | 1. 可用性较差,每次新增成员变量可能需要修改clone()方法 2. 拷贝类(包括其成员变量)需要实现Cloneable接口 |
| Apache Commons Lang序列化 | 1. 可用性强,新增成员变量不需要修改拷贝方法 | 1. 底层实现较复杂 2. 需要引入Apache Commons Lang第三方JAR包 3. 拷贝类(包括其成员变量)需要实现Serializable接口 4. 序列化与反序列化存在一定的系统开销 |
| Gson序列化 | 1. 可用性强,新增成员变量不需要修改拷贝方法 2. 对拷贝类没有要求,不需要实现额外接口和方法 | 1. 底层实现复杂 2. 需要引入Gson第三方JAR包 3. 序列化与反序列化存在一定的系统开销 |
| Jackson序列化 | 1. 可用性强,新增成员变量不需要修改拷贝方法 | 1. 底层实现复杂 2. 需要引入Jackson第三方JAR包 3. 拷贝类(包括其成员变量)需要实现默认的无参构造函数 4. 序列化与反序列化存在一定的系统开销 |
以上是关于Java基础 -- IO流深 / 浅拷贝的主要内容,如果未能解决你的问题,请参考以下文章