mysql中使用正则表达式
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql中使用正则表达式相关的知识,希望对你有一定的参考价值。
[\u4e00-\u9fa5]这应该匹配中文字符的吧,但为什么结果正好相反
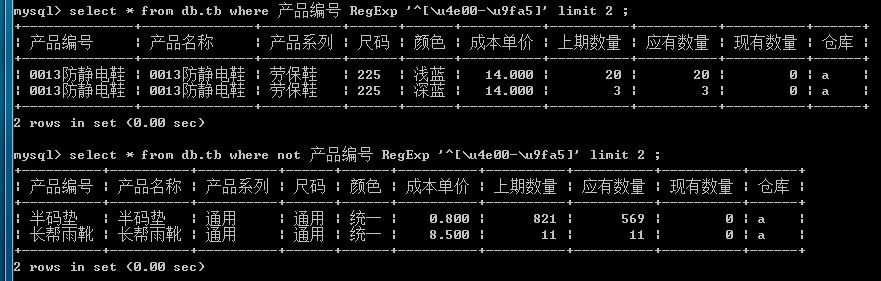
应该这样写 select * from db.tb where 产品编号 RegExp '^[\u4e00-\u9fa5].*' limit2追问
图上我做了2个查询,第一个是没加not的,按你的解释,第一个查询应该是空
我还是拿你的作了测试,结果一样


但是你保存到数据库里的编码不一定是。
可以这样测试
你把“你”字保存在“产品编号”字段中
然后
select hex(产品编号)
utf8是E4BDA0 还有一种是C4E3
unicode是4F60追问
谢谢,确实是这个问题,我已经找到了解决方案
本回答被提问者采纳 参考技术Cmysql 一直以来都支持正则匹配,不过对于正则替换则一直到MySQL 8.0 才支持。对于这类场景,以前要么在MySQL端处理,要么把数据拿出来在应用端处理。
比如我想把表y1的列str1的出现第3个action的子 串替换成dble,怎么实现?
1. 自己写SQL层的存储函数。代码如下写死了3个,没有优化,仅仅作为演示,MySQL 里非常不建议写这样的函数。
mysql
DELIMITER $$
USE `ytt`$$
DROP FUNCTION IF EXISTS `func_instr_simple_ytt`$$
CREATE DEFINER=`root`@`localhost` FUNCTION `func_instr_simple_ytt`(
f_str VARCHAR(1000), -- Parameter 1
f_substr VARCHAR(100), -- Parameter 2
f_replace_str varchar(100),
f_times int -- times counter.only support 3.
) RETURNS varchar(1000)
BEGIN
declare v_result varchar(1000) default 'ytt'; -- result.
declare v_substr_len int default 0; -- search string length.
set f_times = 3; -- only support 3.
set v_substr_len = length(f_substr);
select instr(f_str,f_substr) into @p1; -- First real position .
select instr(substr(f_str,@p1+v_substr_len),f_substr) into @p2; Secondary virtual position.
select instr(substr(f_str,@p2+ @p1 +2*v_substr_len - 1),f_substr) into @p3; -- Third virtual position.
if @p1 > 0 && @p2 > 0 && @p3 > 0 then -- Fine.
select
concat(substr(f_str,1,@p1 + @p2 + @p3 + (f_times - 1) * v_substr_len - f_times)
,f_replace_str,
substr(f_str,@p1 + @p2 + @p3 + f_times * v_substr_len-2)) into v_result;
else
set v_result = f_str; -- Never changed.
end if;
-- Purge all session variables.
set @p1 = null;
set @p2 = null;
set @p3 = null;
return v_result;
end;
$$
DELIMITER ;
-- 调用函数来更新:
mysql> update y1 set str1 = func_instr_simple_ytt(str1,'action','dble',3);
Query OK, 20 rows affected (0.12 sec)
Rows matched: 20 Changed: 20 Warnings: 0
2. 导出来用sed之类的工具替换掉在导入,步骤如下:(推荐使用)
1)导出表y1的记录。
mysqlmysql> select * from y1 into outfile '/var/lib/mysql-files/y1.csv';Query OK, 20 rows affected (0.00 sec)
2)用sed替换导出来的数据。
shellroot@ytt-Aspire-V5-471G:/var/lib/mysql-files# sed -i 's/action/dble/3' y1.csv
3)再次导入处理好的数据,完成。
mysql
mysql> truncate y1;
Query OK, 0 rows affected (0.99 sec)
mysql> load data infile '/var/lib/mysql-files/y1.csv' into table y1;
Query OK, 20 rows affected (0.14 sec)
Records: 20 Deleted: 0 Skipped: 0 Warnings: 0
以上两种还是推荐导出来处理好了再重新导入,性能来的高些,而且还不用自己费劲写函数代码。
那MySQL 8.0 对于以上的场景实现就非常简单了,一个函数就搞定了。
mysqlmysql> update y1 set str1 = regexp_replace(str1,'action','dble',1,3) ;Query OK, 20 rows affected (0.13 sec)Rows matched: 20 Changed: 20 Warnings: 0
还有一个regexp_instr 也非常有用,特别是这种特指出现第几次的场景。比如定义 SESSION 变量@a。
mysqlmysql> set @a = 'aa bb cc ee fi lucy 1 1 1 b s 2 3 4 5 2 3 5 561 19 10 10 20 30 10 40';Query OK, 0 rows affected (0.04 sec)
拿到至少两次的数字出现的第二次子串的位置。
mysqlmysql> select regexp_instr(@a,'[:digit:]2,',1,2);+--------------------------------------+| regexp_instr(@a,'[:digit:]2,',1,2) |+--------------------------------------+| 50 |+--------------------------------------+1 row in set (0.00 sec)
那我们在看看对多字节字符支持如何。
mysql
mysql> set @a = '中国 美国 俄罗斯 日本 中国 北京 上海 深圳 广州 北京 上海 武汉 东莞 北京 青岛 北京';
Query OK, 0 rows affected (0.00 sec)
mysql> select regexp_instr(@a,'北京',1,1);
+-------------------------------+
| regexp_instr(@a,'北京',1,1) |
+-------------------------------+
| 17 |
+-------------------------------+
1 row in set (0.00 sec)
mysql> select regexp_instr(@a,'北京',1,2);
+-------------------------------+
| regexp_instr(@a,'北京',1,2) |
+-------------------------------+
| 29 |
+-------------------------------+
1 row in set (0.00 sec)
mysql> select regexp_instr(@a,'北京',1,3);
+-------------------------------+
| regexp_instr(@a,'北京',1,3) |
+-------------------------------+
| 41 |
+-------------------------------+
1 row in set (0.00 sec)
那总结下,这里我提到了 MySQL 8.0 的两个最有用的正则匹配函数 regexp_replace 和 regexp_instr。针对以前类似的场景算是有一个完美的解决方案。
MySQL中使用正则表达式
- 备战2022春招或暑期实习,本专栏会持续输出MySQL系列文章,祝大家每天进步亿点点!文末私信作者,我们一起去大厂。
- 本篇总结的是 《MySQL中使用正则表达式》,后续会每日更新~
- 关于《Redis入门到精通》、《并发编程》、《Java全面入门》、《鸿蒙开发》等知识点可以参考我的往期博客
- 相信自己,越活越坚强,活着就该逢山开路,遇水架桥!生活,你给我压力,我还你奇迹!

目录
1、简介
MySQL中支持正则表达式匹配,在复杂的过滤条件中,可以考虑使用正则表达式。使用正则表达式需要掌握一些正则表达式的语法和指令,小捌推荐一个学习地址和在线工具,在学习MySQL中使用正则表达式之前,去了解一下正则表达式的语法和指令。
正则表达式学习网址:
正则表达式在线测试:
值得注意的是,MySQL支持的正则表达式仅仅是正则表达式众多实现的一个子集,在使用正则表达式之前,建议先测试一下。测试的时候不一定要先建立表、插入数据,可以直接使用select省略form子句,以简便的方式处理表达式,比如如下方式:
mysql> select '我爱你中国' regexp '我爱你';
+------------------------------+
| '我爱你中国' regexp '我爱你' |
+------------------------------+
| 1 |
+------------------------------+
mysql> select '12306' regexp '[:digit:]';
+----------------------------+
| '12306' regexp '[:digit:]' |
+----------------------------+
| 1 |
+----------------------------+
2、正文
首先准备一张product表,DDL和表数据如下所示,可以直接复制使用。
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for product
-- ----------------------------
DROP TABLE IF EXISTS `product`;
CREATE TABLE `product` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`product_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '产品名称',
`price` decimal(10, 2) UNSIGNED NOT NULL COMMENT '产品价格',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of product
-- ----------------------------
INSERT INTO `product` VALUES (1, 'Apple iPhone 13 (A2634)', 6799.00);
INSERT INTO `product` VALUES (2, 'HUAWEI P50 Pro', 6488.00);
INSERT INTO `product` VALUES (3, 'MIX4', 4999.00);
INSERT INTO `product` VALUES (4, 'OPPO Find X3', 3999.00);
INSERT INTO `product` VALUES (5, 'vivo X70 Pro+', 5999.00);
SET FOREIGN_KEY_CHECKS = 1;
初始数据如下所示:
mysql> select * from product;
+----+-------------------------+---------+
| id | product_name | price |
+----+-------------------------+---------+
| 1 | Apple iPhone 13 (A2634) | 6799.00 |
| 2 | HUAWEI P50 Pro | 6488.00 |
| 3 | MIX4 | 4999.00 |
| 4 | OPPO Find X3 | 3999.00 |
| 5 | vivo X70 Pro+ | 5999.00 |
+----+-------------------------+---------+
2.1 语句顺序
正则表达式的作用是文本匹配,使用一个正则表达式与一个文本内容进行比较,可以校验文本是否符合正则表达式阐述的规则。在MySQL中,正则表达式用在where子句中,可以对select查询的数据进行过滤。
select * from table_name where regexp '你的正则表达式' order by cloumn_name;
需求:
查询产品表中,产品名称中包含3的产品
语句:
mysql> select * from product where product_name regexp '3';
结果:
+----+-------------------------+---------+
| id | product_name | price |
+----+-------------------------+---------+
| 1 | Apple iPhone 13 (A2634) | 6799.00 |
| 4 | OPPO Find X3 | 3999.00 |
+----+-------------------------+---------+
2.2 如何区分大小写
MySQL使用正则表达式默认不区分大小写,但是大部分情况下我们需要明确英文的大小写进行匹配,这个时候我们可以使用binary关键字。
需求:
查询产品表中,产品名称包含huawei的产品
语句:
mysql> select * from product where product_name regexp 'huawei';
结果:
+----+----------------+---------+
| id | product_name | price |
+----+----------------+---------+
| 2 | HUAWEI P50 Pro | 6488.00 |
+----+----------------+---------+
此时查询结果默认不区分大小写,所以可以直接查询出来,如果我们希望查询区分大小写,此时只需要在regexp后面加上binary关键字即可。
语句:
mysql> select * from product where product_name regexp binary 'huawei';
结果:
Empty set (0.00 sec)
由于product表中并没有包含小写huawei的产品,所以返回结果为Empty set
2.3 正则表达式与like的区别
相信有些小伙伴发现上面实现的功能,其实用like也能实现。很多场景下我们使用like来对字符串进行匹配,但是这些场景往往非常简单,而正则表达式是一个非常强大的文本检索过滤工具,它的所能实现的功能比like操作符强大太多啦。总之like能做的正则表达式都能做,正则表示能做的like基本上做不了(要么非常棘手)。
比如如下需求,使用正则表达式可以轻松实现,但是like操作符却不知道怎么实现了。
需求:
查询产品表中,产品名称中v至少出现一次产品信息
语句:
mysql> select * from product where product_name regexp 'v+';
结果:
+----+---------------+---------+
| id | product_name | price |
+----+---------------+---------+
| 5 | vivo X70 Pro+ | 5999.00 |
+----+---------------+---------+
注意:正则表达式重复元字符的匹配都是整个连续出现。下面给出这几个重复元字符,感觉有些小伙伴会理解错。
重复元字符
| 元字符 | 说明 |
|---|---|
| * | 0个或多个匹配,效果与0,一致 |
| + | 1个或多个匹配,效果与1,一致 |
| ? | 1个或0匹配,效果与0,1一致 |
| n | 等于n个匹配数目 |
| n, | 大于等于n个匹配 |
| n,m | 大于等于n小于等于m个,m<255 |
👇🏻 关注公众号 获取更多资料👇🏻
以上是关于mysql中使用正则表达式的主要内容,如果未能解决你的问题,请参考以下文章