FLINK安装及提交任务
Posted 海绵不老
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FLINK安装及提交任务相关的知识,希望对你有一定的参考价值。
FLINK安装及提交任务
FLINK安装
1.安装前确认有java环境,我这里有三台机器,分别是hadoop1,hadoop2,hadoop3;
2.将tar包上传到服务器的一个节点上:flink-1.10.0-bin-scala_2.11.tgz,我这里是放在/opt/soft下;
3.解压:tar -zxvf flink-1.10.0-bin-scala_2.11.tgz,解压后的文件夹:flink-1.10.0
4.修改flink-1.10.0/conf下的flink-conf.yaml 文件:
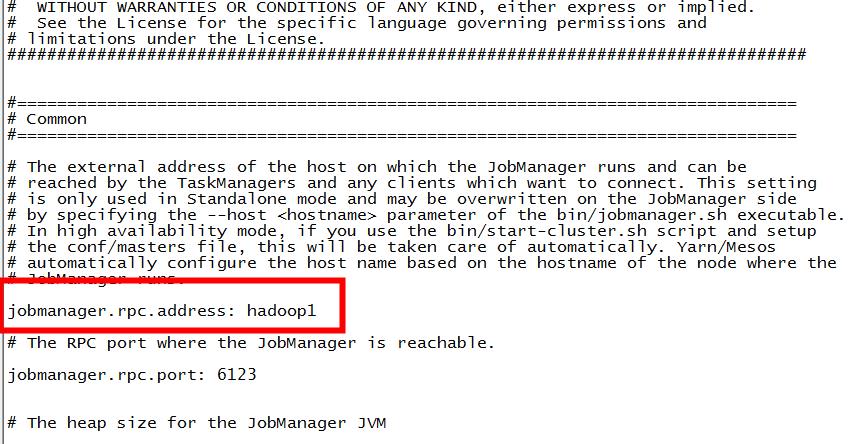
5.修改 /conf/slaves文件,将三台机器hostname写入:

6.一台机器配好后,分发到其他两台机器:
cp -r flink-1.10.0/ atguigu@hadoop2:/opt/module/
cp -r flink-1.10.0/ atguigu@hadoop1:/opt/module/
7.启动集群:
/opt/module/flink-1.10.0/bin/start-cluster.sh

访问http://localhost:8081可以对flink集群和任务进行监控管理:

8.停止集群:
/opt/module/flink-1.10.0/bin/stop-cluster.sh
编写测试代码
编写代码(这里已单词统计为例):
package com.atguigu.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
/**
*
*
* @Author duanguizheng
* @Date 2021/1/20 13:47
* @Version 1.0
*/
public class dataStreamWordCount
public static void main(String[] args) throws Exception
String hostname = "";
int port = 9999;
try
if (args.length == 0)
throw new IllegalArgumentException("give param hostname & port");
hostname = args[0];
port = Integer.valueOf(args[1]);
catch (IllegalArgumentException e)
System.err.println(e.getMessage());
return;
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = null;
if(null == hostname || "" == hostname)
// 设置socket数据源
source = env.socketTextStream("hadoop1", 9999, "\\n");
else
source = env.socketTextStream(hostname, port, "\\n");
// 转化处理数据
//flatmap,也就是将嵌套集合转换并平铺成非嵌套集合
//对于map()来说,实现MapFunction也只是支持一对一的转换。
//那么有时候你需要处理一个输入元素,但是要输出一个或者多个输出元素的时候,就可以用到flatMap()。
DataStream<WordWithCount> dataStream = source.flatMap(new FlatMapFunction<String, WordWithCount>()
@Override
public void flatMap(String line, Collector<WordWithCount> collector) throws Exception
for (String word : line.split(" "))
collector.collect(new WordWithCount(word, 1));
).keyBy("word")//以key分组统计
/* .timeWindow(Time.seconds(10))//设置一个窗口函数,模拟数据流动*/
.sum("count");//计算时间窗口内的词语个数
/* .reduce(new ReduceFunction<WordWithCount>()
@Override
public WordWithCount reduce(WordWithCount a, WordWithCount b)
return new WordWithCount(a.word, a.count + b.count);
);*/
//reduce算子是flink流处理中的一个聚合算子,可以对属于同一个分组的数据进行一些聚合操作。
//但有一点需要注意,就是在需要对聚合结果进行除聚合操作之外的操作时,有可能会失效。
//这里利用reduce函数实现了与和函数相同的效果。熟悉map-reduce的同学可能更容易理解这个函数。
// 这个示例中,reduce函数的功能就是将数据流中的上一个数据和当前数据相加,然后返回传递给下次调用。
// 输出数据到目的端
dataStream.print().setParallelism(1);
// 执行任务操作
env.execute("Flink Streaming Word Count By Java");
//WordWithCountword='mnihao', count=1
//WordWithCountword='nihao', count=1
//WordWithCountword='hi', count=1
//WordWithCountword='hi', count=2
//WordWithCountword='hi', count=3
//WordWithCountword='hi', count=4
public static class WordWithCount
public String word;
public int count;
public WordWithCount()
public WordWithCount(String word, int count)
this.word = word;
this.count = count;
@Override
public String toString()
return "WordWithCount" +
"word='" + word + '\\'' +
", count=" + count +
'';
打jar包,用idea的package打包

自带UI界面提交JOB
将jar包上传

填写主程序类名,填写需要传入的参数,点击submit提交(在hadoop1上运行命令:nc -lk 7777):

nc终端输入字符,在对应的任务控制台会输入结果:


命令提交JOB
1.将jar包放到服务器上(所有任务节点都要放),这里我放到flink安装包的jar文件夹下;
2.命令行执行job:
[atguigu@hadoop1 bin]$ ./flink run -c com.atguigu.flink.dataStreamWordCount -p 2 /opt/module/flink-1.10.0/jar/filnktest-1.0-SNAPSHOT.jar hadoop1 7777
Job has been submitted with JobID ea6c1a229eaeb9299d5816a63ad2b874
3.出现job has been submitted 说明已经提交,可以在http://localhost:8081/查看

YARN模式提交JOB
以Yarn模式部署Flink任务时,要求Flink是有Hadoop支持的版本,Hadoop环境需要保证版本在2.2以上,并且集群中安装有HDFS服务。
这里我之前已经有了HDFS集群,现在将flink的hadoop支持jar包放到flink的lib目录下:

Flink提供了两种在yarn上运行的模式,分别为Session-Cluster和Per-Job-Cluster模式。
1) Session-cluster 模式:
Session-Cluster模式需要先启动集群,然后再提交作业,接着会向yarn申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作业共享Dispatcher和ResourceManager;共享资源;适合规模小执行时间短的作业。
在yarn中初始化一个flink集群,开辟指定的资源,以后提交任务都向这里提交。这个flink集群会常驻在yarn集群中,除非手工停止。
2) Per-Job-Cluster 模式:
一个Job会对应一个集群,每提交一个作业会根据自身的情况,都会单独向yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常 提交和运行。独享Dispatcher和ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。
每次提交都会创建一个新的flink集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。
Session-cluster 模式
- 启动hadoop集群:
2)启动yarn-session:
./yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d
其中:
-n(–container):TaskManager的数量。
-s(–slots): 每个TaskManager的slot数量,默认一个slot一个core,默认每个taskmanager的slot的个数为1,有时可以多一些taskmanager,做冗余。
-jm:JobManager的内存(单位MB)。
-tm:每个taskmanager的内存(单位MB)。
-nm:yarn 的appName(现在yarn的ui上的名字)。
-d:后台执行。
注意------ 这里我启动时报了如下错误:
Container [pid=41355,containerID=container_1451456053773_0001_01_000002] is running beyond physical memory limits.
Current usage: 2.0 GB of 2 GB physical memory used; 5.2 GB of 4.2 GB virtual memory used. Killing container.
Dump of the process-tree for container_1451456053773_0001_01_000002 : |- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS)
SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE |- 41538 41355 41355 41355 (java) 3092 243 5511757824 526519
/usr/jdk64/jdk1.7.0_67/bin/java -server -XX:NewRatio=8 -Djava.net.preferIPv4Stack=true
-Dhadoop.metrics.log.level=WARN -Xmx4506m
-Djava.io.tmpdir=/diskb/hadoop/yarn/local/usercache/hdfs/appcache/application_1451456053773_0001/container_1451456053773_0001_01_000002/tmp
-Dlog4j.configuration=container-log4j.properties
-Dyarn.app.container.log.dir=/diska/hadoop/yarn/log/application_1451456053773_0001/container_1451456053773_0001_01_000002
-Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA
org.apache.hadoop.mapred.YarnChild 10.111.32.92 61224 attempt_1451456053773_0001_m_000000_0 2 |- 41355 37725 41355
通过查找资料在网上看到了这个大神的文章,最后解决了:https://blog.csdn.net/u012042963/article/details/53099638
解决办法:
- 在启动Yarn是调节虚拟内存率或者应用运行时调节内存大小:
修改etc/hadoop/yarn-site.xml
yarn.nodemanager.vmem-pmem-ratio
3.1
- 或者关闭虚拟内存检查:
修改etc/hadoop/yarn-site.xml
yarn.nodemanager.vmem-check-enabled
false
如下为启动成功日志:

最后会有一个jobManager Web 地址:
打开它,我们可以监控该flink集群下执行的任务了:

这里提交一个上面的单词统计任务,提交成功给出一个JobID:

通过WEB界面我们可以看到该job在执行了:

通过nc输入一些单词:

我们在taskManager下的控制台可以看到输出的统计结果:

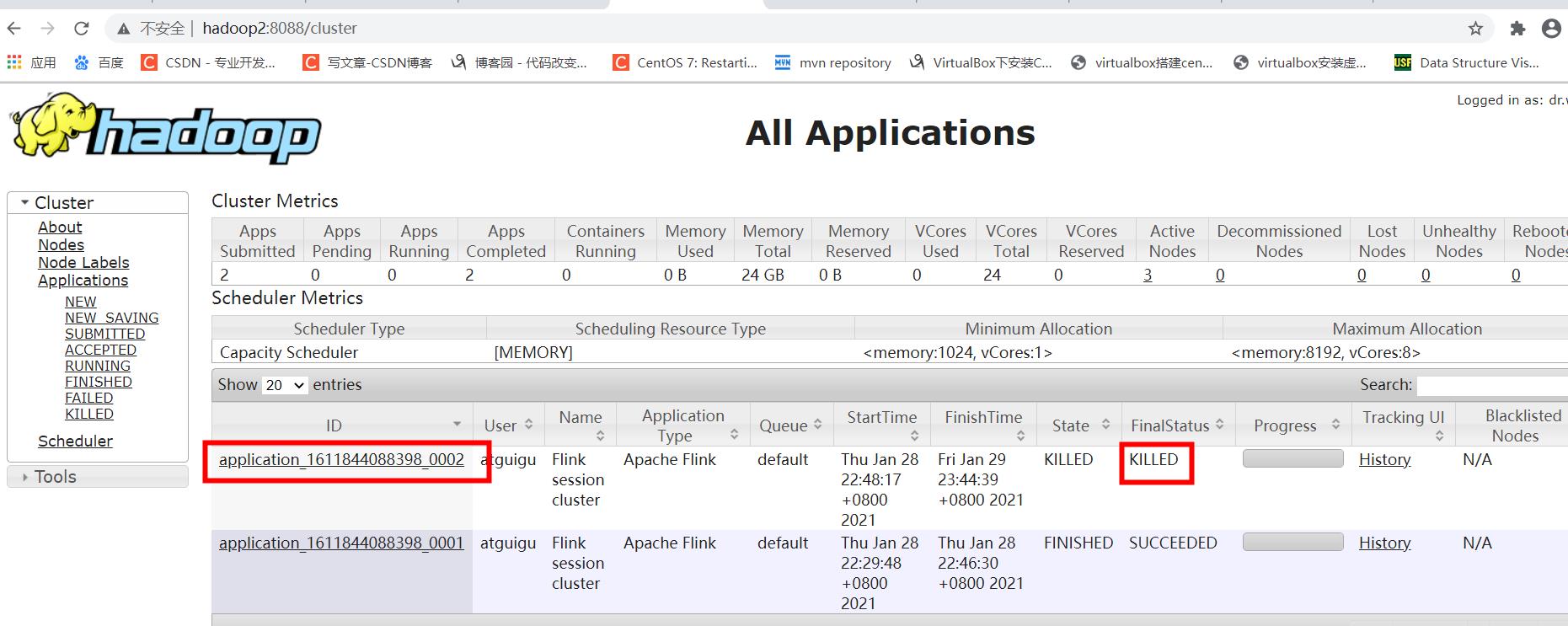
3)关闭yarn-session:
yarn application --kill application_1611844088398_0002

Per-Job-Cluster 模式
1)启动hadoop集群(略)
2)不启动yarn-session,直接执行job
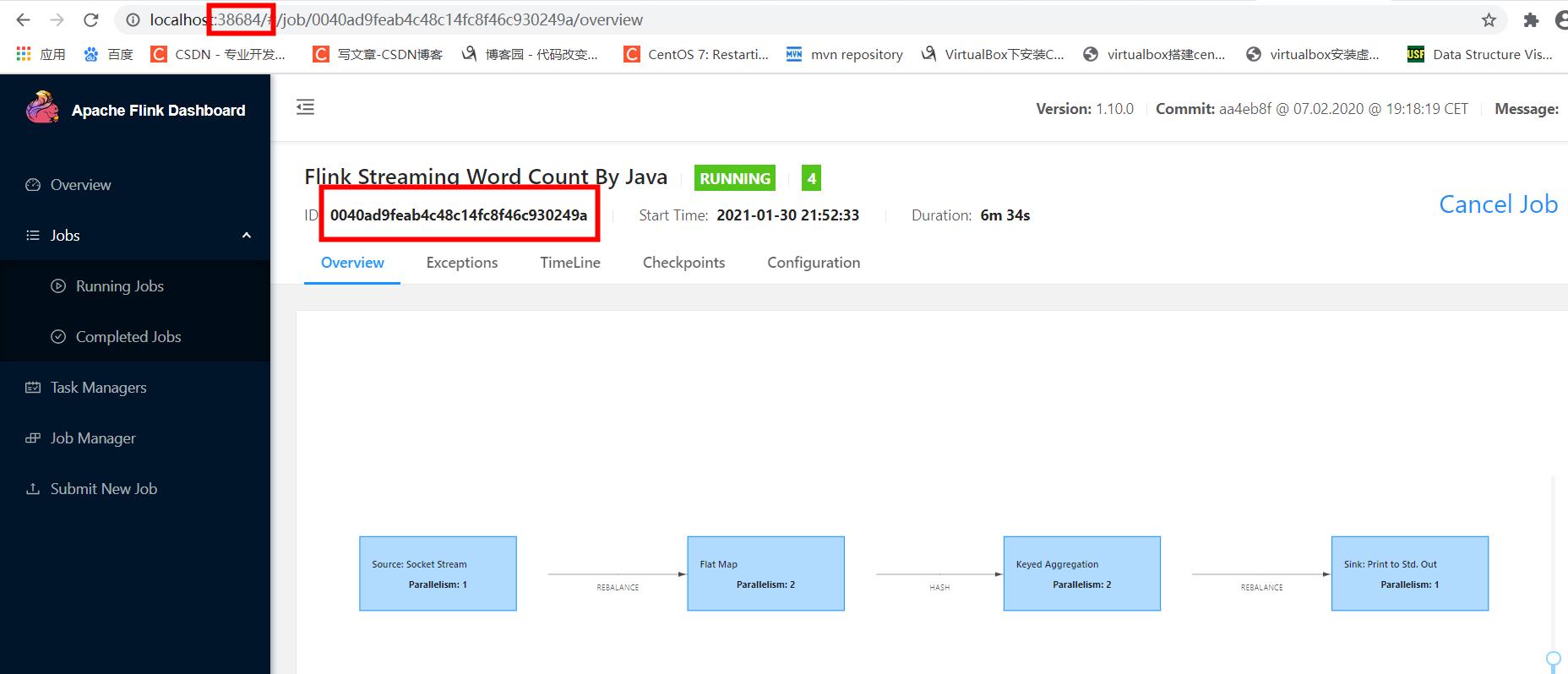
[atguigu@hadoop1 flink-1.10.0]$ flink run –m yarn-cluster -c com.atguigu.flink.dataStreamWordCount /opt/module/flink-1.10.0/jar/filnktest-1.0-SNAPSHOT.jar hadoop1 7777

打开提交job给出的web地址,可以看到job的运行信息:
任务提交参数讲解:相对于 Yarn-Session 参数而言,只是前面加了 y:
a、 -yn,–container 表示分配容器的数量,也就是 TaskManager 的数量。
b、 -d,–detached:设置在后台运行。
c、 -yjm,–jobManagerMemory:设置 JobManager 的内存,单位是 MB。
d、 -ytm,–taskManagerMemory:设置每个 TaskManager 的内存,单位是 MB。
e、 -ynm,–name:给当前 Flink application 在 Yarn 上指定名称。
f、 -yq,–query:显示 yarn 中可用的资源(内存、cpu 核数)
g、 -yqu,–queue :指定 yarn 资源队列
h、 -ys,–slots :每个 TaskManager 使用的 Slot 数量。
i、 -yz,–zookeeperNamespace:针对 HA 模式在 Zookeeper 上创建 NameSpace
j、 -yid,–applicationID : 指定 Yarn 集群上的任务 ID,附着到一个后台独立运行的 Yarn Session 中。
并行度拓展
其中的关系如下:假设集群中有一台master,k台slave节点。
Flink-conf.yaml中有两个重要的参数:
taskmanager.numberOfTaskSlots,The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
parallelism.default,The parallelism used for programs that did not specify and other parallelism.
前者指定了每个taskmanager提供的slot个数,后者的指定的程序默认的并行度。两者之间的关系为:
p a r a l l e l i s m . d e f a u l t < = k ( t h e N u m b e r O f t a s k m a n a g e r ) ∗ t a s k m a n a g e r . n u m b e r O f T a s k S l o t s parallelism.default<=k(theNumber Of taskmanager)*taskmanager.numberOfTaskSlotsparallelism.default<=k(theNumberOftaskmanager)∗taskmanager.numberOfTaskSlots
否则程序运行时候将不会得到足够多的slot而报错。
总之就是,slot提供资源,越多越好,并行度不能超过slot总上限。
1、TaskManager 和 Slot
Flink的每个TaskManager为集群提供solt。 solt的数量通常与每个TaskManager节点的可用CPU内核数成比例。一般情况下你的slot数是你每个节点的cpu的核数。
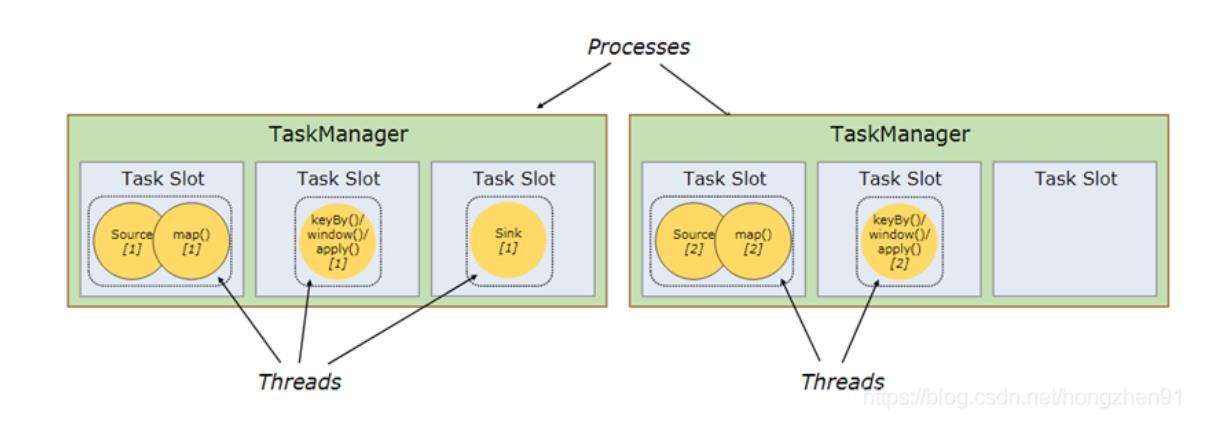
Slot 是进程,如果使用Flink on Yarn 模式不需要考虑资源的配置。
2、并行度(Parallel)
一个Flink程序由多个任务组成(source、transformation和 sink)。 一个任务由多个并行的实例(线程)来执行, 一个任务的并行实例(线程)数目就被称为该任务的并行度。
2.1、并行度(Parallel)的设置
一个任务的并行度设置可以从多个层次指定
Operator Level(算子层次)
Execution Environment Level(执行环境层次)
Client Level(客户端层次)
System Level(系统层次)
2.2、Operator Level(算子层面)
一个算子、数据源和sink的并行度可以通过调用 setParallelism()方法来指定

2.3、Execution Environment Level(全局层面)
执行环境(任务)的默认并行度可以通过调用setParallelism()方法指定。为了以并行度3来执行所有的算子、数据源和data sink, 可以通过如下的方式设置执行环境的并行度:
执行环境的并行度可以通过显式设置算子的并行度而被重写:

2.4、Client Level
并行度可以在客户端将job提交到Flink时设定。
对于CLI客户端,可以通过-p参数指定并行度
./bin/flink run -p 10 WordCount-java.jar
2.5、System Level(尽量不使用)
在系统级可以通过设置flink-conf.yaml文件中的parallelism.default属性来指定所有执行环境的默认并行度
2.6、并行度图解
Example1 :

解释:
在fink-conf.yaml中 taskmanager.numberOfTaskSlots 默认值为1,即每个Task Manager上只有一个Slot ,此处是3
Example中,WordCount程序设置了并行度为1,意味着程序 Source、Reduce、Sink在一个Slot中,占用一个Slot
Example2 :
解释:
通过设置并行度为2后,将占用2个Slot

Example3 :
解释: 通过设置并行度为9,将占用9个Slot
Example4 :
解释:通过设置并行度为9,并且设置sink的并行度为1,则Source、Reduce将占用9个Slot,但是Sink只占用1个Slot
以上是关于FLINK安装及提交任务的主要内容,如果未能解决你的问题,请参考以下文章