Python爬虫 scrapy -- CrawlSpider链接提取器scrapy 数据保存到数据库
Posted CodeJiao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫 scrapy -- CrawlSpider链接提取器scrapy 数据保存到数据库相关的知识,希望对你有一定的参考价值。
1. CrawlSpider链接提取器
- 继承自scrapy.Spider
- 独门秘笈
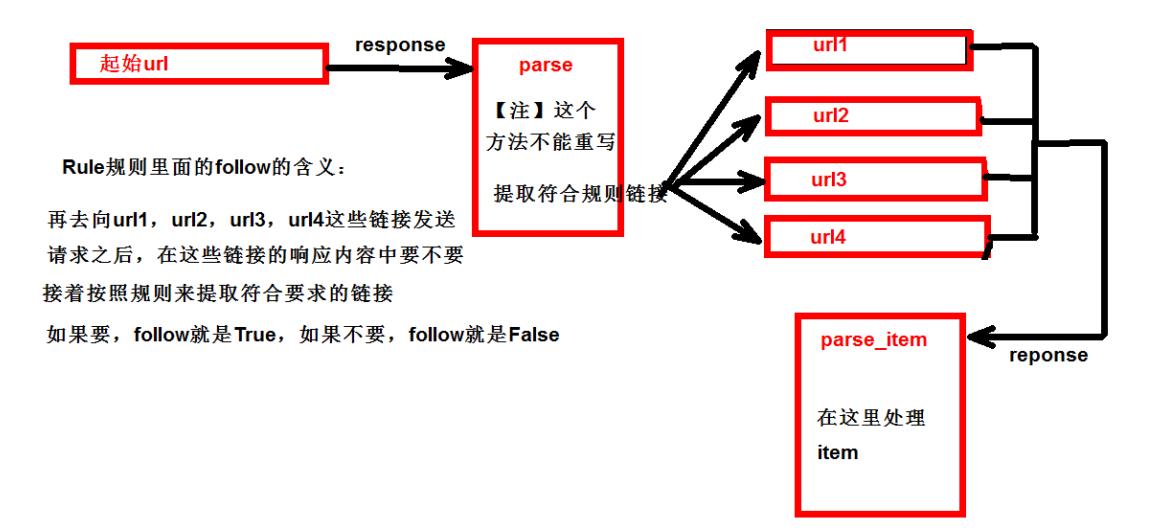
- CrawlSpider可以定义规则,再解析html内容的时候,可以根据链接规则提取出指定的链接,然后再向这些链接发送请求。
- 所以,如果有需要跟进链接的需求,意思就是爬取了网页之后,需要提取链接再次爬取,使用CrawlSpider是非常合适的。
2. 当当网案例
2.1 访问当当网
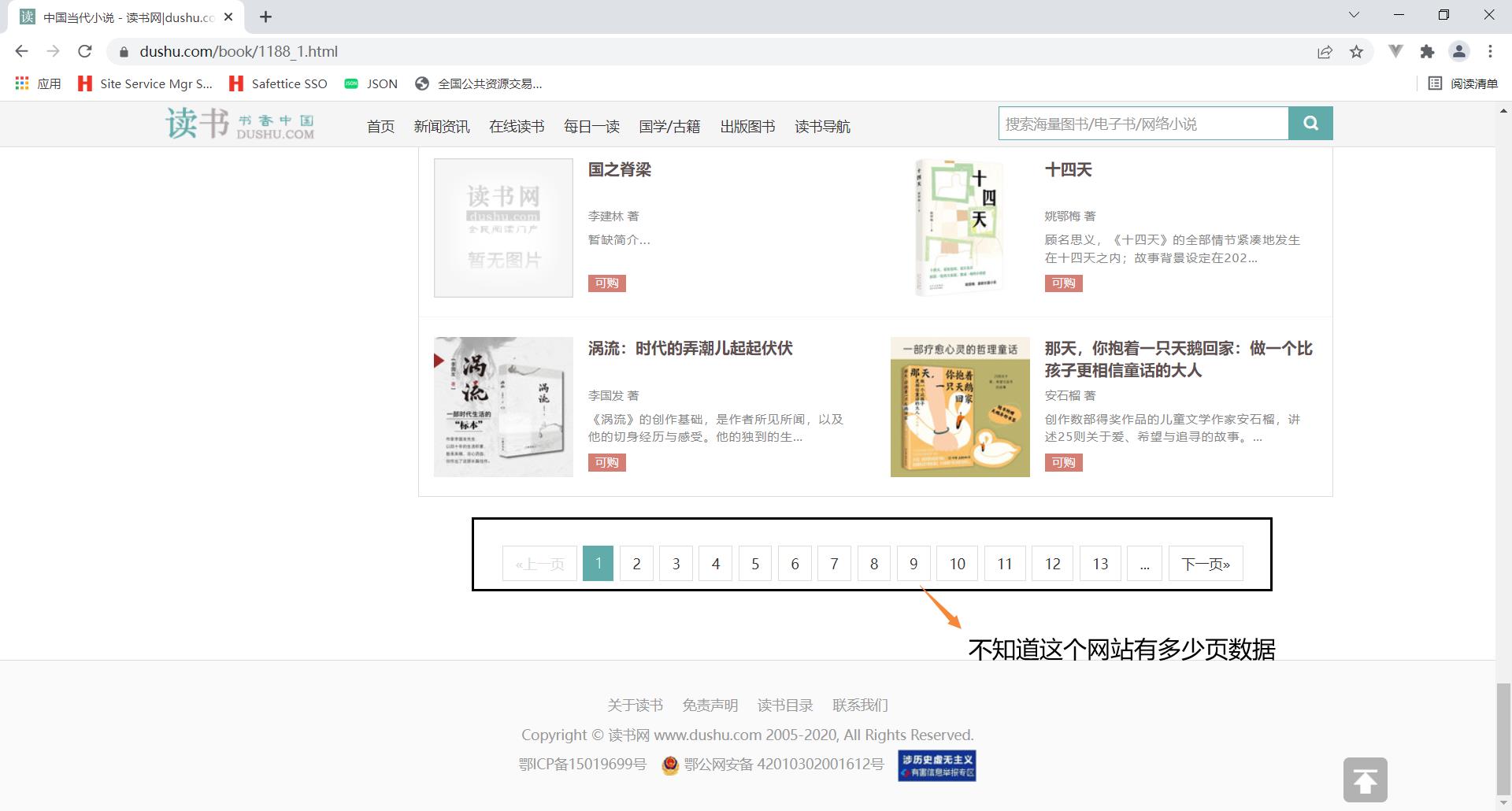
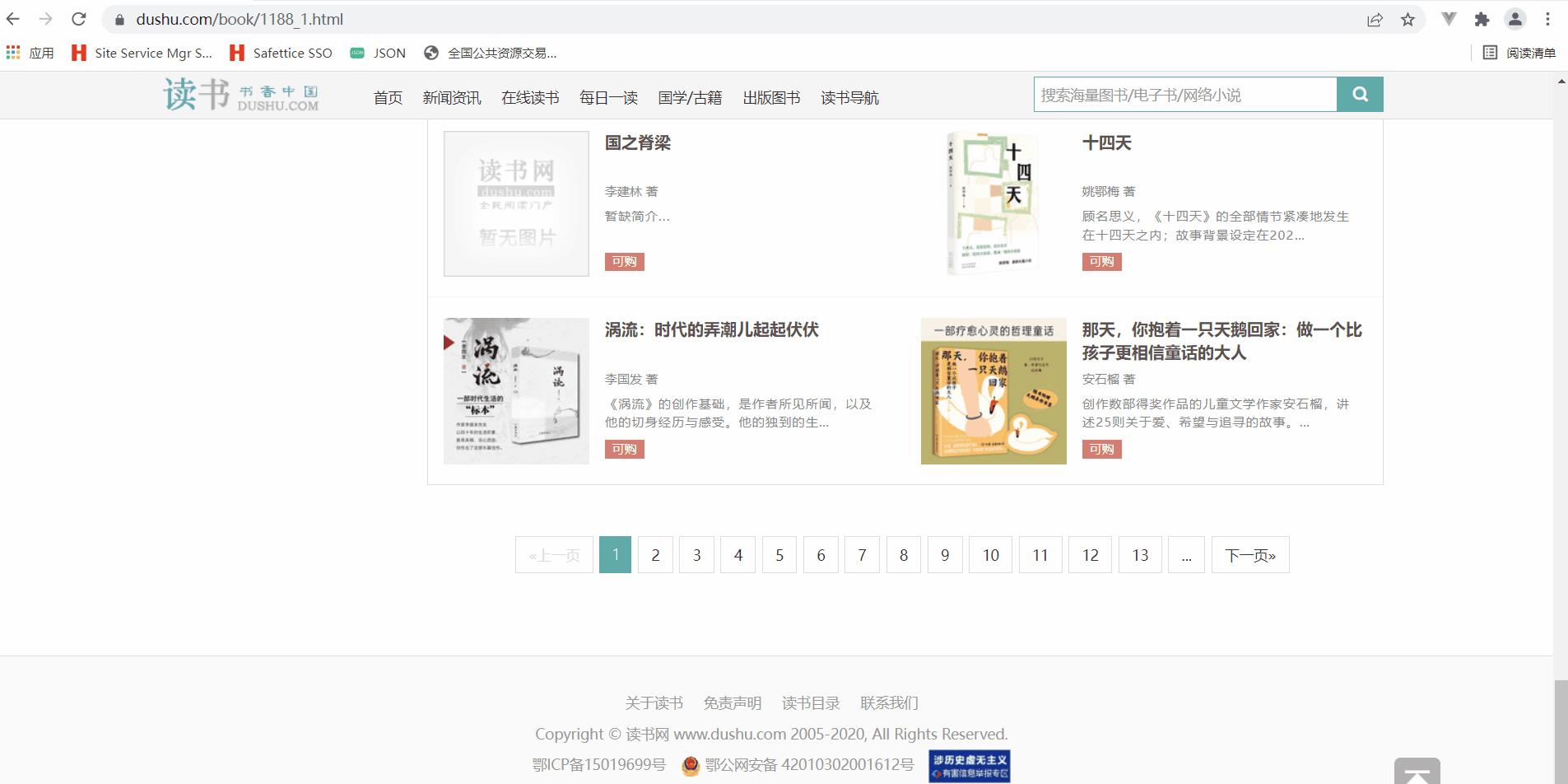
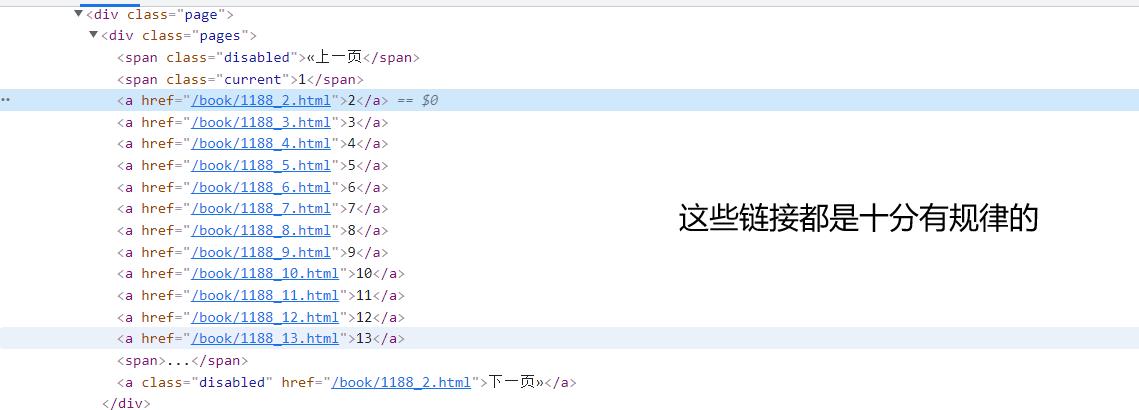
我们可以把所有符合规则的链接都提取出来,然后进行访问。
2.2 我们用scrapy shell进行链接提取
打开终端输入:
scrapy shell https://www.dushu.com/book/1188_1.html

导入链接提取器:
from scrapy.linkextractors import LinkExtractor
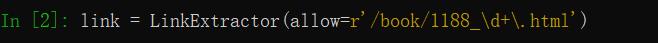
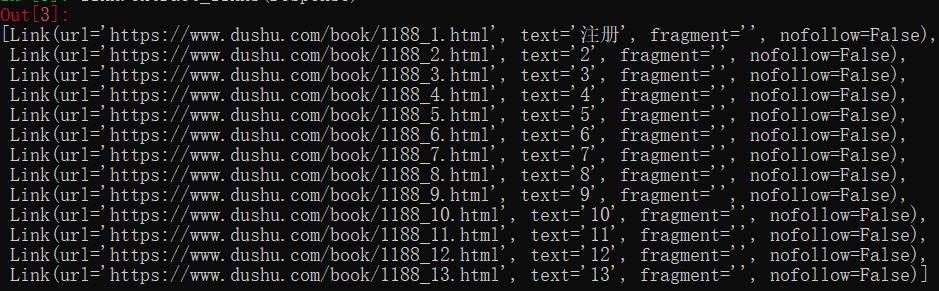
2.3 提取链接的规则说明
allow使用的比较多的。
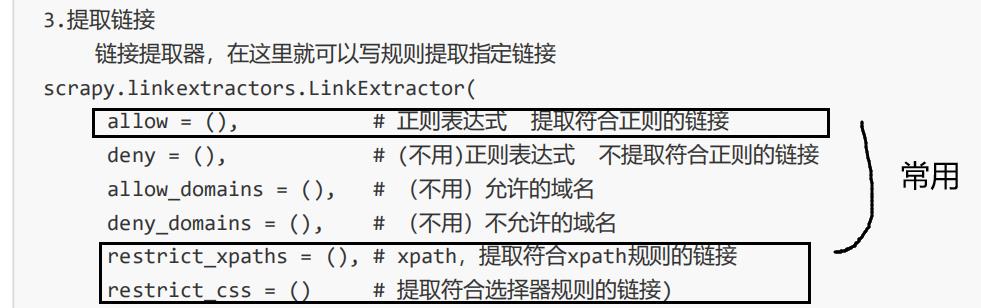


2.4 创建爬虫项目
1.创建项目:scrapy startproject 项目名称,我这里输入的是scrapy startproject dushuproject


-
跳转到spiders路径
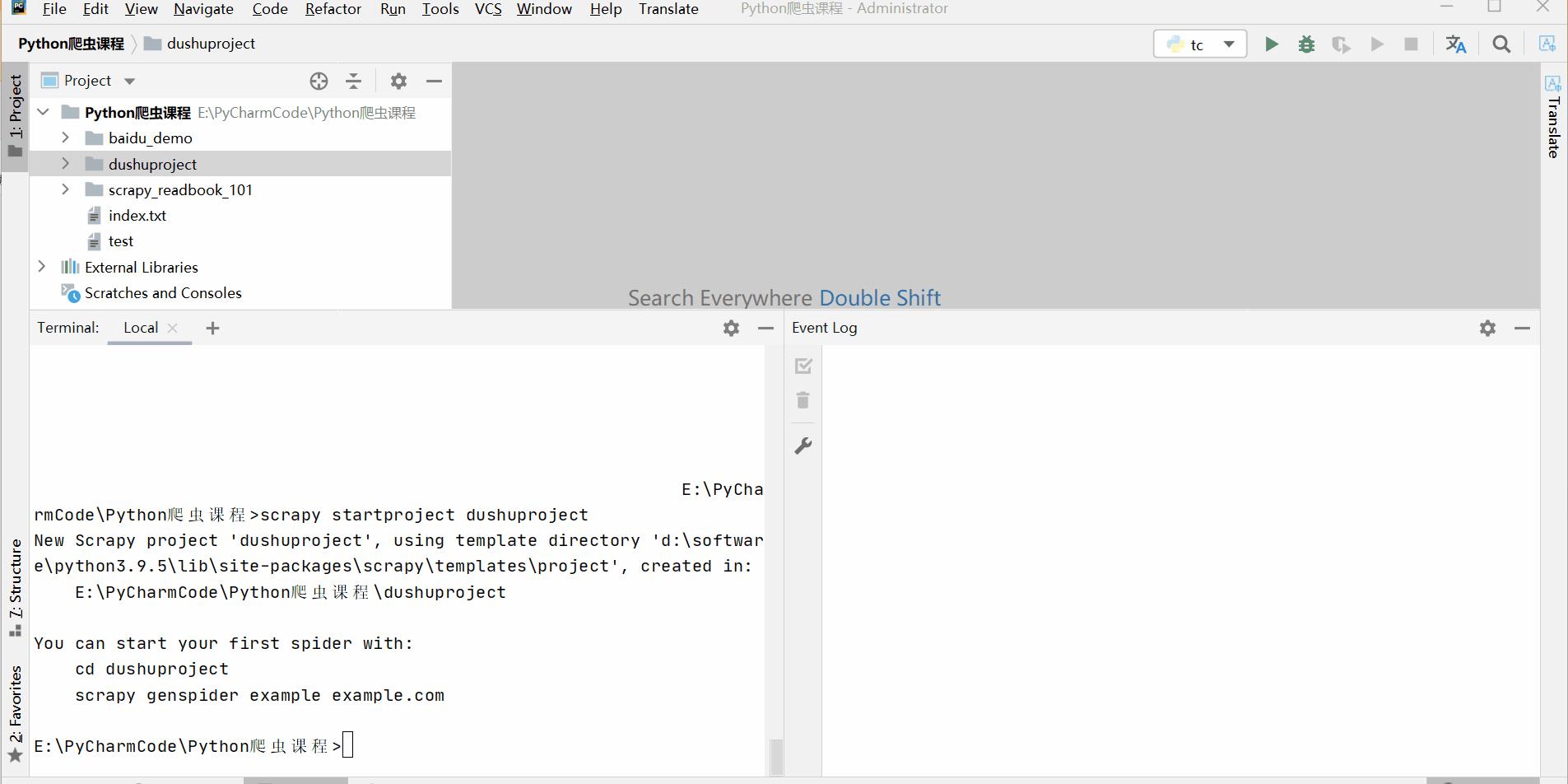
-
创建爬虫类:
scrapy genspider ‐t crawl 爬虫文件的名字 爬取的域名,我这里输入的是scrapy genspider -t crawl read www.dushu.com


2.6 定义数据结构
因为我们要爬取图片的路径和书籍的名称,所以我们先定义相应的数据结构。

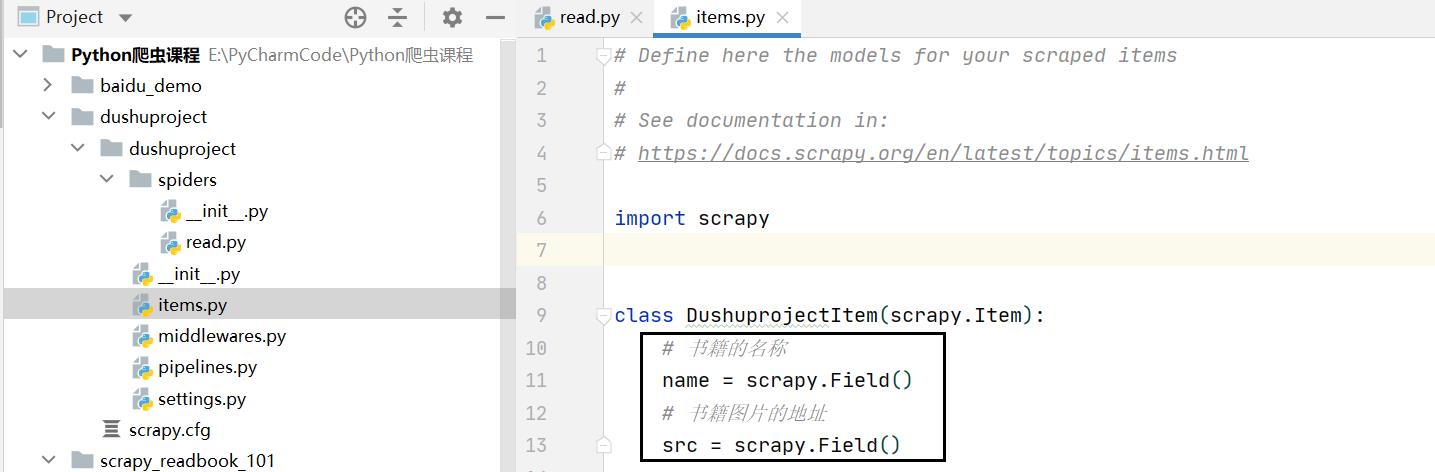
# 书籍的名称
name = scrapy.Field()
# 书籍图片的地址
src = scrapy.Field()
2.7 编写核心爬虫文件
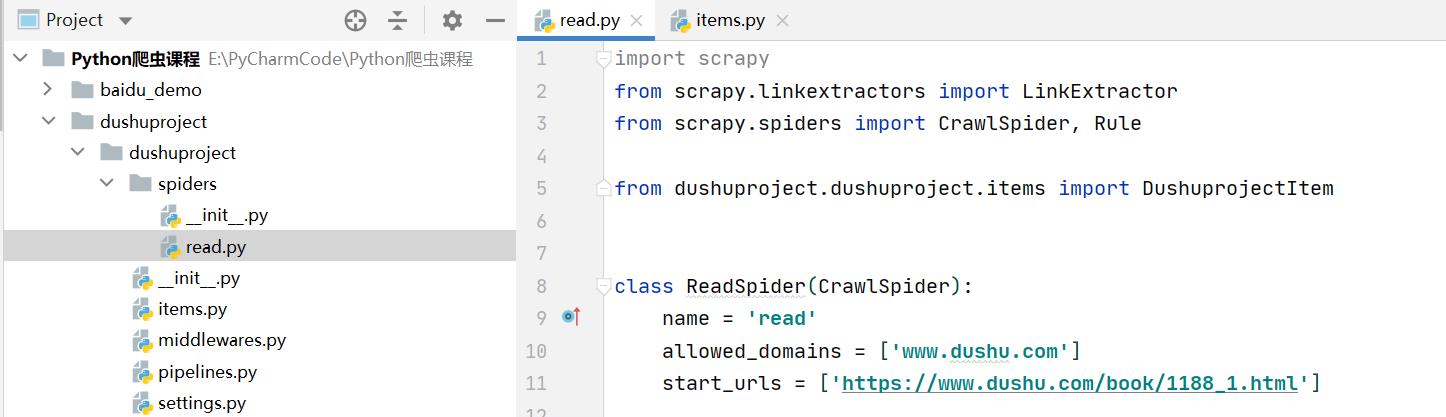
read.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from dushuproject.items import DushuprojectItem
class ReadSpider(CrawlSpider):
name = 'read'
allowed_domains = ['www.dushu.com']
# 注意:这里是爬取的首页的数据的链接!记得修改一下
start_urls = ['https://www.dushu.com/book/1188_1.html']
rules = (
Rule(LinkExtractor(allow=r'/book/1188_\\d+.html'),
callback='parse_item',
# 这里值为False表示把已有的符合规则的链接爬取完后就不再往后面爬了(这里是13页数据)
follow=False),
)
def parse_item(self, response):
img_list = response.xpath('//div[@class="bookslist"]//img')
for img in img_list:
name = img.xpath('./@data-original').extract_first()
src = img.xpath('./@alt').extract_first()
book = DushuprojectItem(name=name, src=src)
yield book
2.8 开启管道下载文件
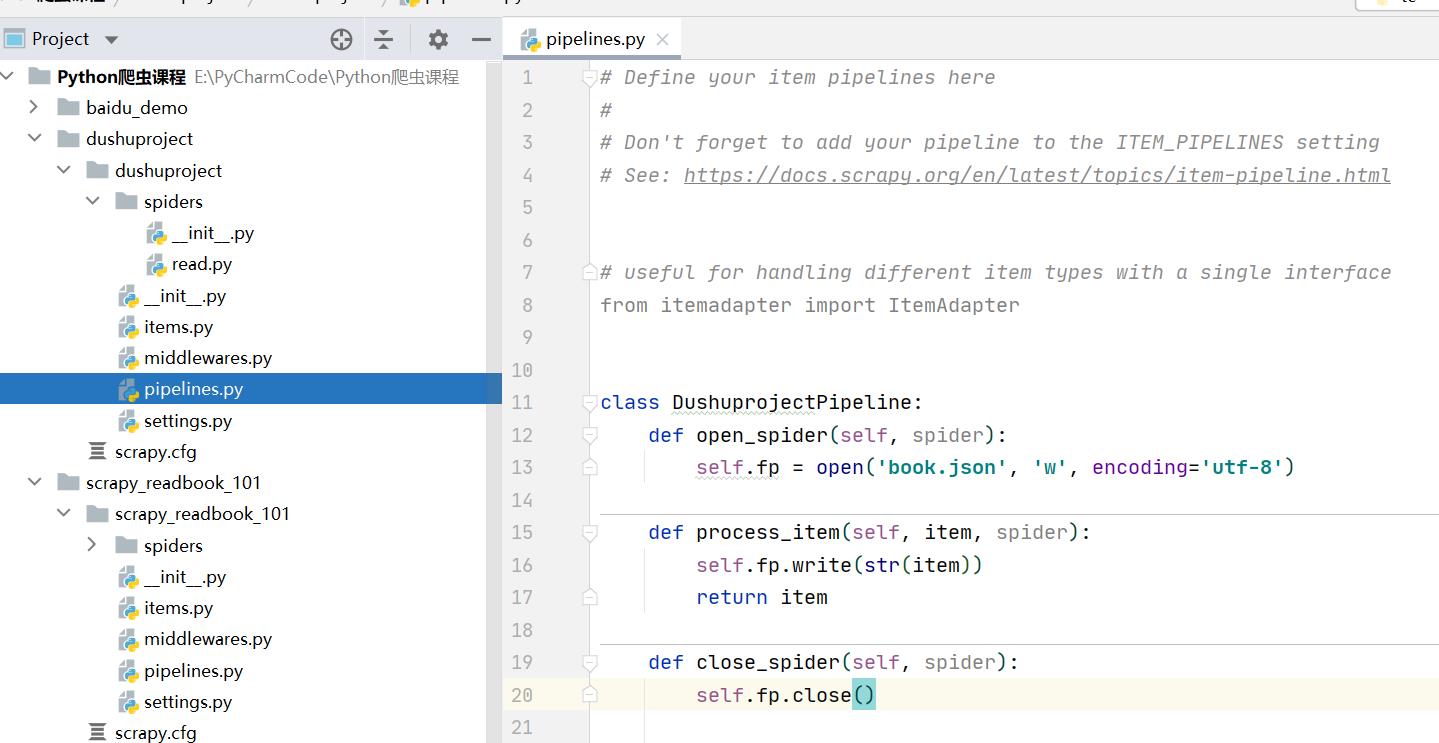
pipelines.py
class DushuprojectPipeline:
def open_spider(self, spider):
self.fp = open('book.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self, spider):
self.fp.close()
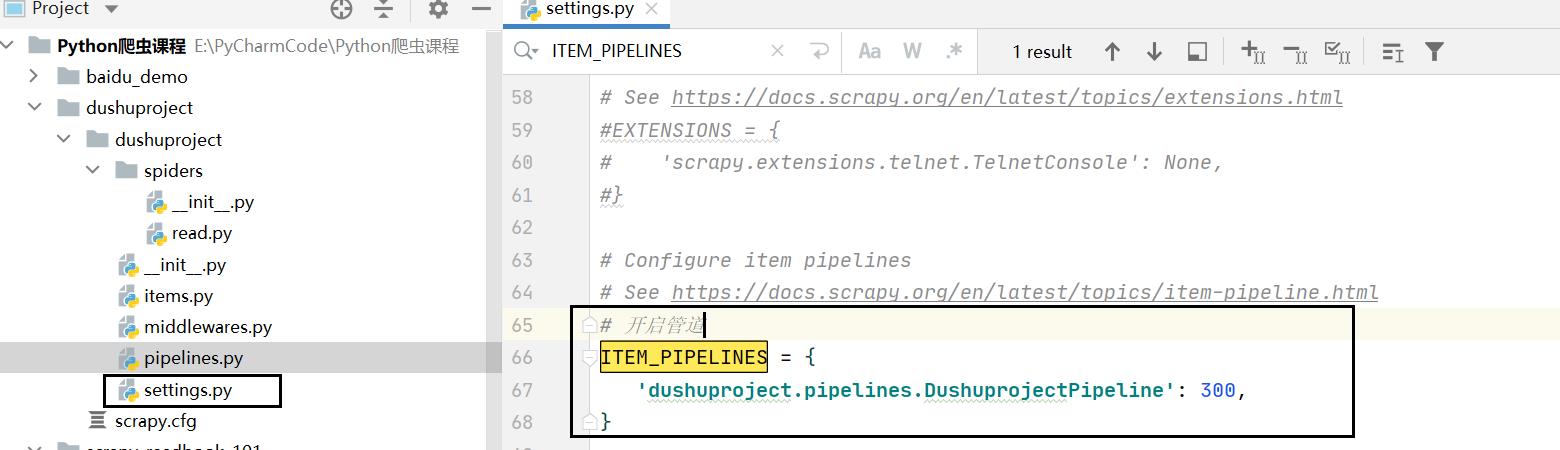
settings.py
# 开启管道
ITEM_PIPELINES =
'dushuproject.pipelines.DushuprojectPipeline': 300,
2.9 运行测试
k控制台输入scrapy crawl read

3. 案例拓展
3.1 下载全部数据
可以看见上一次下载了450行数据。

这一次我们要爬取全部的数据。操作很简单,我们把follow改为True即可。
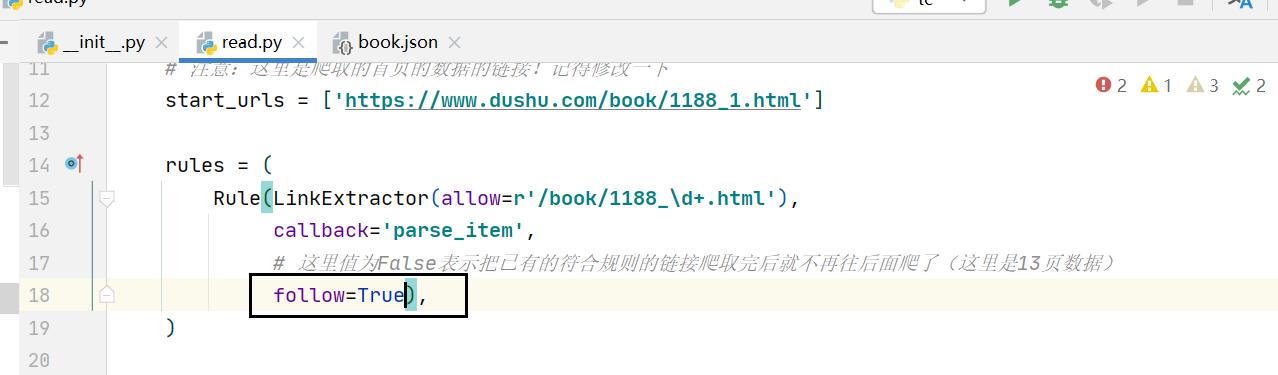
再次运行程序:
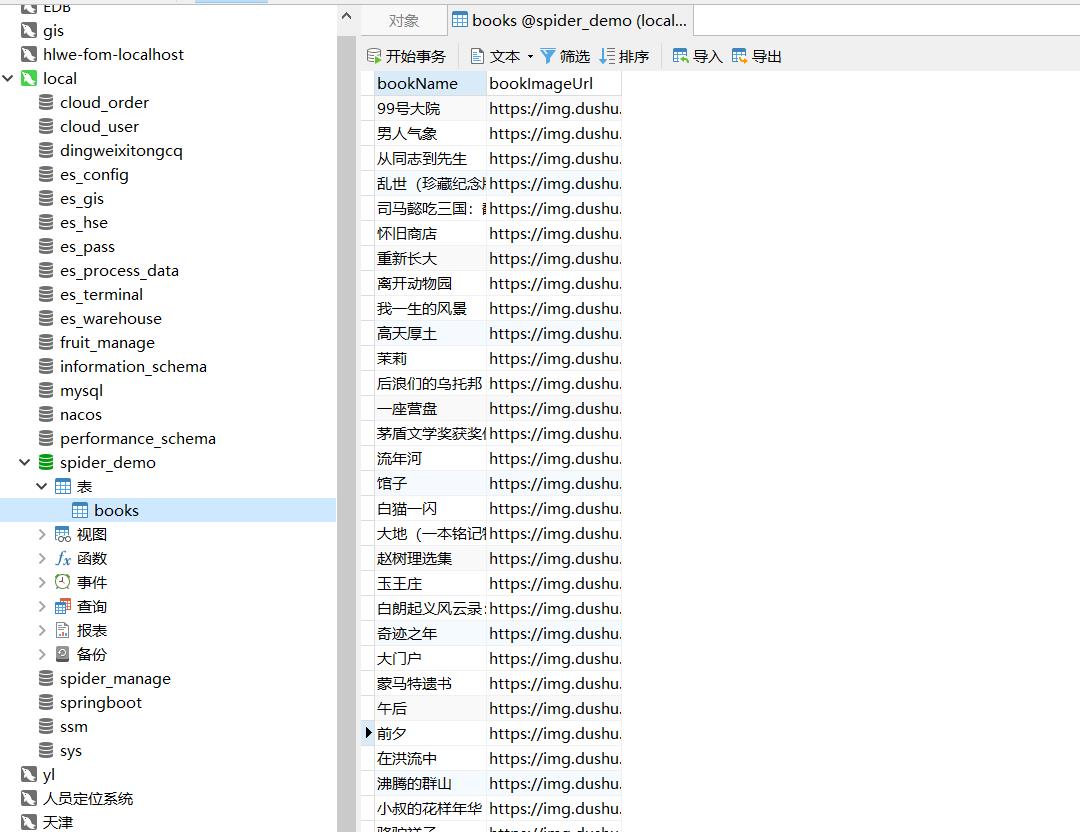
3.2 把数据保存到数据库
准备工作:py环境安装pymysql
pip install pymysql
3.2.1 数据库建表和数据库
建表SQL:
CREATE DATABASE spider_demo;
USE spider_demo;
CREATE TABLE IF NOT EXISTS `books`(
`bookName` VARCHAR(30) COMMENT "学号",
`bookImageUrl` VARCHAR(100) COMMENT "姓名"
)ENGINE =INNODB DEFAULT CHARSET=utf8

3.2.2 我们先在settings文件里面配置数据库的信息
settings.py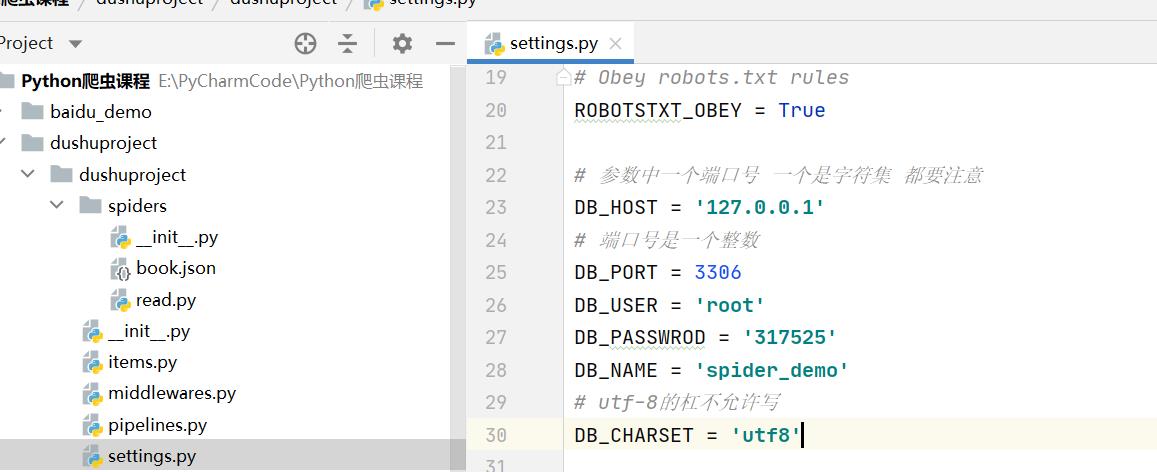
# 参数中一个端口号 一个是字符集 都要注意
DB_HOST = '127.0.0.1'
# 端口号是一个整数
DB_PORT = 3306
DB_USER = 'root'
DB_PASSWROD = '317525'
DB_NAME = 'spider_demo'
# utf-8的杠不允许写
DB_CHARSET = 'utf8'
3.2.3 开启管道下载数据
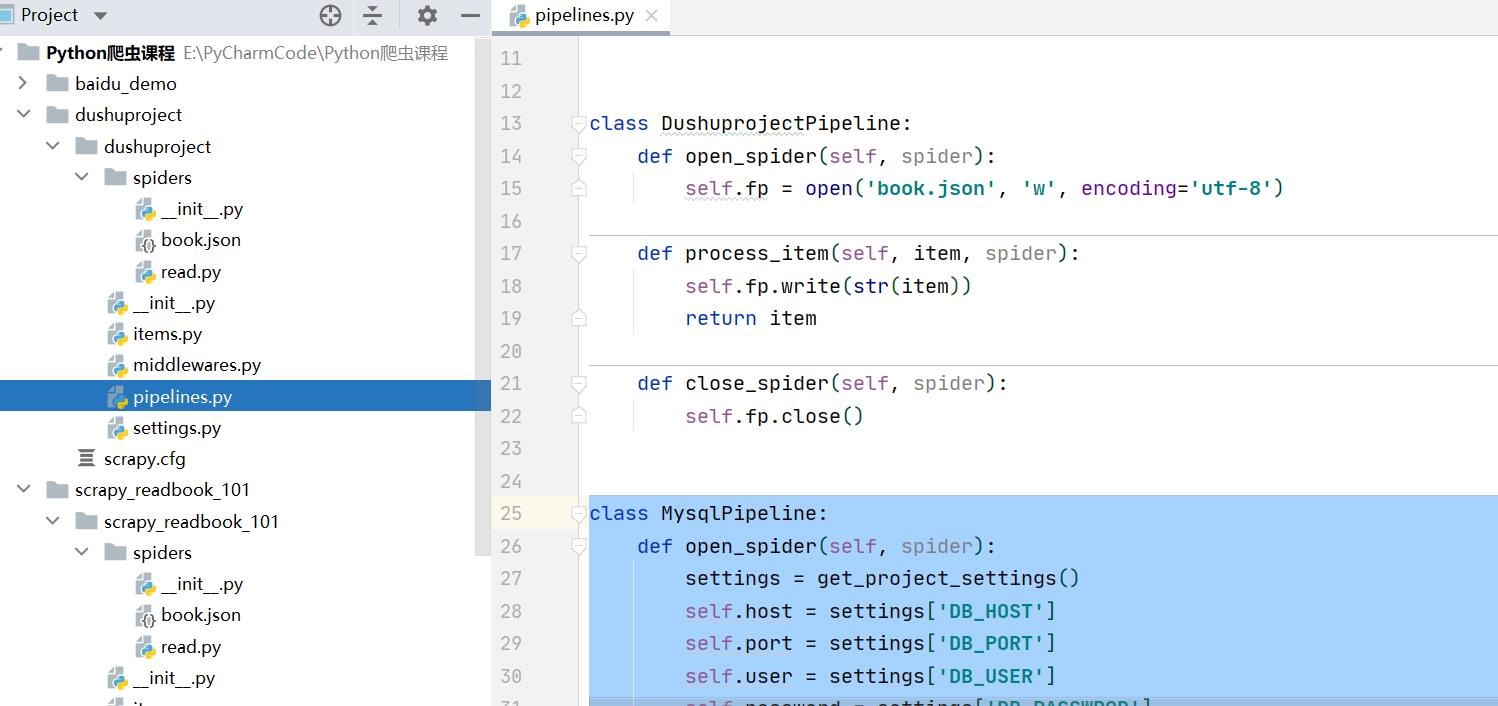
import pymysql
from scrapy.utils.project import get_project_settings
class DushuprojectPipeline:
def open_spider(self, spider):
self.fp = open('book.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self, spider):
self.fp.close()
class MysqlPipeline:
def open_spider(self, spider):
settings = get_project_settings()
self.host = settings['DB_HOST']
self.port = settings['DB_PORT']
self.user = settings['DB_USER']
self.password = settings['DB_PASSWROD']
self.name = settings['DB_NAME']
self.charset = settings['DB_CHARSET']
self.connect()
def connect(self):
self.conn = pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
db=self.name,
charset=self.charset
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = 'insert into books(bookName,bookImageUrl) values("","")'.format(item['src'], item['name'])
# 执行sql语句
self.cursor.execute(sql)
# 提交
self.conn.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
设置文件开启Mysql的管道:

ITEM_PIPELINES =
'dushuproject.pipelines.DushuprojectPipeline': 300,
'dushuproject.pipelines.MysqlPipeline': 200,
运行项目:
3.3 CrawlSpider原理
以上是关于Python爬虫 scrapy -- CrawlSpider链接提取器scrapy 数据保存到数据库的主要内容,如果未能解决你的问题,请参考以下文章