月产10000个中药科普短视频方法,Python编程AI教程
Posted Mr数据杨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了月产10000个中药科普短视频方法,Python编程AI教程相关的知识,希望对你有一定的参考价值。
你没看错1个月做1万个科普短视频,其他编程语言和工具能不能做我不知道,但是用Python的 MoviePy 模块是可以做到的。
19年我还在学校的时候领导安排让我用pr做一个中医药的药材的科普短视频,那个玩意我实在搞不来,后来用爬虫抓了一下中医药网的中药材数据,发现数据都是固定的格式,既然是重复的工作那么用 Python 脚本就应该能批量生产了。
先来看一个成品的案例,制作耗时全自动5分钟左右。可以扩展思路类似这种科普类的视频都可以量产,如果有兴趣的话往下看实现方法。
YYSD 用Python能月产万个短视频的正确姿势 中医药篇
文章目录
软硬件、技能需求
- CPU最好是I7-8750以上,要不整体制作会非常慢
- Python版本3.6以上
- Moviepy模块暂时不支持GPU,因此显卡好坏无视
- PyEcharta模块的地图制作和图片渲染,因为视频要用到
- 常规的数据清洗处理操作,不然视频内容没法做
- 需要会用PPT制作素材,图片和视频这种
- 需要会写爬虫基础的就行Scrapy框架用不上
- 需要会操作Moviepy模块,不会的看我专栏里的对应介绍和操作方法
- 需要1-N个手机号,用于申请百度AI的免费API使用
- 需要有耐心,很多地方需要微调
数据获取
做视频的内容文稿自然是要有数据了,这种视频的数据是公开的,在药智数据上可以找到。
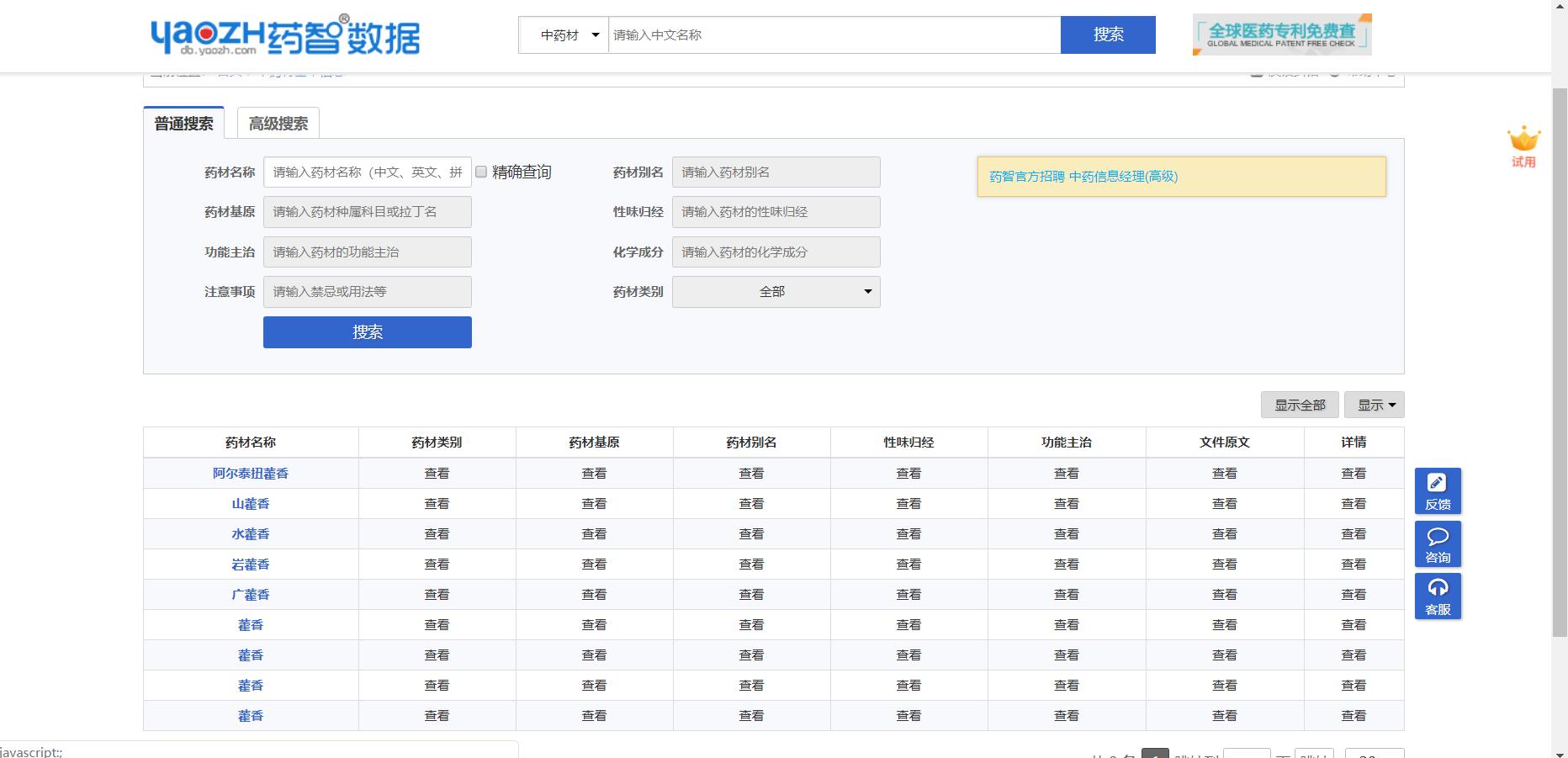
数据在这里,具体抓取方法很简单,Python写个爬虫脚本就搞定了,这个整体耗时1个钟头吧。最后的数据长这样,才发现咱们国家中药材居然有13000+种,真实开眼了。
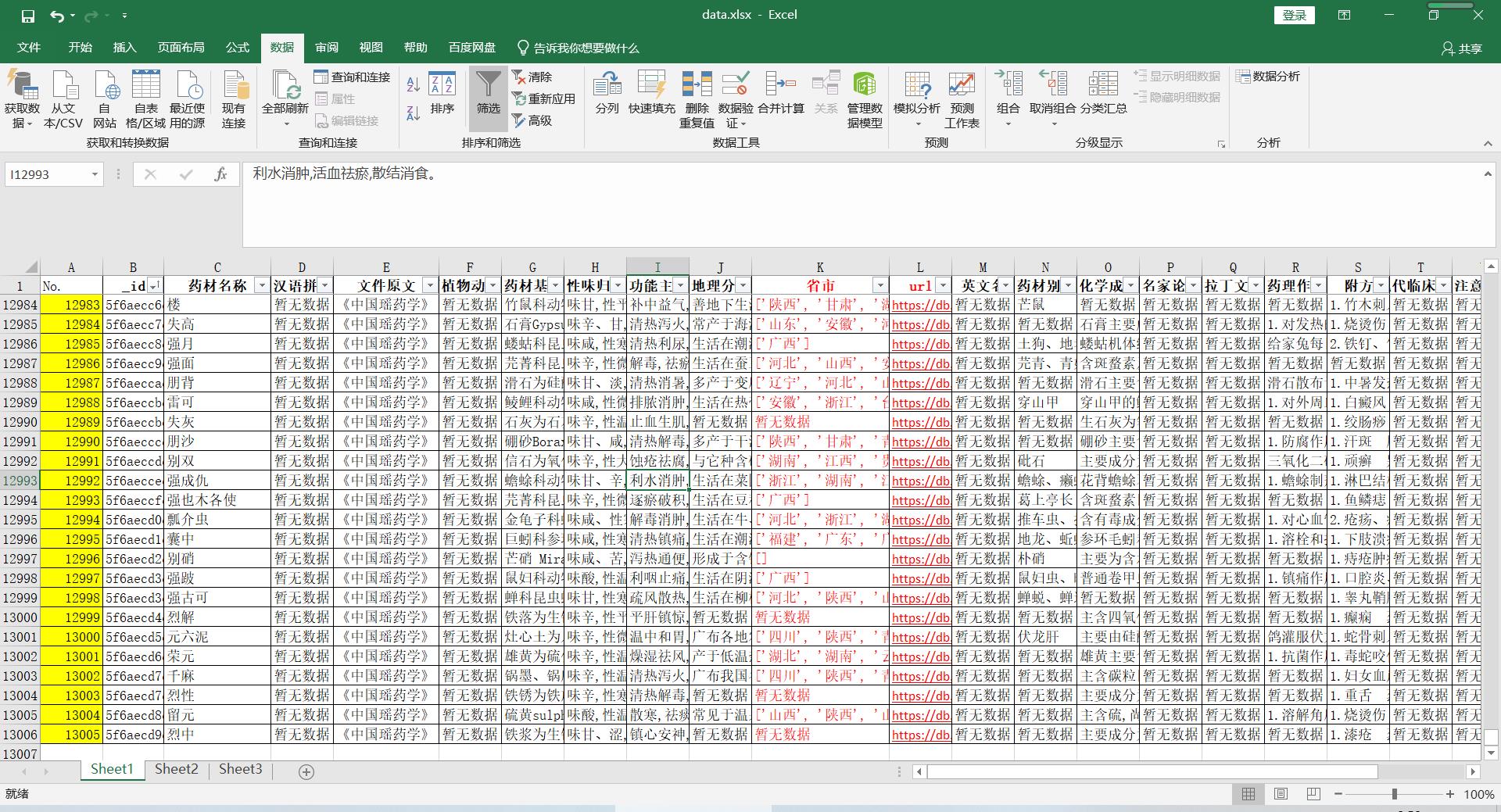
红色字体部分是通过excel表单提取的药材生长所在省市的名称、对应数据访问的网址页面。暂无数据的部分是原数据部分空白抓取后自动填充,这个后面会用到。
基础素材准备
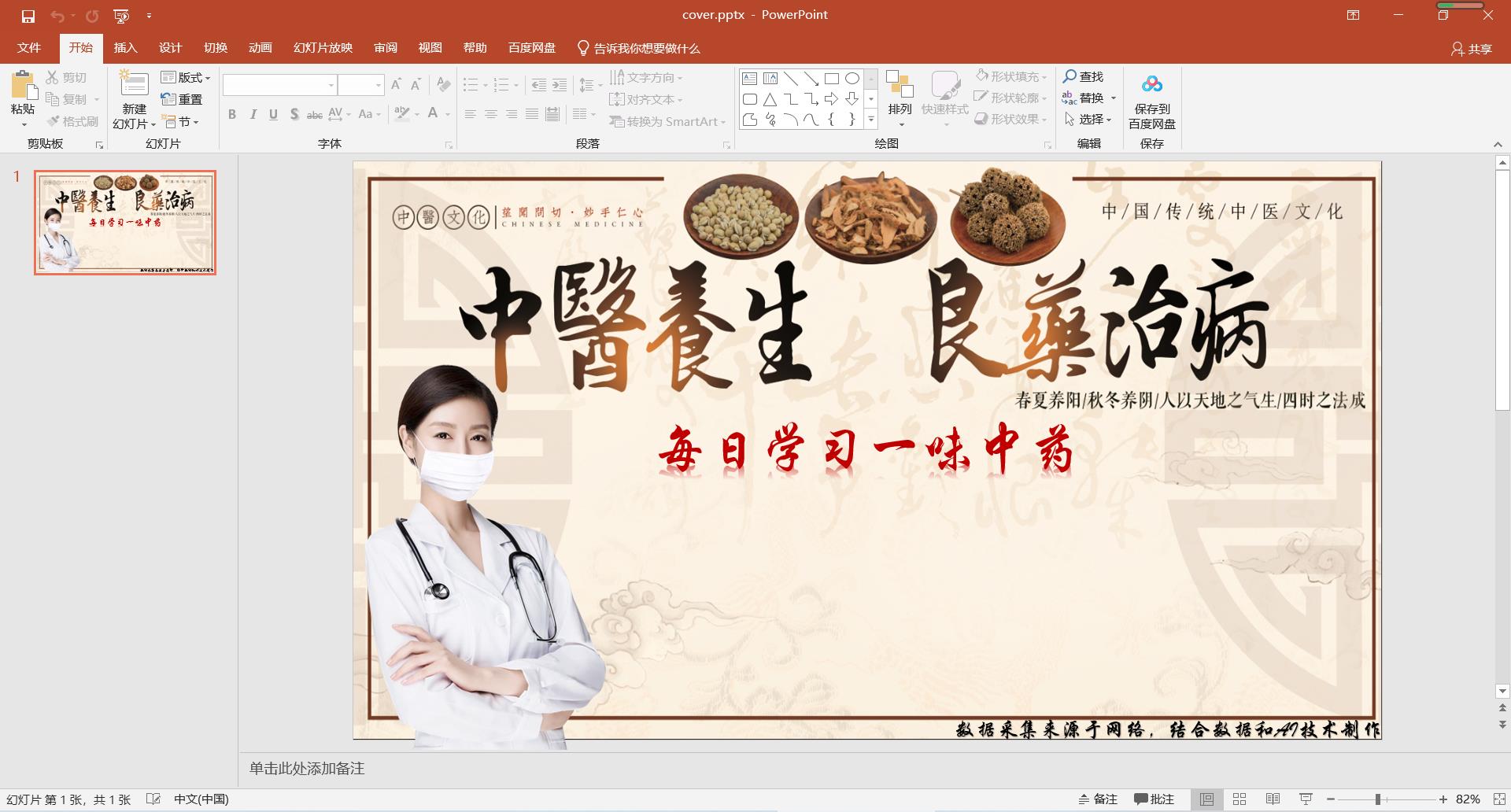
视频封面素材,固定模板的视频封面。这个东西用PPT做就行了,很简单。然后把制作好的保存成jpg图片。
水印制作,用图片工厂做一个也比较简单。记得保存成png格式。

其他通用素材图片,比如说处方、汤药的图片,毕竟中药的汤药熬制出来都差不多。
这些图片素材都放到 material_jpg\\base 目录下。
视频模板,这个也用PPT做就行了,然后保存成一段循环播放的视频,后面用代码切。然后将这个视频的模板切分成转场和部分2个。如果需要片尾视频自己搞一个就行了。
文字合成语音的API,随便拿个手机号申请百度AI的接口服务就行。不怕贵的话可以使用科大讯飞的。自行选择,代码会根据接口进行微调。自己不会的仔细看API文档,这点耐心要没有的话后面也不用看了。
流程与代码
了解业务处理制作流程有助于理解代码,或者流程了解了代码就很容易。
先看一下整体的工程目录。
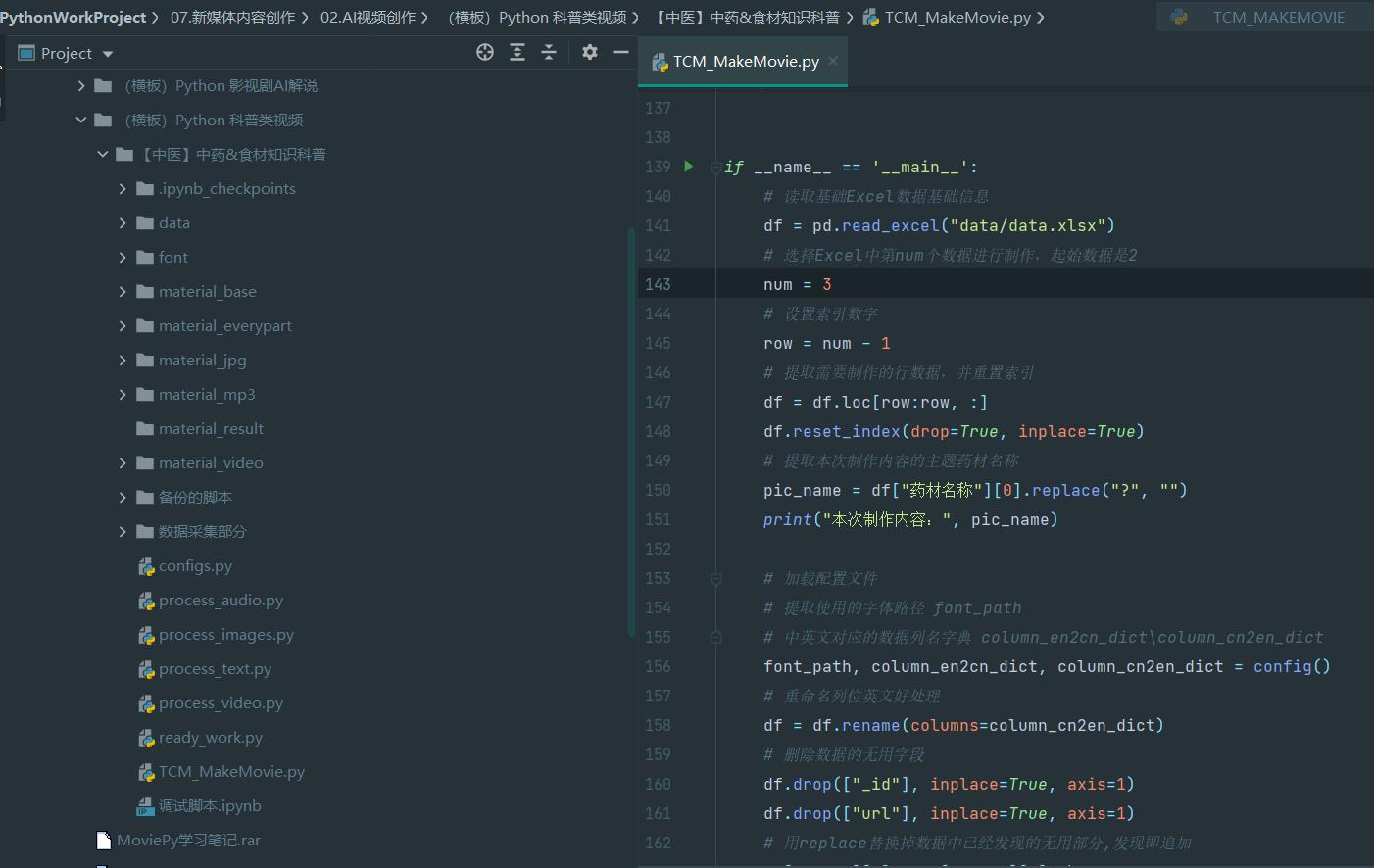
项目总体执行文件
- TCM_MakeMovie.py
# coding:utf-8
__author__ = 'Mr.数据杨'
__explain__ = '文件目录说明:' \\
'data:用于存放视频中生成内容的excel表格数据,以及AI抠图的日志文件' \\
'font:用于存放字体文件' \\
'material_base:用于存放视频素材片头、片尾、片中、过场的MP4' \\
'material_everypart:根据不同的内容存放算法生成的无语音part素材和封面' \\
'material_jpg:用于存放视频用使用的水印、封面、不同的内容按照规则生成的图片' \\
'material_mp3:用于存放百度AI生成的MP3文件' \\
'material_result:用于存放最终视频生成的结果文件,如果生成同样的内容需要将源文件删除' \\
'material_video:根据不同的内容存放算法生成的合成语音后part素材和封面、总合成的结果' \\
'备份脚本:该项目Debug的过程' \\
'' \\
'使用说明:' \\
'1.在material_jpg中创建内容的文件夹,名称为对应pic_name的名称' \\
'2.在互联网上采集对应内容的图片,改名pic_name.jpg格式' \\
'3.无脑启动脚本等material_result出结果' \\
'4.代码423行处,根据material_jpg的base的文件夹下fuyong、zhongzhi进行随机切换图片生成不同的内容,素材自行搞定' \\
'5.水印根据material_jpg的base下的logo.png进行更换' \\
'6.封面根据material_jpg的base下的cover.pptx进行操作生成base.jpg进行更换'
# 加载使用的三方安装包
import pandas as pd
# 加载自定义py方法
from configs import * # 工程配置数据
from ready_work import * # 工程启动准备工作
from process_images import * # 处理工程需要的图片数据
from process_audio import * # 处理工程需要的音频数据
from process_video import * # 处理工程需要的视频数据
if __name__ == '__main__':
# 读取基础Excel数据基础信息
df = pd.read_excel("data/data.xlsx")
# 选择Excel中第num个数据进行制作,起始数据是2
num = 3
# 设置索引数字
row = num - 1
# 提取需要制作的行数据,并重置索引
df = df.loc[row:row, :]
df.reset_index(drop=True, inplace=True)
# 提取本次制作内容的主题药材名称
pic_name = df["药材名称"][0].replace("?", "")
print("本次制作内容:", pic_name)
# 加载配置文件
# 提取使用的字体路径 font_path
# 中英文对应的数据列名字典 column_en2cn_dict\\column_cn2en_dict
font_path, column_en2cn_dict, column_cn2en_dict = config()
# 重命名列位英文好处理
df = df.rename(columns=column_cn2en_dict)
# 删除数据的无用字段
df.drop(["_id"], inplace=True, axis=1)
df.drop(["url"], inplace=True, axis=1)
# 用replace替换掉数据中已经发现的无用部分,发现即追加
df["QYFB"][0] = df["QYFB"][0]. \\
replace(" ", ""). \\
replace("生态环境", ""). \\
replace("资源分布", "")
# 填充无数据的部分内容
df = df.fillna("暂无数据")
# 创建单词视频会使用的制作目录,对应目录以药材名称pic_name为顶级目录
# 1.单条视频每个部分素材的目录 material_everypart
# 2.合成每个部分素材的目录以及素材全部合并的目录 material_video
# 3.单条视频使用的图片素材的目录 material_jpg
# 4.单条视频使用的音频素材的目录 material_mp3
MakeMaterialDir(pic_name)
# 避免重复制作素材数据发生错误,每次都清空原有旧的数据
# 1.清空单条视频每个部分素材目录 material_everypart
# 2.清空合成每个部分素材目录 material_video
# 3.清空单条视频使用的音频素材目录 material_mp3
CleanFiles(pic_name)
# 从百度百科抓取图片,如果错误需要更换
# 未来尝试再wiki百科抓取
RequestGetImage(pic_name)
# 抓取的药材图片用算法自动去背景扣图
CutoutJPG(pic_name)
# 使用基础的背景图片合成抠图的影像合成图片到封面
CompositeCoverJPG(pic_name)
# 音频文件数据处理
# 使用API接口生成字幕对应的音频文件保存到material_mp3的对应的目录下
ChangeWordsToMp3(df)
time_name_dict = Mp3Info(df)
# 正文部分1-6
try:
FirstPart(pic_name, df, time_name_dict, column_en2cn_dict)
except:
pass
try:
SecondPart(pic_name, df, time_name_dict, column_en2cn_dict)
except:
pass
try:
ThirdPart(pic_name, df, time_name_dict, column_en2cn_dict)
except:
pass
try:
FourthPart(pic_name, df, time_name_dict, column_en2cn_dict)
except:
pass
try:
FifthPart(pic_name, df, time_name_dict, column_en2cn_dict)
except:
pass
try:
SixthPart(pic_name, df, time_name_dict, column_en2cn_dict)
except:
pass
# 合成封面MP4文件
MakeCoverMp4(pic_name)
# 拼接视频合成背景音乐
StitchingVideo(pic_name)
几个重要py文件。
- configs.py # 工程配置数据
- process_audio.py # 处理工程需要的音频数据
- process_images.py # 处理工程需要的图片数据
- process_text.py # 处理工程需要的文字数据
- process_video.py # 处理工程需要的视频数据
- ready_work.py # 工程启动准备工作
按照上面的思路执行后会生成对应中药材的制作文件。
material_everypart
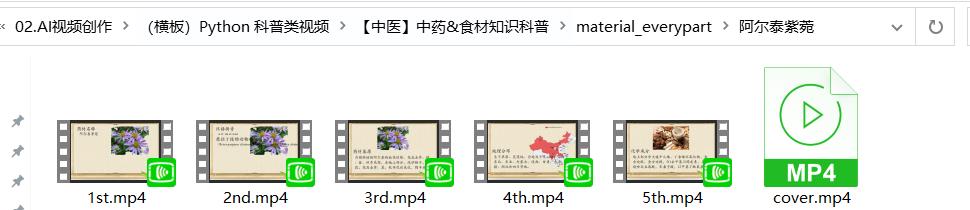
material_jpg
material_mp3
material_video
最终合成的结果视频是 result.mp4。
以上是关于月产10000个中药科普短视频方法,Python编程AI教程的主要内容,如果未能解决你的问题,请参考以下文章