SECOND点云检测代码详解
Posted NNNNNathan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SECOND点云检测代码详解相关的知识,希望对你有一定的参考价值。
1、前言
SECOND也是一片基于Voxel按anchor-based的点云检测方法,网络的整体结构和实现大部分与原先VoxelNet相近,同时在VoxelNet的基础上改进了中间层的3D卷积,采用稀疏卷积来完成,提高了训练的效率和网络推理的速度,同时解决了VoxelNet中角度预测中,因为物体完全反向和产生很大loss的情况;同时,SECOND还提出了GT_Aug的点云数据增强。没有了解过VoxelNet的小伙伴可以查看我的这篇文章:
 https://blog.csdn.net/qq_41366026/article/details/123175074?spm=1001.2014.3001.5501
https://blog.csdn.net/qq_41366026/article/details/123175074?spm=1001.2014.3001.5501SECOND论文地址:Sensors | Free Full-Text | SECOND: Sparsely Embedded Convolutional Detection
SECOND代码地址:GitHub - traveller59/second.pytorch: SECOND for KITTI/NuScenes object detection
本文的代码解析将会根据OpenPCDet的实现来进行,期间异同会说明:
GitHub - open-mmlab/OpenPCDet: OpenPCDet Toolbox for LiDAR-based 3D Object Detection.
2、SECOND网络模块解析
SECOND(Sparsely Embedded CONvolutional Detection)网络整体架构(图来自原论文)

SECOND与VoxelNet网络结构异同(图来自【3D目标检测】SECOND算法解析 - 知乎)

注:VoxelNet中的点云特征提取VFE模块在作者最新的实现中已经被替换;因为原来的VFE操作速度太慢,并且对显存不友好。具体可以查看这个issue:
https://github.com/traveller59/second.pytorch/issues/153
SECOND在PCDet中的代码实现类结构图:
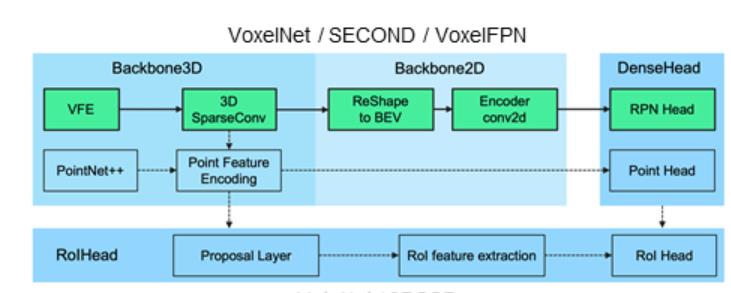
1、MeanVFE (voxel特征编码)
2、VoxelBackBone8x (中间卷积层,此处为3D稀疏卷积)
3、HeightCompression (Z轴方向压缩)
4、BaseBEVBackbone (BEV视角下 2D卷积特征提取)
5、AnchorHeadSingle (anchor分类和box预测)
3、VFE(Voxel Feature Encoding)
3.1 Point Cloud Grouping
在最先的SECOND中,将点云变成Voxel的方法和VoxelNet中一样,首先创建一个最大存储N个voxel的buffer,并迭代整个点云来分配他们所在的voxe,同时存储这个voxel在voxel坐标系中的坐标和每个voxel中有多少个点云数据(详细可以参看我VoxelNet中2.1.5节,高效实现部分)。
在最新的是实现中,采用了稀疏卷积来进行完成 。
经过对点云数据进行Grouping操作后得到三份数据:
1、得到所有的voxel shape为(N, 5 , 4) ; 5为每个voxel最大的点数,4为每个point的数据 (x,y,z,reflect intensity)
2、得到每个voxel的位置坐标 shape(N, 3)
3、得到每个voxel中有多少个非空点 shape (N)
注:
1.原文中分别对车、自行车和行人使用了不同的网络结构,PCDet仅使用一种结构训练三个类别。
2.在kitti数据集的实现中,点云的范围为[0, -40, -3, 70.4, 40, 1],超出部分会被裁剪, 此处以OpenPCDet中的统一规范坐标为准,x向前,y向左,z向上,旋转角从x到y逆时针为正。
3.原论文中的每个voxel的长宽高为0.2,0.2,0.4且每个voxel中采样35个点,在PCDet的实现中每个voxel的长宽0.05米,高0.1米且每个voxel采样5个点;同时在Grouping的过程中,一个voxel中点的数量不足5个的话,用0填充至5个。
3.N为非空voxel的最大个数,训练过程中N取16000,推理时取40000。
代码在:pcdet/datasets/processor/data_processor.py
def transform_points_to_voxels(self, data_dict=None, config=None):
"""
将点云转换为voxel,调用spconv的VoxelGeneratorV2
"""
if data_dict is None:
grid_size = (self.point_cloud_range[3:6] - self.point_cloud_range[0:3]) / np.array(config.VOXEL_SIZE)
self.grid_size = np.round(grid_size).astype(np.int64)
self.voxel_size = config.VOXEL_SIZE
# just bind the config, we will create the VoxelGeneratorWrapper later,
# to avoid pickling issues in multiprocess spawn
return partial(self.transform_points_to_voxels, config=config)
if self.voxel_generator is None:
self.voxel_generator = VoxelGeneratorWrapper(
# 给定每个voxel的长宽高 [0.05, 0.05, 0.1]
vsize_xyz=config.VOXEL_SIZE, # [0.16, 0.16, 4]
# 给定点云的范围 [ 0. -40. -3. 70.4 40. 1. ]
coors_range_xyz=self.point_cloud_range,
# 给定每个点云的特征维度,这里是x,y,z,r 其中r是激光雷达反射强度
num_point_features=self.num_point_features,
# 给定每个pillar中有采样多少个点,不够则补0
max_num_points_per_voxel=config.MAX_POINTS_PER_VOXEL, # 32
# 最多选取多少个voxel,训练16000,推理40000
max_num_voxels=config.MAX_NUMBER_OF_VOXELS[self.mode], # 16000
)
# 使用spconv生成voxel输出
points = data_dict['points']
voxel_output = self.voxel_generator.generate(points)
# 假设一份点云数据是N*4,那么经过pillar生成后会得到三份数据
# voxels代表了每个生成的voxel数据,维度是[M, 5, 4]
# coordinates代表了每个生成的voxel所在的zyx轴坐标,维度是[M,3]
# num_points代表了每个生成的voxel中有多少个有效的点维度是[m,],因为不满5会被0填充
voxels, coordinates, num_points = voxel_output
# False
if not data_dict['use_lead_xyz']:
voxels = voxels[..., 3:] # remove xyz in voxels(N, 3)
data_dict['voxels'] = voxels
data_dict['voxel_coords'] = coordinates
data_dict['voxel_num_points'] = num_points
return data_dict其中VoxelGeneratorWrapper在pcdet/datasets/processor/data_processor.py。
3.2 Mean VFE
在得到Voxel和每个Voxel对应的coordinate后,此处的VFE方式稍有变化,原因已写在上面的issue中。
原文:在原论文的实现中,VFE模块是和VoxelNet中一样的,详情可以看我voxelnet的 2.1.3节VFE堆叠(Stacked Voxel Feature Encoding)。
新实现:在新的实现中,去掉了原来Stacked Voxel Feature Encoding,直接计算每个voxel内点的平均值,当成这个voxel的特征;大幅提高了计算的速度,并且也取得了不错的检测效果。得到voxel特征的维度变换为:
(Batch*16000, 5, 4) --> (Batch*16000, 4)
代码在:pcdet/models/backbones_3d/vfe/mean_vfe.py
class MeanVFE(VFETemplate):
def __init__(self, model_cfg, num_point_features, **kwargs):
super().__init__(model_cfg=model_cfg)
# 每个点多少个特征(x,y,z,r)
self.num_point_features = num_point_features
def get_output_feature_dim(self):
return self.num_point_features
def forward(self, batch_dict, **kwargs):
"""
Args:
batch_dict:
voxels: (num_voxels, max_points_per_voxel, C)
voxel_num_points: optional (num_voxels) how many points in a voxel
**kwargs:
Returns:
vfe_features: (num_voxels, C)
"""
# here use the mean_vfe module to substitute for the original pointnet extractor architecture
voxel_features, voxel_num_points = batch_dict['voxels'], batch_dict['voxel_num_points']
# 求每个voxel内 所有点的和
# eg:SECOND shape (Batch*16000, 5, 4) -> (Batch*16000, 4)
points_mean = voxel_features[:, :, :].sum(dim=1, keepdim=False)
# 正则化项, 保证每个voxel中最少有一个点,防止除0
normalizer = torch.clamp_min(voxel_num_points.view(-1, 1), min=1.0).type_as(voxel_features)
# 求每个voxel内点坐标的平均值
points_mean = points_mean / normalizer
# 将处理好的voxel_feature信息重新加入batch_dict中
batch_dict['voxel_features'] = points_mean.contiguous()
return batch_dict
4、VoxelBackBone8x
在VoxelNet中,对voxel进行特征提取采取的是3D卷积的操作,但是3D卷积由于计算量太大,并且消耗的计算资源太多;作者对其进行了改进。
首先稀疏卷积的概念最早由facebook开源且使用在2D手写数字识别上的,因为其特殊的映射规则,其卷积速度比普通的卷积快,所以,作者在这里想到了用常规稀疏卷积的替代方法,submanifold卷积; submanifold卷积将输出位置限制为在且仅当相应的输入位置处于活动状态时才处于活动状态。 这避免了太多的激活位置的产生,从而导致后续卷积层中速度的降低。
作者经过自己的改进,使用了新的稀疏卷积方法,详情可以看这个知乎
这部分内容由于涉及了多个稀疏卷积的内容,包括了作者提出的3D稀疏卷积和submanifold卷积,这个坑以后再填,先让我们看代码实现。
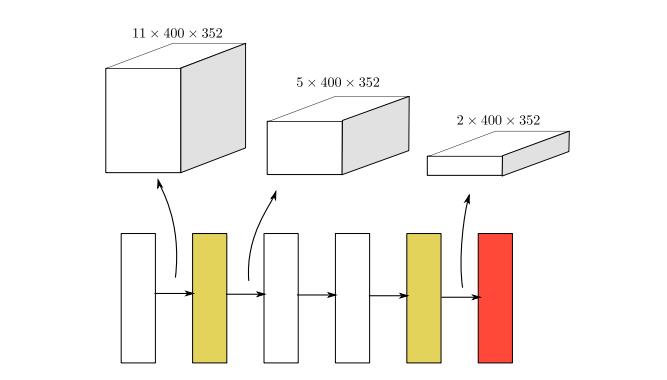
SECOND中的中间特征提取层,黄色代表作者自己提出的稀疏卷积,白色代表submanifold卷积,红色代表sparse-to-dense层。其中上方的数字为稀疏数据的空间大小(代码实现中的尺度与该图中有不同)。
代码在:pcdet/models/backbones_3d/spconv_backbone.py
class VoxelBackBone8x(nn.Module):
def __init__(self, model_cfg, input_channels, grid_size, **kwargs):
super().__init__()
self.model_cfg = model_cfg
norm_fn = partial(nn.BatchNorm1d, eps=1e-3, momentum=0.01)
self.sparse_shape = grid_size[::-1] + [1, 0, 0]
self.conv_input = spconv.SparseSequential(
spconv.SubMConv3d(input_channels, 16, 3, padding=1, bias=False, indice_key='subm1'),
norm_fn(16),
nn.ReLU(),
)
block = post_act_block
self.conv1 = spconv.SparseSequential(
block(16, 16, 3, norm_fn=norm_fn, padding=1, indice_key='subm1'),
)
self.conv2 = spconv.SparseSequential(
# [1600, 1408, 41] <- [800, 704, 21]
block(16, 32, 3, norm_fn=norm_fn, stride=2, padding=1, indice_key='spconv2', conv_type='spconv'),
block(32, 32, 3, norm_fn=norm_fn, padding=1, indice_key='subm2'),
block(32, 32, 3, norm_fn=norm_fn, padding=1, indice_key='subm2'),
)
self.conv3 = spconv.SparseSequential(
# [800, 704, 21] <- [400, 352, 11]
block(32, 64, 3, norm_fn=norm_fn, stride=2, padding=1, indice_key='spconv3', conv_type='spconv'),
block(64, 64, 3, norm_fn=norm_fn, padding=1, indice_key='subm3'),
block(64, 64, 3, norm_fn=norm_fn, padding=1, indice_key='subm3'),
)
self.conv4 = spconv.SparseSequential(
# [400, 352, 11] <- [200, 176, 5]
block(64, 64, 3, norm_fn=norm_fn, stride=2, padding=(0, 1, 1), indice_key='spconv4', conv_type='spconv'),
block(64, 64, 3, norm_fn=norm_fn, padding=1, indice_key='subm4'),
block(64, 64, 3, norm_fn=norm_fn, padding=1, indice_key='subm4'),
)
last_pad = 0
last_pad = self.model_cfg.get('last_pad', last_pad)
self.conv_out = spconv.SparseSequential(
# [200, 150, 5] -> [200, 150, 2]
spconv.SparseConv3d(64, 128, (3, 1, 1), stride=(2, 1, 1), padding=last_pad,
bias=False, indice_key='spconv_down2'),
norm_fn(128),
nn.ReLU(),
)
self.num_point_features = 128
self.backbone_channels =
'x_conv1': 16,
'x_conv2': 32,
'x_conv3': 64,
'x_conv4': 64
def forward(self, batch_dict):
"""
Args:
batch_dict:
batch_size: int
vfe_features: (num_voxels, C)
voxel_coords: (num_voxels, 4), [batch_idx, z_idx, y_idx, x_idx]
Returns:
batch_dict:
encoded_spconv_tensor: sparse tensor
"""
# voxel_features, voxel_coords shape (Batch * 16000, 4)
voxel_features, voxel_coords = batch_dict['voxel_features'], batch_dict['voxel_coords']
batch_size = batch_dict['batch_size']
# 根据voxel坐标,并将每个voxel放置voxel_coor对应的位置,建立成稀疏tensor
input_sp_tensor = spconv.SparseConvTensor(
# (Batch * 16000, 4)
features=voxel_features,
# (Batch * 16000, 4) 其中4为 batch_idx, x, y, z
indices=voxel_coords.int(),
# [41,1600,1408] ZYX 每个voxel的长宽高为0.05,0.05,0.1 点云的范围为[0, -40, -3, 70.4, 40, 1]
spatial_shape=self.sparse_shape,
# 4
batch_size=batch_size
)
"""
稀疏卷积的计算中,feature,channel,shape,index这几个内容都是分开存放的,
在后面用out.dense才把这三个内容组合到一起了,变为密集型的张量
spconv卷积的输入也是一样,输入和输出更像是一个 字典或者说元组
注意卷积中pad与no_pad的区别
"""
# # 进行submanifold convolution
# [batch_size, 4, [41, 1600, 1408]] --> [batch_size, 16, [41, 1600, 1408]]
x = self.conv_input(input_sp_tensor)
# [batch_size, 16, [41, 1600, 1408]] --> [batch_size, 16, [41, 1600, 1408]]
x_conv1 = self.conv1(x)
# [batch_size, 16, [41, 1600, 1408]] --> [batch_size, 32, [21, 800, 704]]
x_conv2 = self.conv2(x_conv1)
# [batch_size, 32, [21, 800, 704]] --> [batch_size, 64, [11, 400, 352]]
x_conv3 = self.conv3(x_conv2)
# [batch_size, 64, [11, 400, 352]] --> [batch_size, 64, [5, 200, 176]]
x_conv4 = self.conv4(x_conv3)
# for detection head
# [200, 176, 5] -> [200, 176, 2]
# [batch_size, 64, [5, 200, 176]] --> [batch_size, 128, [2, 200, 176]]
out = self.conv_out(x_conv4)
batch_dict.update(
'encoded_spconv_tensor': out,
'encoded_spconv_tensor_stride': 8
)
batch_dict.update(
'multi_scale_3d_features':
'x_conv1': x_conv1,
'x_conv2': x_conv2,
'x_conv3': x_conv3,
'x_conv4': x_conv4,
)
batch_dict.update(
'multi_scale_3d_strides':
'x_conv1': 1,
'x_conv2': 2,
'x_conv3': 4,
'x_conv4': 8,
)
return batch_dict其中block为稀疏卷积构建:
def post_act_block(in_channels, out_channels, kernel_size, indice_key=None, stride=1, padding=0,
conv_type='subm', norm_fn=None):
# 后处理执行块,根据conv_type选择对应的卷积操作并和norm与激活函数封装为块
if conv_type == 'subm':
conv = spconv.SubMConv3d(in_channels, out_channels, kernel_size, bias=False, indice_key=indice_key)
elif conv_type == 'spconv':
conv = spconv.SparseConv3d(in_channels, out_channels, kernel_size, stride=stride, padding=padding,
bias=False, indice_key=indice_key)
elif conv_type == 'inverseconv':
conv = spconv.SparseInverseConv3d(in_channels, out_channels, kernel_size, indice_key=indice_key, bias=False)
else:
raise NotImplementedError
m = spconv.SparseSequential(
conv,
norm_fn(out_channels),
nn.ReLU(),
)
return m5、HeightCompression (Z轴方向压缩)
由于前面VoxelBackBone8x得到的tensor是稀疏tensor,数据为:
[batch_size, 64, [5, 200, 176]] --> [batch_size, 128, [2, 200, 176]]
这里需要将原来的稀疏数据转换为密集数据;同时将得到的密集数据在Z轴方向上进行堆叠,因为在KITTI数据集中,没有物体会在Z轴上重合;同时这样做的好处有:
1.简化了网络检测头的设计难度
2.增加了高度方向上的感受野
3.加快了网络的训练、推理速度
最终得到的BEV特征图为:(batch_size, 128*2, 200, 176) ,这样就可以将图片的检测思路运用进来了。
代码在pcdet/models/backbones_2d/map_to_bev/height_compression.py
# 在高度方向上进行压缩
class HeightCompression(nn.Module):
def __init__(self, model_cfg, **kwargs):
super().__init__()
self.model_cfg = model_cfg
# 高度的特征数
self.num_bev_features = self.model_cfg.NUM_BEV_FEATURES
def forward(self, batch_dict):
"""
Args:
batch_dict:
encoded_spconv_tensor: sparse tensor
Returns:
batch_dict:
spatial_features:
"""
# 得到VoxelBackBone8x的输出特征
encoded_spconv_tensor = batch_dict['encoded_spconv_tensor']
# 将稀疏的tensor转化为密集tensor,[bacth_size, 128, 2, 200, 176]
# 结合batch,spatial_shape、indice和feature将特征还原到密集tensor中对应位置
spatial_features = encoded_spconv_tensor.dense()
# batch_size,128,2,200,176
N, C, D, H, W = spatial_features.shape
"""
将密集的3D tensor reshape为2D鸟瞰图特征
将两个深度方向内的voxel特征拼接成一个 shape : (batch_size, 256, 200, 176)
z轴方向上没有物体会堆叠在一起,这样做可以增大Z轴的感受野,
同时加快网络的速度,减小后期检测头的设计难度
"""
spatial_features = spatial_features.view(N, C * D, H, W)
# 将特征和采样尺度加入batch_dict
batch_dict['spatial_features'] = spatial_features
# 特征图的下采样倍数 8倍
batch_dict['spatial_features_stride'] = batch_dict['encoded_spconv_tensor_stride']
return batch_dict
6、BaseBEVBackbone
在获得类图片的特征数据后,需要在对该特征在BEV的视角上进行特征提取。这里采用了和VoxelNet类是的网络结构;分别对特征图进行不同尺度的下采样然后再进行上采用后在通道维度进行拼接。
SECOND中存在两个下采样分支结构,则对应存在两个反卷积结构:
经过HeightCompression得到的BEV特征图是:(batch_size, 128*2, 200, 176)
下采样分支一:(batch_size, 128*2, 200, 176) --> (batch,128, 200, 176)
下采样分支二:(batch_size, 128*2, 200, 176) --> (batch,128, 200, 176)
反卷积分支一:(batch, 128, 200, 176) --> (batch, 256, 200, 176)
反卷积分支二:(batch, 256, 100, 88) --> (batch, 256, 200, 176)
最终将结构在通道维度上进行拼接的特征图维度:(batch, 256 * 2, 200, 176)
代码在:pcdet/models/backbones_2d/base_bev_backbone.py
def forward(self, data_dict):
"""
Args:
data_dict:
spatial_features : (4, 64, 496, 432)
Returns:
"""
spatial_features = data_dict['spatial_features']
ups = []
ret_dict =
x = spatial_features
# 对不同的分支部分分别进行conv和deconv的操作
for i in range(len(self.blocks)):
"""
SECOND中一共存在两个下采样分支,
分支一: (batch,128,200,176)
分支二: (batch,256,100,88)
"""
x = self.blocks[i](x)
stride = int(spatial_features.shape[2] / x.shape[2])
ret_dict['spatial_features_%dx' % stride] = x
# 如果存在deconv,则对经过conv的结果进行反卷积操作
"""
SECOND中存在两个下采样,则分别对两个下采样分支进行反卷积操作
分支一: (batch,128,200,176)-->(batch,256,200,176)
分支二: (batch,256,100,88)-->(batch,256,200,176)
"""
if len(self.deblocks) > 0:
ups.append(self.deblocks[i](x))
else:
ups.append(x)
# 将上采样结果在通道维度拼接
if len(ups) > 1:
"""
最终经过所有上采样层得到的2个尺度的的信息
每个尺度的 shape 都是 (batch,256,200,176)
在第一个维度上进行拼接得到x 维度是 (batch,512,200,176)
"""
x = torch.cat(ups, dim=1)
elif len(ups) == 1:
x = ups[0]
# Fasle
if len(self.deblocks) > len(self.blocks):
x = self.deblocks[-1](x)
# 将结果存储在spatial_features_2d中并返回
data_dict['spatial_features_2d'] = x
return data_dict
7、AnchorHeadSingle
经过BaseBEVBackbone后得到的特征图为(batch, 256 * 2, 200, 176);在SECOND中,作者提出了方向分类,将原来VoxelNet的两个预测头上增加了一个方向分类头,来解决角度训练过程中一个预测的结果与GTBox的方向相反导致大loss的情况。
检测头图:

每个头分别采用了1*1的卷积来进行预测。
7.1 anchor生成
由于在3D世界中,每个类别的物体大小相对固定,所以直接使用了基于KITTI数据集上每个类别的平均长宽高作为anchor大小,同时每个类别的anchor都有两个方向角为0度和90度。
anchor的类别尺度大小(单位:米):
分别是车 [3.9, 1.6, 1.56],anchor的中心在Z轴的-1米、
人[0.8, 0.6, 1.73],anchor的中心在Z轴的-0.6米、
自行车[1.76, 0.6, 1.73],anchor的中心在Z轴的-0.6米
每个anchro都有被指定两个个one-hot向量,一个用于方向分类,一个用于类别分类;还被指定一个7维的向量用于anchor box的回归,分别是(x, y, z, l, w, h, θ)其中θ为PCDet坐标系下物体的朝向信息。
最终可以得到3个类别的anchor,维度都是[z, y, x, num_size, num_rot, 7],其中num_size是每个类别有几个尺度(1个);num_rot为每个anchor有几个方向类别(2个);7维向量表示为 [x, y, z, dx, dy, dz, rot](每个anchor box的信息)。
代码在:pcdet/models/dense_heads/target_assigner/anchor_generator.py
注:SECOND的特征图尺度大小为 宽200, 长176,下面注释中需要将所有216替换为176,248替换为200即可。同时点云的尺度信息是[0, -40, -3, 70.4, 40, 1]。
class AnchorGenerator(object):
def __init__(self, anchor_range, anchor_generator_config):
super().__init__()
self.anchor_generator_cfg = anchor_generator_config # list:3
# 得到anchor在点云中的分布范围[0, -39.68, -3, 69.12, 39.68, 1]
self.anchor_range = anchor_range
# 得到配置参数中所有尺度anchor的长宽高
# list:3 --> 车、人、自行车[[[3.9, 1.6, 1.56]],[[0.8, 0.6, 1.73]],[[1.76, 0.6, 1.73]]]
self.anchor_sizes = [config['anchor_sizes'] for config in anchor_generator_config]
# 得到anchor的旋转角度,这是是弧度,也就是0度和90度
# list:3 --> [[0, 1.57],[0, 1.57],[0, 1.57]]
self.anchor_rotations = [config['anchor_rotations'] for config in anchor_generator_config]
# 得到每个anchor初始化在点云中z轴的位置,其中在kitti中点云的z轴范围是-3米到1米
# list:3 --> [[-1.78],[-0.6],[-0.6]]
self.anchor_heights = [config['anchor_bottom_heights'] for config in anchor_generator_config]
# 每个先验框产生的时候是否需要在每个格子的中间,
# 例如坐标点为[1,1],如果需要对齐中心点的话,需要加上0.5变成[1.5, 1.5]
# 默认为False
# list:3 --> [False, False, False]
self.align_center = [config.get('align_center', False) for config in anchor_generator_config]
assert len(self.anchor_sizes) == len(self.anchor_rotations) == len(self.anchor_heights)
self.num_of_anchor_sets = len(self.anchor_sizes) # 3
def generate_anchors(self, grid_sizes):
assert len(grid_sizes) == self.num_of_anchor_sets
# 1.初始化
all_anchors = []
num_anchors_per_location = []
# 2.三个类别的先验框逐类别生成
for grid_size, anchor_size, anchor_rotation, anchor_height, align_center in zip(
grid_sizes, self.anchor_sizes, self.anchor_rotations, self.anchor_heights, self.align_center):
# 2 = 2x1x1 --> 每个位置产生2个anchor,这里的2代表两个方向
num_anchors_per_location.append(len(anchor_rotation) * len(anchor_size) * len(anchor_height))
# 不需要对齐中心点来生成先验框
if align_center:
x_stride = (self.anchor_range[3] - self.anchor_range[0]) / grid_size[0]
y_stride = (self.anchor_range[4] - self.anchor_range[1]) / grid_size[1]
# 中心对齐,平移半个网格
x_offset, y_offset = x_stride / 2, y_stride / 2
else:
# 2.1计算每个网格的在点云空间中的实际大小
# 用于将每个anchor映射回实际点云中的大小
# (69.12 - 0) / (216 - 1) = 0.3214883848678234 单位:米
x_stride = (self.anchor_range[3] - self.anchor_range[0]) / (grid_size[0] - 1)
# (39.68 - (-39.68.)) / (248 - 1) = 0.3212955490297634 单位:米
y_stride = (self.anchor_range[4] - self.anchor_range[1]) / (grid_size[1] - 1)
# 由于没有进行中心对齐,所有每个点相对于左上角坐标的偏移量都是0
x_offset, y_offset = 0, 0
# 2.2 生成单个维度x_shifts,y_shifts和z_shifts
# 以x_stride为step,在self.anchor_range[0] + x_offset和self.anchor_range[3] + 1e-5,
# 产生x坐标 --> 216个点 [0, 69.12]
x_shifts = torch.arange(
self.anchor_range[0] + x_offset, self.anchor_range[3] + 1e-5, step=x_stride, dtype=torch.float32,
).cuda()
# 产生y坐标 --> 248个点 [0, 79.36]
y_shifts = torch.arange(
self.anchor_range[1] + y_offset, self.anchor_range[4] + 1e-5, step=y_stride, dtype=torch.float32,
).cuda()
"""
new_tensor函数可以返回一个新的张量数据,该张量数据与指定的有相同的属性
如拥有相同的数据类型和张量所在的设备情况等属性;
并使用anchor_height数值个来填充这个张量
"""
# [-1.78]
z_shifts = x_shifts.new_tensor(anchor_height)
# num_anchor_size = 1
# num_anchor_rotation = 2
num_anchor_size, num_anchor_rotation = anchor_size.__len__(), anchor_rotation.__len__() # 1, 2
# [0, 1.57] 弧度制
anchor_rotation = x_shifts.new_tensor(anchor_rotation)
# [[3.9, 1.6, 1.56]]
anchor_size = x_shifts.new_tensor(anchor_size)
# 2.3 调用meshgrid生成网格坐标
x_shifts, y_shifts, z_shifts = torch.meshgrid([
x_shifts, y_shifts, z_shifts
])
# meshgrid可以理解为在原来的维度上进行扩展,例如:
# x原来为(216,)-->(216,1, 1)--> (216,248,1)
# y原来为(248,)--> (1,248,1)--> (216,248,1)
# z原来为 (1, ) --> (1,1,1) --> (216,248,1)
# 2.4.anchor各个维度堆叠组合,生成最终anchor(1,432,496,1,2,7)
# 2.4.1.堆叠anchor的位置
# [x, y, z, 3]-->[216, 248, 1, 3] 代表了每个anchor的位置信息
# 其中3为该点所在映射tensor中的(z, y, x)数值
anchors = torch.stack((x_shifts, y_shifts, z_shifts), dim=-1)
# 2.4.2.将anchor的位置和大小进行组合,编程为将anchor扩展并复制为相同维度(除了最后一维),然后进行组合
# (216, 248, 1, 3) --> (216, 248, 1 , 1, 3)
# 维度分别代表了: z,y,x, 该类别anchor的尺度数量,该个anchor的位置信息
anchors = anchors[:, :, :, None, :].repeat(1, 1, 1, anchor_size.shape[0], 1)
# (1, 1, 1, 1, 3) --> (216, 248, 1, 1, 3)
anchor_size = anchor_size.view(1, 1, 1, -1, 3).repeat([*anchors.shape[0:3], 1, 1])
# anchors生成的最终结果需要有位置信息和大小信息 --> (216, 248, 1, 1, 6)
# 最后一个纬度中表示(z, y, x, l, w, h)
anchors = torch.cat((anchors, anchor_size), dim=-1)
# 2.4.3.将anchor的位置和大小和旋转角进行组合
# 在倒数第二个维度上增加一个维度,然后复制该维度一次
# (216, 248, 1, 1, 2, 6) 长, 宽, 深, anchor尺度数量, 该尺度旋转角个数,anchor的6个参数
anchors = anchors[:, :, :, :, None, :].repeat(1, 1, 1, 1, num_anchor_rotation, 1)
# (216, 248, 1, 1, 2, 1) 两个不同方向先验框的旋转角度
anchor_rotation = anchor_rotation.view(1, 1, 1, 1, -1, 1).repeat(
[*anchors.shape[0:3], num_anchor_size, 1, 1])
# [z, y, x, num_size, num_rot, 7] --> (216, 248, 1, 1, 2, 7)
# 最后一个纬度表示为anchors的位置+大小+旋转角度(z, y, x, l, w, h, theta)
anchors = torch.cat((anchors, anchor_rotation), dim=-1) # [z, y, x, num_size, num_rot, 7]
# 2.5 置换anchor的维度
# [z, y, x, num_anchor_size, num_rot, 7]-->[x, y, z, num_anchor_zie, num_rot, 7]
# 最后一个纬度代表了 : [x, y, z, dx, dy, dz, rot]
anchors = anchors.permute(2, 1, 0, 3, 4, 5).contiguous()
# 使得各类anchor的z轴方向从anchor的底部移动到该anchor的中心点位置
# 车 : -1.78 + 1.56/2 = -1.0
# 人、自行车 : -0.6 + 1.73/2 = 0.23
anchors[..., 2] += anchors[..., 5] / 2
all_anchors.append(anchors)
# all_anchors: [(1,248,216,1,2,7),(1,248,216,1,2,7),(1,248,216,1,2,7)]
# num_anchors_per_location:[2,2,2]
return all_anchors, num_anchors_per_location7.2 预测头实现
对特征图上的每个anchor预测对应的类别,方向和box的7个回归参数。
代码在:pcdet/models/dense_heads/anchor_head_single.py
注:SECOND的特征图尺度大小为 宽200, 长176,下面注释中需要将所有216替换为176,248替换为200即可。同时点云的尺度信息是[0, -40, -3, 70.4, 40, 1]。
class AnchorHeadSingle(AnchorHeadTemplate):
"""
Args:
model_cfg: AnchorHeadSingle的配置
input_channels: 384 输入通道数
num_class: 3
class_names: ['Car','Pedestrian','Cyclist']
grid_size: (X, Y, Z)
point_cloud_range: (0, -39.68, -3, 69.12, 39.68, 1)
predict_boxes_when_training: False
"""
def __init__(self, model_cfg, input_channels, num_class, class_names, grid_size, point_cloud_range,
predict_boxes_when_training=True, **kwargs):
super().__init__(
model_cfg=model_cfg, num_class=num_class, class_names=class_names, grid_size=grid_size,
point_cloud_range=point_cloud_range,
predict_boxes_when_training=predict_boxes_when_training
)
# 每个点有3个尺度的个先验框 每个先验框都有两个方向(0度,90度) num_anchors_per_location:[2, 2, 2]
self.num_anchors_per_location = sum(self.num_anchors_per_location) # sum([2, 2, 2])
# Conv2d(512,18,kernel_size=(1,1),stride=(1,1))
self.conv_cls = nn.Conv2d(
input_channels, self.num_anchors_per_location * self.num_class,
kernel_size=1
)
# Conv2d(512,42,kernel_size=(1,1),stride=(1,1))
self.conv_box = nn.Conv2d(
input_channels, self.num_anchors_per_location * self.box_coder.code_size,
kernel_size=1
)
# 如果存在方向损失,则添加方向卷积层Conv2d(512,12,kernel_size=(1,1),stride=(1,1))
if self.model_cfg.get('USE_DIRECTION_CLASSIFIER', None) is not None:
self.conv_dir_cls = nn.Conv2d(
input_channels,
self.num_anchors_per_location * self.model_cfg.NUM_DIR_BINS,
kernel_size=1
)
else:
self.conv_dir_cls = None
self.init_weights()
# 初始化参数
def init_weights(self):
pi = 0.01
# 初始化分类卷积偏置
nn.init.constant_(self.conv_cls.bias, -np.log((1 - pi) / pi))
# 初始化分类卷积权重
nn.init.normal_(self.conv_box.weight, mean=0, std=0.001)
def forward(self, data_dict):
# 从字典中取出经过backbone处理过的信息
# spatial_features_2d 维度 (batch_size, 384, 248, 216)
spatial_features_2d = data_dict['spatial_features_2d']
# 每个坐标点上面6个先验框的类别预测 --> (batch_size, 18, 248, 216)
cls_preds = self.conv_cls(spatial_features_2d)
# 每个坐标点上面6个先验框的参数预测 --> (batch_size, 42, 248, 216)
# 其中每个先验框需要预测7个参数,分别是(x, y, z, w, l, h, θ)
box_preds = self.conv_box(spatial_features_2d)
# 维度调整,将类别放置在最后一维度 [N, H, W, C] --> (batch_size, 248, 216, 18)
cls_preds = cls_preds.permute(0, 2, 3, 1).contiguous()
# 维度调整,将先验框调整参数放置在最后一维度 [N, H, W, C] --> (batch_size ,248, 216, 42)
box_preds = box_preds.permute(0, 2, 3, 1).contiguous()
# 将类别和先验框调整预测结果放入前向传播字典中
self.forward_ret_dict['cls_preds'] = cls_preds
self.forward_ret_dict['box_preds'] = box_preds
# 进行方向分类预测
if self.conv_dir_cls is not None:
# # 每个先验框都要预测为两个方向中的其中一个方向 --> (batch_size, 12, 248, 216)
dir_cls_preds = self.conv_dir_cls(spatial_features_2d)
# 将类别和先验框方向预测结果放到最后一个维度中 [N, H, W, C] --> (batch_size, 248, 216, 12)
dir_cls_preds = dir_cls_preds.permute(0, 2, 3, 1).contiguous()
# 将方向预测结果放入前向传播字典中
self.forward_ret_dict['dir_cls_preds'] = dir_cls_preds
else:
dir_cls_preds = None
"""
如果是在训练模式的时候,需要对每个先验框分配GT来计算loss
"""
if self.training:
# targets_dict =
# 'box_cls_labels': cls_labels, # (4,211200)
# 'box_reg_targets': bbox_targets, # (4,211200, 7)
# 'reg_weights': reg_weights # (4,211200)
#
targets_dict = self.assign_targets(
gt_boxes=data_dict['gt_boxes'] # (4,39,8)
)
# 将GT分配结果放入前向传播字典中
self.forward_ret_dict.update(targets_dict)
# 如果不是训练模式,则直接生成进行box的预测
if not self.training or self.predict_boxes_when_training:
# 根据预测结果解码生成最终结果
batch_cls_preds, batch_box_preds = self.generate_predicted_boxes(
batch_size=data_dict['batch_size'],
cls_preds=cls_preds, box_preds=box_preds, dir_cls_preds=dir_cls_preds
)
data_dict['batch_cls_preds'] = batch_cls_preds # (1, 211200, 3) 70400*3=211200
data_dict['batch_box_preds'] = batch_box_preds # (1, 211200, 7)
data_dict['cls_preds_normalized'] = False
return data_dict
至此,分别得到每个box的类别预测结果,方向分类结果,box回归结果
类别预测 shape :(batch_size, 200, 176, 18)
方向分类 shape :(batch_size, 200, 176, 12)
box回归shape:(batch_size, 200, 176, 42)
8、Target assignment
由于预测的时候,将不同类别的anchor堆叠在了一个点进行预测,所有进行Target assignment时候,要分类别进行Target assignment操作。这里与2D 的SSD或YOLO的匹配不同。
因此在匹配的时候,需要逐帧逐类别对生成的anchor进行匹配;其中函数assign_targets负责一帧的匹配,函数assign_targets_single负责一帧中单个类别的匹配
代码在:pcdet/models/dense_heads/target_assigner/axis_aligned_target_assigner.py
注:SECOND的特征图尺度大小为 宽200, 长176,下面注释中需要将所有216替换为176,248替换为200即可。同时点云的尺度信息是[0, -40, -3, 70.4, 40, 1]。
import numpy as np
import torch
from ....ops.iou3d_nms import iou3d_nms_utils
from ....utils import box_utils
class AxisAlignedTargetAssigner(object):
def __init__(self, model_cfg, class_names, box_coder, match_height=False):
super().__init__()
# anchor生成配置参数
anchor_generator_cfg = model_cfg.ANCHOR_GENERATOR_CONFIG
# 为预测box找对应anchor的参数
anchor_target_cfg = model_cfg.TARGET_ASSIGNER_CONFIG
# 编码box的7个残差参数(x, y, z, w, l, h, θ) --> pcdet.utils.box_coder_utils.ResidualCoder
self.box_coder = box_coder
# 在PointPillars中指定正负样本的时候由BEV视角计算GT和先验框的iou,不需要进行z轴上的高度的匹配,
# 想法是:1、点云中的物体都在同一个平面上,没有物体在Z轴发生重叠的情况
# 2、每个类别的高度相差不是很大,直接使用SmoothL1损失就可以达到很好的高度回归效果
self.match_height = match_height
# 类别名称['Car', 'Pedestrian', 'Cyclist']
self.class_names = np.array(class_names)
# ['Car', 'Pedestrian', 'Cyclist']
self.anchor_class_names = [config['class_name'] for config in anchor_generator_cfg]
# anchor_target_cfg.POS_FRACTION = -1 < 0 --> None
# 前景、背景采样系数 PointPillars、SECOND不考虑
self.pos_fraction = anchor_target_cfg.POS_FRACTION if anchor_target_cfg.POS_FRACTION >= 0 else None
# 总采样数 PointPillars不考虑
self.sample_size = anchor_target_cfg.SAMPLE_SIZE # 512
# False 前景权重由 1/前景anchor数量 PointPillars不考虑
self.norm_by_num_examples = anchor_target_cfg.NORM_BY_NUM_EXAMPLES
# 类别iou匹配为正样本阈值'Car':0.6, 'Pedestrian':0.5, 'Cyclist':0.5
self.matched_thresholds =
# 类别iou匹配为负样本阈值'Car':0.45, 'Pedestrian':0.35, 'Cyclist':0.35
self.unmatched_thresholds =
for config in anchor_generator_cfg:
self.matched_thresholds[config['class_name']] = config['matched_threshold']
self.unmatched_thresholds[config['class_name']] = config['unmatched_threshold']
self.use_multihead = model_cfg.get('USE_MULTIHEAD', False) # False
# self.separate_multihead = model_cfg.get('SEPARATE_MULTIHEAD', False)
# if self.seperate_multihead:
# rpn_head_cfgs = model_cfg.RPN_HEAD_CFGS
# self.gt_remapping =
# for rpn_head_cfg in rpn_head_cfgs:
# for idx, name in enumerate(rpn_head_cfg['HEAD_CLS_NAME']):
# self.gt_remapping[name] = idx + 1
def assign_targets(self, all_anchors, gt_boxes_with_classes):
"""
处理一批数据中所有点云的anchors和gt_boxes,
计算每个anchor属于前景还是背景,
为每个前景的anchor分配类别和计算box的回归残差和回归权重
Args:
all_anchors: [(N, 7), ...]
gt_boxes_with_classes: (B, M, 8) # 最后维度数据为 (x, y, z, l, w, h, θ,class)
Returns:
all_targets_dict =
# 每个anchor的类别
'box_cls_labels': cls_labels, # (batch_size,num_of_anchors)
# 每个anchor的回归残差 -->(∆x, ∆y, ∆z, ∆l, ∆w, ∆h, ∆θ)
'box_reg_targets': bbox_targets, # (batch_size,num_of_anchors,7)
# 每个box的回归权重
'reg_weights': reg_weights # (batch_size,num_of_anchors)
"""
# 1.初始化结果list并提取对应的gt_box和类别
bbox_targets = []
cls_labels = []
reg_weights = []
# 得到批大小
batch_size = gt_boxes_with_classes.shape[0] # 4
# 得到所有GT的类别
gt_classes = gt_boxes_with_classes[:, :, -1] # (4,num_of_gt)
# 得到所有GT的7个box参数
gt_boxes = gt_boxes_with_classes[:, :, :-1] # (4,num_of_gt,7)
# 2.对batch中的所有数据逐帧匹配anchor的前景和背景
for k in range(batch_size):
cur_gt = gt_boxes[k] # 取出当前帧中的 gt_boxes (num_of_gt,7)
"""
由于在OpenPCDet的数据预处理时,以一批数据中拥有GT数量最多的帧为基准,
其他帧中GT数量不足,则会进行补0操作,使其成为一个矩阵,例:
[
[1,1,2,2,3,2],
[2,2,3,1,0,0],
[3,1,2,0,0,0]
]
因此这里从每一行的倒数第二个类别开始判断,
截取最后一个非零元素的索引,来取出当前帧中真实的GT数据
"""
cnt = cur_gt.__len__() - 1 # 得到一批数据中最多有多少个GT
# 这里的循环是找到最后一个非零的box,因为预处理的时候会按照batch最大box的数量处理,不足的进行补0
while cnt > 0 and cur_gt[cnt].sum() == 0:
cnt -= 1
# 2.1提取当前帧非零的box和类别
cur_gt = cur_gt[:cnt + 1]
# cur_gt_classes 例: tensor([1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 3], device='cuda:0', dtype=torch.int32)
cur_gt_classes = gt_classes[k][:cnt + 1].int()
target_list = []
# 2.2 对每帧中的anchor和GT分类别,单独计算前背景
# 计算时候 每个类别的anchor是独立计算的
for anchor_class_name, anchors in zip(self.anchor_class_names, all_anchors):
# anchor_class_name : 车 | 行人 | 自行车
# anchors : (1, 200, 176, 1, 2, 7) 7 --> (x, y, z, l, w, h, θ)
if cur_gt_classes.shape[0] > 1:
# self.class_names : ["car", "person", "cyclist"]
# 这里减1是因为列表索引从0开始,目的是得到属于列表中gt中哪些类别是与当前处理的了类别相同,得到类别mask
mask = torch.from_numpy(self.class_names[cur_gt_classes.cpu() - 1] == anchor_class_name)
else:
mask = torch.tensor([self.class_names[c - 1] == anchor_class_name
for c in cur_gt_classes], dtype=torch.bool)
# 在检测头中是否使用多头,是的话 此处为True,默认为False
if self.use_multihead: # False
anchors = anchors.permute(3, 4, 0, 1, 2, 5).contiguous().view(-1, anchors.shape[-1])
# if self.seperate_multihead:
# selected_classes = cur_gt_classes[mask].clone()
# if len(selected_classes) > 0:
# new_cls_id = self.gt_remapping[anchor_class_name]
# selected_classes[:] = new_cls_id
# else:
# selected_classes = cur_gt_classes[mask]
selected_classes = cur_gt_classes[mask]
else:
# 2.2.1 计算所需的变量 得到特征图的大小
feature_map_size = anchors.shape[:3] # (1, 248, 216)
# 将所有的anchors展平 shape : (216, 248, 1, 1, 2, 7) --> (107136, 7)
anchors = anchors.view(-1, anchors.shape[-1])
# List: 根据累呗mask索引得到该帧中当前需要处理的类别 --> 车 | 行人 | 自行车
selected_classes = cur_gt_classes[mask]
# 2.2.2 使用assign_targets_single来单独为某一类别的anchors分配gt_boxes,
# 并为前景、背景的box设置编码和回归权重
single_target = self.assign_targets_single(
anchors, # 该类的所有anchor
cur_gt[mask], # GT_box shape : (num_of_GT_box, 7)
gt_classes=selected_classes, # 当前选中的类别
matched_threshold=self.matched_thresholds[anchor_class_name], # 当前类别anchor与GT匹配为正样本的阈值
unmatched_threshold=self.unmatched_thresholds[anchor_class_name] # 当前类别anchor与GT匹配为负样本的阈值
)
target_list.append(single_target)
# 到目前为止,处理完该帧单个类别和该类别anchor的前景和背景分配
if self.use_multihead:
target_dict =
'box_cls_labels': [t['box_cls_labels'].view(-1) for t in target_list],
'box_reg_targets': [t['box_reg_targets'].view(-1, self.box_coder.code_size) for t in target_list],
'reg_weights': [t['reg_weights'].view(-1) for t in target_list]
target_dict['box_reg_targets'] = torch.cat(target_dict['box_reg_targets'], dim=0)
target_dict['box_cls_labels'] = torch.cat(target_dict['box_cls_labels'], dim=0).view(-1)
target_dict['reg_weights'] = torch.cat(target_dict['reg_weights'], dim=0).view(-1)
else:
target_dict =
# feature_map_size:(1,200,176, 2)
'box_cls_labels': [t['box_cls_labels'].view(*feature_map_size, -1) for t in target_list],
# (1,248,216, 2, 7)
'box_reg_targets': [t['box_reg_targets'].view(*feature_map_size, -1, self.box_coder.code_size)
for t in target_list],
# (1,248,216, 2)
'reg_weights': [t['reg_weights'].view(*feature_map_size, -1) for t in target_list]
# list : 3*anchor (1, 248, 216, 2, 7) --> (1, 248, 216, 6, 7) -> (321408, 7)
target_dict['box_reg_targets'] = torch.cat(
target_dict['box_reg_targets'], dim=-2
).view(-1, self.box_coder.code_size)
# list:3 (1, 248, 216, 2) --> (1,248, 216, 6) -> (1*248*216*6, )
target_dict['box_cls_labels'] = torch.cat(target_dict['box_cls_labels'], dim=-1).view(-1)
# list:3 (1, 200, 176, 2) --> (1, 200, 176, 6) -> (1*248*216*6, )
target_dict['reg_weights'] = torch.cat(target_dict['reg_weights'], dim=-1).view(-1)
# 将结果填入对应的容器
bbox_targets.append(target_dict['box_reg_targets'])
cls_labels.append(target_dict['box_cls_labels'])
reg_weights.append(target_dict['reg_weights'])
# 到这里该batch的点云全部处理完
# 3.将结果stack并返回
bbox_targets = torch.stack(bbox_targets, dim=0) # (batch_size,321408,7)
cls_labels = torch.stack(cls_labels, dim=0) # (batch_size,321408)
reg_weights = torch.stack(reg_weights, dim=0) # (batch_size,321408)
all_targets_dict =
'box_cls_labels': cls_labels, # (batch_size,321408)
'box_reg_targets': bbox_targets, # (batch_size,321408,7)
'reg_weights': reg_weights # (batch_size,321408)
return all_targets_dict
def assign_targets_single(self, anchors, gt_boxes, gt_classes, matched_threshold=0.6, unmatched_threshold=0.45):
"""
针对某一类别的anchors和gt_boxes,计算前景和背景anchor的类别,box编码和回归权重
Args:
anchors: (107136, 7)
gt_boxes: (该帧中该类别的GT数量,7)
gt_classes: (该帧中该类别的GT数量, 1)
matched_threshold: 0.6
unmatched_threshold: 0.45
Returns:
前景anchor
ret_dict =
'box_cls_labels': labels, # (107136,)
'box_reg_targets': bbox_targets, # (107136,7)
'reg_weights': reg_weights, # (107136,)
"""
# ----------------------------1.初始化-------------------------------#
num_anchors = anchors.shape[0] # 216 * 248 = 107136
num_gt = gt_boxes.shape[0] # 该帧中该类别的GT数量
# 初始化anchor对应的label和gt_id ,并置为 -1,-1表示loss计算时候不会被考虑,背景的类别被设置为0
labels = torch.ones((num_anchors,), dtype=torch.int32, device=anchors.device) * -1
gt_ids = torch.ones((num_anchors,), dtype=torch.int32, device=anchors.device) * -1
# ---------------------2.计算该类别中anchor的前景和背景------------------------#
if len(gt_boxes) > 0 and anchors.shape[0] > 0:
# 1.计算该帧中某一个类别gt和对应anchors之间的iou(jaccard index)
# anchor_by_gt_overlap shape : (107136, num_gt)
# anchor_by_gt_overlap代表当前类别的所有anchor和当前类别中所有GT的iou
anchor_by_gt_overlap = iou3d_nms_utils.boxes_iou3d_gpu(anchors[:, 0:7], gt_boxes[:, 0:7]) \\
if self.match_height else box_utils.boxes3d_nearest_bev_iou(anchors[:, 0:7], gt_boxes[:, 0:7])
# NOTE: The speed of these two versions depends the environment and the number of anchors
# anchor_to_gt_argmax = torch.from_numpy(anchor_by_gt_overlap.cpu().numpy().argmax(axis=1)).cuda()
# 2.得到每一个anchor与哪个的GT的的iou最大
# anchor_to_gt_argmax表示数据维度是anchor的长度,索引是gt
anchor_to_gt_argmax = anchor_by_gt_overlap.argmax(dim=1)
# anchor_to_gt_max得到每一个anchor最匹配的gt的iou数值
anchor_to_gt_max = anchor_by_gt_overlap[
torch.arange(num_anchors, device=anchors.device), anchor_to_gt_argmax]
# gt_to_anchor_argmax = torch.from_numpy(anchor_by_gt_overlap.cpu().numpy().argmax(axis=0)).cuda()
# 3.找到每个gt最匹配anchor的索引和iou
# (num_of_gt,) 得到每个gt最匹配的anchor索引
gt_to_anchor_argmax = anchor_by_gt_overlap.argmax(dim=0)
# (num_of_gt,)找到每个gt最匹配anchor的iou数值
gt_to_anchor_max = anchor_by_gt_overlap[gt_to_anchor_argmax, torch.arange(num_gt, device=anchors.device)]
# 4.将GT中没有匹配到的anchor的iou数值设置为-1
empty_gt_mask = gt_to_anchor_max == 0 # 得到没有匹配到anchor的gt的mask
gt_to_anchor_max[empty_gt_mask] = -1 # 将没有匹配到anchor的gt的iou数值设置为-1
# 5.找到anchor中和gt存在最大iou的anchor索引,即前景anchor
"""
由于在前面的实现中,仅仅找出来每个GT和anchor的最大iou索引,但是argmax返回的是索引最小的那个,
在匹配的过程中可能一个GT和多个anchor拥有相同的iou大小,
所以此处要找出这个GT与所有anchors拥有相同最大iou的anchor
"""
# 以gt为基础,逐个anchor对应,比如第一个gt的最大iou为0.9,则在所有anchor中找iou为0.9的anchor
# nonzero函数是numpy中用于得到数组array中非零元素的位置(数组索引)的函数
"""
矩阵比较例子 :
anchors_with_max_overlap = torch.tensor([[0.78, 0.1, 0.9, 0],
[0.0, 0.5, 0, 0],
[0.0, 0, 0.9, 0.8],
[0.78, 0.1, 0.0, 0]])
gt_to_anchor_max = torch.tensor([0.78, 0.5, 0.9,0.8])
anchors_with_max_overlap = anchor_by_gt_overlap == gt_to_anchor_max
# 返回的结果中包含了在anchor中与该GT拥有相同最大iou的所有anchor
anchors_with_max_overlap = tensor([[ True, False, True, False],
[False, True, False, False],
[False, False, True, True],
[ True, False, False, False]])
在torch中nonzero返回的是tensor中非0元素的位置,此函数在numpy中返回的是非零元素的行列表和列列表。
torch返回结果tensor([[0, 0],
[0, 2],
[1, 1],
[2, 2],
[2, 3],
[3, 0]])
numpy返回结果(array([0, 0, 1, 2, 2, 3]), array([0, 2, 1, 2, 3, 0]))
所以可以得到第一个GT同时与第一个anchor和最后一个anchor最为匹配
"""
"""所以在实际的一批数据中可以到得到结果为
tensor([[33382, 9],
[43852, 10],
[47284, 5],
[50370, 4],
[58498, 8],
[58500, 8],
[58502, 8],
[59139, 2],
以上是关于SECOND点云检测代码详解的主要内容,如果未能解决你的问题,请参考以下文章