SQL语句中,查询一个结果,满足表1的A条件,满足表2的B条件,怎么写?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL语句中,查询一个结果,满足表1的A条件,满足表2的B条件,怎么写?相关的知识,希望对你有一定的参考价值。
参考技术A1.创建测试表,
创建表test_col_1(id号,varvarchar2(200));
创建表test_col_2(id号,varvarchar2(200));

2.插入测试数据,
insertintotest_col_1
选择level*8, 'var'||*8 from dual connect by level <= 20;
insertintotest_col_2
选择level,‘var’||level from dual connect by level <= 100;

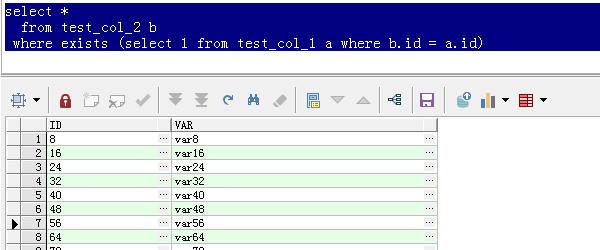
3.查询表A和表B中的相关记录,
Select*
fromtest_col_2b
Whereexists(select1fromtest_col_1awhereb。id=a.id)
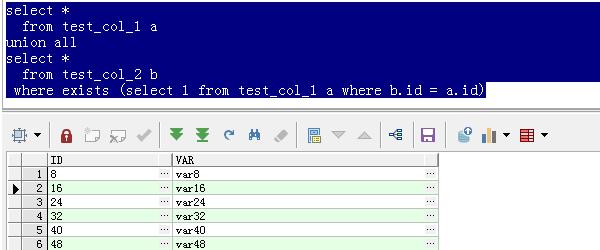
4.查询表A中的所有数据和A、B中的相关数据,
Select*
fromtest_col_1a
unionall
Select*
fromtest_col_2b
Whereexists(select1fromtest_col_1awhereb。id=a.id)
SQL中Union与Union All的区别
在写SQL查询语句时,经常会碰到类似于这种的需求:查询年龄大于60岁的男职工以及所有出生于1950年的职工。在处理这种需求时,无法使用一条简单的SQL语句查询出所有满足条件的结果,此时就需要将这种需求划分为几个小的子需求,然后将子查询得到的结果集合合并即得到了满足查询条件的结果。为了处理类似于这种的需求,SQL提供了Union和Union All操作,如下所示:
select * from employee where gender=‘M‘ and year(‘2013-09-21‘)-year(birthday) > 60 union (all) select * from employee where year(birthday)=1950 with ur; --片段一
那么这两个操作有什么区别呢,请参看以下例子,为了验证该例子我们创建一个employee表并向其中添加一些数据,具体示例代码如下所示:
create table employee(eid integer not null, birthday date not null, gender char(1), name varchar(100), mbltel char(13), mail varchar(20); --片段2
insert into employee values (1, ‘1989-01-01‘,‘M‘,‘李一‘,‘1345663221‘,‘[email protected]‘), (2, ‘1952-01-01‘,‘M‘,‘李二‘,‘1345663331‘,‘[email protected]‘), (3, ‘1951-01-01‘,‘F‘,‘李三‘,‘1345664311‘,‘[email protected]‘), (4, ‘1950-01-01‘,‘M‘,‘李四‘,‘1345662111‘,‘[email protected]‘), (5, ‘1950-07-01‘,‘F‘,‘李五‘,‘1345343221‘,‘[email protected]‘); --片段三
分别执行样例代码片段一中的Union和Union All操作,会出现以下结果:
从上面查询得到的结果我们可以看出,Union All操作仅仅是简单的将两个子查询结果集直接求并操作,并不会剔除掉两者结果集中重复的部分,而Union操作除了会剔除掉结果集中重复的部分以外,还会对结果集进行排序(其实执行的实质逻辑应该是先将某一子结果集进行排序,然后再判断是否有重复的数据,若有则删除掉重复的数据)。
小tips:由于Union需要对查询结果集进行排序操作,当数据量较大时,若非特殊需要,尽量不要使用Union操作,而改用Union All操作,然后对Union All出来的结果执行去重操作即可,这样会使得查询的效率大大的增强。
以上是关于SQL语句中,查询一个结果,满足表1的A条件,满足表2的B条件,怎么写?的主要内容,如果未能解决你的问题,请参考以下文章