架构师之路Learn Day7之Hive生产环境最佳实践
Posted 随缘清风殇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了架构师之路Learn Day7之Hive生产环境最佳实践相关的知识,希望对你有一定的参考价值。
1、分区表和分桶表的应用场景
- 注意事項:分区和分桶都会产生数据倾斜
1.1、分区表应用场景
- 作用:提高查询效率
①在SQL中会按照某个字段进行过滤,建表的时候要按照这个字段作为分区字段
②数据基本上只会分析增量数据,不会分析全量数据,则应该按照时间来分区
1.2、分桶表应用场景
- 作用:提高查询效率+进行抽样
①如果一个表的字段经常被Join查询条件,就应该建分桶表进行优化
select a.*,b.* from a join b on a.guid=b.guid
-
注意事项:a表和b表都要分桶,而且分桶规则要一样(分桶字段一致,分桶个数成倍数关系)。
-
分析分桶join数据快的原因:hash散列提高关联效率
2、全局排序和局部排序
2.1、Order By
- 含义:全局排序,最终使用一个reduceTask来完成排序,就算你设置了多个也没用
- 注意事项:如果数据量很大,使用Order By来排序效率非常低
select * from table order by guid
2.2、Sort By
-
含义:局部排序,使用多个ReduceTask来运行,那么每个ReduceTask输出的结果是有序的,但整体结果无序。
-
应用场景:数据量很大但是需要进行全局排序
select * from table sort by guid
- 实现方案:
①使用一个Reducer,只输出一个Reduce文件
#进行相关参数设置
set mapreduce.job.reduces=1;
#SQL实现
select * from table order by guid desc
②使用多个Reducer
- 实现原理:范围分区(分桶distribute by)+局部排序(每个桶内进行sort by)
#进行相关参数设置
set mapreduce.job.reduces=4;
#SQL实现
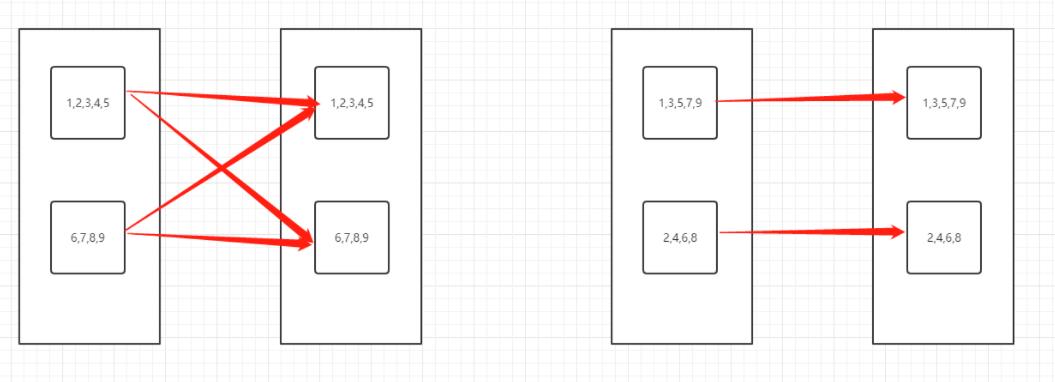
select * from table distribute by(case when guid >= 0 then A
when guid >=10 then B
when guid >=20 then C
else D) sort by guid
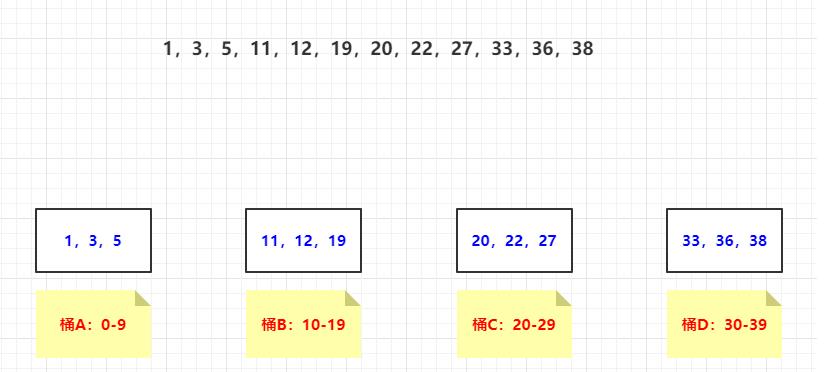
- 分桶规则指定:通过采样确定数据分布规律
①第一步:模糊采样
#采样方式:通过随机数的方式将数据打散分布,之后取前100条
select * from table sort by rand() - 0.5 limit 100;
②第二步:确定范围
- 将采样后的数据进行排序,之后切分10个分区来做
- 第一个分区取最后一条数据,其余分区同理
2.3、distribute by
- 含义:分桶查询
- 应用场景:
- ①必须设置reduceTask的个数
- ②查询中,必须设置distribute by来设置分桶规则:hash散列
set mapreduce.job.reduce=3
select * from table distribute by guid
2.4、cluster by
- 含义:如果sort by的字段和distribute by的字段一样,就可以简写
cluster by guid = distribute by guid order by guid
- 运行规则:数据分成n段,每一段的ID都是按照hash散列的规则得到的结果都是一样,即hash(id)%n=余数
3、常用函数
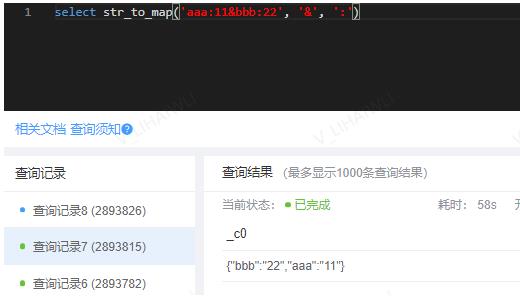
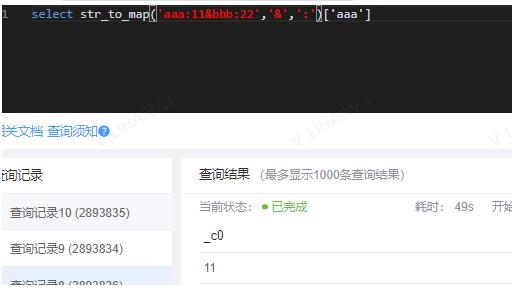
3.1、str_to_map()
- 作用:使用两个分隔符将文本拆分为键值对。 Delimiter1将文本分成K-V对,Delimiter2分割每个K-V对。对于delimiter1默认分隔符是’,’,对于delimiter2默认分隔符是’=’。
3.2、explode
- 作用:将一行转换成多行
select explode(str_to_map("a:1,b:2,c:3",",",":"));
#运行结果
a 1
b 2
c 3
3.3、split()[]
- 作用:通过固定字符对字符串进行切割,可通过索引获得切割后的结果
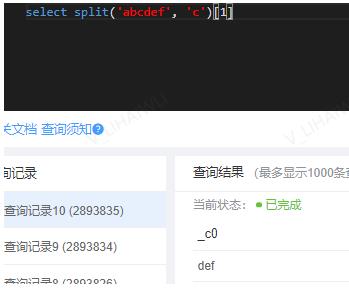
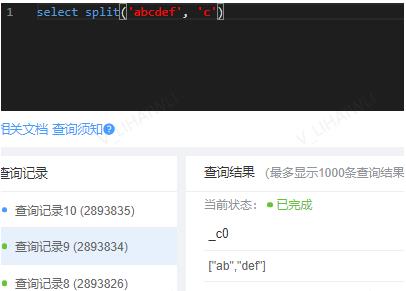
4、高级聚合函数
- 高级聚合函数:相当于group by加强
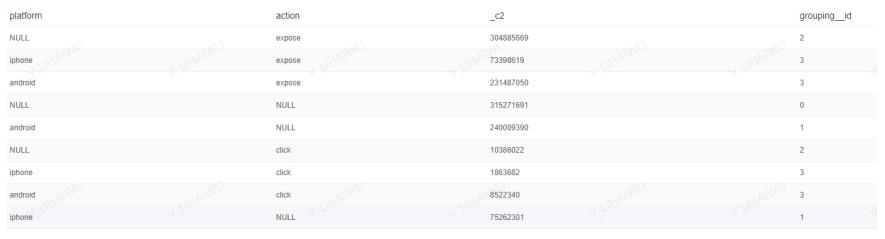
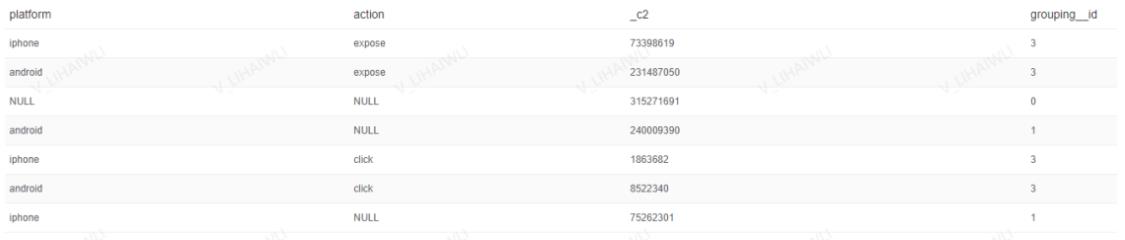
4.1、Grouping sets
- 作用:为自定义维度,根据需要分组即可
grouping sets((device_id),(os_id),(device_id,os_id),())<=>
group by device_id union all group by os_id union all device_id,os_id
select
platform
,action
,count(guid)
,GROUPING__ID
,rpad(reverse(bin(cast(GROUPING__ID AS bigint))),3,'0')
from mtt_search.t_od_mtt_search_three_ecological_novel
where ds = 11111111
group BY
platform
,action
grouping sets((platform),(action),(platform,action),())
- 运行结果
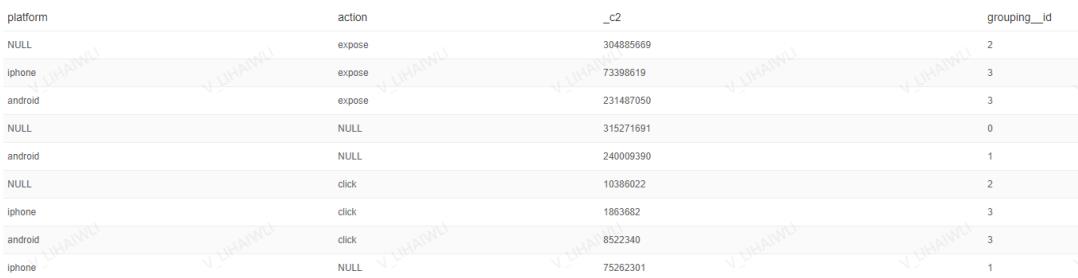
4.2、cube函数
- 作用:分组组合最全,是各个维度值的笛卡尔(包含null)组合,
group by a,b,c with cube <=> grouping sets((a,b,c),(a,b),(a,c),(b,c),(a),(b),(c),())
select
platform
,action
,count(guid)
,GROUPING_ID
from mtt_search.t_od_mtt_search_three_ecological_novel
where ds = 11111111
group BY
platform
,action
with cube
- 运行结果:
4.3、rollup函数
- 含义:从右到做递减多级的统计
group by a,b,c with rollup <=> grouping sets((a,b,c),(a,b),(a),())
select
platform
,action
,count(guid)
,GROUPING_ID
from mtt_search.t_od_mtt_search_three_ecological_novel
where ds = 11111111
group BY
platform
,action
with rollup
- 运行结果
5、Hive处理Json数据
(1)原始数据如下
"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"
"movie":"661","rate":"3","timeStamp":"978302109","uid":"1"
"movie":"914","rate":"3","timeStamp":"978301968","uid":"1"
"movie":"3408","rate":"4","timeStamp":"978300275","uid":"1"
"movie":"2355","rate":"5","timeStamp":"978824291","uid":"1"
.....
"movie":"1197","rate":"3","timeStamp":"978302268","uid":"1"
"movie":"1287","rate":"5","timeStamp":"978302039","uid":"1"
"movie":"2804","rate":"5","timeStamp":"978300719","uid":"1"
"movie":"594","rate":"4","timeStamp":"978302268","uid":"1"
(2)要求导入结果如下
| movie | rate | timestamp | uid |
|---|---|---|---|
| 1193 | 5 | 978300760 | 1 |
(3)解决方案
- 方案:可用内置 get_json_object 或者 自定义函数完成
-- 第一步:先放入中间表
create database if not exists nx_de_json_db;
use nx_de_json_db;
drop table if exists rate_json;
create table rate_json(line string) row format delimited;
load data local inpath '/home/bigdata/rating.json' into table rate_json;
-- 第二步:创建结果表
create table rate(movie int, rate int, unixtime int, userid int) row format
delimited fields terminated by '\\t';
-- 第三步:写解析语句进行插入
insert into table rate select
get_json_object(line,'$.movie') as moive,
get_json_object(line,'$.rate') as rate,
get_json_object(line,'$.timeStamp') as unixtime,
get_json_object(line,'$.uid') as userid
from rate_json;
6、企业三大面试题
6.1、最大值&累计值
(1)需求描述
- 原始表
#用户名,月份,访问次數
A,2015-01,5
A,2015-01,15
B,2015-01,5
A,2015-01,8
B,2015-01,25
A,2015-01,5
A,2015-02,4
A,2015-02,6
B,2015-02,10
B,2015-02,5
A,2015-03,16
A,2015-03,22
B,2015-03,23
B,2015-03,10
B,2015-03,11
- 报表产出
#每个用户截止到每月为止的最大单月访问次数和累计到该月的总访问次数
A 1 20 20 20
A 2 10 30 20
A 3 30 60 30
A 4 50 110 50
.....
B 1 2 2
B 2 10 12
B 3 20 32
B 4 50 82
(2)代码实现
- 第一步:先统计每个人的每个月的PV
- 第二步:之后通过分析函数每个用户截止到每月为止的最大单月访问次数和累计到该月的总访问次数,平均单月访问量,最小单月访问量
select
a.name,
a.month,
a.pv,
sum(a.pv) over (partition by a.name order by a.month rows between unbounded preceding and current row) as sumpv,
max(a.pv) over (partition by a.name order by a.month rows between unbounded preceding and current row) as maxpv,
min(a.pv) over (partition by a.name order by a.month rows between unbounded preceding and current row) as minpv,
avg(a.pv) over (partition by a.name order by a.month rows between unbounded preceding and current row) as avgpv
from
(select b.name as name, b.month as month, sum(b.pv) as pv from exercise_pv b
group by b.name, b.month) a;
6.2、行列转换
(1)行转列
- 作用:本身返回一张虚拟表,使用later view可直接关联两张表,保持原有映射关系。
# Map数据进行行转列
select
t1.uid
,t2.key
,t2.value
from t1
later view explode(map(
'c1',c1,
'c2',c2,
'c3',c3
)) t2 as key,value
# 字符串数据进行行转列
select s.name,temp.x from s later view explode(split('score',',')) temp as x
(2)列转行
- 作用:将多行数据融为一行
str_to_map(concat_ws(','collect_set(':',key_clm,value_clm))))
select
uid
,kv['c1'] as c1
,kv['c2'] as c2
,kv['c3'] as c3
from(
select
uid
,str_to_map(concat_ws(','collect_set(':',key_clm,value_clm)))) kv
from vtable
group by uid
) temp
6.3、TopN实现
(1)需求描述
- 源表数据
#id,name,age,favors
#id,姓名,年龄,爱好
1,huangxiaoming,45,a-c-d-f
2,huangzitao,36,b-c-d-e
3,huanglei,41,c-d-e
4,liushishi,22,a-d-e
5,liudehua,39,e-f-d
6,liuyifei,35,a-d-e
- 报表产出
#求出每种爱好中,年龄最大的两个人(爱好,年龄,姓名)注意思考一个问题:如果某个爱好中的第二大年龄有多个相同的怎么办?
a huangxiaoming 45
a liuyifei 35
b huangzitao 36
c huangixaoming 45
c huanglei 41
(2)代码实现
- 思路总结:
- 1、explode() + lateral view
- 2、求TopN + row_number()
from
(
select b.id, b.name, b.age, b.favor,
row_number() over (partition by b.favor order by b.age desc) as rank
from
(
select a.id as id, a.name as name, a.age as age, favor_view.favor
from exercise_topn a
LATERAL VIEW explode(split(a.favors, "-")) favor_view as favor
) b
) c
where c.rank <= 2;
以上是关于架构师之路Learn Day7之Hive生产环境最佳实践的主要内容,如果未能解决你的问题,请参考以下文章