每日一练:Python爬虫爬取全国新冠肺炎疫情数据实例详解,使用beautifulsoup4库实现
Posted 挣扎的蓝藻
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了每日一练:Python爬虫爬取全国新冠肺炎疫情数据实例详解,使用beautifulsoup4库实现相关的知识,希望对你有一定的参考价值。
Python 爬虫篇 - 爬取全国新冠肺炎疫情数据实例详解
- 效果图展示
- 第一章:疫情信息的下载与数据提取
- ① 爬取页面数据到本地
- ② json 字符串正则表达式分析
- ③ 提取数据中的 json 字符串
- 第二章:疫情信息数据分析
- ① 提取 json 字符串里的省份疫情数据并显示
- ② 显示查询省份的城市疫情数据
[ 系列文章篇 ]
Python 地图篇 - 使用 pyecharts 绘制世界地图、中国地图、省级地图、市级地图实例详解
[ 专栏推荐 ]
Python 短视频自动化发布,包含抖音、快手、bilibili、小红书、微视、好看视频、西瓜视频、微信视频号等 10 余种平台
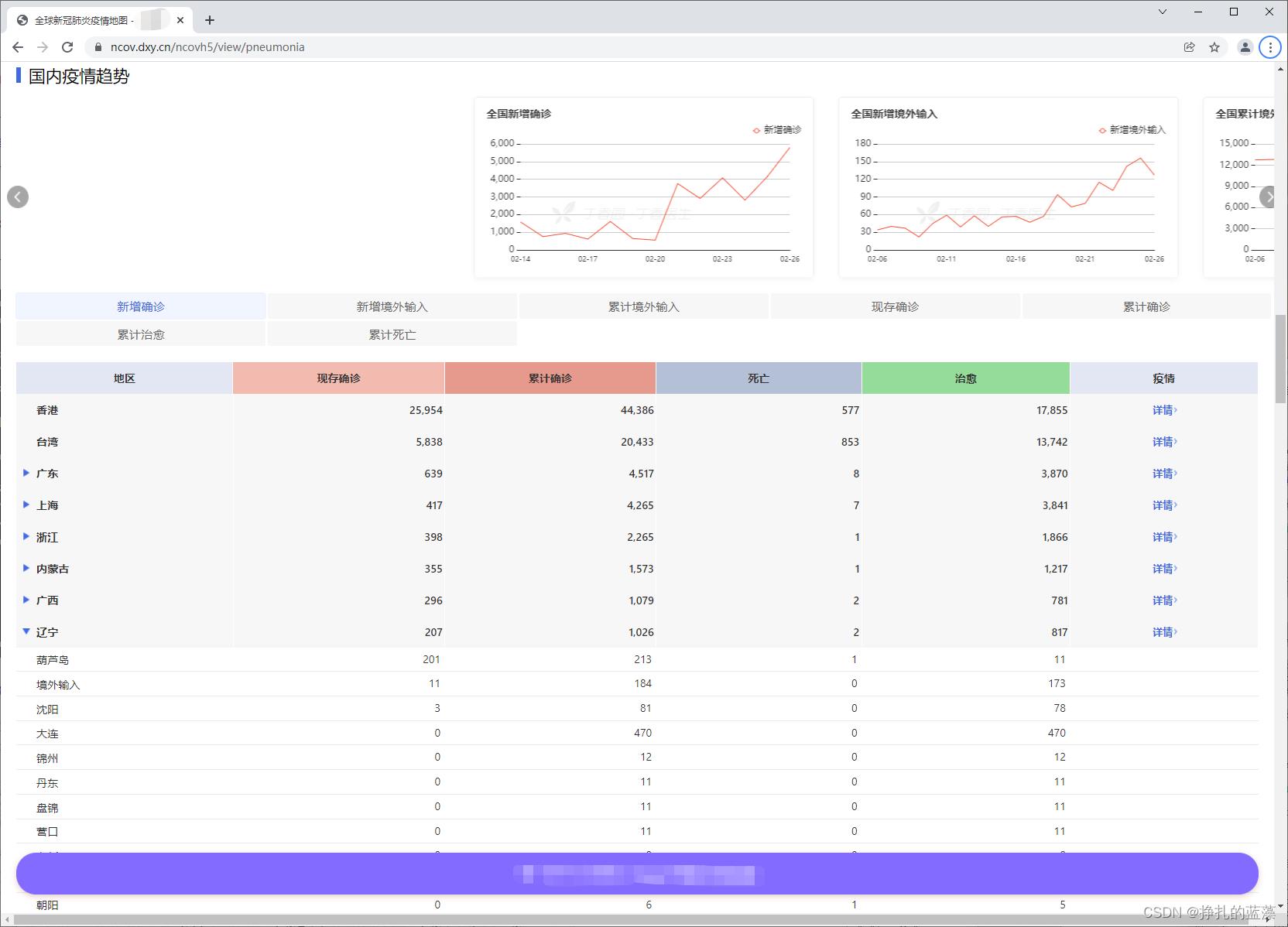
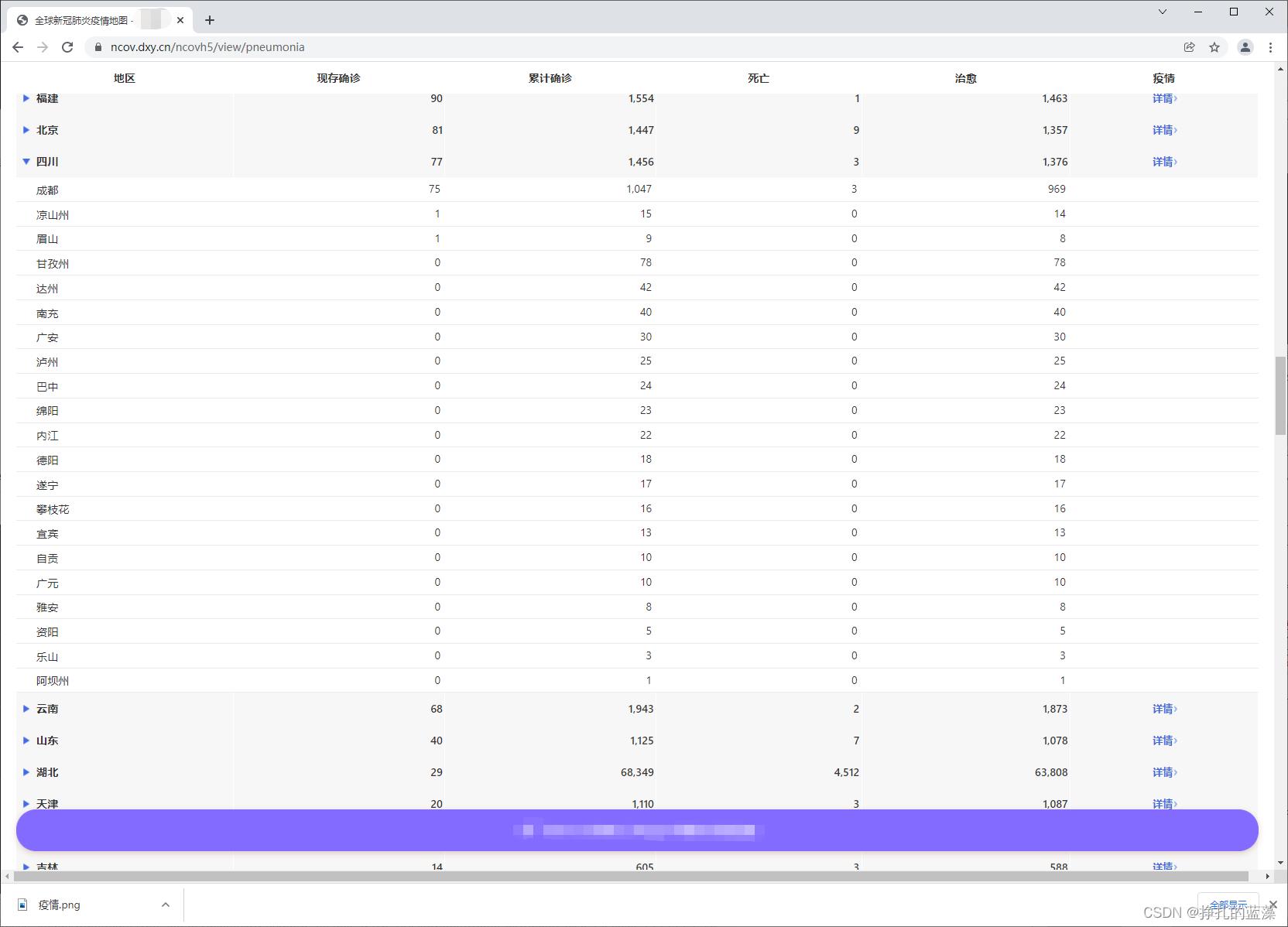
效果图展示
这是省份的:

这是城市的:

第一章:疫情信息的下载与数据提取
① 爬取页面数据到本地
通过 BeautifulSoup 库解析代码,将疫情信息内容下载到本地 txt 文件用于数据分析使用。
from urllib.request import urlopen
from bs4 import BeautifulSoup
def dxy_data_down(article_url):
"""
xiaolanzao, 2022.02.27
【作用】
下载疫情数据信息
【参数】
article_url : 需要下载数据的地址
【返回】
无
"""
url = urlopen(article_url)
soup = BeautifulSoup(url, 'html.parser') # parser解析
f = open("疫情数据.txt","w",encoding="utf-8")
f.write(str(soup))
f.close()
dxy_data_down("https://ncov.dxy.cn/ncovh5/view/pneumonia")
下载后的数据

② json 字符串正则表达式分析
通过分析文件查找到
需要数据的 json 字符串前关键词 "try window.getAreaStat = "
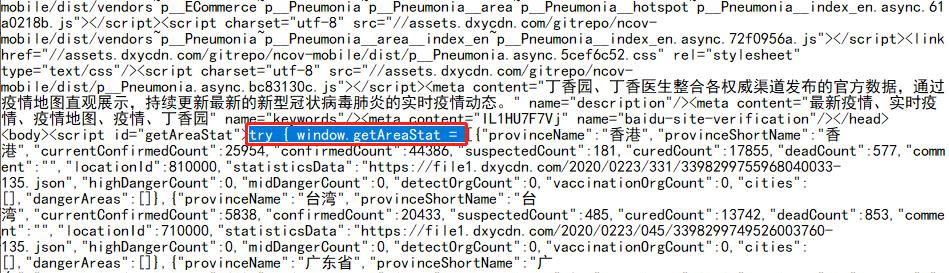
json 字符串后关键词 catch(e)
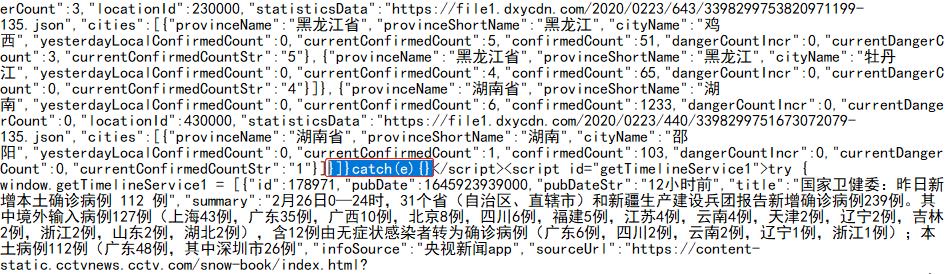
(.*?) 是匹配所有内容。
整合的正则表达式为如下:
# json字符串前后关键词
json_start = "try window.getAreaStat = "
# 字符串包含的括号要进行转义
json_end = "catch\\(e\\)"
# json字符串正则匹配
# (.*?)是匹配所有内容
regular_key = json_start + "(.*?)" + json_end
③ 提取数据中的 json 字符串
读取本地文件,提取里面的 json 字符串数据。
import re
def get_json():
"""
xiaolanzao, 2022.02.27
【作用】
读取本地文件,获取json信息
【参数】
无
【返回】
json字符串
"""
# 读取本地文件
f = open("疫情数据.txt", "r", encoding="utf-8")
f_content = f.read()
f.close()
# json字符串前后关键词
json_start = "try window.getAreaStat = "
# 字符串包含的括号要进行转义
json_end = "catch\\(e\\)"
# json字符串正则匹配
# (.*?)是匹配所有内容
regular_key = json_start + "(.*?)" + json_end
# 参数rs.S可以无视换行符,将所有文本视作一个整体进行匹配
re_content = re.search(regular_key, f_content, re.S)
# group()用于获取正则匹配后的字符串
content = re_content.group()
# 去除json字符串的前后关键词
content = content.replace(json_start, '')
# 尾巴要去掉转义符号
json_end = "catch(e)"
content = content.replace(json_end, '')
print(content)
return content
json_content = get_json()
读取后的内容:

第二章:疫情信息数据分析
① 提取 json 字符串里的省份疫情数据并显示
方法里所传入的数据是上面返回的 json 字符串。
import json
def display_provinces(json_content):
"""
xiaolanzao, 2022.02.27
【作用】
展示省份疫情
【参数】
json_content : json字符串
【返回】
无
"""
# 将字符串转化为字典
json_data = json.loads(json_content)
# 省份数据展示
print("全国各省份疫情数据如下:")
for i in json_data:
print("【省份名】:" + i["provinceName"])
print("现存确诊:" + str(i["currentConfirmedCount"]))
print("累计确诊:" + str(i["confirmedCount"]))
print("死亡:" + str(i["deadCount"]))
print("治愈:" + str(i["curedCount"]))
print()
display_provinces(json_content)
运行效果图:

可以对比下数据是一致的
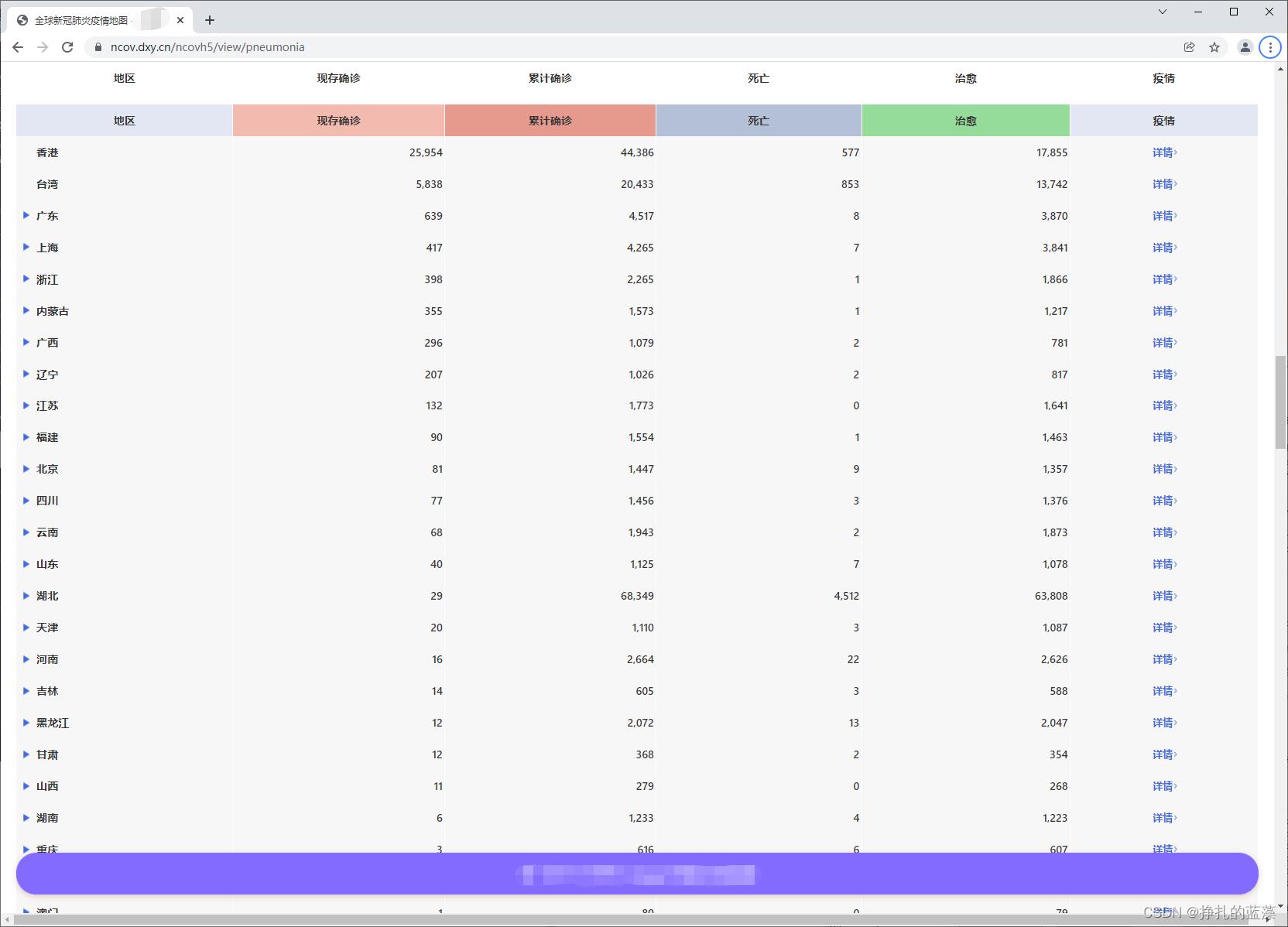
② 显示查询省份的城市疫情数据
城市数据在省份数据的 cities 里面。
import json
def display_citys(json_content, province_name):
"""
xiaolanzao, 2022.02.27
【作用】
展示城市疫情
【参数】
json_content : json字符串
province_name : 需要查询的省份名
【返回】
无
"""
# 将字符串转化为字典
json_data = json.loads(json_content)
# 省份数据展示
print(province_name + "疫情数据如下:")
for i in json_data:
# print(i)
if(i["provinceName"] == province_name):
# 读取里面的城市信息
try:
citys = i["cities"]
for ii in citys:
print("【城市名】:" + ii["cityName"])
print("现存确诊:" + str(ii["currentConfirmedCount"]))
print("累计确诊:" + str(ii["confirmedCount"]))
print("死亡:" + str(ii["deadCount"]))
print("治愈:" + str(ii["curedCount"]))
print()
except Exception as e:
print(e)
print("没有相应的城市信息!")
display_citys(json_content, "河北省")
运行效果图:
可以对比下数据是一致的
喜欢的点个赞❤吧!
以上是关于每日一练:Python爬虫爬取全国新冠肺炎疫情数据实例详解,使用beautifulsoup4库实现的主要内容,如果未能解决你的问题,请参考以下文章