Elasticsearch:在摄入管道中添加 NLP 任务
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:在摄入管道中添加 NLP 任务相关的知识,希望对你有一定的参考价值。
在我之前的文章 “在 Elasticsearch 中使用 PyTorch 进行现代自然语言处理的介绍” 里,我详细地介绍了 NLP 是如何在 Elastic Stack 中是如何工作的。如果我们已经对选中的模型的结果比较满意,那么我们可以把这些 NLP 的任务添加到 ingest pipeline 里,这样当我们的数据摄入时,我们可以对数据进行分析,并得到我们想要的分析的结果。
在进行摄入之前,我们可以按照文章 “Elasticsearch:Mapper Annotated Text Plugin 及其使用” 来安装 Mapper Annotated Text Plugin 插件,这是因为针对 full mask 类型的 NLP,它里面含有诸如 [mask] 这样的字符。
在今天的展示中,我使用 Elastic Stack 8.0。
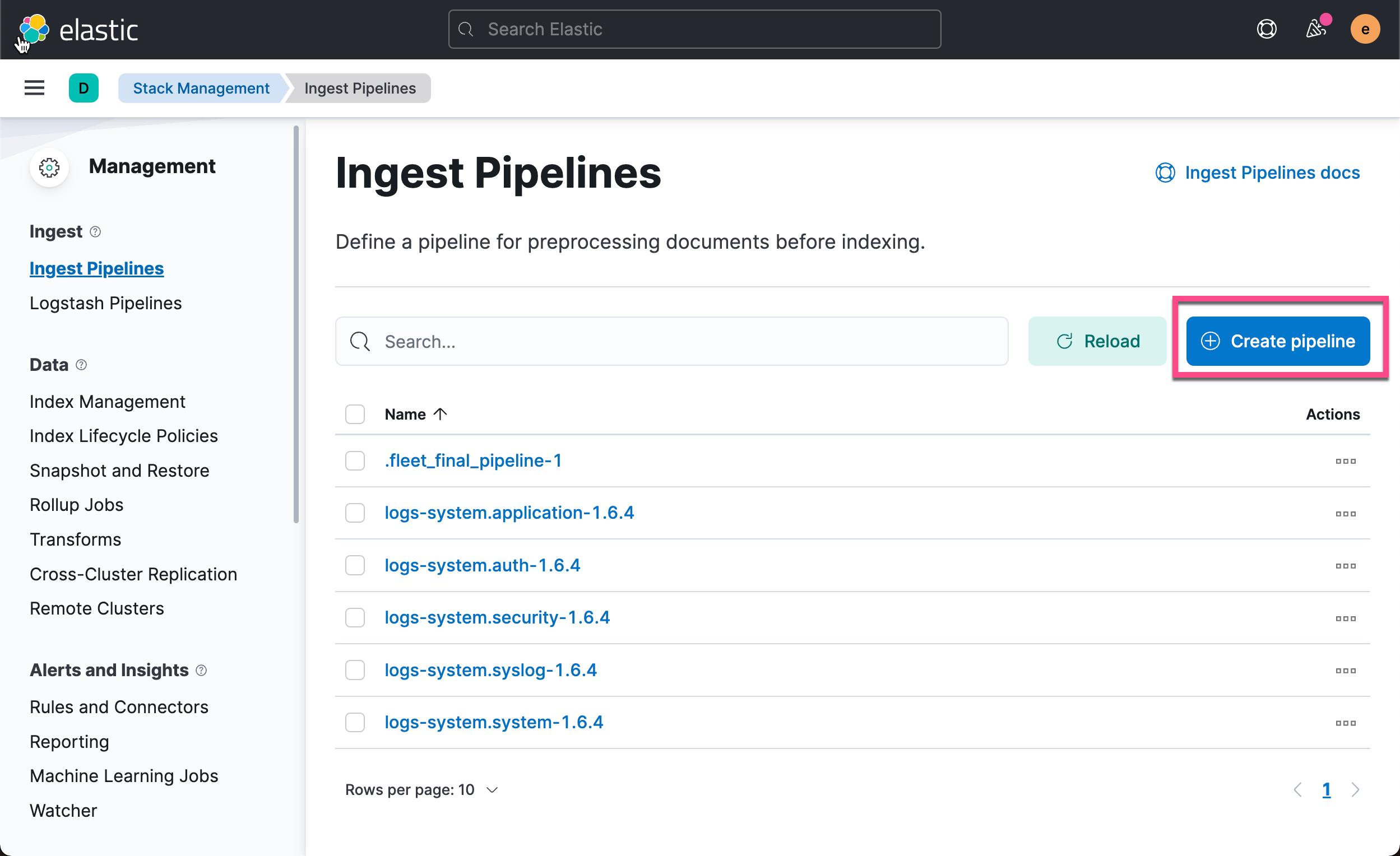
添加一个 inference processor 到 ingest pipeline 里去
我们打开 Kibana,并进入到 Stack Management:
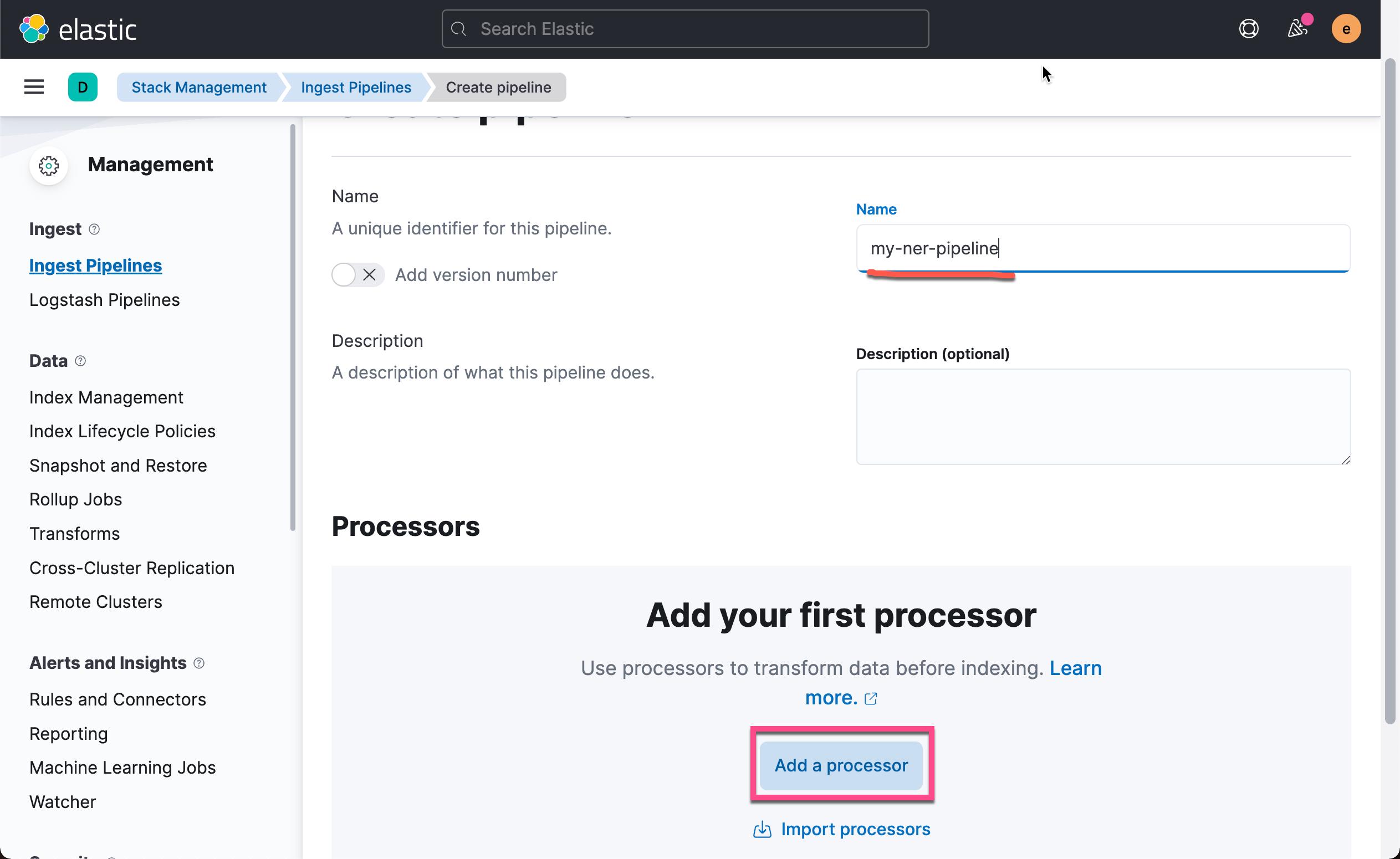
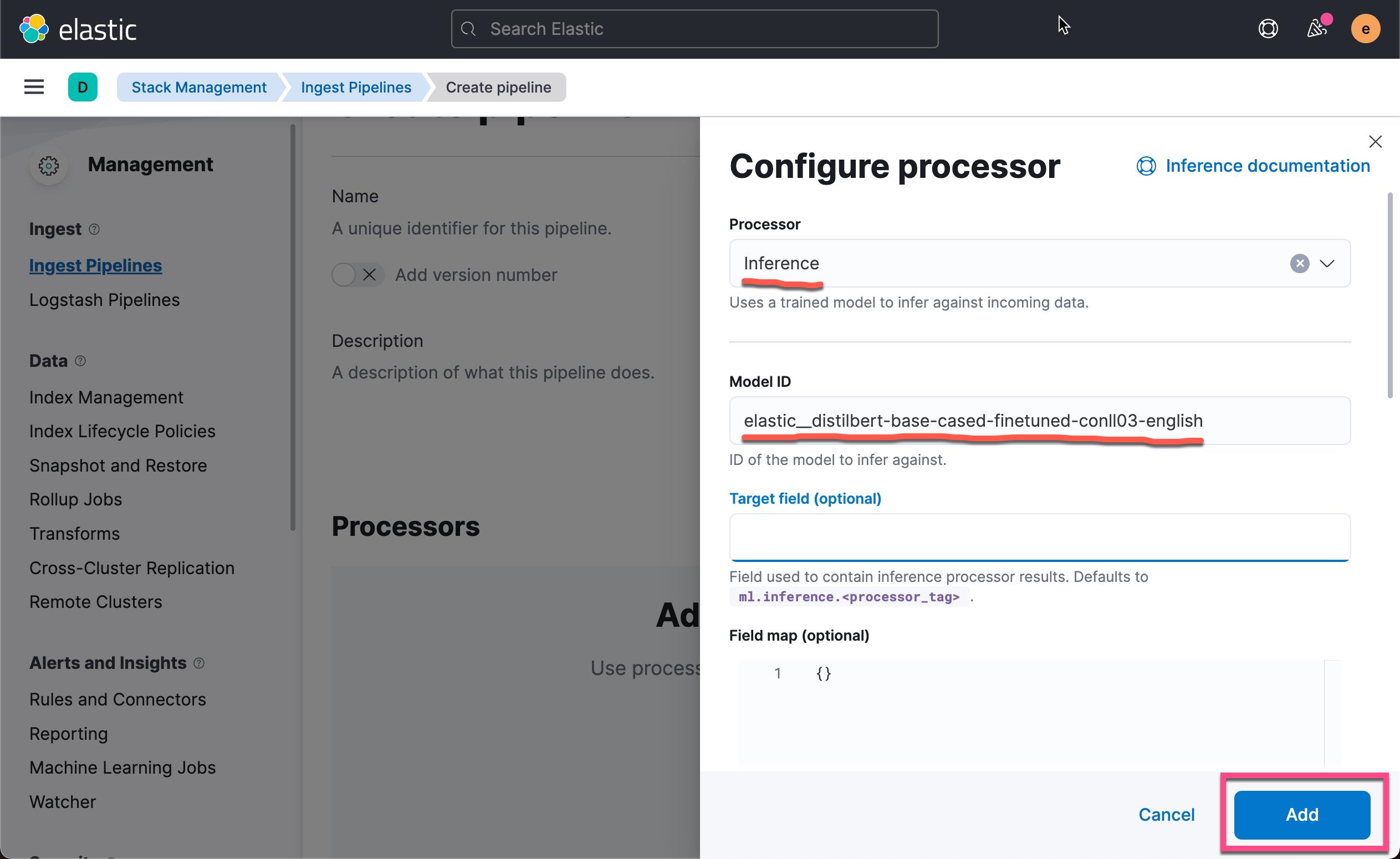
请注意上面的 Model ID。我们设置的值为 elastic__distilbert-base-cased-finetuned-conll03-english。这个值可以在如下的画面中找到:
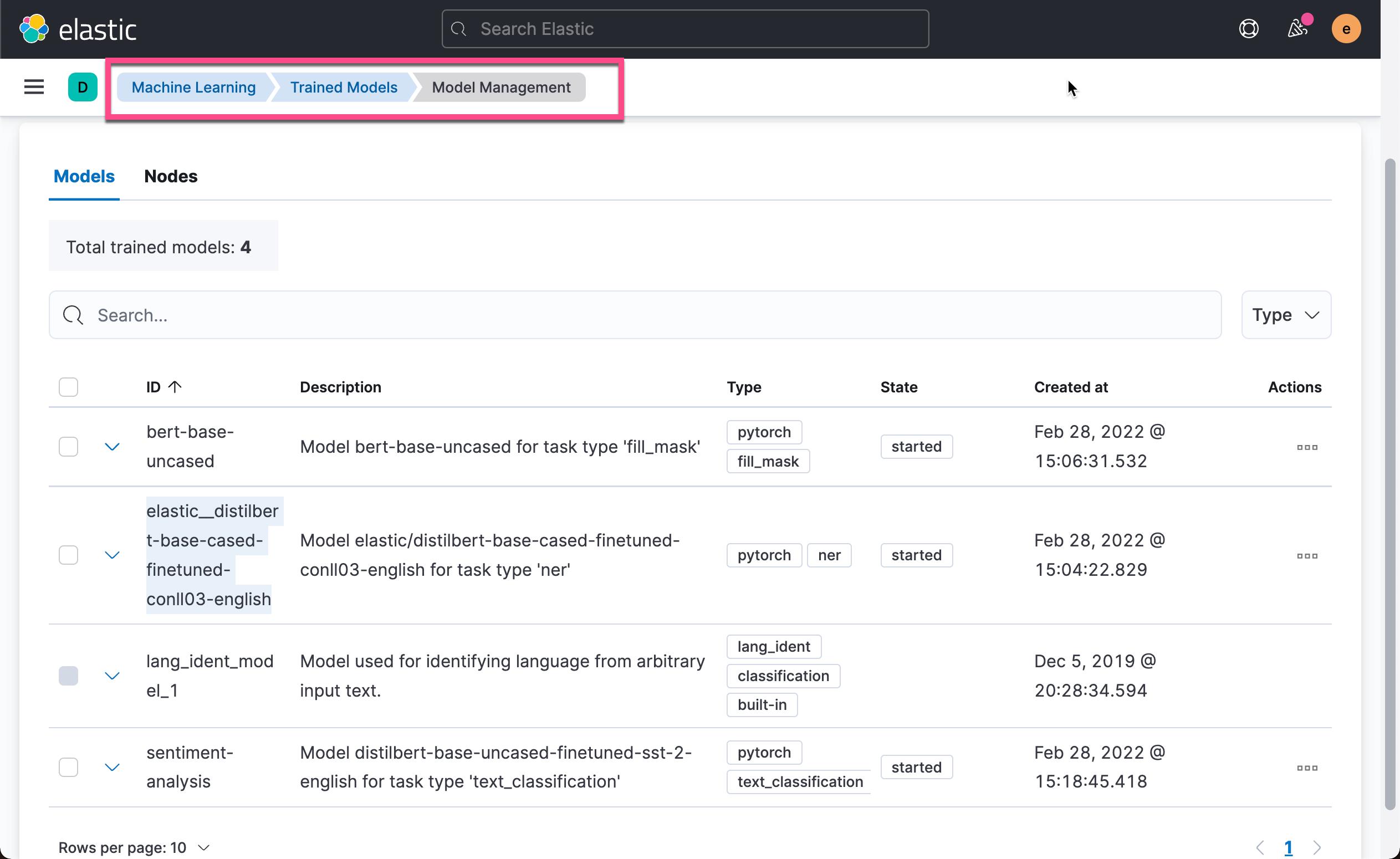
如果你还不知道如何生成这个 model ID,请阅读我之前的文章 “在 Elasticsearch 中使用 PyTorch 进行现代自然语言处理的介绍”。
点击上面的 Add 按钮:
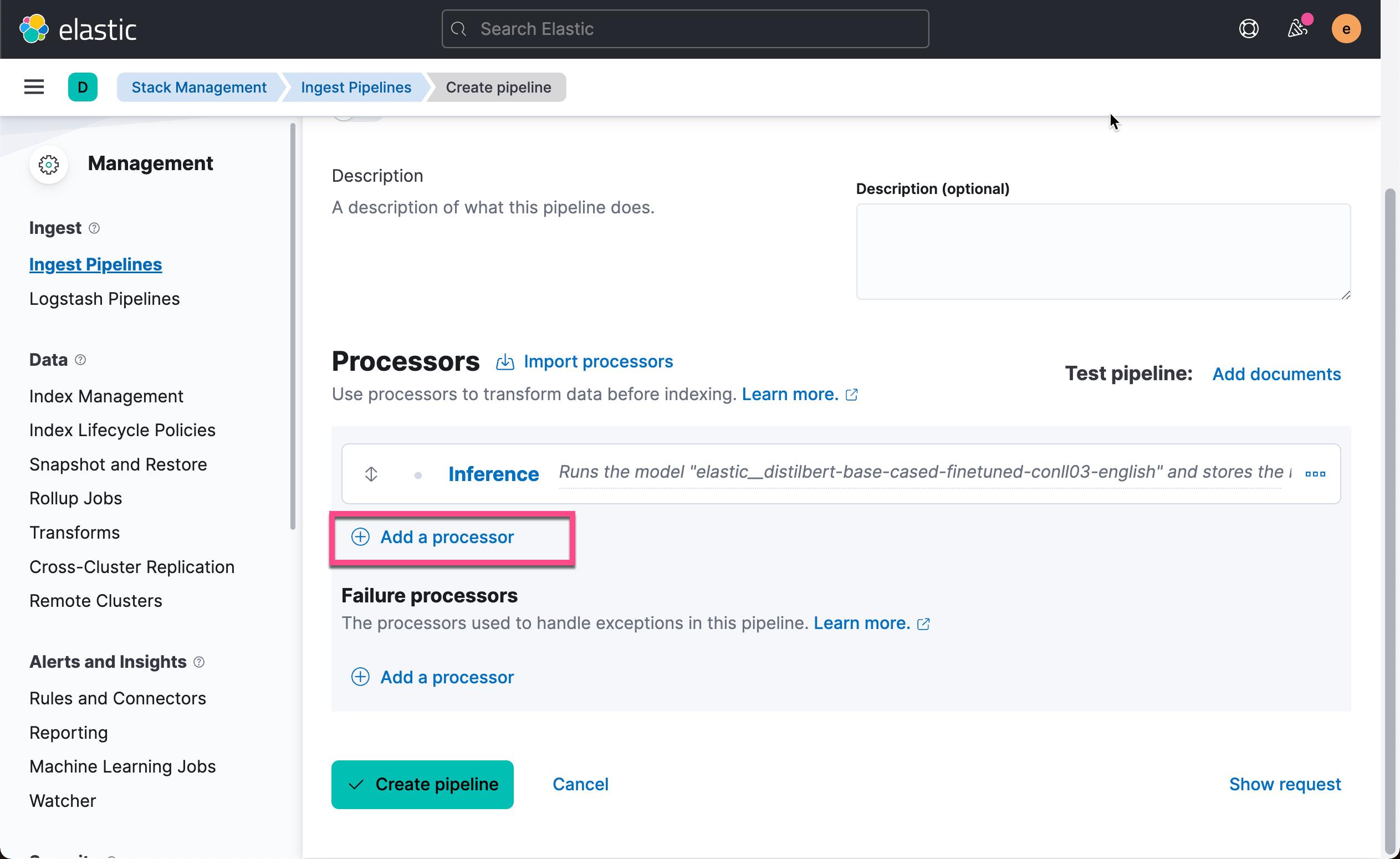
我们还可以添加一个额外的 set processor。我们在摄入时添加摄入的时间。点击上面的 Add a processor:
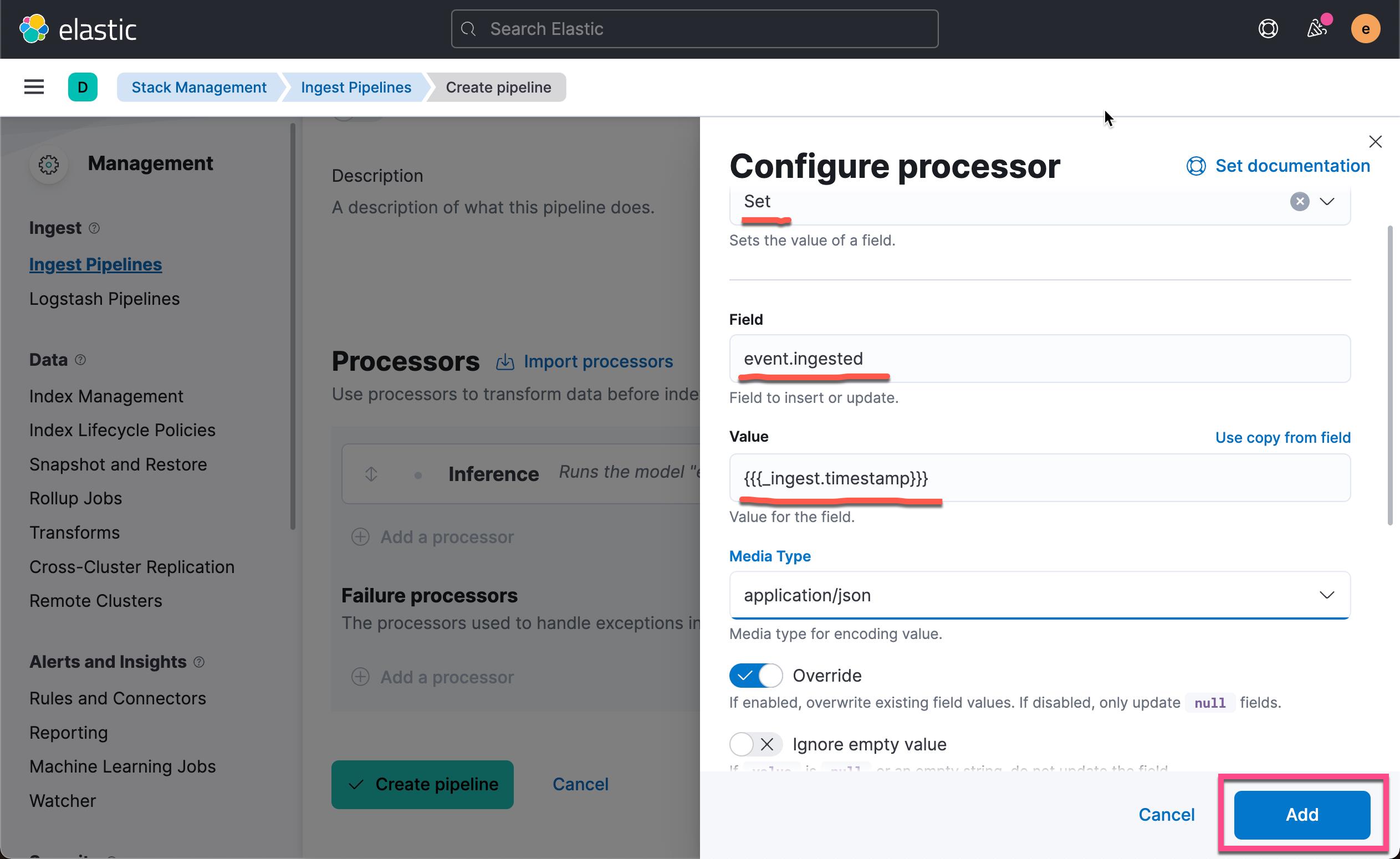
关于如何在 processor 中访问 ingest metadata,请参考官方文档。 点击上面的 Add 按钮:
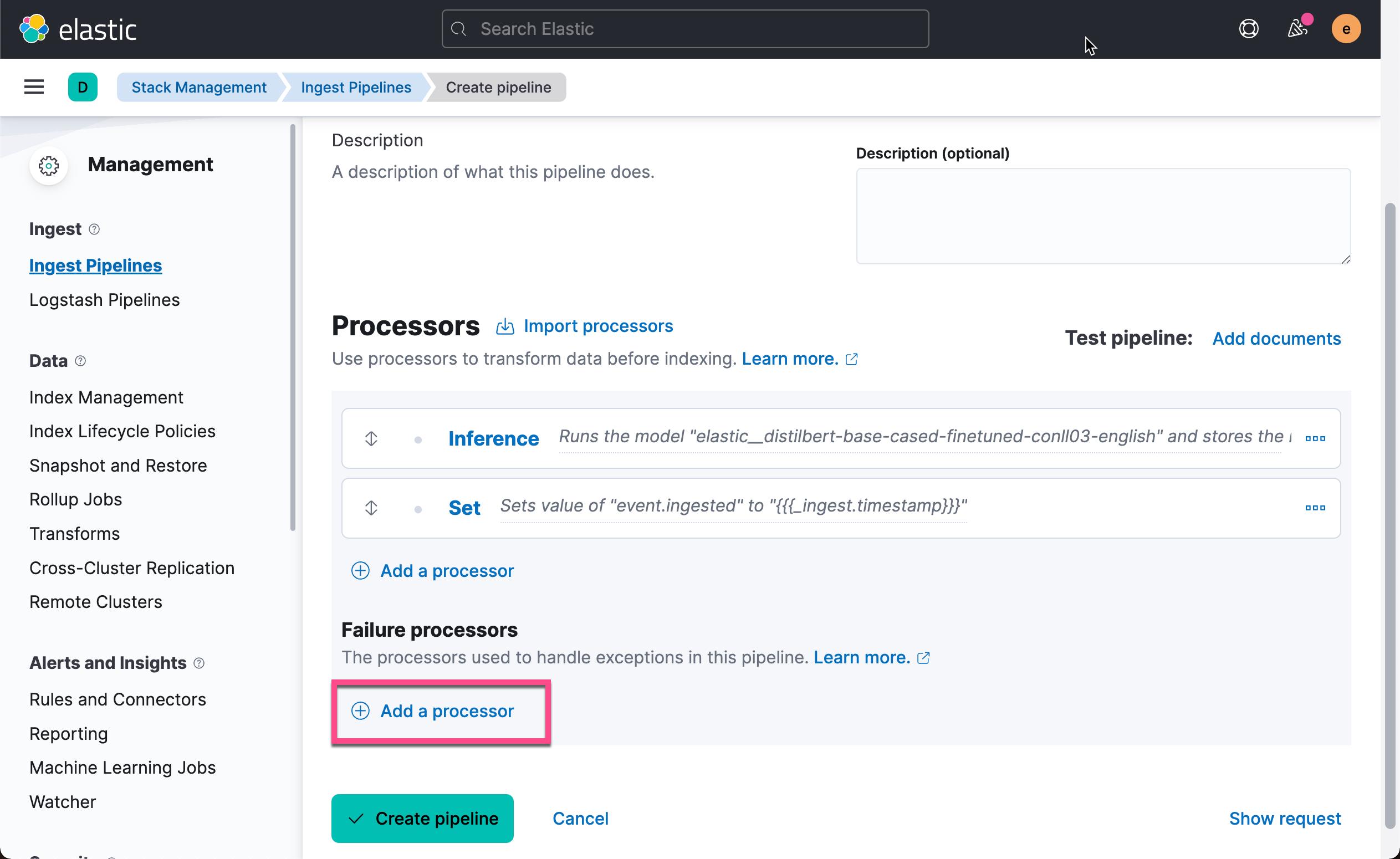
在数据摄入的过程中,我们可能会遇到错误的情况。我们在上面的 Failure processors 中点击 Add a processor 来添加一个或一些处理器来处理这个错误的情况:
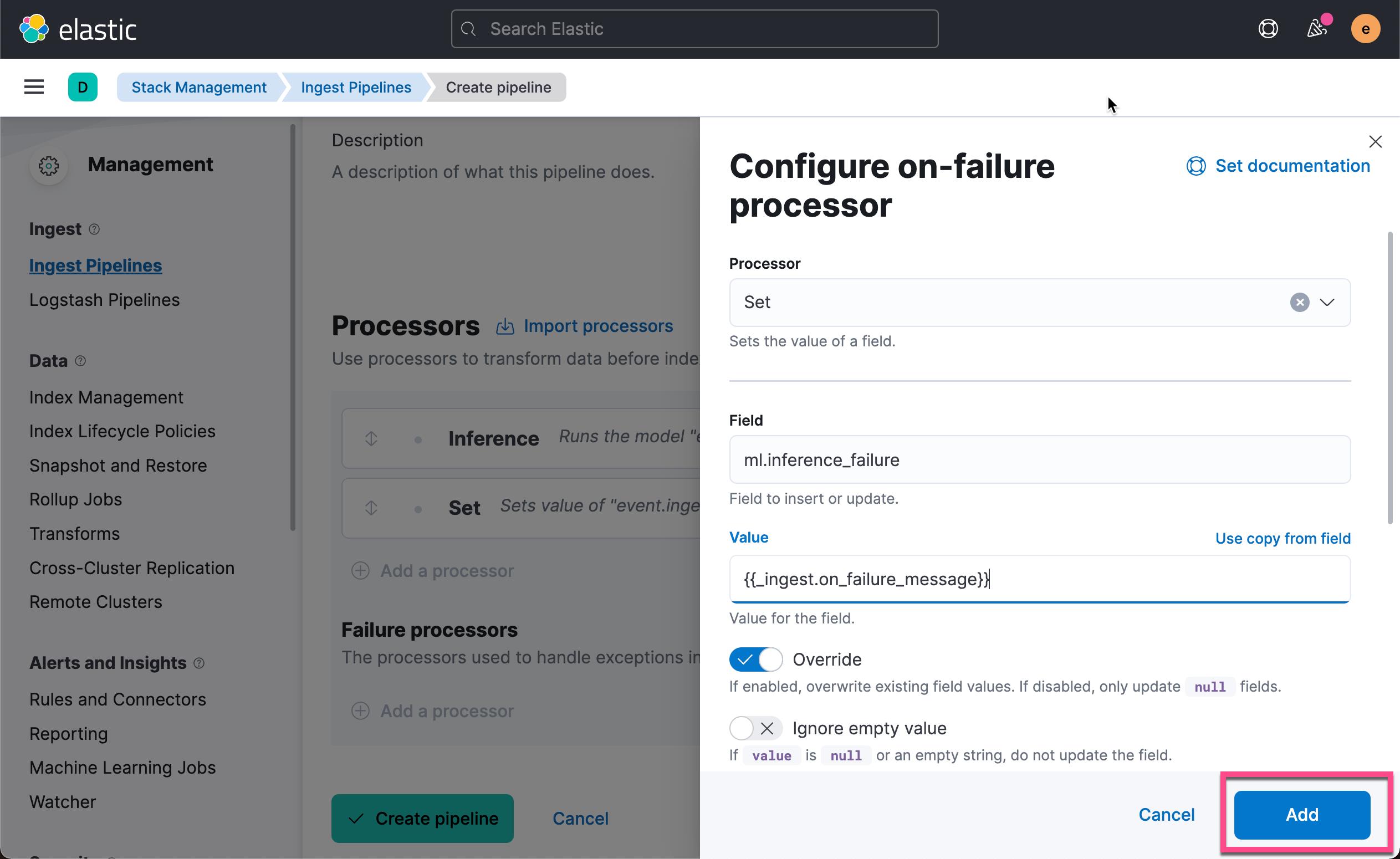
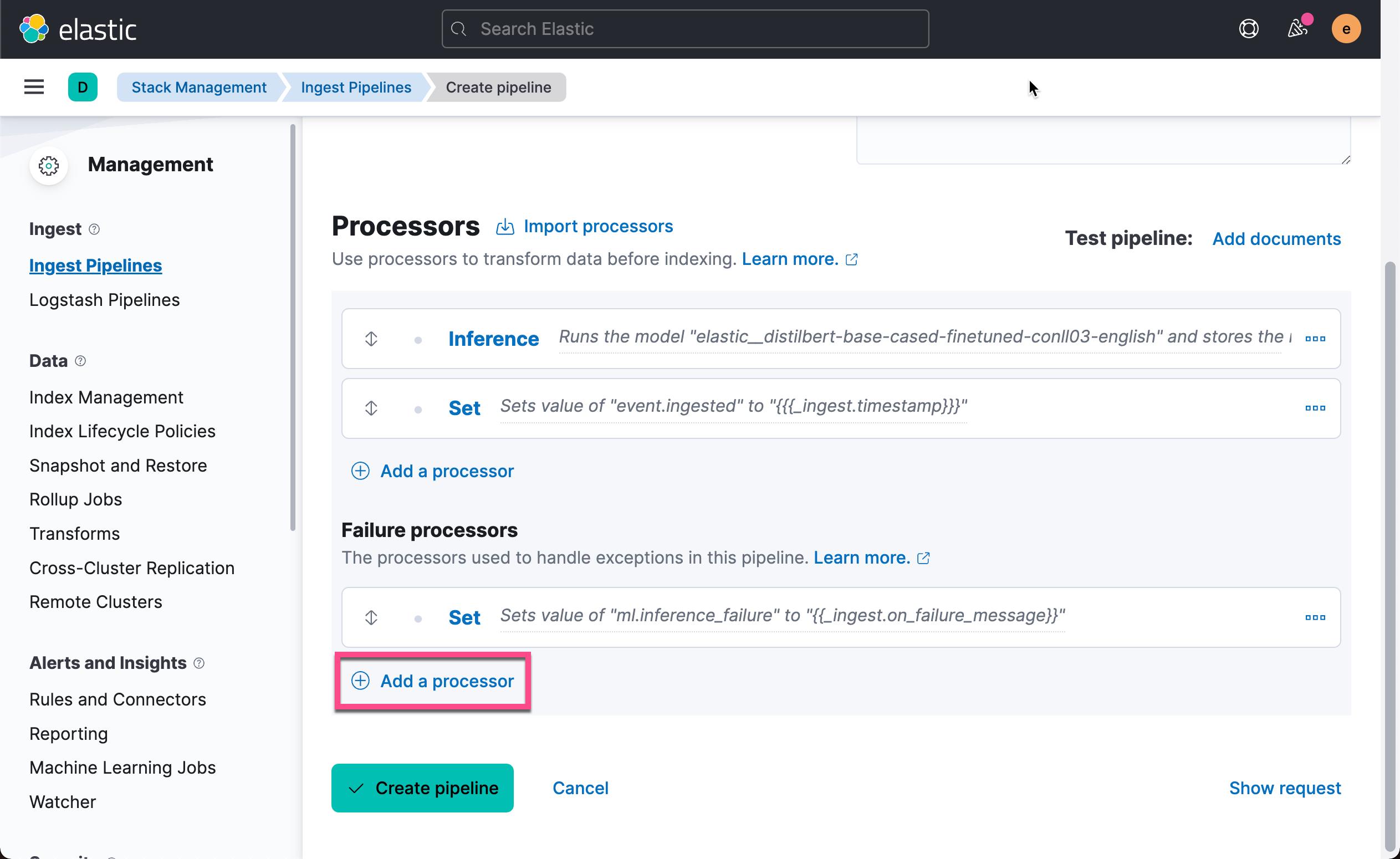
我们接下来添加一个设置处理器以将有问题的文档重新路由到不同的索引以进行故障排除。 使用 _index 元数据字段并将其值设置为新名称(例如 failed- _index )。 点击上面的 Add a processor:
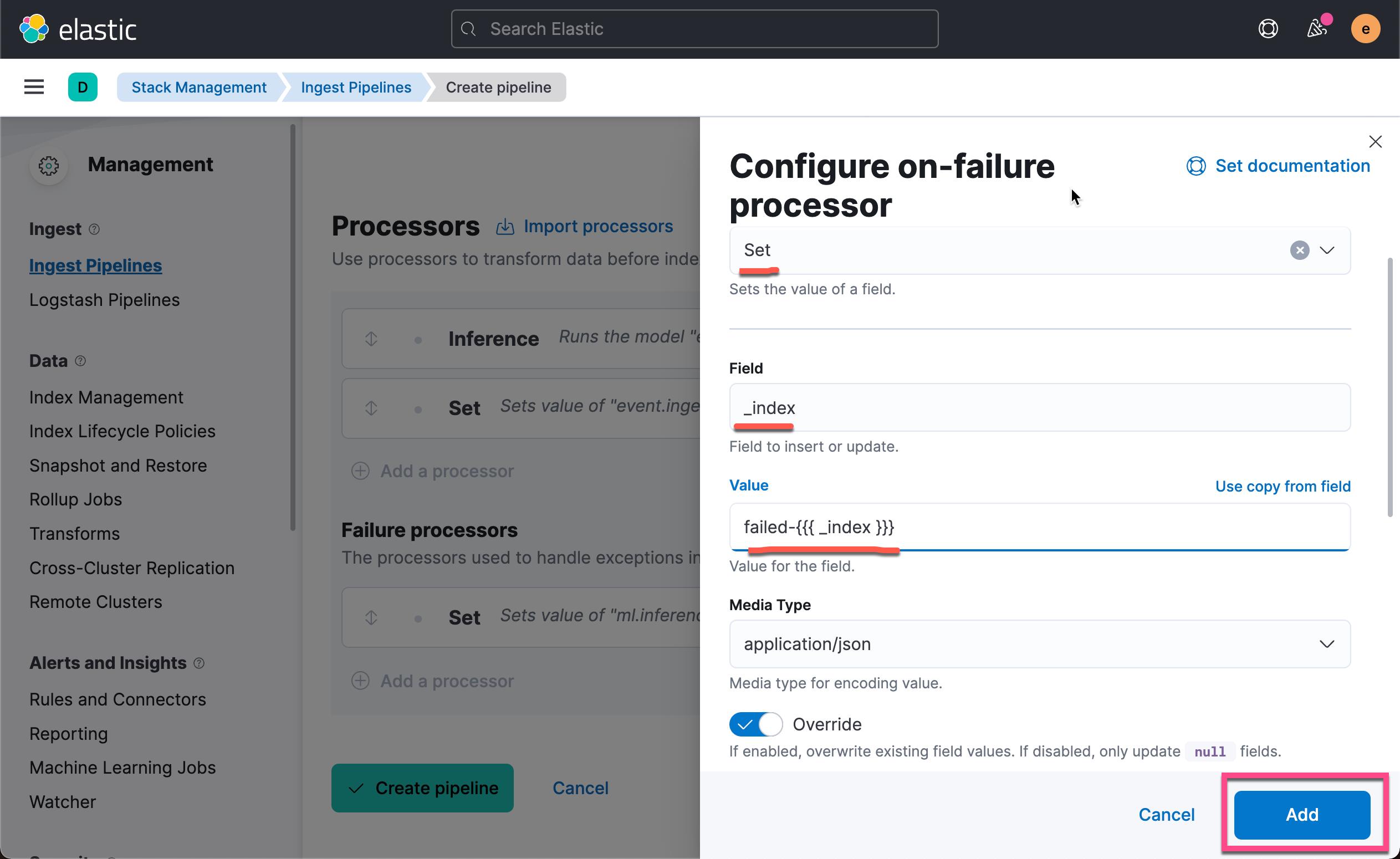
上面将会使得被处理的错误信息保存到 failed-<index> 索引中去。点击上面的 Add 按钮:
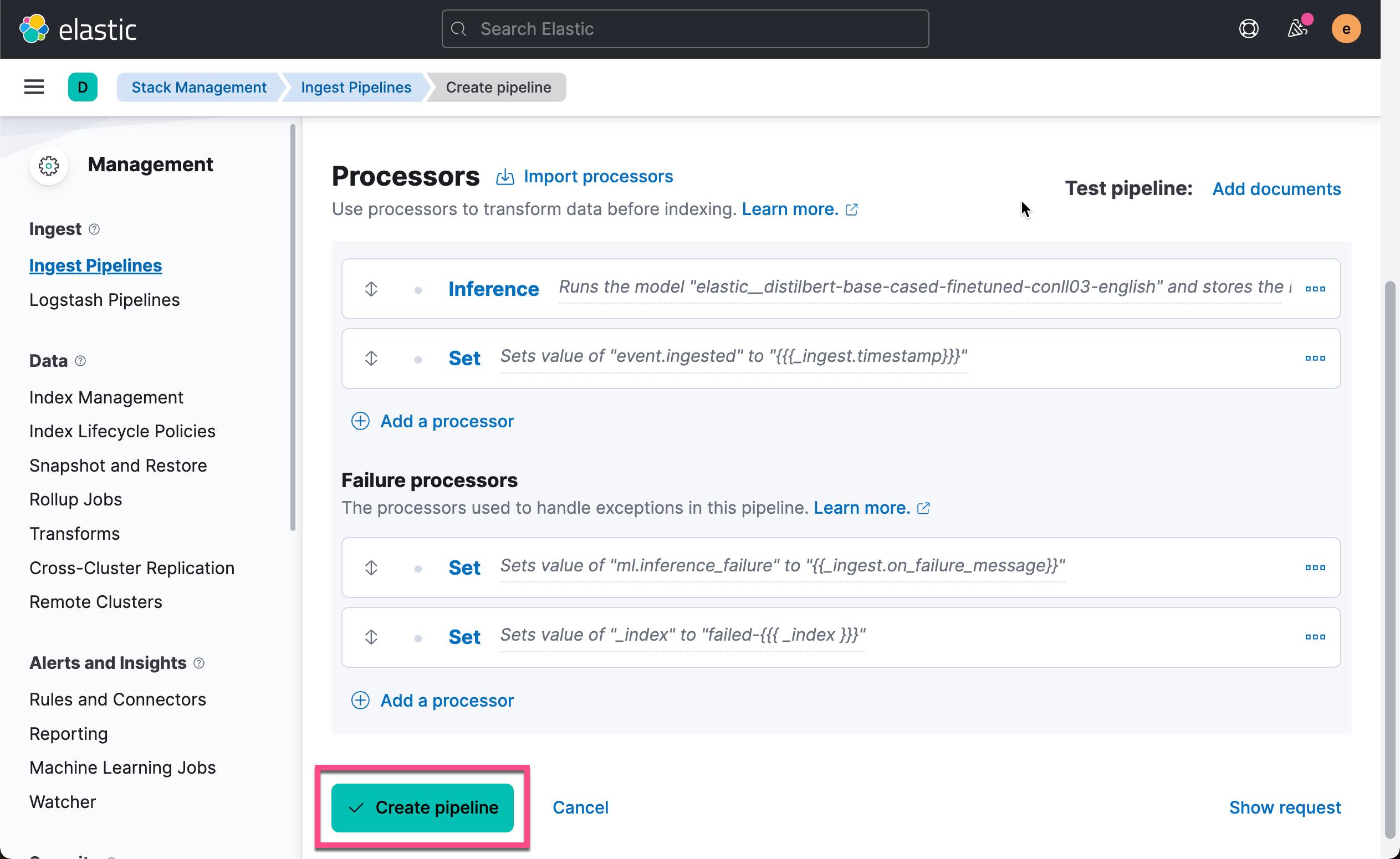
在上面的图中,我们可以看到已经被设置的 processors 及错误处理 processors。
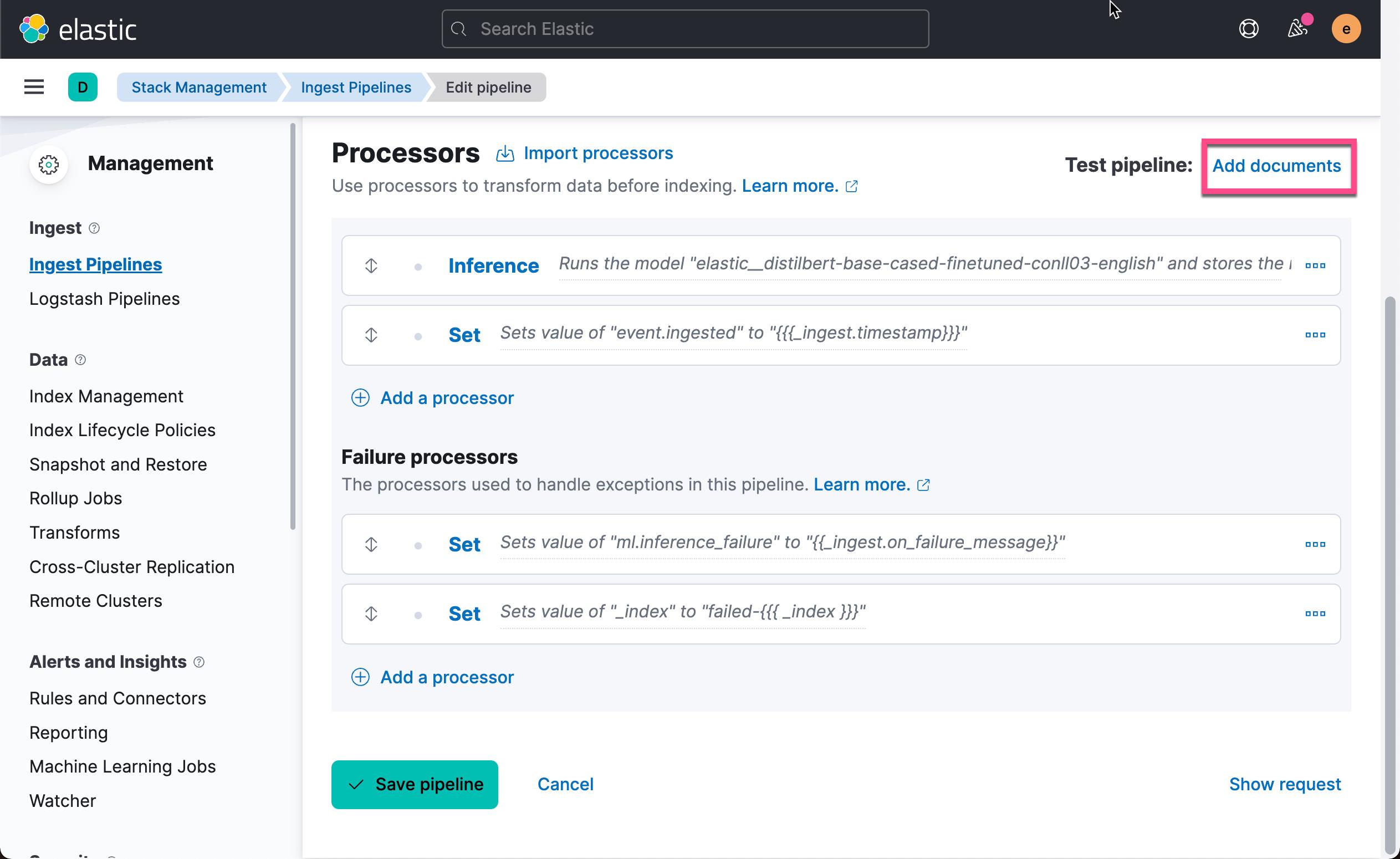
为了测试我们的 pipeline,我们点击上面的 Add documents:
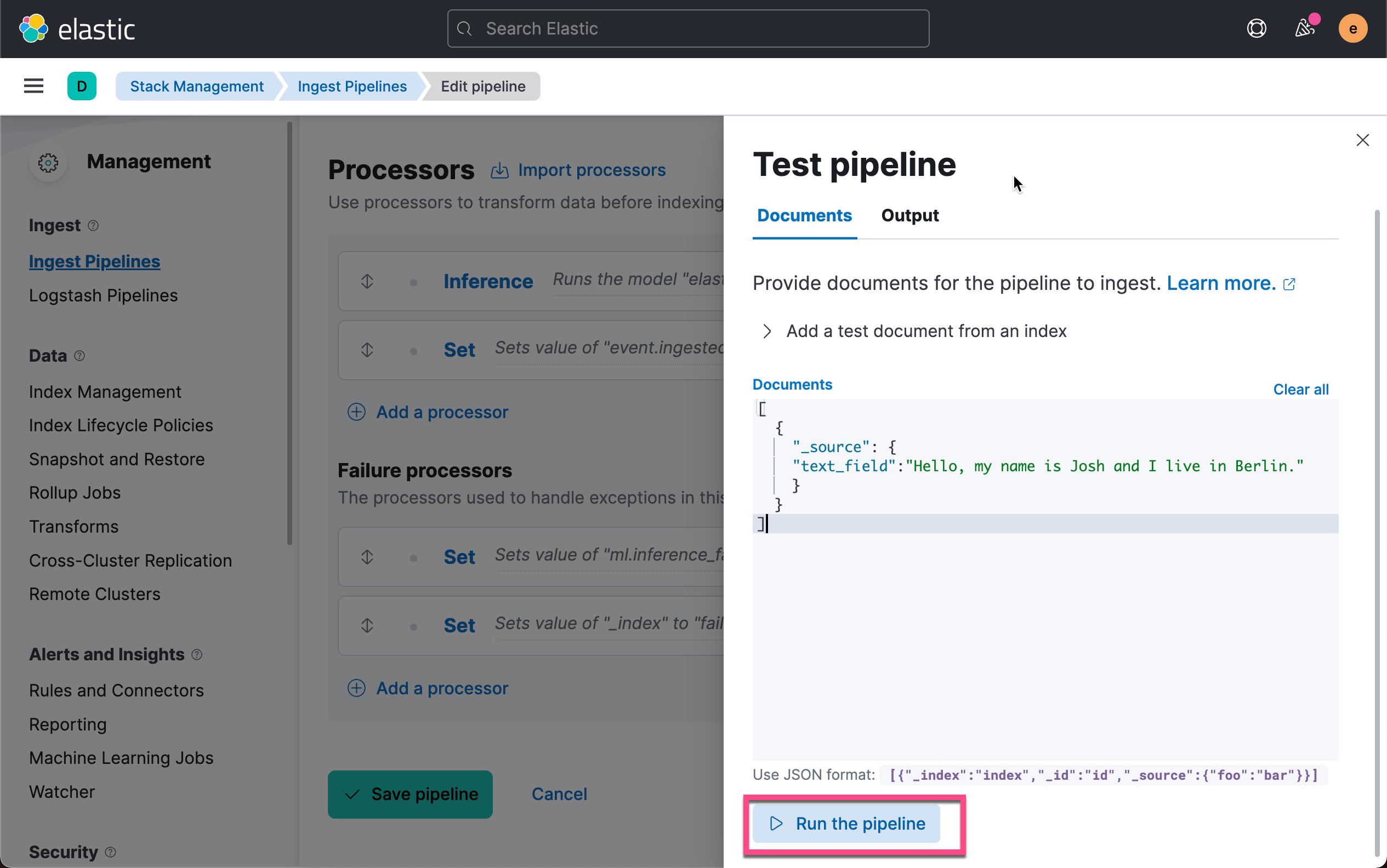
我们把如下的内容复制到 Documents 的编辑框里:
[
"_source":
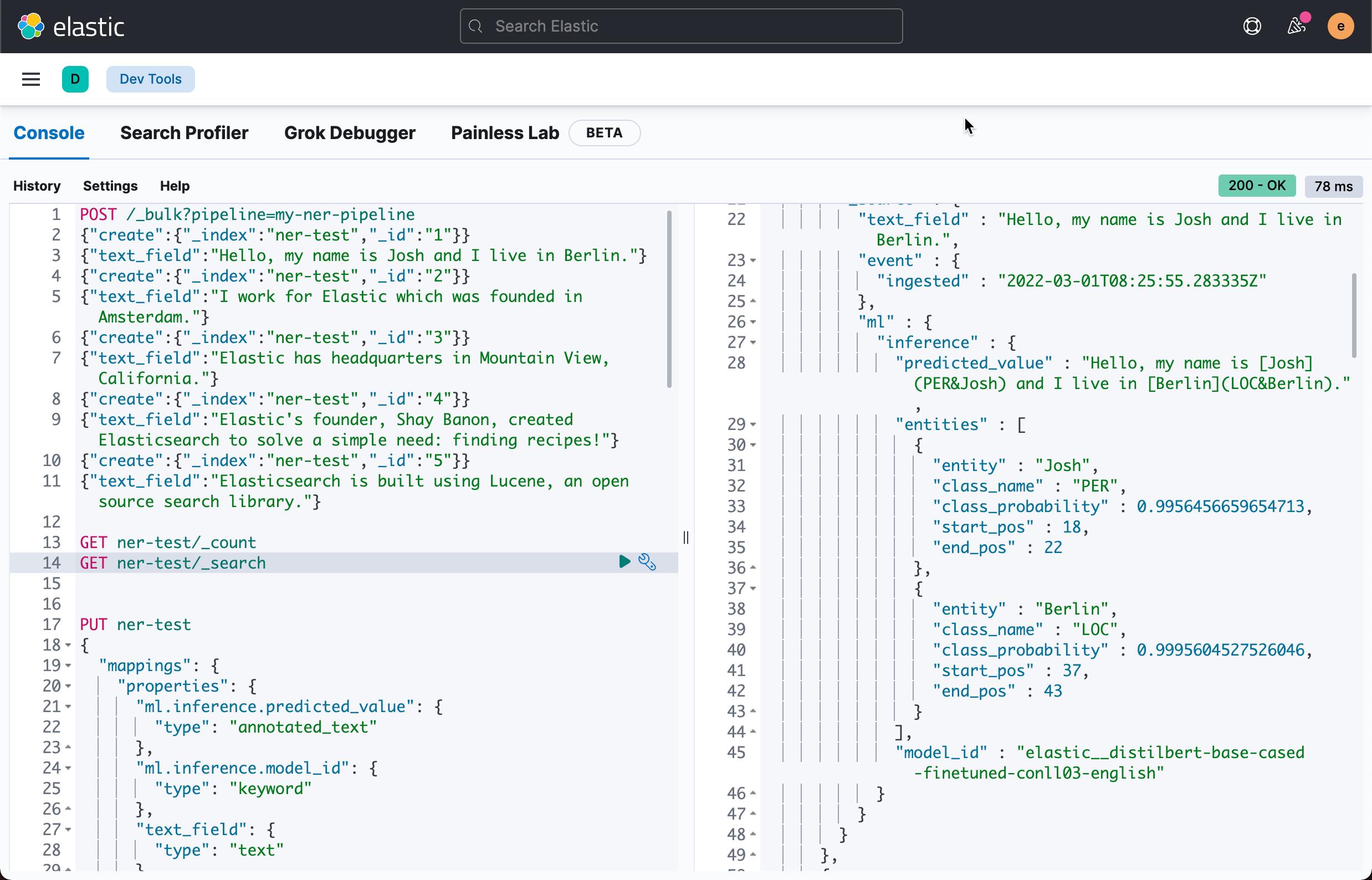
"text_field":"Hello, my name is Josh and I live in Berlin."
]点击上面的 Run the pipeline:
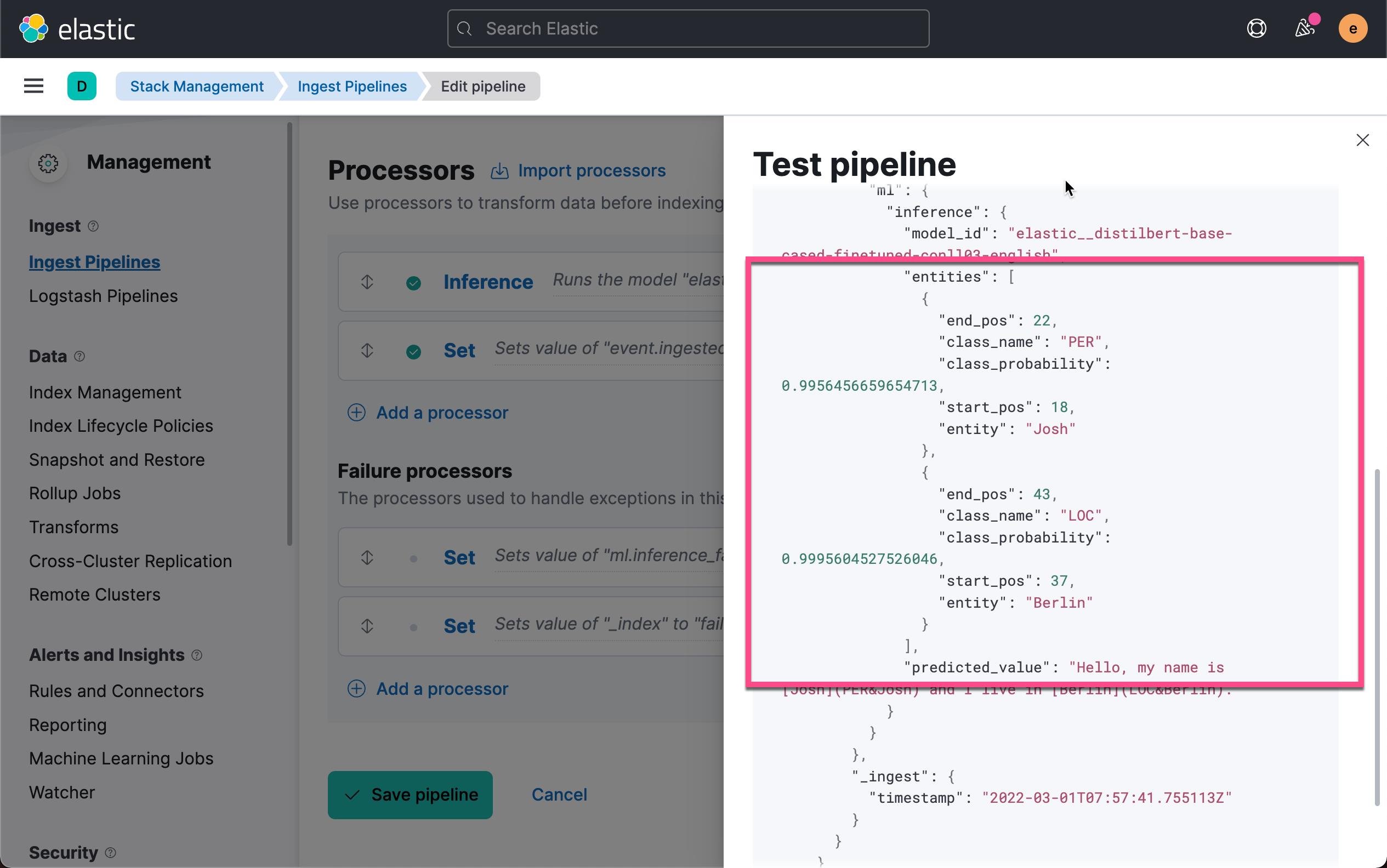
从上面的返回的结果中,我们可以看出来 Josh 有 99.56% 的可能性为人名(PER),而 Berlin 有 99.95% 的可能性为一个地名(LOC)。
如果我们对上面的结果感到满意,我们点击 Save pipeline 或者 Create pipeline 来保存或者创建这个 pipeline:
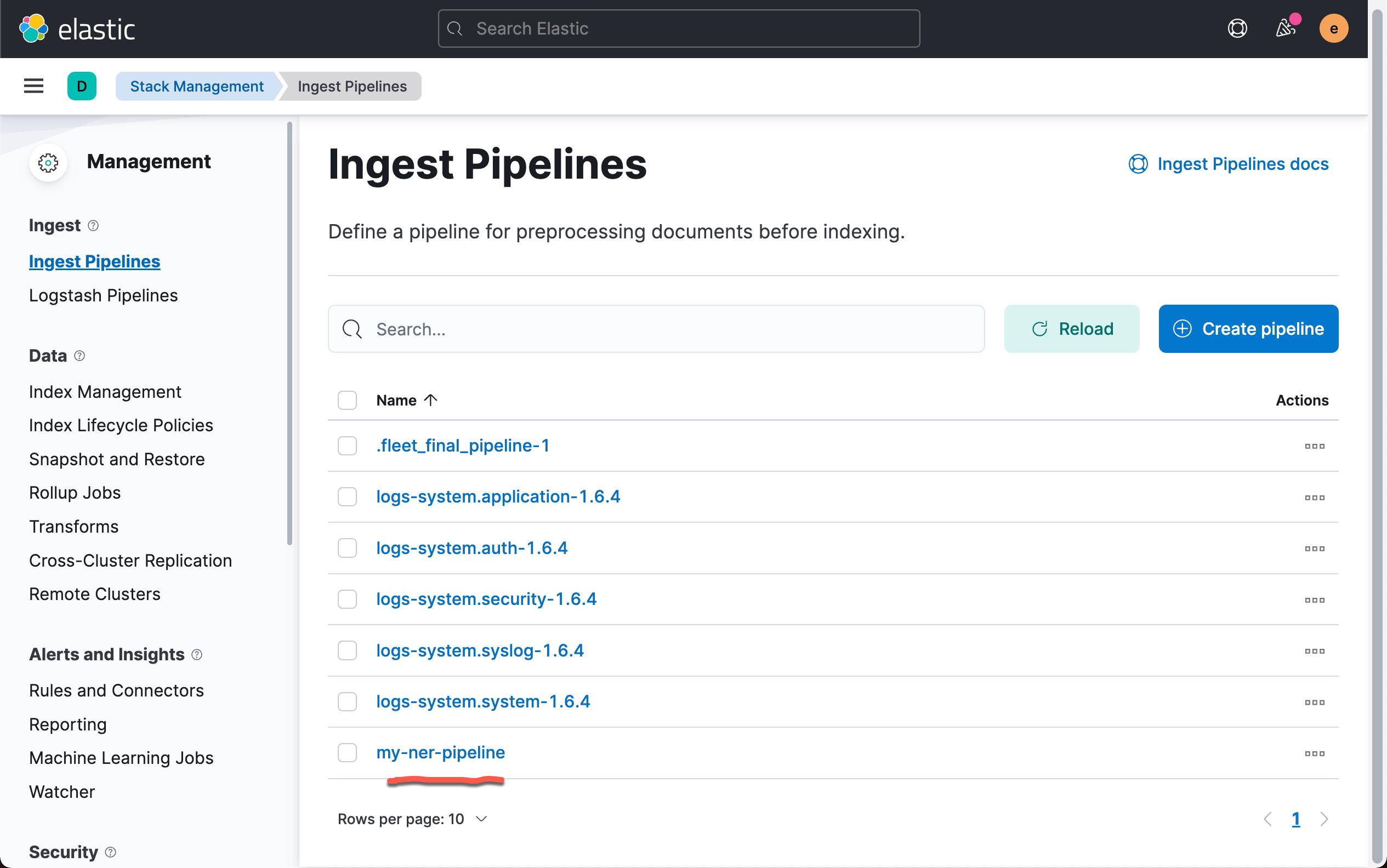
在上面,我们可以看到已经被生成的 my-ner-pipeline。
摄入文档
你现在可以使用摄取管道对数据执行 NLP 任务。
在添加数据之前,请考虑要使用哪些映射。 例如,你可以在 Dev Tools > Console 中使用 create index API 创建显式映射:
PUT ner-test
"mappings":
"properties":
"ml.inference.predicted_value":
"type": "annotated_text"
,
"ml.inference.model_id":
"type": "keyword"
,
"text_field":
"type": "text"
,
"event.ingested":
"type": "date"
在上面,我们使用了一个叫做 annotated_text 的数据类型。你需要参考文章 “Elasticsearch:Mapper Annotated Text Plugin 及其使用” 来安装插件以使得这个数据类型被识别。
然后,你可以使用新管道来索引一些文档。 例如,为你的 NER 管道使用带有管道查询参数的批量索引请求:
POST /_bulk?pipeline=my-ner-pipeline
"create":"_index":"ner-test","_id":"1"
"text_field":"Hello, my name is Josh and I live in Berlin."
"create":"_index":"ner-test","_id":"2"
"text_field":"I work for Elastic which was founded in Amsterdam."
"create":"_index":"ner-test","_id":"3"
"text_field":"Elastic has headquarters in Mountain View, California."
"create":"_index":"ner-test","_id":"4"
"text_field":"Elastic's founder, Shay Banon, created Elasticsearch to solve a simple need: finding recipes!"
"create":"_index":"ner-test","_id":"5"
"text_field":"Elasticsearch is built using Lucene, an open source search library."我们运行上面的命令后,我们就成功地把文档摄入到 Elasticsearch 中去了。
查看结果
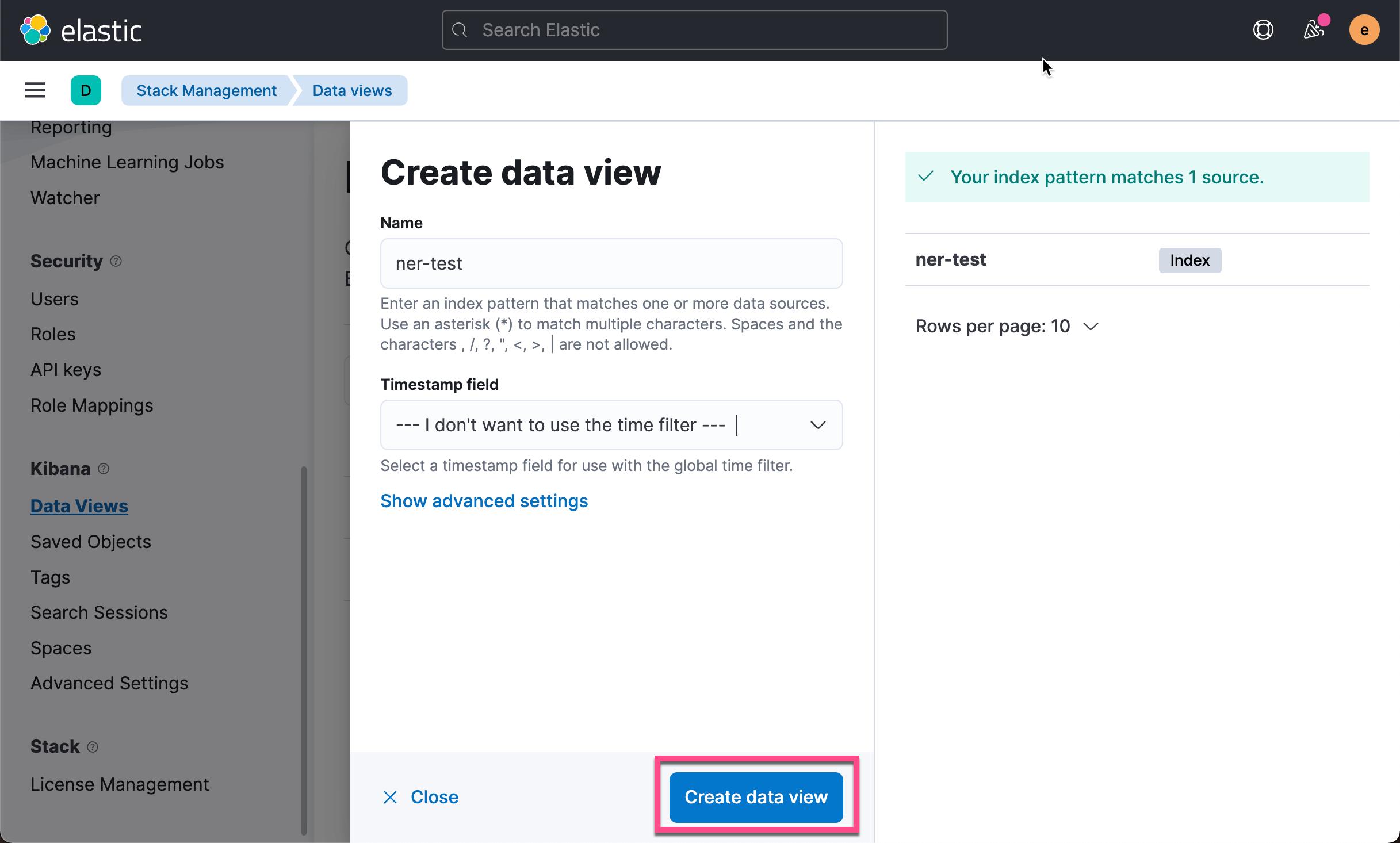
在你可以验证管道的结果之前,你必须创建数据视图(data views):
然后你可以在 Discover 中探索你的数据:
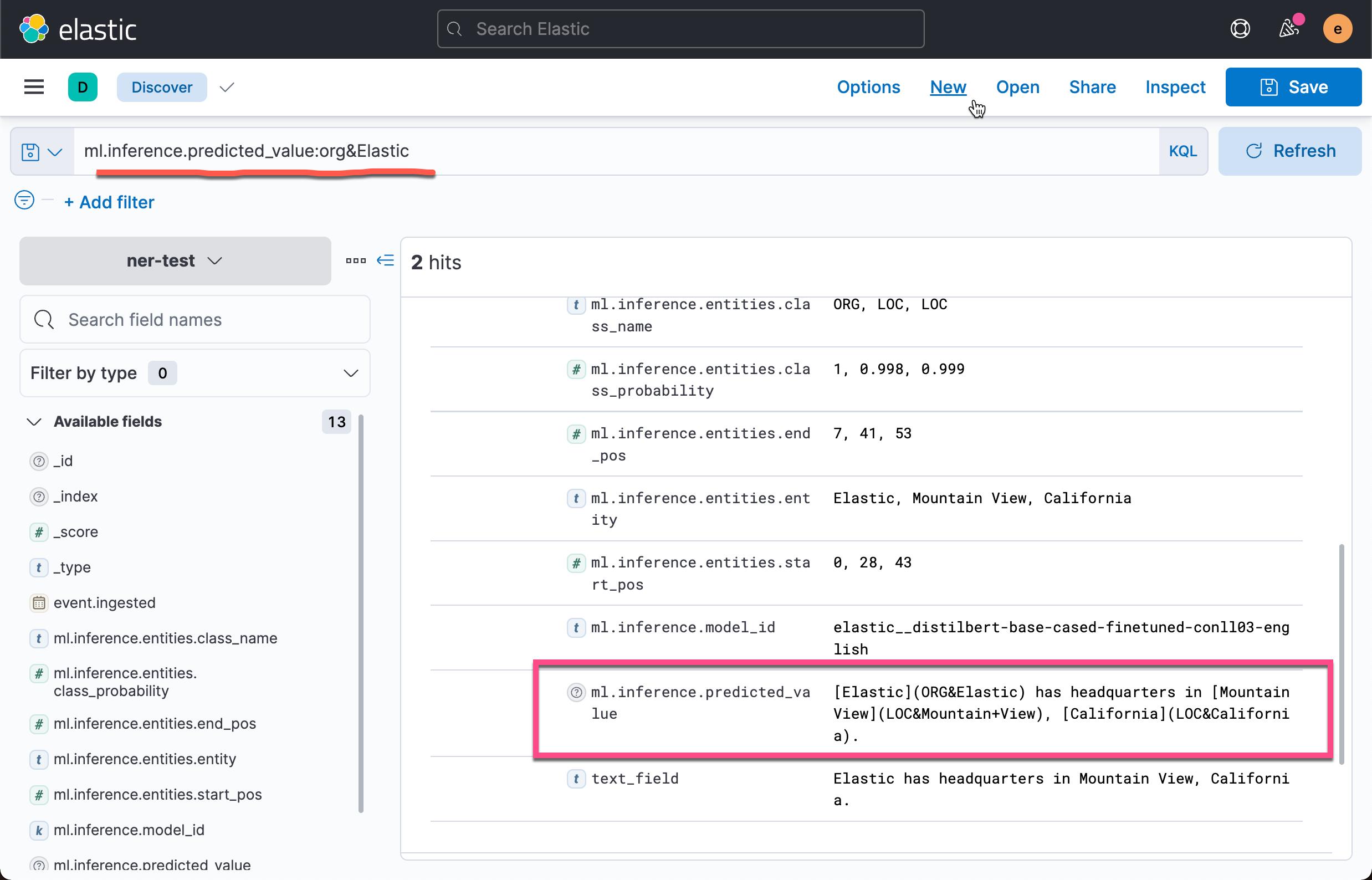
ml.inference.predicted_value 字段包含来自 inference processor 的输出。 在这个 NER 示例中,有两个文档包含 Elastic 组织实体。
常见问题
如果你在摄入管道中使用经过训练的模型时遇到问题,请检查以下可能的原因:
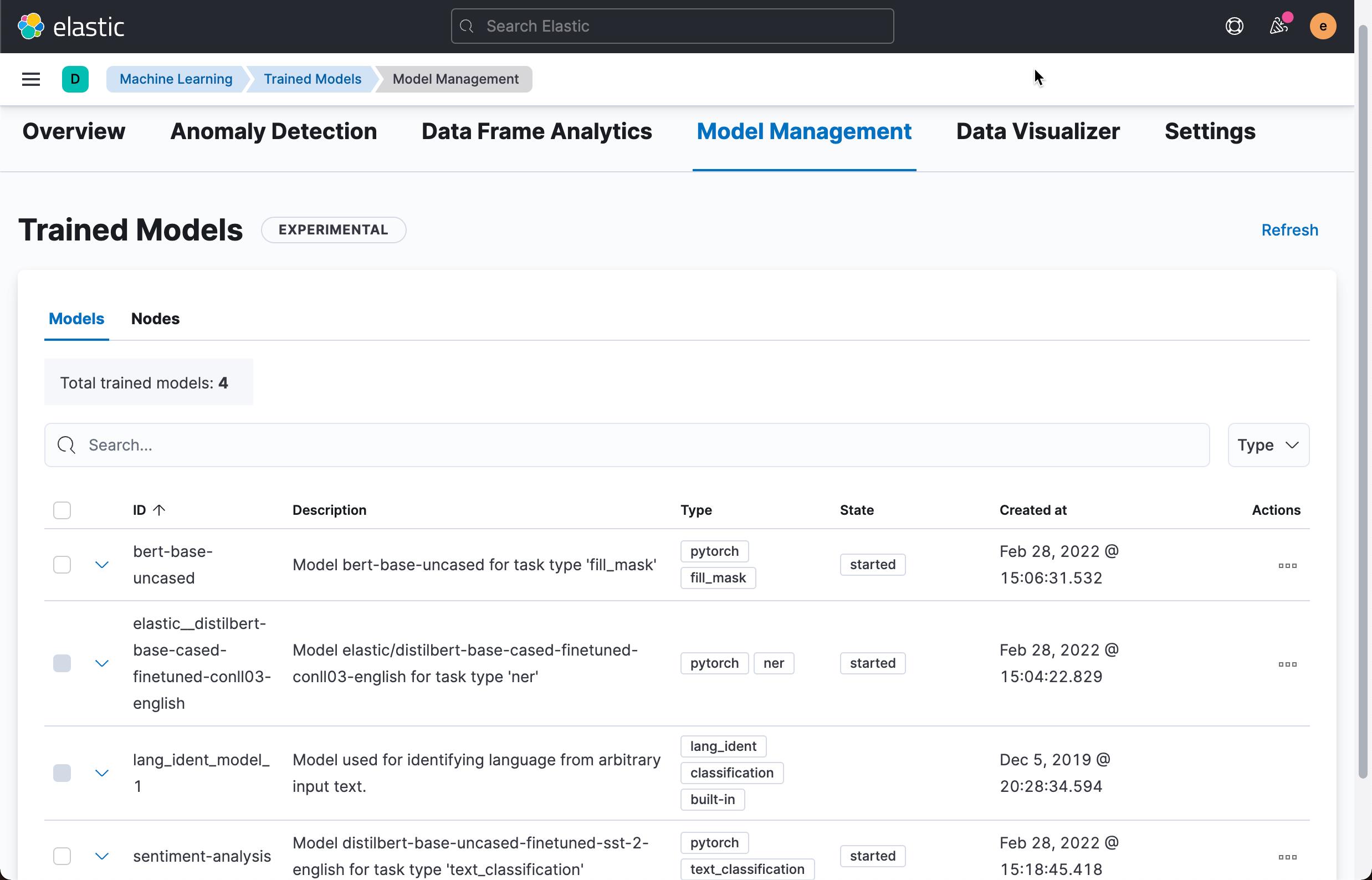
1)训练后的模型未部署在您的集群中。 你可以在 Machine Learning > Model Management 中查看其状态,或使用获取训练模型统计 API。 除非你使用的是内置的 lang_ident_model_1 模型,否则你必须确保您的模型已成功部署
2)你的训练模型所期望的默认输入字段名称不存在于你的源文档中。 使用推理处理器中的 Field Map 选项设置适当的字段名称。
3)请求太多。 如果你使用批量摄入,请减少批量请求中的文档数量。 如果要重新索引,请使用 size 参数减少每批中处理的文档数。
以上是关于Elasticsearch:在摄入管道中添加 NLP 任务的主要内容,如果未能解决你的问题,请参考以下文章