什么是ZK-Rollup(零知识汇总)?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是ZK-Rollup(零知识汇总)?相关的知识,希望对你有一定的参考价值。
ZK-Rollup(零知识汇总)基于zero-knowledge proof(零知识证明),在发往主链的交易包里包含了一个对应的零知识证明,主链上的rollup(汇总)智能合约只需验证这个零知识证明。
这个零知识证明不会透露任何交易细节,但能通过与智能合约不断交互,证明上链的所有数据的有效性和真实性。

优点:
l 高度的去中心化
l 隐私性好:零知识证明不会透露任何交易细节
l 上链效率高:一次性提交多笔操作的结果,节约时间和gas fee
l 验证效率高:无需等待期,快速完成资产取出动作
l 安全性极高:zk技术保证了提交给主链的数据真实有效,同时主链可随时还原侧链发生的交易细节(即拥有主链的数据可用性),因此拥有以太坊级别的安全性
缺点:
l 技术开发难度大
l 难兼容不同智能合约
l 需要大量运算
代表项目:
l 路印:成熟的zk技术运用,获得4500万美元私募,当前市值超8亿美元
l ZKSync:旨在为以太坊带来 Visa 级别、每秒数千笔交易的吞吐量
链乔教育在线旗下学硕创新区块链技术工作站是中国教育部学校规划建设发展中心开展的“智慧学习工场2020-学硕创新工作站 ”唯一获准的“区块链技术专业”试点工作站。专业站立足为学生提供多样化成长路径,推进专业学位研究生产学研结合培养模式改革,构建应用型、复合型人才培养体系。
参考技术A链闻 ChainNews
Rollup 解决了 Plasma 等前辈在开发过程中发现的「数据可用性」问题,ZK Rollup 和 Optimistic Rollup 方案成为了当前以太坊扩容改进的主力军。读懂 ZK Rollup 和 Optimistic Rollup,从这篇开始。
撰文:潘致雄,链闻研究总监
以太坊在诞生后遭遇的最多质疑就是性能问题,在二层网络解决方案 Plasma 几乎全面溃败后,前沿研究领域又将眼光放在了Rollup技术上。
当前以太坊链上交易的吞吐量 (TPS) 约每秒可执行不到 30 笔交易,虽然接近比特币的几倍,但离大规模应用还有较远的距离。相比之下,Visa 或支付宝的交易处理能力的峰值至少每秒上万笔。
加密货币经常被提及的一个用户场景是「跨国汇款或支付」,采用链上发行的稳定币 USDT、USDC 或 PAX 作为交易媒介,以目前以太坊每秒 20 多笔交易的性能,离满足全球的需求还有很大差距。
另一个比较热门的用户场景是去中心化金融(DeFi) ,3 月 12 日「黑色星期四」期间,以太坊网络在链上清算和交易的首次大规模压力测试中,虽说勉强可用,但交易成本提高了数百倍。只有交易成本降到比传统方式更低之后,区块链才更有实用价值。
为了提升交易性能,以太坊设立了多个研究方向,第二层网络 (Layer 2) 解决方案Plasma曾是其中最重要的一个。但在过去 2 年多的发展中,研究人员逐渐发现 Plasma 以及改进版本 Plasma Cash 存在不少的问题,比如要求用户定期上线以及数据可用性问题,制约了 Plasma 的发展。
在 Plasma 诞生的一年后,名为 Rollup 的技术浮出水面。基于此概念,还诞生了多个分支,最主流的是ZK Rollup和Optimistic Rollup两个方案。
Rollup 技术解决了之前 Plasma 暴露出的问题,提供了和以太坊 Layer 1 (也就是以太坊自己) 相同的数据可用性和安全性,而且还能极大提高网络的吞吐能力,同时降低单笔交易成本。正因如此,虽然很多人在广义上称 Rollup 为 Layer 2 的技术,但事实上却介于 Layer 1 和 Layer 2 之间。
Rollup 是什么?
Rollup 的核心理念其实很简单,就是将原本散布在区块中的大量交易数据,打包成一笔「浓缩」的交易,发布到链上。为确保其中每笔交易的有效性,各种 Rollup 方案设计了不同的机制以确保整个过程的安全性与 Layer 1 保持一致。ZK Rollup 以零知识证明 zk-SNARKs的密码学技术确保安全性,而 Optimistic Rollup 则继承了 Plasma 的惩罚机制,以确保节点如果作恶将付出很大的代价。
当然,Rollup 的各种方案都存在不同的取舍。比如,ZK Rollup 的缺点是支持通用型智能合约更难,而且「浓缩」数据 (创建 ZK 证明) 的过程耗时较长;而 Optimistic Rollup 的整体安全性略差一些。不过,各个开发团队具体的实现方案,都针对性优化了上述的这些权衡,部分问题已有显著改善。
Rollup 技术将有助于提升链上应用的竞争力,特别是对于高频交易的场景,有望降低转账或交易费用。不过由于本身机制的设计,相比直接的链上交易来说,Rollup 类交易可能在链上的结算速度会慢一些。出于这个原因,Rollup 的具体应用场景可以包括:
普通转账或支付
提升匿名性的转账或支付
去中心化交易所
去中心化身份系统
去中心化社交媒体
Rollup 概念出现还不到两年,各个 Rollup 实现方案已经陆续上线了测试网,如Matter Labs和Fuel Labs的方案,而应用层的产品也在开发之中,最先上线主网的是由路印 Loopring开发的去中心化交易所,其他也宣布将采用 Rollup 的项目包括Synthetix、Dharma、AZTEC等。
接下来,我们更深入了解学习一下。
Plasma 失败了吗?
关于区块链扩容的讨论起源于比特币网络,针对比特币成为「全球支付工具」的愿景,社区、开发者和矿工最终讨论出的一个方案是,将高频的交易迁移到比特币之外的一个虚拟层中进行,或可以称为「Layer 2」,而不是依赖于比特币自身 (Layer 1) ,不过,最终的结算还是需要依赖 Layer 1 进行。
这就是比特币「闪电网络」的由来。而 Plasma 曾是以太坊 Layer 2 解决方案中最受瞩目的一个,不仅因为这是由Joseph Poon和以太坊创始人Vitalik Buterin共同发布的白皮书,而且还有不少项目宣布过,将基于 Plasma 技术展开研发。
Plasma 通过将高频的交易迁移到以太坊网络之外的侧链之上,定期将批量交易的哈希值发布到以太坊主网,然后设置一些防恶意攻击机制,确保资金安全性。最终的目的是为以太坊扩容,提升交易吞吐量,减少交易成本。Plasma Group、Matic、LeapDAO 和 OmiseGo 等团队都曾经是 Plasma 技术最主要的研发团队,有些项目也获得过以太坊基金会和 Consensys 等机构的资助。
但毕竟这是个试验性的项目,在项目的研发过程中,很多现实问题被暴露了出来,其中最重要的两个挑战是:
数据可用性:因为仅将批量交易的整体哈希值发布到 Layer 1 上,而不是每一笔交易均发布到底层公链,所以具体的交易数据不存在 Layer 1 上,用户需要自己存储具体的交易数据。
用户体验差:为了避免恶意攻击,Plasma 在设计挑战期的机制的时候,用户需要定期上线网络,否则可能错过而遭受不必要的损失。
虽说 Plasma 也推出过更新版的标准 Plasma Cash,但这些问题也依旧存在,最终导致了Plasma Group和LeapDAO两个研发团队在今年初决定,放弃 Plasma 技术,并转向另一个新技术的研发:Rollup。
而Matic依旧坚持在 Plasma 技术的开发中,他们计划在 5 月 15 日至 5 月底期间启动主网的上线流程,并逐步进行去中心化,扩展到超过 100 个节点。究竟 Matic 有没有处理好上述的这些问题,值得更多时间的观察。
无论如何,研究以太坊扩容技术的开发社区,已经将更多精力切换到研究 Rollup 了。
为什么 Rollup 有机会?
在 Plasma 诞生的一年后,一位匿名人士Barry Whitehat在 Github 中提出了「Rollup」的概念,试图以「SNARK」对以太坊进行扩容。
SNARK 是零知识证明的一类密码学技术,全称是「简洁化的非交互式零知识证明」 (zero-knowledge succinct non-interactive argument of knowledge) 。
关于零知识证明的更多信息,可以参阅:Rollup 一词本身的含义为「卷曲」或「卷起」,或者可以引申为「汇总」或「聚合」。在数据库的标准计算机语言 SQL 中,语法中的「Rollup」可以帮助 Group by 语句,将搜索出的一系列结果以聚合的数据显示,或许这是他以 Rollup 命名该技术的由来。
在 Barry Whitehat 提出 Rollup 概念时,它是这样被定义的:
「Rollup 通过将交易聚合,仅需要在链上进行一次交易,就可以验证多笔其他交易。」
而打包交易和验证交易的方式是通过 zk-SNARK 技术实现的,这样就能大幅度减少交易成本,确保安全性,也可以解决 Plasma 之前遇到的问题。
有人会将 Rollup 归类为 Layer 2 技术,但 Vitalik Buterin 却不这么认为。
在 Rollup 概念被提出后,Vitalik Buterin 于同月在以太坊研究论坛中发表文章介绍该技术,他是这么解释的:「我们可以将在以太坊上的资产转账交易的规模进一步增加,而且不需要使用 Layer 2 技术中引入的『活性假设』 (liveness assumption,如状态通道和 Plasma) ,只需要使用ZK-SNARKs为大量的交易进行验证。」
有意思的是,「Rollup」这个名字一开始没受到重视。2019 年的 1 月,Matter Labs推出了名为「Plasma Ignis」的技术,因为在此之前 Layer 2 的主流技术是 Plasma,所以他们以「零知识证明版本的 Plasma」作为研究方向。但从技术角度来说,这其实不能算是 Plasma 的一类,更像是 Rollup。后来该团队全面放弃了 Plasma Ignis 这个名字,转而采用 ZK Rollup 作为技术的方向,后续也推出了他们自己基于 ZK Rollup 的技术实现方案ZK Sync,还进行了更多的深度定制和优化。
Matter Labs 联合创始人 Alex Gluchowski 在 2019 年 1 月份发的推特。
由于早期 ZK Rollup 的概念中,主要的缺点是生成 SNAKR 证明过程较长,而且也未能支持通用型的智能合约,所以 Fuel Labs 联合创始人、以太坊二层扩容方案的长期研究者John Adler在 2019 年 6 月提出了另一个方案,称为Optimistic Rollup。该方案吸收了 ZK Rollup 对于数据可用性的优势,以及 Plasma 的惩罚机制,由于去除了零知识证明,所以可以更方便地支持通用型的智能合约。
Optimistic 意思是「乐观的」,所以在该方案中,不是通过 SNARK 处理后再将数据聚合到链上,而是默认「乐观」相信节点会将最新且准确的数据发布到链上,否则其他人在验证后,如果发现有问题可以发起挑战,成功后节点会受到惩罚。
所以整体来看,Rollup 的技术相比较 Plasma,最关键的是解决了数据可用性的问题,所有交易数据都是在以太坊链上的,安全性也能和以太坊主链相同级别。
那既然同样都是把交易发布在链上,为什么 Rollup 比普通的转账的吞吐量更高,成本更低呢?
因为在构建 Rollup 类交易的时候,大量的普通转账行为可以通过某些技巧进行压缩,最终在通过零知识证明 SNARK处理后,虽然 SNARK 生成过程较长且资源消耗 (Gas) 较大,但分摊到每一笔交易中就微不足道了。在 Vitalik Buterin 的初始提案中有具体的数据可以参考,虽然后续有各种不同的实现和差别。
在他的方案中,单笔交易的构成类似于:
相比普通链上交易所需要的 2.1 万的 Gas 费用来说,以上这种单笔交易由于缩减了体积 (比如,以太坊地址是 20 bytes,以上这个仅需 3 bytes) ,所以总共仅需892 Gas。
但是由于 SNARK 证明的计算资源消耗较多,约600k Gas,以及运行合约所需约 50k Gas,所以这也就意味着,必须要批量处理很多交易,才可以分摊这几百 k 的间接成本。
以太坊单个区块 Gas 上限以 8M 计算的话,如果以纯 ETH 交易来说,吞吐量约为:
8M / 21k / 15 秒 ≈ 25 tps
而该方案中的吞吐量约为:
(8M - 600k - 50k)/ 892 / 15 秒 ≈ 550 tps
这就是 Rollup 既能保证 Layer 1 数据的可获得性,也能大幅减少数据需求并减少单笔交易的成本的主要原因。
除了上述提到的 Rollup 方案研发团队之外,不少应用层的项目也看到了 Rollup 的优势,宣布将研究或集成 Rollup 技术。从目前公开的项目来看,选择Optimistic Rollup的项目更多一些,包括去中心化交易所、DeFi 协议、匿名服务等,很可能是因为项目方考虑到 Optimistic Rollup 的优势为支持通用智能合约,以及不会像 ZK Rollup 需要花费很多时间生成 SNARK 证明,毕竟在没有优化方案之前,可能会影响应用的使用体验。
宣布采用ZK Rollup方案的项目目前并不多,但是路印 Loopring的去中心化交易所是当前 Rollup 项目中开发进度最快的一个,早在 2 月底就已经上线以太坊主网,开始了公开测试。虽然后来也遇到了前端页面的非致命漏洞,但是他们的经验会为后续很多其他即将采用 ZK Rollup 的项目提供参考和指导意义。
到底可以减少多少链上的交易成本呢?路印给出了重要的实战数据,在他们采用的方案中,批量处理 4096 笔交易时,单笔交易只需要 375 Gas。也就是在正常的 Gas 费用下,每次交易成本为 0.09 分人民币 (注意单位) ,换句话说,100 万笔交易的成本大约为900 元。
但曾经研发 Plasma 技术的团队LeapDAO却认为 Rollup 技术不是万灵药。在他们进行了具体的数据分析后,为大家提供了很多值得参考的数据。根据他们的估算,整体而言 Rollup 可以为以太坊网络提升略超过 10 倍的吞吐量,因为相比 Plasma 还是牺牲了很多成本的。
除了两个最流行的 Rollup 衍生版本外,还有一些以太坊二层扩容方案也采用了 Rollup 这个名字,比较常见的两个是 SKALE Labs 提出的BLS-Rollup和 Offchain Labs 的Arbitrum Rollup。
不过 Optimistic Rollup 的提出者 John Adler 认为,BLS-Rollup 不算是通常意义上的 Rollup,更像是一种批处理技术。而 Arbitrum Rollup 在 2018 年发布论文和 2019 年发布白皮书时都未提及 Rollup,他们在今年初上线测试网时才称之为 Arbitrum Rollup。
ZK Rollup 进展
ZK Rollup 技术研发中最重要的公司是Matter Labs和iden3,两者均已推出测试网。但他们产品的定位略有差异,Matter Labs 更像是通用型解决方案,而 iden3 是专用型解决方案。
Matter Labs 推出的是一套完整的通用型解决方案,叫做ZK Sync。该方案考虑到了 ZK Rollup 存在的一些缺点,提出了相应的机制优化,比如之前提及的,生成 SNARK 证明耗时较长,以及较难支持通用智能合约。Matter Lab 联合创始人兼首席执行官 Alex Gluchowski 表示,「在伊斯坦布尔升级之后,ZK Sync 将处于非常有利的位置,可轻松地达到每秒数千的交易量」。
为了实现通用智能合约这一需求,Matter Labs 还推出了零知识证明智能编程语言及框架 Zinc,在今年 2 月推出了首个版本 v0.1 Alpha。Matter Labs 表示,Zinc 是用于创建安全的零知识证明线路以及基于其运行程序的智能编程语言和执行环境,Zinc 遵循Rust原理,并基于简化的 Rust 语法,精通 Rust、C++、Solidity 等语言的开发者可在一天内快速上手。
而 iden3 研究 ZK Rollup 的初衷则是为了他们原本项目考虑的。iden3 这个名字,可以想象成是 identity (身份) 的 3.0,感受一下,是不是类似于「Web3」?所以 iden3 团队专注的是为数字世界提供一种开源的身份管理系统,利用零知识证明 zk-SNARK 提升隐私特性,而 Rollup 则可以增加身份认证系统和应用层在链上交互行为中交易吞吐量。
而从应用层来说,路印 Loopring 和 AZTEC 分别解决了用户链上交易和隐私的需求。路印 Loop ring 的去中心化交易所是当前 Rollup 项目中开发进度最快的一个,早在 2 月底就已经上线以太坊主网,开始了公 开测试。
AZTEC 是一个隐私技术解决方案,在今年 2 月就上线了以太坊主网,但是他们还在考虑采用 Rollup 技术,以显著降低以太坊网络中隐私交易的成本。他们原本在隐私技术中就采用了零知识证明 ZK,扩容方案选择的是 ZK Rollup,所以他们给新的这套方案取名为 ZK ZK Rollup,或ZK Rollup。第一个 ZK 是利用 SNARK 技术中的「简洁性」 (succinctness) 提升网络的可扩展性,将多笔交易合并为一笔以减少交易成本,第二个 ZK 是利用 SNARK 作为隐私技术,将合并前的每一笔普通交易升级为隐私交易。
Optimistic Rollup 进展
Optimistic Rollup 技术中最重要的公司是Fuel Labs、Optimism(前 Plasma Group) 和NutBerry,他们研发的是通用型的 Optimistic Rollup 解决方案。相比 ZK Rollup,由于去除了复杂的零知识证明这类复杂的密码学技术,所以支持通用的智能合约会更容易一些。
Optimistic Rollup 虽然比 Plasma 增加了数据可用性的优点,但也直接吸纳了之前 Plasma 的成果,除了都用同一套博弈和惩罚机制之外,Optimism 团队表示,这两个方案可以共享很多基础设施和代码。另外,他们认为对于一个成熟的Layer 2 生态系统,Rollup、Plasma 和状态通道应该是可以在同一个客户端 (智能钱包) 内一起工作的。
其实在 Plasma Group 对外公开放弃 Plasma 技术之前的 2019 年年底,就组建了一家新公司Optimism,专注于实施 Optimistic Rollup,该公司目前已经从加密风险基金Paradigm和设计公司 IDEO 旗下的IDEO CoLab Ventures筹集了350 万美元种子轮融资。新募集的资金主要用于实施 Optimistic Rollup 解决方案和基于该解决方案构建应用程序。尽管这是一家商业公司,但该研究小组表示,希望继续为开源项目做贡献,并与公众分享自己的研究成果。
为了支持以太坊的智能合约,Optimism 已经发布了虚拟机 Optimistic Virtual Machine (OVM) 的 Alpha 版本。OVM 是嵌入在以太坊虚拟机(EVM) 中的副本,允许开发者使用 Optimistic Rollup 时,可使用和 EVM 相同的开发者工具集和智能合约语言。
刚开始,Optimistic Rollup 被称为「最小可行合并共识」 (Minimal Viable Merged Consensus) ,在John Adler于去年 6 月提出了这个概念后,就成立了Fuel Labs,以实行他们的扩容方案。
Fuel Labs 将开发一条无需信任的以太坊侧链 Fuel,专门针对以太坊链上的支付进行设计,在伊斯坦布尔升级之前,保守估计能将以太坊 ERC-20 代币交易成本降低至原来的五分之一。
今年 1 月,Fuel Labs 基于 Optimistic Rollup 的以太坊侧链 Fuel 的公开测试网上线,代码也已开源。值得注意的是,他们测试网的合约就已经支持所有的 ERC-20 代币了,毕竟 ERC-20 本就是一种智能合约。后来在 3 月,他们宣布推出一门新的以太坊底层语言 Yul+,作为对 Yul 的实验性升级,为 Yul (以太坊虚拟机的一种低级中间语言) 添加了各种 QoL 功能。Yul 是由 Solidity 开发者编写的一门旨在进一步优化编译目标的低级中间语言,简单且具有实用的低级语法,让开发人员比 Solidity 更接近原始以太坊虚拟机 (EVM) ,同时具有优化 gas 费使用效率的潜力。
NutBerry相比上述两个影响力更小一些,但他们的目标是开发一个基于 Optimistic Rollup 的 Layer 2 解决方案,且支持具有状态 (stateful) 的智能合约。该项目最早被发布在以太坊研究论坛,其中描述了该项目将分为四个里程碑:支持 ERC-20 标准、支持 ERC-721 标准、支持无状态智能合约、支持具有状态的智能合约 (也就是可以储存数据的智能合约) 。NutBerry 已于今年 2 月发布了第二个测试网,已支持 ERC-712 (Ethereum typed structured data hashing and signing) 。
Optimistic Rollup 的应用层产品相对较多一些,可能是因为支持智能合约更简单,所以对于这些DeFi、DEX或隐私服务这些需要智能合约处理逻辑的应用来说,更方便一些。
这些应用将会在后续的一两个季度内逐步上线,不用多久就能体验到了。
其他 Rollup
虽然其他几个 Rollup 解决方案和上述的这些项目不太一样,但是他们都以 Rollup 命名,所以本文也做相关的整理和收集:
BLS-Rollup,可以参考 SKALE Labs 的介绍: https://ethresear.ch/t/the-optimal-snark-less-on-chain-scaling-solution/4790
Arbitrum Rollup,可以参考 Offchain Labs 的介绍: https://medium.com/offchainlabs/how-arbitrum-rollup-works-39788e1ed73f
另外还有一个基于账户的匿名 Rollup 项目: https://ethresear.ch/t/account-based-anonymous-rollup/6657
未来
为了以太坊链上应用生态的发展,扩容是一个持续且重要的话题,毕竟,离以太坊 2.0 最终形态至少还有 2-3 年的时间。在此之前,DApp、DeFi、游戏等各种链上应用生态是无法规模化的,计算资源将成为重要的瓶颈,任何一个强势的 DApp 都可能迅速将链上的计算资源占满。以 3 月 12 日为例,Maker 协议因以太坊价格暴跌而发起的抵押品拍卖清算流程,就是因为整体网络拥堵而产生了巨额损失。
曾经最重要的扩容方案 Plasma,在实现过程中遭遇一些问题之后,开发者社区将更多精力转移至 Rollup,因为它解决了前辈在开发过程中发现的「数据可用性」问题。虽然有一些取舍,但还是比以太坊 Layer 1 效率高上几十数百倍。而衍生出两个最重要的分支 ZK Rollup 和 Optimistic Rollup ,分别选择了不同的挑战以确保安全性:是研究困难的零知识证明密码学技术,还是寻找出一套安全且照顾用户体验的博弈机制。
不过,那些上百倍的提升目前还是理论值,或许是实验室环境下的最优情况,在此之前还有很多的研发工作和配套的优化。只有这些方案被实现,并且被应用集成且大规模采用之后,才能知道真实的性能,或是否有其他的弱点和问题。
毕竟实践才能出真知。Rollup 不是第一个扩容方案,也不会是最后一个。虽然我们都知道目标在哪里,但是实现的路径依旧是曲折的。
由浅入深全面了解以太坊 2.0
链闻 ChainNews
Rollup 解决了 Plasma 等前辈在开发过程中发现的「数据可用性」问题,ZK Rollup 和 Optimistic Rollup 方案成为了当前以太坊扩容改进的主力军。读懂 ZK Rollup 和 Optimistic Rollup,从这篇开始。
撰文:潘致雄,链闻研究总监
以太坊在诞生后遭遇的最多质疑就是性能问题,在二层网络解决方案 Plasma 几乎全面溃败后,前沿研究领域又将眼光放在了Rollup技术上。
当前以太坊链上交易的吞吐量 (TPS) 约每秒可执行不到 30 笔交易,虽然接近比特币的几倍,但离大规模应用还有较远的距离。相比之下,Visa 或支付宝的交易处理能力的峰值至少每秒上万笔。
加密货币经常被提及的一个用户场景是「跨国汇款或支付」,采用链上发行的稳定币 USDT、USDC 或 PAX 作为交易媒介,以目前以太坊每秒 20 多笔交易的性能,离满足全球的需求还有很大差距。
另一个比较热门的用户场景是去中心化金融(DeFi) ,3 月 12 日「黑色星期四」期间,以太坊网络在链上清算和交易的首次大规模压力测试中,虽说勉强可用,但交易成本提高了数百倍。只有交易成本降到比传统方式更低之后,区块链才更有实用价值。
为了提升交易性能,以太坊设立了多个研究方向,第二层网络 (Layer 2) 解决方案Plasma曾是其中最重要的一个。但在过去 2 年多的发展中,研究人员逐渐发现 Plasma 以及改进版本 Plasma Cash 存在不少的问题,比如要求用户定期上线以及数据可用性问题,制约了 Plasma 的发展。
在 Plasma 诞生的一年后,名为 Rollup 的技术浮出水面。基于此概念,还诞生了多个分支,最主流的是ZK Rollup和Optimistic Rollup两个方案。
Rollup 技术解决了之前 Plasma 暴露出的问题,提供了和以太坊 Layer 1 (也就是以太坊自己) 相同的数据可用性和安全性,而且还能极大提高网络的吞吐能力,同时降低单笔交易成本。正因如此,虽然很多人在广义上称 Rollup 为 Layer 2 的技术,但事实上却介于 Layer 1 和 Layer 2 之间。
Rollup 是什么?
Rollup 的核心理念其实很简单,就是将原本散布在区块中的大量交易数据,打包成一笔「浓缩」的交易,发布到链上。为确保其中每笔交易的有效性,各种 Rollup 方案设计了不同的机制以确保整个过程的安全性与 Layer 1 保持一致。ZK Rollup 以零知识证明 zk-SNARKs的密码学技术确保安全性,而 Optimistic Rollup 则继承了 Plasma 的惩罚机制,以确保节点如果作恶将付出很大的代价。
当然,Rollup 的各种方案都存在不同的取舍。比如,ZK Rollup 的缺点是支持通用型智能合约更难,而且「浓缩」数据 (创建 ZK 证明) 的过程耗时较长;而 Optimistic Rollup 的整体安全性略差一些。不过,各个开发团队具体的实现方案,都针对性优化了上述的这些权衡,部分问题已有显著改善。
Rollup 技术将有助于提升链上应用的竞争力,特别是对于高频交易的场景,有望降低转账或交易费用。不过由于本身机制的设计,相比直接的链上交易来说,Rollup 类交易可能在链上的结算速度会慢一些。出于这个原因,Rollup 的具体应用场景可以包括:
普通转账或支付
提升匿名性的转账或支付
去中心化交易所
去中心化身份系统
去中心化社交媒体
Rollup 概念出现还不到两年,各个 Rollup 实现方案已经陆续上线了测试网,如Matter Labs和Fuel Labs的方案,而应用层的产品也在开发之中,最先上线主网的是由路印 Loopring开发的去中心化交易所,其他也宣布将采用 Rollup 的项目包括Synthetix、Dharma、AZTEC等。
接下来,我们更深入了解学习一下。
Plasma 失败了吗?
关于区块链扩容的讨论起源于比特币网络,针对比特币成为「全球支付工具」的愿景,社区、开发者和矿工最终讨论出的一个方案是,将高频的交易迁移到比特币之外的一个虚拟层中进行,或可以称为「Layer 2」,而不是依赖于比特币自身 (Layer 1) ,不过,最终的结算还是需要依赖 Layer 1 进行。
这就是比特币「闪电网络」的由来。而 Plasma 曾是以太坊 Layer 2 解决方案中最受瞩目的一个,不仅因为这是由Joseph Poon和以太坊创始人Vitalik Buterin共同发布的白皮书,而且还有不少项目宣布过,将基于 Plasma 技术展开研发。
Plasma 通过将高频的交易迁移到以太坊网络之外的侧链之上,定期将批量交易的哈希值发布到以太坊主网,然后设置一些防恶意攻击机制,确保资金安全性。最终的目的是为以太坊扩容,提升交易吞吐量,减少交易成本。Plasma Group、Matic、LeapDAO 和 OmiseGo 等团队都曾经是 Plasma 技术最主要的研发团队,有些项目也获得过以太坊基金会和 Consensys 等机构的资助。
但毕竟这是个试验性的项目,在项目的研发过程中,很多现实问题被暴露了出来,其中最重要的两个挑战是:
数据可用性:因为仅将批量交易的整体哈希值发布到 Layer 1 上,而不是每一笔交易均发布到底层公链,所以具体的交易数据不存在 Layer 1 上,用户需要自己存储具体的交易数据。
用户体验差:为了避免恶意攻击,Plasma 在设计挑战期的机制的时候,用户需要定期上线网络,否则可能错过而遭受不必要的损失。
虽说 Plasma 也推出过更新版的标准 Plasma Cash,但这些问题也依旧存在,最终导致了Plasma Group和LeapDAO两个研发团队在今年初决定,放弃 Plasma 技术,并转向另一个新技术的研发:Rollup。
而Matic依旧坚持在 Plasma 技术的开发中,他们计划在 5 月 15 日至 5 月底期间启动主网的上线流程,并逐步进行去中心化,扩展到超过 100 个节点。究竟 Matic 有没有处理好上述的这些问题,值得更多时间的观察。
无论如何,研究以太坊扩容技术的开发社区,已经将更多精力切换到研究 Rollup 了。
为什么 Rollup 有机会?
在 Plasma 诞生的一年后,一位匿名人士Barry Whitehat在 Github 中提出了「Rollup」的概念,试图以「SNARK」对以太坊进行扩容。
SNARK 是零知识证明的一类密码学技术,全称是「简洁化的非交互式零知识证明」 (zero-knowledge succinct non-interactive argument of knowledge) 。
关于零知识证明的更多信息,可以参阅:Rollup 一词本身的含义为「卷曲」或「卷起」,或者可以引申为「汇总」或「聚合」。在数据库的标准计算机语言 SQL 中,语法中的「Rollup」可以帮助 Group by 语句,将搜索出的一系列结果以聚合的数据显示,或许这是他以 Rollup 命名该技术的由来。
在 Barry Whitehat 提出 Rollup 概念时,它是这样被定义的:
「Rollup 通过将交易聚合,仅需要在链上进行一次交易,就可以验证多笔其他交易。」
而打包交易和验证交易的方式是通过 zk-SNARK 技术实现的,这样就能大幅度减少交易成本,确保安全性,也可以解决 Plasma 之前遇到的问题。
有人会将 Rollup 归类为 Layer 2 技术,但 Vitalik Buterin 却不这么认为。
在 Rollup 概念被提出后,Vitalik Buterin 于同月在以太坊研究论坛中发表文章介绍该技术,他是这么解释的:「我们可以将在以太坊上的资产转账交易的规模进一步增加,而且不需要使用 Layer 2 技术中引入的『活性假设』 (liveness assumption,如状态通道和 Plasma) ,只需要使用ZK-SNARKs为大量的交易进行验证。」
有意思的是,「Rollup」这个名字一开始没受到重视。2019 年的 1 月,Matter Labs推出了名为「Plasma Ignis」的技术,因为在此之前 Layer 2 的主流技术是 Plasma,所以他们以「零知识证明版本的 Plasma」作为研究方向。但从技术角度来说,这其实不能算是 Plasma 的一类,更像是 Rollup。后来该团队全面放弃了 Plasma Ignis 这个名字,转而采用 ZK Rollup 作为技术的方向,后续也推出了他们自己基于 ZK Rollup 的技术实现方案ZK Sync,还进行了更多的深度定制和优化。
Matter Labs 联合创始人 Alex Gluchowski 在 2019 年 1 月份发的推特。
由于早期 ZK Rollup 的概念中,主要的缺点是生成 SNAKR 证明过程较长,而且也未能支持通用型的智能合约,所以 Fuel Labs 联合创始人、以太坊二层扩容方案的长期研究者John Adler在 2019 年 6 月提出了另一个方案,称为Optimistic Rollup。该方案吸收了 ZK Rollup 对于数据可用性的优势,以及 Plasma 的惩罚机制,由于去除了零知识证明,所以可以更方便地支持通用型的智能合约。
Optimistic 意思是「乐观的」,所以在该方案中,不是通过 SNARK 处理后再将数据聚合到链上,而是默认「乐观」相信节点会将最新且准确的数据发布到链上,否则其他人在验证后,如果发现有问题可以发起挑战,成功后节点会受到惩罚。
所以整体来看,Rollup 的技术相比较 Plasma,最关键的是解决了数据可用性的问题,所有交易数据都是在以太坊链上的,安全性也能和以太坊主链相同级别。
那既然同样都是把交易发布在链上,为什么 Rollup 比普通的转账的吞吐量更高,成本更低呢?
因为在构建 Rollup 类交易的时候,大量的普通转账行为可以通过某些技巧进行压缩,最终在通过零知识证明 SNARK处理后,虽然 SNARK 生成过程较长且资源消耗 (Gas) 较大,但分摊到每一笔交易中就微不足道了。在 Vitalik Buterin 的初始提案中有具体的数据可以参考,虽然后续有各种不同的实现和差别。
在他的方案中,单笔交易的构成类似于:
相比普通链上交易所需要的 2.1 万的 Gas 费用来说,以上这种单笔交易由于缩减了体积 (比如,以太坊地址是 20 bytes,以上这个仅需 3 bytes) ,所以总共仅需892 Gas。
但是由于 SNARK 证明的计算资源消耗较多,约600k Gas,以及运行合约所需约 50k Gas,所以这也就意味着,必须要批量处理很多交易,才可以分摊这几百 k 的间接成本。
以太坊单个区块 Gas 上限以 8M 计算的话,如果以纯 ETH 交易来说,吞吐量约为:
8M / 21k / 15 秒 ≈ 25 tps
而该方案中的吞吐量约为:
(8M - 600k - 50k)/ 892 / 15 秒 ≈ 550 tps
这就是 Rollup 既能保证 Layer 1 数据的可获得性,也能大幅减少数据需求并减少单笔交易的成本的主要原因。
除了上述提到的 Rollup 方案研发团队之外,不少应用层的项目也看到了 Rollup 的优势,宣布将研究或集成 Rollup 技术。从目前公开的项目来看,选择Optimistic Rollup的项目更多一些,包括去中心化交易所、DeFi 协议、匿名服务等,很可能是因为项目方考虑到 Optimistic Rollup 的优势为支持通用智能合约,以及不会像 ZK Rollup 需要花费很多时间生成 SNARK 证明,毕竟在没有优化方案之前,可能会影响应用的使用体验。
宣布采用ZK Rollup方案的项目目前并不多,但是路印 Loopring的去中心化交易所是当前 Rollup 项目中开发进度最快的一个,早在 2 月底就已经上线以太坊主网,开始了公开测试。虽然后来也遇到了前端页面的非致命漏洞,但是他们的经验会为后续很多其他即将采用 ZK Rollup 的项目提供参考和指导意义。
到底可以减少多少链上的交易成本呢?路印给出了重要的实战数据,在他们采用的方案中,批量处理 4096 笔交易时,单笔交易只需要 375 Gas。也就是在正常的 Gas 费用下,每次交易成本为 0.09 分人民币 (注意单位) ,换句话说,100 万笔交易的成本大约为900 元。
但曾经研发 Plasma 技术的团队LeapDAO却认为 Rollup 技术不是万灵药。在他们进行了具体的数据分析后,为大家提供了很多值得参考的数据。根据他们的估算,整体而言 Rollup 可以为以太坊网络提升略超过 10 倍的吞吐量,因为相比 Plasma 还是牺牲了很多成本的。
除了两个最流行的 Rollup 衍生版本外,还有一些以太坊二层扩容方案也采用了 Rollup 这个名字,比较常见的两个是 SKALE Labs 提出的BLS-Rollup和 Offchain Labs 的Arbitrum Rollup。
不过 Optimistic Rollup 的提出者 John Adler 认为,BLS-Rollup 不算是通常意义上的 Rollup,更像是一种批处理技术。而 Arbitrum Rollup 在 2018 年发布论文和 2019 年发布白皮书时都未提及 Rollup,他们在今年初上线测试网时才称之为 Arbitrum Rollup。
ZK Rollup 进展
ZK Rollup 技术研发中最重要的公司是Matter Labs和iden3,两者均已推出测试网。但他们产品的定位略有差异,Matter Labs 更像是通用型解决方案,而 iden3 是专用型解决方案。
Matter Labs 推出的是一套完整的通用型解决方案,叫做ZK Sync。该方案考虑到了 ZK Rollup 存在的一些缺点,提出了相应的机制优化,比如之前提及的,生成 SNARK 证明耗时较长,以及较难支持通用智能合约。Matter Lab 联合创始人兼首席执行官 Alex Gluchowski 表示,「在伊斯坦布尔升级之后,ZK Sync 将处于非常有利的位置,可轻松地达到每秒数千的交易量」。
为了实现通用智能合约这一需求,Matter Labs 还推出了零知识证明智能编程语言及框架 Zinc,在今年 2 月推出了首个版本 v0.1 Alpha。Matter Labs 表示,Zinc 是用于创建安全的零知识证明线路以及基于其运行程序的智能编程语言和执行环境,Zinc 遵循Rust原理,并基于简化的 Rust 语法,精通 Rust、C++、Solidity 等语言的开发者可在一天内快速上手。
而 iden3 研究 ZK Rollup 的初衷则是为了他们原本项目考虑的。iden3 这个名字,可以想象成是 identity (身份) 的 3.0,感受一下,是不是类似于「Web3」?所以 iden3 团队专注的是为数字世界提供一种开源的身份管理系统,利用零知识证明 zk-SNARK 提升隐私特性,而 Rollup 则可以增加身份认证系统和应用层在链上交互行为中交易吞吐量。
而从应用层来说,路印 Loopring 和 AZTEC 分别解决了用户链上交易和隐私的需求。路印 Loop ring 的去中心化交易所是当前 Rollup 项目中开发进度最快的一个,早在 2 月底就已经上线以太坊主网,开始了公 开测试。
AZTEC 是一个隐私技术解决方案,在今年 2 月就上线了以太坊主网,但是他们还在考虑采用 Rollup 技术,以显著降低以太坊网络中隐私交易的成本。他们原本在隐私技术中就采用了零知识证明 ZK,扩容方案选择的是 ZK Rollup,所以他们给新的这套方案取名为 ZK ZK Rollup,或ZK Rollup。第一个 ZK 是利用 SNARK 技术中的「简洁性」 (succinctness) 提升网络的可扩展性,将多笔交易合并为一笔以减少交易成本,第二个 ZK 是利用 SNARK 作为隐私技术,将合并前的每一笔普通交易升级为隐私交易。
Optimistic Rollup 进展
Optimistic Rollup 技术中最重要的公司是Fuel Labs、Optimism(前 Plasma Group) 和NutBerry,他们研发的是通用型的 Optimistic Rollup 解决方案。相比 ZK Rollup,由于去除了复杂的零知识证明这类复杂的密码学技术,所以支持通用的智能合约会更容易一些。
Optimistic Rollup 虽然比 Plasma 增加了数据可用性的优点,但也直接吸纳了之前 Plasma 的成果,除了都用同一套博弈和惩罚机制之外,Optimism 团队表示,这两个方案可以共享很多基础设施和代码。另外,他们认为对于一个成熟的Layer 2 生态系统,Rollup、Plasma 和状态通道应该是可以在同一个客户端 (智能钱包) 内一起工作的。
其实在 Plasma Group 对外公开放弃 Plasma 技术之前的 2019 年年底,就组建了一家新公司Optimism,专注于实施 Optimistic Rollup,该公司目前已经从加密风险基金Paradigm和设计公司 IDEO 旗下的IDEO CoLab Ventures筹集了350 万美元种子轮融资。新募集的资金主要用于实施 Optimistic Rollup 解决方案和基于该解决方案构建应用程序。尽管这是一家商业公司,但该研究小组表示,希望继续为开源项目做贡献,并与公众分享自己的研究成果。
为了支持以太坊的智能合约,Optimism 已经发布了虚拟机 Optimistic Virtual Machine (OVM) 的 Alpha 版本。OVM 是嵌入在以太坊虚拟机(EVM) 中的副本,允许开发者使用 Optimistic Rollup 时,可使用和 EVM 相同的开发者工具集和智能合约语言。
刚开始,Optimistic Rollup 被称为「最小可行合并共识」 (Minimal Viable Merged Consensus) ,在John Adler于去年 6 月提出了这个概念后,就成立了Fuel Labs,以实行他们的扩容方案。
Fuel Labs 将开发一条无需信任的以太坊侧链 Fuel,专门针对以太坊链上的支付进行设计,在伊斯坦布尔升级之前,保守估计能将以太坊 ERC-20 代币交易成本降低至原来的五分之一。
今年 1 月,Fuel Labs 基于 Optimistic Rollup 的以太坊侧链 Fuel 的公开测试网上线,代码也已开源。值得注意的是,他们测试网的合约就已经支持所有的 ERC-20 代币了,毕竟 ERC-20 本就是一种智能合约。后来在 3 月,他们宣布推出一门新的以太坊底层语言 Yul+,作为对 Yul 的实验性升级,为 Yul (以太坊虚拟机的一种低级中间语言) 添加了各种 QoL 功能。Yul 是由 Solidity 开发者编写的一门旨在进一步优化编译目标的低级中间语言,简单且具有实用的低级语法,让开发人员比 Solidity 更接近原始以太坊虚拟机 (EVM) ,同时具有优化 gas 费使用效率的潜力。
NutBerry相比上述两个影响力更小一些,但他们的目标是开发一个基于 Optimistic Rollup 的 Layer 2 解决方案,且支持具有状态 (stateful) 的智能合约。该项目最早被发布在以太坊研究论坛,其中描述了该项目将分为四个里程碑:支持 ERC-20 标准、支持 ERC-721 标准、支持无状态智能合约、支持具有状态的智能合约 (也就是可以储存数据的智能合约) 。NutBerry 已于今年 2 月发布了第二个测试网,已支持 ERC-712 (Ethereum typed structured data hashing and signing) 。
Optimistic Rollup 的应用层产品相对较多一些,可能是因为支持智能合约更简单,所以对于这些DeFi、DEX或隐私服务这些需要智能合约处理逻辑的应用来说,更方便一些。
这些应用将会在后续的一两个季度内逐步上线,不用多久就能体验到了。
其他 Rollup
虽然其他几个 Rollup 解决方案和上述的这些项目不太一样,但是他们都以 Rollup 命名,所以本文也做相关的整理和收集:
BLS-Rollup,可以参考 SKALE Labs 的介绍: https://ethresear.ch/t/the-optimal-snark-less-on-chain-scaling-solution/4790
Arbitrum Rollup,可以参考 Offchain Labs 的介绍: https://medium.com/offchainlabs/how-arbitrum-rollup-works-39788e1ed73f
另外还有一个基于账户的匿名 Rollup 项目: https://ethresear.ch/t/account-based-anonymous-rollup/6657
未来
为了以太坊链上应用生态的发展,扩容是一个持续且重要的话题,毕竟,离以太坊 2.0 最终形态至少还有 2-3 年的时间。在此之前,DApp、DeFi、游戏等各种链上应用生态是无法规模化的,计算资源将成为重要的瓶颈,任何一个强势的 DApp 都可能迅速将链上的计算资源占满。以 3 月 12 日为例,Maker 协议因以太坊价格暴跌而发起的抵押品拍卖清算流程,就是因为整体网络拥堵而产生了巨额损失。
曾经最重要的扩容方案 Plasma,在实现过程中遭遇一些问题之后,开发者社区将更多精力转移至 Rollup,因为它解决了前辈在开发过程中发现的「数据可用性」问题。虽然有一些取舍,但还是比以太坊 Layer 1 效率高上几十数百倍。而衍生出两个最重要的分支 ZK Rollup 和 Optimistic Rollup ,分别选择了不同的挑战以确保安全性:是研究困难的零知识证明密码学技术,还是寻找出一套安全且照顾用户体验的博弈机制。
不过,那些上百倍的提升目前还是理论值,或许是实验室环境下的最优情况,在此之前还有很多的研发工作和配套的优化。只有这些方案被实现,并且被应用集成且大规模采用之后,才能知道真实的性能,或是否有其他的弱点和问题。
毕竟实践才能出真知。Rollup 不是第一个扩容方案,也不会是最后一个。虽然我们都知道目标在哪里,但是实现的路径依旧是曲折的。
由浅入深全面了解以太坊 2.0
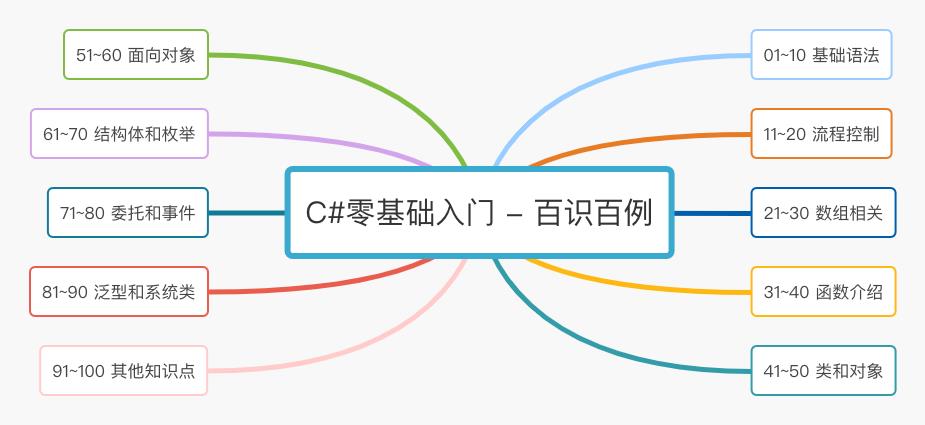
C# 零基础入门知识点汇总
C# 零基础入门 知识点汇总
- 前言
- 一,基础语法(1~10)
- 二,流程控制(11~20)
- 三,数组相关(21~30)
- 四,函数介绍(31~40)
- 五,类和对象(41~50)
- 六,面向对象(51~60)
- 七,结构体和枚举(61~70)
- 八,委托和事件(71~80)
- 九,泛型和系统类(81~90)
- 十,其他知识点(91~100)
- 后语
前言
本文属于C#零基础入门之百识百例系列知识点整理目录。此系列文章旨在为学习C#语言的童鞋提供一套系统的学习路径。此系列文章都会通过【知识点】【练习题】的形式呈现。有任何问题,你都可以通过评论,私信等方式找到我,我会一对一解答你的问题。
系列文章目录:
《C#零基础入门之百识百例》 学习专栏地址
一,基础语法(1~10)
-
初识程序 – Hello Csharp 【点击查看】
C#是由C和C++衍生出来的面向对象的编程语言,它在继承C和C++强大功能的同时去掉了一些它们的复杂特性 -
数据类型 – 值类型, 引用类型 – 写默认值 【点击查看】
数据类型主要用于指明变量和常量存储值的类型,C# 语言是一种强类型语言,要求每个变量都必须指定数据类型。 -
变量常量 – 两数交换 – readonly,const关键字 【点击查看】
常量和变量都是用来存储数据的容器,在定义时都需要指明数据类型。 -
输入输出 – 模拟登陆 【点击查看】
输入和输出是用户与计算机之间进行交流的方法。 -
输出格式控制 – 竖式计算 【点击查看】
使用Console类的Write方法和WriteLine方法输出时,可以通过设置输出格式字符串以更合适的格式输出信息 -
类型转换 – 强制转换 – Convert类 【点击查看】
C#是强类型语言,每个变量都有严格的类型。如果运算符两侧的类型不一致,在运算是要进行类型转换。 -
算数运算符 – 圆的面积 【点击查看】
运算符是一种告诉编译器执行特定的数学或逻辑操作的符号。C# 有丰富的内置运算符,本文带你学习C# 中算数运算符。 -
比较和逻辑运算符 – 判断闰年 【点击查看】
比较运算符是在条件判断中经常使用的一类运算符,包括大于、小于、不等于、大于等于、小于等于等。逻辑运算符主要包括与、或、非等,它主要用于多个布尔型表达式之间的运算。 -
位和赋值运算符 – 2的n次幂 【点击查看】
所谓的位运算,通常是指将数值型的值从十进制转换成二进制后的运算,由于是对二进制数进行运算,所以使用位运算符对操作数进行运算的速度稍快。 -
其他运算符和优先级 – 解方程式 【点击查看】
在使用 C# 编程时字符串是比较常用的一种数据类型,例如用户名、邮箱、家庭住址、商品名称等信息都需要使用字符串类型来存取。
二,流程控制(11~20)
-
顺序结构 – 流程图 – 梯形面积【点击查看】
顺序执行的程序中语句的次序很重要,不能随意调整顺序执行语句顺序,这将会导致程序结果出错。 -
选择结构 – if:else – 判断偶数【点击查看】
C#中的if else语句是最常用的条件语句,并且 if else 句的形式有多种,包括单一条件的 if语句、二选一条件的 if else 语句以及多选一条件的 if , else if语句。 -
选择结构 – switch – 成绩查询【点击查看】
C# switch case 语句也是条件语句的一种,与 if else语句是类似的,但在判断条件的选择上会有一些局限性。 -
循环结构 – for 打印乘法表【点击查看】
循环语句和条件语句一样都是每个程序中必不可少的,循环语句是用来完成一些重复的工作的,以减少编写代码的工作量。 -
循环结构 – while - N阶乘【点击查看】
C# while 循环与 for 循环类似,但是 while 循环一般适用于不固定次数的循环。 -
循环结构 – do…white – 这题会了吗?【点击查看】
C# do while 循环可以说是上一节 C# while循环的另一个版本,与 while 循环最大的区别是它至少会执行一次。 -
break,continue,goto – 代码敲七? – 斐波那契数列【点击查看】
C# break 语句用于中断循环,使循环不再执行。如果是多个循环语句嵌套使用,则 break 语句跳出的则是最内层循环。 -
算法概述 – 特殊回文数【点击查看】
算法是解决特定问题求解步骤的描述,在计算机汇总表现为指令的有限序列,并且每条之类表示一个或者多个动作。 -
穷举法 – 百钱百鸡问题【点击查看】
在进行归纳推理时,如果逐个考察了某类事件的所有可能情况,因而得出一般结论,那么这结论是可靠的,这种归纳方法叫做穷举法 -
异常处理 – 除数为0【点击查看】
异常是在程序执行期间出现的问题。C# 中的异常是对程序运行时出现的特殊情况的一种响应。
三,数组相关(21~30)
-
数组遍历 – 删除0元素【点击查看】
数组从字面上理解就是存放一组数,但在 C# 语言中数组存放的并不一定是数字,也可以是其他数据类型。在一个数组中存放的值都是同一数据类型的,并且可以通过循环以及数据操作的方法对数组的值进行运算或操作。 -
数组排序 – 冒泡排序【点击查看】
冒泡排序也是一种简单直观的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。 -
数组排序 – 选择排序【点击查看】
选择排序是一种简单直观的排序算法,无论什么数据进去都是 O(n²) 的时间复杂度。所以用到它的时候,数据规模越小越好。 -
数组排序 – 插入排序【点击查看】
插入排序是一种最简单直观的排序算法,它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。 -
数组查找 – 顺序查找 – 求最值【点击查看】
查找就是在一批数据中查找指定数据,如最值查找或指定值查找,查找结束后应该给出查找成功与否的结论。 -
数组查找 – 二分查找 – 查找指定元素【点击查看】
折半查找又称二分查找,二分查找是对有序数组而言的,所以在使用二分查找前要确保数组已经是顺序的。 -
多维数组 – 二维数组 – 矩阵翻转【点击查看】
C#中允许定义多维数组,多维数组的每个元素又是一个数组,称为子数组。 -
可变数组 – 交错数组 – freach语句数组求和【点击查看】
交错数组是数组的数组。与矩形数组不同,交错数组的子数组可以有不同数目的元素。 -
数组类常用方法 – 清空,复制,逆转,排序【点击查看】
Array 类是 C# 中所有数组的基类,它是在 System 命名空间中定义。Array 类提供了各种用于数组的属性和方法。 -
数组应用 – 推箱子游戏 – 地图初始化【点击查看】
最经典的推箱子游戏,类似的游戏你一定早就玩过。要控制搬运工上下左右移动,来将箱子推到指定地点。
四,函数介绍(31~40)
-
方法介绍 – 猜数游戏【点击查看】
方法是将完成同一功能的内容放到一起,方便书写和调用的一种方式,也体现了面向对象语言中封装的特性。 -
方法参数 – ref引用参数 & out输出参数【点击查看】
方法参数的本质是为了在调用者和方法之间实现数据交换,是方法接口的重要组成部分。 -
方法参数 – 位置和命名参数【点击查看】
根据参数传递机制的不同,C#方法的形式参数分为四种:值形参、引用形参、输出形参以及形参数组,通过在形参定义时添加不同的参数描述符来表示。 -
方法参数 – 可选参数 & param形参数组【点击查看】
C#允许在方法定义时为形参指定默认值,具有默认值的参数称为默认参数或可选参数。 -
方法返回值 – 完全数【点击查看】
方法执行过程中遇到return语句,方法会立刻返回,执行流程立刻结束。方法返回的使用介绍和实例练习。 -
方法重载 – 回文数【点击查看】
C#的一个类中超过一个方法具有相同名称的现象叫做方法重载。 -
递归方法 – 李白打酒【点击查看】
方法直接或间接的调用自己,称为递归调用。递归会产生很优雅的代码。 -
常用方法 – String类 – 字符串常用方法【点击查看】
C#中String类常用方法汇总14个String类的常用方法,字符串比较,字符串截取,字符串连接,字符串转换。 -
常用方法 – Math类 – Math常用方法【点击查看】
C#中Math类主要用于一些与数学相关的计算,并提供了很多静态方法方便访问。 -
方法应用实例 – 推箱子游戏【点击查看】
推箱子游戏是每个人小时候都会玩的一款游戏,玩家需要把箱子推送到相应的位置是上去,现使用C#还原经典版推箱子。
五,类和对象(41~50)
-
类的定义和使用 – 鸡兔同笼【点击查看】
程序的数据和功能被组织为逻辑上相关的数据项和函数的封装集合,称之为类。 -
类的成员 – 模拟计算器【点击查看】
在 C# 语言中类定义后就要确定类中包含的内容,类中包含的内容被称为类中的成员。 -
类的构造析构函数 – 模拟用户注册【点击查看】
构造方法是在创建类的对象时被调用的。通常会将一些对类中成员初始化的操作放到构造方法中去完成。析构方法是在程序结束后自动被调用的。 -
静态类 – 温度转换【点击查看】
静态类是不能实例化的,我们直接使用它的属性与方法,静态类最大的特点就是共享。 -
类的属性 – 单例模式【点击查看】
C#的属性把字段和访问它们的方法相结合,属性为类用户提供了与字段读写相同的使用方法。属性为类用户提供了与字段读写相同的使用方法;属性值的读写通过get访问器和set访问器实现的,可以对非法的赋值进行检查过滤。 -
类的索引 – 数组索引器【点击查看】
索引器的行为的声明在某种程度上类似于属性(property)。就像属性(property),您可使用 get 和 set 访问器来定义索引器。但是,属性返回或设置一个特定的数据成员,而索引器返回或设置对象实例的一个特定值。 -
类的运算符 – 学生成绩汇总【点击查看】
运算符重载的其实就是函数重载。首先通过指定的运算表达式调用对应的运算符函数,然后再将运算对象转化为运算符函数的实参,接着根据实参的类型来确定需要调用的函数的重载,这个过程是由编译器完成。 -
分布类和分部方法 – 水仙花数【点击查看】
每个分部类的声明中都含有一些类成员的声明,这些分部类可以在一个文件中,也可以在不同文件中。分部方法是在分部类中声明的两个部分中的方法。分部方法的那两个部分可以声明在分部类的不同部分,也可以声明在同一部分。 -
作用域和生命期 – 求N位自幂数【点击查看】
在同一个作用域中,C#程序中的每个名字与唯一的实体对应;只要在不同的作用域上,程序就可以多次使用相同的名字来对应不同作用域中的不同实体。 -
内嵌类和内嵌方法 – 求解汉诺塔【点击查看】
C#可以在一个类中定义另一个类。如果嵌套的类声明为私有,就不能在包含类外部实例化嵌套类。
六,面向对象(51~60)
-
面向对象概述 – 一维多项式求值【点击查看】
面向对象三大特征:封装,继承,多态。封装是指隐藏对象的特征和实现细节,仅对外提供公共访问方式。 -
封装介绍 – 二维多项式求值【点击查看】
封装是指隐藏对象的特征和实现细节,仅对外提供公共访问方式。被定义为 “把一个或多个项目封闭在一个物理的或者逻辑的包中”。在面向对象程序设计方法论中,封装是为了防止对实现细节的访问。 -
继承介绍 – 模拟计算器【点击查看】
继承用于创建可重用、扩展和修改在其他类中定义的行为的新类。继承就是在一个已存在的类的基础上建立一个新的类。继承为多态提供了前提。 -
派生类使用 – 等差数列求和【点击查看】
在设计派生类的构造函数时,需要考虑派生类新增成员和从基类继承的数据成员的初始化。 -
抽象类 – 经典猫狗案例【点击查看】
抽象类是不完整的类,它只能用做基类来派生出其他类,其中包含的抽象方法必须在每个非抽象派生类中重写。 -
密封类 – 任意年月日历输出【点击查看】
同一操作作用于不同类的实例、不同的类型将进行不同的解释,产生不同的结果,即为多态。 -
多态介绍 – 简单工厂模式【点击查看】
如果类定义时使用sealed 修饰符进行修饰,则说明该类是一个密封类。密封类只能被用作独立的类,不能从密封类派生出其他类。 -
接口 – 模拟银行存储【点击查看】
接口是类和类之间的协议,使用接口可以使得实现接口的类或结构在形式上保持一致,使程序更加清晰和条理化,具有很好的扩展性,并可以方便实现类与类之间的统一管理,是组件技术的重要支撑。 -
程序集合命名空间 – using用法【点击查看】
命名空间的设计目的是提供一种让一组名称与其他名称分隔开的方式。在一个命名空间中声明的类的名称与另一个命名空间中声明的相同的类的名称不冲突。 -
面向对象经典例题 – 图书管理系统【点击查看】
请利用面向对象分析实现图片管理系统,具有录入,查询 ,删除,显示所有图书信息功能。
七,结构体和枚举(61~70)
-
结构体的定义 – 时间设计【点击查看】
C#的结构体类型(或称为结构)是用户自定义类型的一种,它为用户将实际应用中数据类型不同,但互相联系的数据看作一个整体提供了类型支持。 -
结构体类型变量 – 学生数据录入【点击查看】
C#中结构体类型变量称为对象或称为结构实例。定义结构体类型变量称为把结构体类型实例化,这时会根据结构体类型的定义为结构体变量分配相应的存储空间。 -
结构体数组数组 – 学生成绩存储【点击查看】
结构体类型的数组:当有多个同一结构体类型的结构体实例时,可以将它们组织成一个结构体数组。结构体数组的元素类型为结构体类型。 -
结构体在方法中的使用 – 学生成绩排序 – 排序拓展【点击查看】
当结构体作为方法的值参数、引用形参或输出形参时,方法的定义和调用语法与其它数据类型作为方法的形参时基本一致。 -
结构体和类的对比 – 对战文字游戏【点击查看】
类的对象是存储在堆空间中,结构存储在栈中。堆空间大,但访问速度较慢,栈空间小,访问速度相对更快。简言之:同生共死Class,随用随扔Struct。 -
枚举类型的定义和使用 – 猜拳游戏【点击查看】
如果希望得到一个固定的集合值,就采用枚举。枚举与结构体类型一样,是由程序员定义的类型。 -
枚举常用方法介绍 – 使用示例【点击查看】
枚举与结构体常用方法的使用示例和注意事项。 -
位标识 – 枚举拓展【点击查看】
在开发过程中很多人都有使用单字的不同位作为表示一组开 / 关标志的使用情况。枚举类型为此提供了简便的实现方法。 -
初识LINQ – 语法介绍和实例【点击查看】
Linq是在.NET Framework 3.5之后的版本出现的.在程序中的数据和数据库的数据相反,保存在类对象或结构中的数据差异很大。没有通用的查询语言从数据结构中获取数据 -
LINQ的查询语法 – 示例练习【点击查看】
写LINQ是又两种语法:1.查询语法:查询语法是声明形式的,使用查询表达式形式来书写。2.方法语法:方法语法是命令形式的,它使用的是标准的方法调用。方法是一组叫做标准查询运算符的方法。
八,委托和事件(71~80)
-
委托介绍 – 战士升级示例【点击查看】
委托的存在是因为,我们有时候需要将一个函数作为另一个函数的参数,这时就要用的委托机制。委托用关键字delegate声明,他实际上定义了一种“函数类型”,明确规定了函数参数类型和返回值类型。 -
多波委托 – 妈妈喊吃饭啦【点击查看】
多播委托,我们把包含多个函数的委托称为多播委托,所有被委托函数的引用都存储在多播委托类的调用列表中,当调用多播委托时,会按顺序依次调用列表中的所有函数。 -
匿名函数 – lamada表达式【点击查看】
匿名方法提供了一种传递代码块作为委托参数的技术。匿名方法是没有名称只有主体的方法。匿名方法本质上是一个方法,只是没有名字,任何使用委托变量的地方都可以使用匿名方法。 -
事件介绍 – 热水器烧水示例【点击查看】
事件和函数的关系:事件具有可以注册多个函数(和解绑函数)的功能,而函数如果要注册和解绑其他在其主体上运行的函数则需要改动该函数本体的代码,这就是区别。 -
系统事件 – Actin/Func【点击查看】
除了我们自己定义的委托之外,系统还给我们提供过来一个内置的委托类型,Action和Func。两种委托类型的区别在于:Action委托不提供返回类型, 而Func提供返回类型 -
委托事件实例练习1 – 猫捉老鼠【点击查看】
杰瑞鼠带着和杰克鼠去汤姆猫家偷奶酪,当有一只老鼠看到猫来了或者听见猫的声音都会做好逃跑的准备,并且通知同伴躲藏起来并且做好逃跑的准备。 -
委托事件实例练习2 – 刘备招亲甘露寺【点击查看】
刘备招亲 :故事出自《三国演义》。刘备借东吴的荆州后,没有归还之意,周瑜便定下了美人计,企图乘刘备过江之机,把刘备扣留起来作为人质,以夺取荆州。 -
委托事件实例练习3 – 观察者模式【点击查看】
观察者模式是一种行为设计模式, 允许你定义一种订阅机制, 可在对象事件发生时通知多个 “观察” 该对象的其他对象。 -
常见和不常见运算符汇总 – 示例练习【点击查看】
你知道C#的??运算符 和??=运算符吗? 来看看有哪些C#运算符是你没有使用过的吧。 -
类型转换汇总 – 拆箱装箱【点击查看】
类型转换是接受一个类型的值并使用它作为另一个类型的等价值的过程。转换后的值应和原值一样,但它是目标类型。
九,泛型和系统类(81~90)
-
泛型概念 – 泛型类/接口/委托/方法【点击查看】
泛型是程序设计语言的一种特性。允许程序员在强类型程序设计语言中编写代码时定义一些可变部分,那些部分在使用前必须作出指明。各种程序设计语言和其编译器、运行环境对泛型的支持均不一样。将类型参数化以达到代码复用提高软件开发工作效率的一种数据类型。 -
泛型方法 – Where约束语句 – 泛型单例【点击查看】
由于泛型类型参数可以接受任意参数类型,当我们需要提供额外的信息让编译器可以接受哪些类型,这些额外的信息叫做约束;只有符合约束的实参才能用类型参数。 -
ArrayList数组列表 – 代码示例【点击查看】
C#为我们提供了多种强大,易用的集合类,实现了多种不同类型的集合,我们可以根据实际用途来选择适合的集合类型。 -
List列表 – 扑克排序【点击查看】
List类是 ArrayList 类的泛型等效类。该类使用大小可按需动态增加的数组实现 IList泛型接口。 -
Stack栈 – 中缀表达式转后缀表达式【点击查看】
栈是一种特殊的数据类型,先存储的元素最后被使用,这种操作通常称为先进后出(FILO),通常的操作只有两种,分别是入栈(压栈),出栈。两种操作的元素都在栈顶 -
Queue队列 – 回文字符串【点击查看】
队列代表了一个先进先出的对象集合。当需要对各项进行先进先出的访问时,则使用队列。当您在列表中添加一项,称为入队,当您从列表中移除一项时,称为出队。 -
HasTable哈希表 – 几种遍历方式【点击查看】
Hashtable类表示基于键的哈希码组织的键和值对的集合。它使用键来访问集合中的元素。哈希表中的每个项目都有一个键 / 值对;键用于访问集合中的项目。 -
Dictinary字典 – 21点游戏【点击查看】
Dictionary泛型类提供从一组键到一组值的映射。字典中的每个添加都包含一个值及其关联的键。使用其键检索值非常快,接近 O(1),因为Dictionary & lt; TKey,TValue & gt;类是作为哈希表实现的。 -
SrtedList & SrtedDictinary – 对比分析【点击查看】
排序列表是数组和哈希表的组合。它包含一个可使用键或索引访问各项的列表。如果您使用索引访问各项,则它是一个动态数组(ArrayList),如果您使用键访问各项,则它是一个哈希表(Hashtable)。集合中的各项总是按键值排序。 -
Tuple元组 – 订单查询【点击查看】
Tuple 是在.NET Framework 4.0中引入的。元组是一种数据结构,包含一系列不同数据类型的元素。它可以用于您希望拥有一个数据结构来保存具有属性的对象,但您不想为其创建单独的类型。
十,其他知识点(91~100)
-
预处理器指令 – 示例代码【点击查看】
处理器指令从来不会被翻译为可执行代码中的命令,但会影响编译过程的各个方面。预处理指令提供按条件跳过源文件中的节、报告错误和警告条件,以及描绘源代码的不同区域的能力。 -
本地数据交互 – 文件概述【点击查看】
对于计算机而言,文件往往保存在磁盘之类的外部设备中,对文件的操作常常涉及对相关文件夹的操作,操作文件和操作文件夹是程序访问文件的两个主要方面。 -
本地数据交互 – 读写txt文本文件【点击查看】
文件相关类,FileInfo类介绍和使用示例,Directory类介绍和使用示例;eStream,StreamReader,StreamWriter:文件流相关介绍和使用示例 -
本地数据交互 – 读写二进制文件【点击查看】
BinaryReader类用特定的编码将基元数据类型读作二进制值,BinaryWriter类以二进制形式将基元类型写入流,并支持用特定的编码写入字符串。 -
本地数据交互 – 读写pdf文件【点击查看】
操作PDF文档需要使用iTextSharp对象,它是一个开源的PDF操作类库。解决System.NotSupportedException:“No data is available for encoding 1252.报错问题, -
本地数据交互 – 读写excel文件【点击查看】
微软提供了用以操作Office文档的库。如Microsoft Excel Object Library 、 Microsoft Word Object Library 、 Microsoft PowerPoint Object Library 等 -
线程&多线程 – 开启线程的几种方式【点击查看】
线程被定义为程序的执行路径。每个线程都定义了一个独特的控制流。 -
线程&多线程 – Task任务 - 模拟支付【点击查看】
C#异步多线程Task的介绍和使用,从相关关键字到使用示例,详细解析Task和TaskCompletionSource的使用方法。 -
特性详解 – 自定义特性【点击查看】
特性其实就是一个类,直接或间接继承自Attribute。.NET预定了很多特性,我们也可以声明自定义特性。 -
反射详解 – 检索特性【点击查看】
反射指程序可以访问、检测和修改它本身状态或行为的一种能力。所谓的反射则是把类或方法的标签信息提取出来。
后语
完整导图分享
以上是关于什么是ZK-Rollup(零知识汇总)?的主要内容,如果未能解决你的问题,请参考以下文章