2大模块+20个函数,完美诠释Python随机过程~
Posted 尤尔小屋的猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2大模块+20个函数,完美诠释Python随机过程~相关的知识,希望对你有一定的参考价值。
公众号:尤而小屋
作者:Peter
编辑:Peter
大家好,我是Peter~
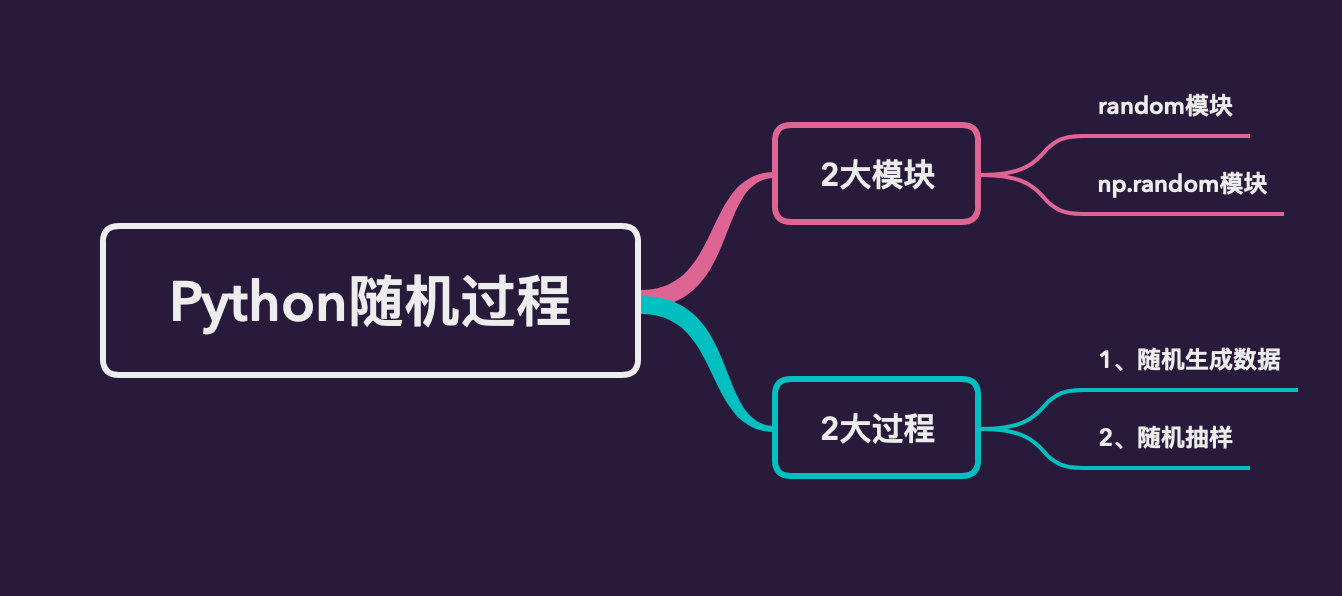
本文详细地介绍基于Python的第三方库random和numpy.random模块进行随机生成数据和随机采样的过程。
导入库
import random
import numpy as np
import pandas as pd
一、random模块
Python中的random模块实现了各种分布的伪随机数生成器。
random.random()
用于生成一个0到1的随机符点数: 0 <= n < 1.0
我们可以模仿多次,每次生成的结果是不同的:
random.random()
0.47917938679860983
random.random()
0.5609907030373721
random.uniform()
返回一个随机的浮点数
random.uniform(1,10)
6.001485472959377
同样的改变区间,每次生成不同的数据:
random.uniform(2,5)
3.9644214464183154
random.randint()
返回的是一个随机整数;重复操作生成不同的数据:
random.randint(1,10)
7
random.randint(2,7)
3
random.randrange()
random.randrange([start], stop[, step])
返回的结果就是一个数值
random.randrange(10) # 默认起始值是0
1
random.randrange(1,10) # 指定头尾
7
random.randrange(1,10,2) # 指定步长
1
random.randrange(-6,-1) # 范围为负数
-2
random.choices()
针对序列进行随机取数的一个函数
random.choices(sequence, weights=None, cum_weights=None, k=1)
- sequence:待抽取的序列;list,tuple,字符串等
- weights:列表是可以权衡每个值的可能性,可选
- cum_weights:列表是可以权衡每个值的可能性,只有这一次累积的可能性
- k:可选。一个定义返回列表长度的整数
来自中文官网的解释:https://docs.python.org/zh-cn/3/library/random.html
如果指定了 weight 序列,则根据相对权重进行选择。 或者,如果给出 cum_weights 序列,则根据累积权重(可能使用 itertools.accumulate() 计算)进行选择。
例如,相对权重[10, 5, 30, 5]相当于累积权重[10, 15, 45, 50]。 在内部,相对权重在进行选择之前会转换为累积权重,因此提供累积权重可以节省工作量。
1、针对列表的随机取数
# 1、列表
names = ["Mike","Tom","Peter","Jimmy"]
random.choices(names)
['Tom']
random.choices(names)
['Mike']
random.choices(names)
['Jimmy']
2、针对元组的随机取数:
# 2、元组
fruits = ("苹果","梨","葡萄","香蕉")
random.choices(fruits)
['梨']
random.choices(fruits)
['梨']
random.choices(fruits)
['葡萄']
3、针对字符串的随机取数:
# 3、字符串
address = "abcdefg"
random.choices(address)
['g']
重复操作返回不同的数据:
random.choices(address)
['a']
random.choice()
从序列中随机选取一个数据,返回的是一个字符,而不是列表
random.choice(names) # choice
'Mike'
random.choice(fruits) # choice
'苹果'
random.choice(address) # choice
'a'
要注意random.choices返回的是列表:
random.choices(address) # choices:返回列表
['g']
random.shuffle()
将一个列表(只针对列表)中的数据随机打乱
names # 打乱前
['Mike', 'Tom', 'Peter', 'Jimmy']
random.shuffle(names)
names # 打乱后
['Tom', 'Peter', 'Mike', 'Jimmy']
random.sample()
random.sample的函数原型为:random.sample(sequence, k)
从指定序列中随机获取指定长度的片断,sample函数不会修改原有序列。
用于无重复的随机抽样
number = [1,2,3,4,5,6,7,8,9,10]
# 从中随机选择6个数据
random.sample(number, 6)
[9, 6, 7, 4, 8, 3]
number # 原数据是不变的
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
random.seed
random.seed(a, version):自定义随机数生成器的起始编号,保证每次运行的结果是相同的。就是我们通常理解的设置随机种子
同样的种子下操作3次,结果是相同的:
random.seed(3)
random.random()
0.23796462709189137
random.seed(3)
random.random()
0.23796462709189137
random.seed(3)
random.random()
0.23796462709189137
np.random模块
在numpy中同样也有一个random能够用于生成各种随机数据,同时也能够用于数据的随机采样
np.random.rand()
生成指定维度的的[0,1)范围之间的随机数,输入参数为维度
np.random.rand(3) # 一维
array([0.56316478, 0.19472655, 0.77416481])
np.random.rand(3,2) # 二维
array([[0.53948953, 0.28900922],
[0.50819889, 0.87661466],
[0.6275246 , 0.50510408]])
np.random.rand(3,2,2) # 三维
array([[[0.07652093, 0.08418762],
[0.26209203, 0.62653792]],
[[0.35453925, 0.79562255],
[0.38392161, 0.13594379]],
[[0.76627042, 0.46727042],
[0.71653905, 0.36350333]]])
random.randint()
具体语法为:
random.randint(low, high=None, size=None, dtype=int)
np.random.randint(10) # 指定low
1
np.random.randint(2, 100) # 指定low和high
2
np.random.randint(2,100,size=5) # 指定size
array([45, 45, 17, 78, 72])
np.random.randint(2,100,5) # 指定size
array([13, 61, 9, 77, 25])
np.random.randint(2,100,size=(5,3)) # 指定多维度size
array([[89, 4, 94],
[96, 26, 76],
[71, 2, 78],
[26, 79, 68],
[30, 85, 94]])
np.random.randn()
生成指定维度的服从标准正态分布的随机数,输入参数为维度
np.random.randn(3) # 一维
array([ 0.86231343, -0.17504608, -1.18435821])
np.random.randn(2, 4) # 二维
array([[ 0.6815724 , -0.40425239, -0.70292058, 1.50423829],
[ 1.39392811, 1.21985809, -0.13557424, 0.01812161]])
np.random.random_integers()
返回范围为[low,high] 闭区间 随机整数;可放回的抽样取数
np.random.random_integers(2,size=5)
array([1, 1, 2, 1, 1])
np.random.random_integers(1,6,size=5)
array([5, 3, 5, 1, 1])
np.random.random_integers(1,6,size=8)
array([4, 2, 4, 2, 4, 3, 5, 6])
np.random.random()
返回0-1之间指定维度下的随机数
np.random.random(size=None)
np.random.random()
0.5446614807473444
np.random.random(size=(2,3))
array([[0.24849247, 0.24794785, 0.12318699],
[0.38708798, 0.12982558, 0.67378513]])
np.random.random(size=(2,3,4))
array([[[0.34112893, 0.19507699, 0.0998322 , 0.1613075 ],
[0.14750045, 0.64746506, 0.37992539, 0.96126298],
[0.4169575 , 0.21279002, 0.84499108, 0.46106979]],
[[0.35969999, 0.83434346, 0.435845 , 0.22377047],
[0.49878421, 0.7140939 , 0.19513683, 0.90309624],
[0.84402436, 0.94049321, 0.44680034, 0.12482742]]])
np.random.seed()
设置随机种子,保证每次的结果相同
np.random.seed(20)
np.random.random()
0.5881308010772742
np.random.seed(20)
np.random.random()
0.5881308010772742
np.random.seed(20)
np.random.random()
0.5881308010772742
np.random.choice()
从序列中随机选择数据,放回或者不放回可指定
np.random.choice(a, size = None, replace = True, p = None)
p可以指定a中每个元素被选择的概率
# 等价于: np.random.randint(0,5,3)
np.random.choice(5, 3)
array([4, 2, 1])
下面通过一个详细的例子来说明各个参数的使用
numbers = [1,2,3,4,5,6,7,8,9,10]
np.random.choice(numbers) # 抽一个数据
5
np.random.choice(numbers,size=5) # 一维抽样
array([7, 8, 3, 1, 7])
np.random.choice(numbers,size=(2,4)) # 二维抽样
array([[ 9, 6, 4, 1],
[ 7, 7, 1, 10]])
在无放回抽样中,取出来的数据是没有重复的:
# 无放回抽样
np.random.choice(
numbers,
size=5,
replace=False # 不放回
)
array([1, 5, 2, 9, 4])
还可以指定每个元素被抽取的概率,p中所有元素的和为1,且个数必须为待抽取的序列中的个数相同:
np.random.choice([1,2,3,4,5],
size=3,
p=[0.2,0.2,0.1,0.2,0.3])
array([2, 2, 5])
np.random.standard_normal()
标准正态分布随机取数,就一个可选参数size,用来指定维度
np.random.standard_normal()
-2.098773908831827
np.random.standard_normal(10)
array([-1.85559768, 0.55097131, -0.36372358, -0.99642606, -1.1653022 ,
1.30970062, 0.32287203, 0.64708367, -0.49947789, -0.38030095])
np.random.standard_normal(size=(3,2))
array([[ 1.60136877, -0.21666908],
[-0.76330235, 1.4667905 ],
[-0.45362263, 0.65496734]])
np.random.random_sample()
用于生成0-1之间的随机浮点数或者数组
np.random.random_sample()
0.29533501415054364
np.random.random_sample(size=(3,2))
array([[0.32882246, 0.26813417],
[0.13655489, 0.37195498],
[0.01574185, 0.34472747]])
np.random.shuffle()
对给定的数据进行重排序,如果数据为为多维数组,只沿第一条轴洗牌
names
['Tom', 'Peter', 'Mike', 'Jimmy']
np.random.shuffle(names) # 第一次洗牌
names
['Peter', 'Tom', 'Mike', 'Jimmy']
np.random.shuffle(names) # 第二次洗牌
names
['Tom', 'Jimmy', 'Mike', 'Peter']
当给定的数据是多维度的,该如何处理?
# 如果数据是多维度
data = np.random.random_sample(size=(3,2))
data
array([[0.64656729, 0.42563648],
[0.51356833, 0.50125784],
[0.03708381, 0.7081161 ]])
np.random.shuffle(data)
data
array([[0.51356833, 0.50125784],
[0.03708381, 0.7081161 ],
[0.64656729, 0.42563648]])
np.random.permutation()
同样也是洗牌的过程,只是不会打乱原数据的顺序
names
['Tom', 'Jimmy', 'Mike', 'Peter']
permutation()没有改变names的顺序:
np.random.permutation(names)
array(['Peter', 'Jimmy', 'Mike', 'Tom'], dtype='<U5')
names
['Tom', 'Jimmy', 'Mike', 'Peter']
下面执行shuffle操作,已经改变了顺序:
np.random.shuffle(names)
names
['Tom', 'Peter', 'Jimmy', 'Mike']
以上是关于2大模块+20个函数,完美诠释Python随机过程~的主要内容,如果未能解决你的问题,请参考以下文章