Python爬虫 解析 xpath -- Xpath Helper插件的安装xpath的基本使用
Posted CodeJiao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫 解析 xpath -- Xpath Helper插件的安装xpath的基本使用相关的知识,希望对你有一定的参考价值。
1. Xpath Helper插件的安装
我这里使用的是QQ游览器
安装了xPath helper后就能轻松获取html元素的xPath,程序员就再也不需要通过
搜索html源代码,定位一些id去找到对应的位置去解析网页了。
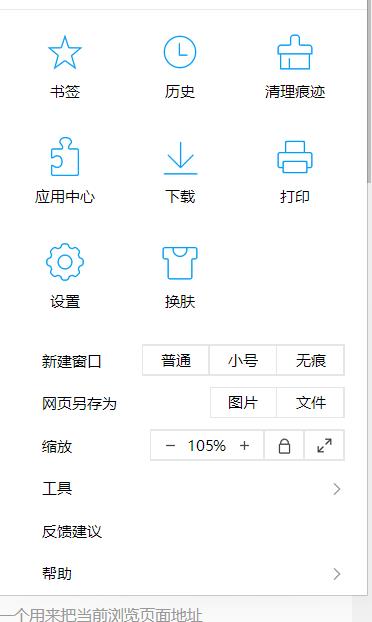
1.1 点击应用中心
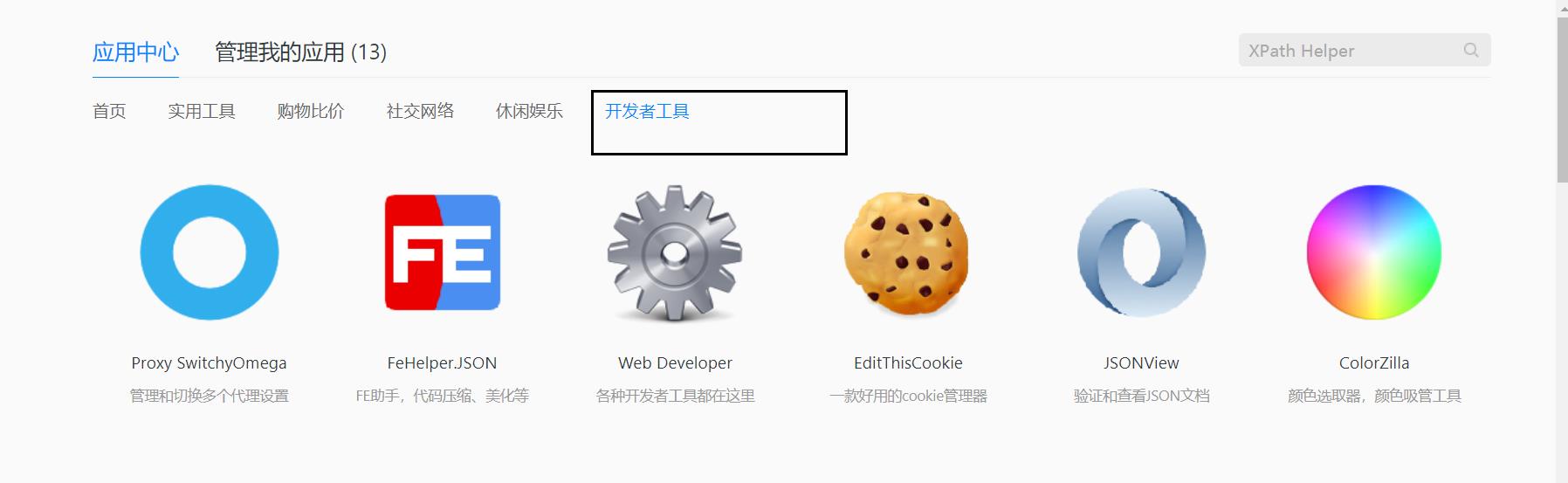
1.2 点击开发者工具
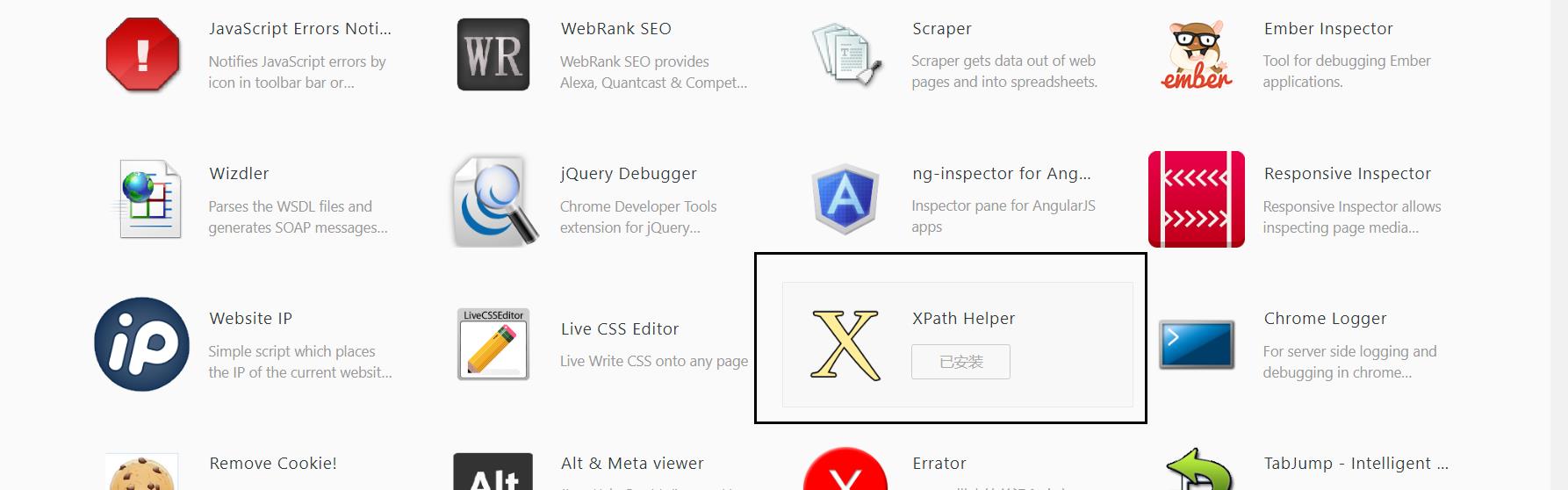
1.3 找到并且安装XPath Helper
安装成功按 ctrl + shift + x 即可开启和关闭 XPath Helper 插件:

2. xpath的基本使用
- 安装lxml库
- 导入lxml.etree from lxml import etree
- etree.parse() 解析本地文件 html_tree = etree.parse(‘XX.html’)
- etree.HTML() 服务器响应文件 html_tree = etree.HTML(response.read().decode(‘utf‐8’)
- html_tree.xpath(xpath路径)
2.1 安装lxml库
在当前项目的Python依赖目录安装lxml


2.2 学习xpath基本语法

XPath:
// 根节点
/ 节点
@ 属性


我们现在来定位 “名次 ”
tr里面有许多的td元素 可以用[index]的方式来定位具体的元素 注意 index是从1开始
//div[@id='data265440']/table[@border='1']/tbody/tr[@class='firstRow']/td[1]
开始测试:
# 进行 html静态页面字符串 的数据提取
def getDataInfo(html):
# 4. 创建一个html对象
myHtml = etree.HTML(html)
# text() 是把定位到的数据转换成文本格式
print(myHtml.xpath("//div[@id='data265440']/table[@border='1']/tbody/tr[@class='firstRow']/td[1]/text()"))
if __name__ == '__main__':
getDataInfo(getHtmlInfo())
主函数的运行结果:可以看见得到的都是列表的格式的数据

2.3 解析本地文件
这是我本地创建的一个html文件:

<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<title>Title</title>
</head>
<body>
<ul>
<li id="l1" class="c1">北京</li>
<li id="l2">上海</li>
<li id="c3">深圳</li>
<li id="c4">武汉</li>
</ul>
<ul>
<li>大连</li>
<li>锦州</li>
<li>沈阳</li>
</ul>
</body>
</html>
py代码:
- 查找ul下面的li
from lxml import etree
# xpath解析本地文件
tree = etree.parse('index.html')
# 查找ul下面的li
li_list = tree.xpath('//body/ul/li')
# 判断列表的长度
print(li_list)
print(len(li_list))

- 查找所有有id的属性的li标签的内容
from lxml import etree
# xpath解析本地文件
tree = etree.parse('index.html')
# 查找所有有id的属性的li标签
# text()获取标签中的内容
li_list = tree.xpath('//ul/li[@id]/text()')
# 判断列表的长度
print(li_list)
print(len(li_list))

- 找到id为l1的li标签 注意引号的问题
from lxml import etree
# xpath解析本地文件
tree = etree.parse('index.html')
# 找到id为l1的li标签 注意引号的问题
li_list = tree.xpath('//ul/li[@id="l1"]/text()')
# 判断列表的长度
print(li_list)
print(len(li_list))

- 查找到id为l1的li标签的class的属性值
from lxml import etree
# xpath解析本地文件
tree = etree.parse('index.html')
# 查找到id为l1的li标签的class的属性值
li_list = tree.xpath('//ul/li[@id="l1"]/@class')
# 判断列表的长度
print(li_list)
print(len(li_list))

- 查询id中包含l的li标签
from lxml import etree
# xpath解析本地文件
tree = etree.parse('index.html')
# 查询id中包含l的li标签
li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')
# 判断列表的长度
print(li_list)
print(len(li_list))

- 查询id的值以c开头的li标签
from lxml import etree
# xpath解析本地文件
tree = etree.parse('index.html')
# 查询id的值以c开头的li标签
li_list = tree.xpath('//ul/li[starts-with(@id,"c")]/text()')
# 判断列表的长度
print(li_list)
print(len(li_list))

- 查询id为l1和class为c1的li标签
from lxml import etree
# xpath解析本地文件
tree = etree.parse('index.html')
# 查询id为l1和class为c1的
li_list = tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()')
# 判断列表的长度
print(li_list)
print(len(li_list))

- 查询id为l1或者l2的li标签
from lxml import etree
# xpath解析本地文件
tree = etree.parse('index.html')
# 查询id为l1或者l2的li标签
li_list = tree.xpath('//ul/li[@id="l1"]/text() | //ul/li[@id="l2"]/text()')
# 判断列表的长度
print(li_list)
print(len(li_list))

2.4 解析服务器响应文件
获取百度的百度一下

# (1) 获取网页的源码
# (2) 解析 解析的服务器响应的文件 etree.HTML
# (3) 打印
import urllib.request
url = 'https://www.baidu.com/'
headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
# 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器访问服务器
response = urllib.request.urlopen(request)
# 获取网页源码
content = response.read().decode('utf-8')
# 解析网页源码 来获取我们想要的数据
from lxml import etree
# 解析服务器响应的文件
tree = etree.HTML(content)
# 获取想要的数据 xpath的返回值是一个列表类型的数据
result = tree.xpath('//input[@id="su"]/@value')
print(result)
运行结果:

以上是关于Python爬虫 解析 xpath -- Xpath Helper插件的安装xpath的基本使用的主要内容,如果未能解决你的问题,请参考以下文章