阿里云大佬叮嘱我务必要科普这个 Elasticsearch API
Posted 铭毅天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里云大佬叮嘱我务必要科普这个 Elasticsearch API相关的知识,希望对你有一定的参考价值。
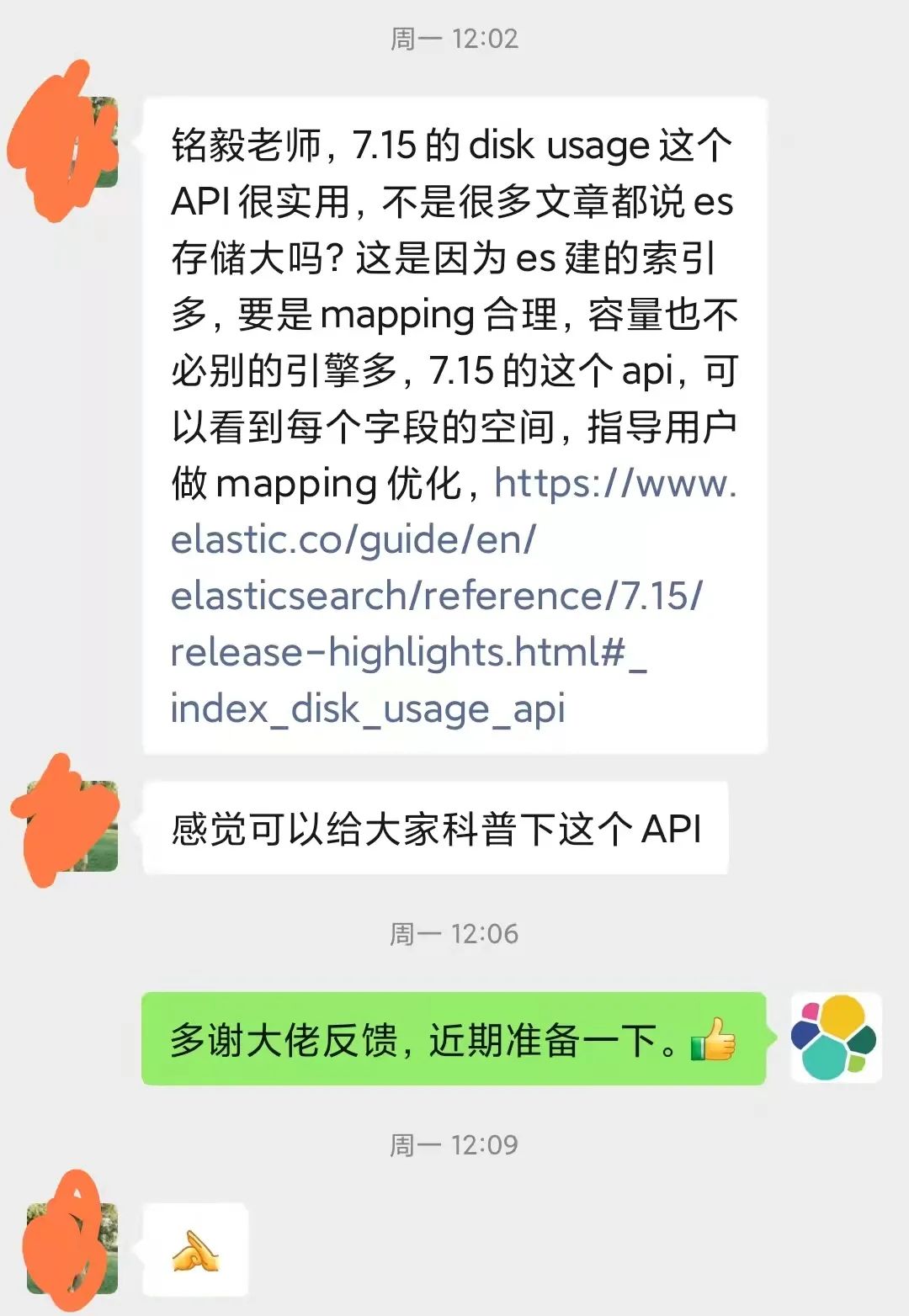
上截图是阿里云魏子珺大佬(阿里巴巴集团技术专家)周一叮嘱我的。
魏子珺大佬的早期分享参考:
2021 年 Elasticsearch 生态和技术峰会干货总结
1、啥 API 这么重要,阿里大佬要亲自叮嘱?
There’s a new API that supports analyzing the disk usage of each field of an index, including the entire index itself. The API estimates the disk usage of a field by iterating over its content and tracking the number of bytes read
https://www.elastic.co/guide/en/elasticsearch/reference/7.15/release-highlights.html#_index_disk_usage_api
POST kibana_sample_data_ecommerce/_disk_usage?run_expensive_tasks=true用途:
第一:支持统计索引自身的磁盘使用。
第二:支持统计每个字段级别的磁盘使用。
2、_disk_usage API 适用场景是啥?
此 API 不支持在以前的 Elasticsearch 版本中创建的索引。
适用于大索引。
PS:小索引的结果可能不准确,因为 API 可能无法分析索引的某些细节部分。
本质用途:
技术人员可直观看到索引各个字段占据存储空间的大小。
评估数据建模的合理性。
定量指导Mapping 优化。
3、_disk_usage API对应版本?
7.15+ 之后的版本才可以用哦。
4、_disk_usage API 如何用?
POST kibana_sample_data_ecommerce/_disk_usage?run_expensive_tasks=true注意一个细节:run_expensive_tasks 意味着这个 API 非常耗费资源,所以大家别频繁验证线上环境。
召回结果如下:
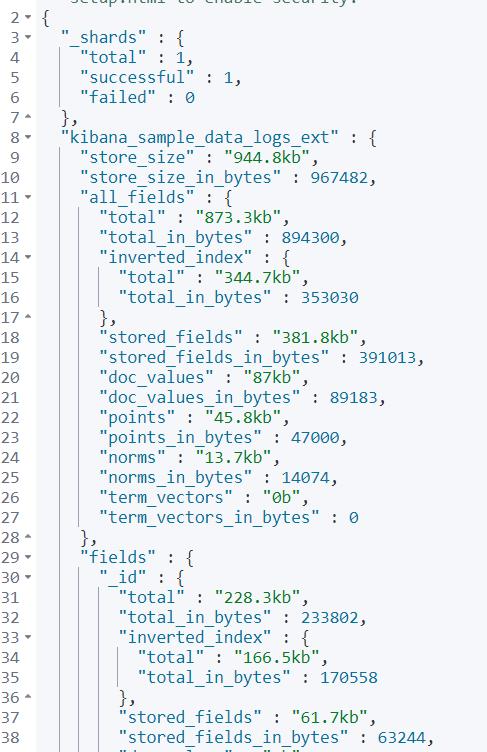
执行结果部分截图
每个字段的磁盘使用率清晰、明白的列举出来了。
7.17 版本 Elasticsearch 集群验证一把:
POST _reindex
"source":
"index": "kibana_sample_data_logs",
"_source": [
"host",
"index",
"ip",
"tags",
"response"
]
,
"dest":
"index": "kibana_sample_data_logs_ext"
POST kibana_sample_data_logs_ext/_disk_usage?run_expensive_tasks=true官方并没有统计,我把结果数据梳理统计了一下,如下两张图所示:
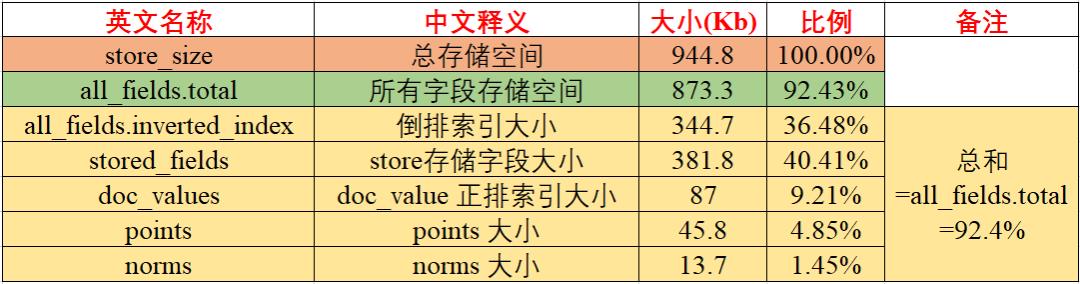
说明了啥?
所有字段的存储实际是:倒排索引所占据存储空间大小 + doc_values 正排索引存储空间大小 + store_fields 存储空间大小等的总和。
再深问一句,这个和咱们最早设定的 Mapping 就有关系了,和数据建模就有关系了。
看一下 Mapping:
"kibana_sample_data_logs_ext" :
"mappings" :
"properties" :
"host" :
"type" : "text",
"fields" :
"keyword" :
"type" : "keyword",
"ignore_above" : 256
,
"index" :
"type" : "text",
"fields" :
"keyword" :
"type" : "keyword",
"ignore_above" : 256
,
"ip" :
"type" : "text",
"fields" :
"keyword" :
"type" : "keyword",
"ignore_above" : 256
,
"response" :
"type" : "long"
,
"tags" :
"type" : "text",
"fields" :
"keyword" :
"type" : "keyword",
"ignore_above" : 256
再进一步看看各个字段所占据的存储空间大小:
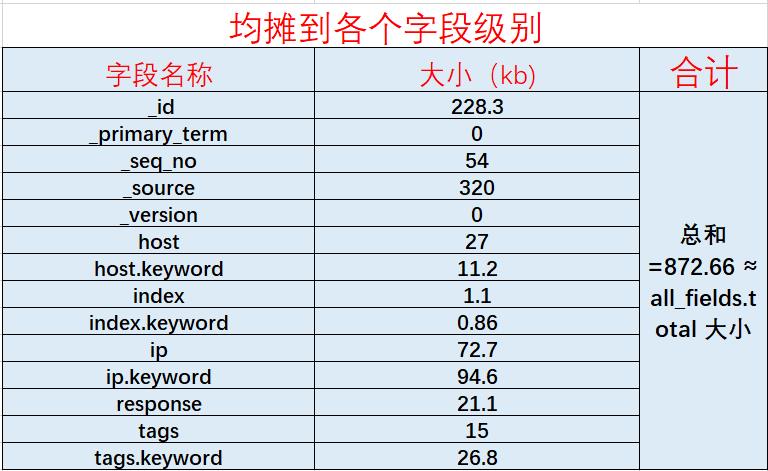
能有什么结论?
_source 是占据存储空间的。
默认的 Mapping 在 dynamic 默认为 true 的前提下字符串类型会包含两种类型:text 和 keyword,两个是分别占据不同的存储空间的。
数据建模建议:如果只需要全文检索,字符串类型设置 text 就足够了。
数据建模建议:如果不需要全文检索只需要排序和聚合,字符串类型设置 keyword 就足够了。
_version 是占据存储空间的,咱们的 update_by_query 和 delete_by_query 本质都是逻辑删除,势必会增加 _version 的空间。
如果未来再有字段选型搞不定存储空间的时候——用这个 API 一下就搞定了。
。。。。。
还能进一步推出很多有意思的结论。
5、_disk_usage API "牛逼"在什么地方?
之前我们对于磁盘占据空间是一个泛泛的整体概念,现在有了这个 API 我们可以做的很细了。
具体到哪个字段占据了多少磁盘知道了以后,极大便利的指导我们的数据建模。
相当于数据建模有了可量化的、可视化的参考依据。
之前两个同事可能为某个字段的某些属性的设置会争吵,甚至吵得不可开交。
现在不需要了,“走两步”,对比一下磁盘容量,直接就能给出孰优孰劣的结论。

图片来自:优酷
6、小结
个人更期望的功能就是字段存储空间的可视化功能,各个字段占据一目了然呈现出来,类似:search_profile 的功能。估计未来版本会出现。
欢迎大家留言说一下自己的思考。
您或者您的团队发现类似好用但相对小众的“新功能”,也欢迎第一时间联系我。我会尽自己的一点微薄之力,让更多 Elastic 爱好者知道。
感谢魏子珺大佬!
推荐
1、重磅 | 死磕 Elasticsearch 方法论认知清单(2021年国庆更新版)
2、Elasticsearch 7.X 进阶实战私训课(口碑不错)
6、从一个实战问题再谈 Elasticsearch 数据建模

更短时间更快习得更多干货!
和全球近 1600+ Elastic 爱好者一起精进!

比同事抢先一步学习进阶干货!
以上是关于阿里云大佬叮嘱我务必要科普这个 Elasticsearch API的主要内容,如果未能解决你的问题,请参考以下文章