r语言中随机正态分布均值
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了r语言中随机正态分布均值相关的知识,希望对你有一定的参考价值。
如图所示,正态分布中随机产生10个均值为1的序列赋值给x,再对x求均值,为什么不是1?
图片内容为:
> x<-c(rnorm(10,mean=1))
> x
[1] 1.63382782 1.41237007 0.21381031 1.95237903 1.08686937 2.70204065 0.01613913 0.49487134 1.23512581 1.98837463
> mean(x)
[1] 1.273581
----------------------------------------------------------------------------------------------
我想问的是为什么mean(x)不是1

> x <- c(1.63382782, 1.41237007, 0.21381031, 1.95237903, 1.08686937, 2.70204065, 0.01613913, 0.49487134, 1.23512581, 1.98837463)
> mean(x)
[1] 1.273581
如何在R语言中进行中文编程
又发现了个好玩的hiahiahia:
给四个例子,大家看了例子应该都能会用中文写r语言:
例1
预定义:
# 定义函数
"生成正态分布随机数"<-function(数量=1,均值=0,标准差=1){rnorm(数量,mean=均值,sd=标准差)}
"画个直方图"<-function(数据,是否转换为概率密度){
if(是否转换为概率密度=='是的'){
hist(数据,probability=TRUE)
}else{
hist(数据,probability=FALSE)
}
}
"计算核密度"<-function(x){density(x)}
"画条线"<-function(曲线数据,颜色,粗细程度){lines(曲线数据,col=颜色,lwd=粗细程度)}
中文编程:
# 中文编程代码部分
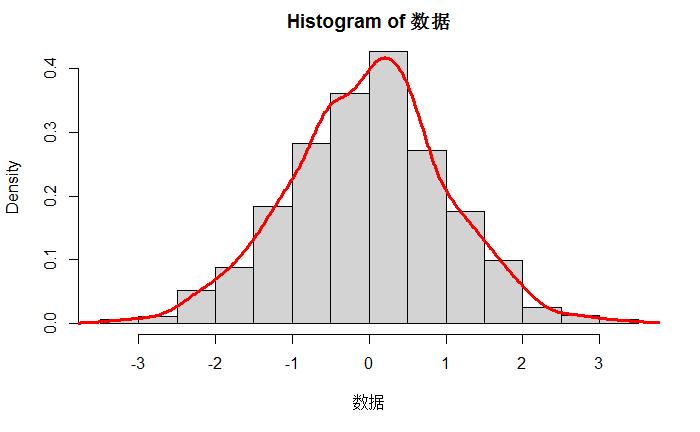
"正态分布数据"<-生成正态分布随机数(数量=1000,均值=0,标准差=1)
画个直方图(正态分布数据,是否转换为概率密度='是的')
画条线(计算核密度(正态分布数据),颜色='red',粗细程度=3)
效果:
例2
预定义:
# 定义函数
"输出"<-function(x){print(x)}
"求均值"<-function(x){mean(x)}
"建立集合"<-function(...){c(...)}
中文编程:
# 中文编程代码部分
"一群人的年龄"=建立集合(15,26,18,21,30)
输出(一群人的年龄)
"平均年龄"<-求均值(一群人的年龄)
输出(平均年龄)
结果:
[1] 15 26 18 21 30
[1] 22
例3
预定义:
# 定义函数
"输出"<-function(x){print(x)}
"生成正态分布随机数"<-function(数量=1,均值=0,标准差=1){rnorm(数量,mean=均值,sd=标准差)}
"排序"<-function(x){sort(x)}
"获取长度"<-function(x){length(x)}
"建立等差数列"<-function(开始,结尾,公差){seq(from=开始,to=结尾,by=公差)}
"求均值"<-function(x){mean(x)}
"求标准差"<-function(x){sd(x)}
"画条折线"<-function(横轴数据,纵轴数据,线的样式){
if(线的样式=='楼梯状'){
plot(横轴数据,纵轴数据,type="s")
}else{
plot(横轴数据,纵轴数据)
}
}
中文编程:
# 中文编程代码部分
# 数据生成
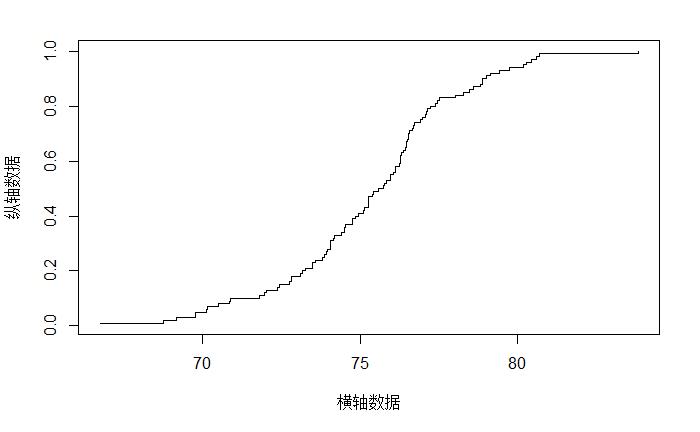
"正态分布数据"<-生成正态分布随机数(数量=100,均值=75,标准差=3)
# 概率分布图
"排序后数据"<-排序(正态分布数据)
"长度"<-获取长度(排序后数据)
"网格"<-建立等差数列(开始=1,结尾=长度,公差=1)/长度
"数据的均值"<-求均值(排序后数据)
"数据的标准差"<-求标准差(排序后数据)
输出(数据的均值)
输出(数据的标准差)
画条折线(排序后数据,纵轴数据=网格,线的样式='楼梯状')
结果:
[1] 75.36
[1] 2.914
例4
预定义:
# 定义函数
"输出"<-function(x){print(x)}
"建立等差数列"<-function(开始,结尾,公差){seq(from=开始,to=结尾,by=公差)}
"创建一个矩阵"<-function(用到的数据,矩阵行数,矩阵列数,按行排列){
if(按行排列=='是的'){
matrix(data=用到的数据,nrow=矩阵行数,ncol=矩阵列数,byrow=TRUE)
}else{
matrix(data=用到的数据,nrow=矩阵行数,ncol=矩阵列数,byrow=FALSE)
}
}
中文编程:
# 中文编程代码部分
"一个数列"<-建立等差数列(开始=1,结尾=17,公差=2)
输出(一个数列)
"第一个矩阵"<-创建一个矩阵(用到的数据=一个数列,矩阵行数=3,矩阵列数=3,按行排列='是的')
输出(第一个矩阵)
"第二个矩阵"<-创建一个矩阵(用到的数据=一个数列,矩阵行数=3,矩阵列数=3,按行排列='不要')
输出(第二个矩阵)
结果:
[1] 1 3 5 7 9 11 13 15 17
.
…[,1] [,2] [,3]
[1,] 1 3 5
[2,] 7 9 11
[3,] 13 15 17
.
…[,1] [,2] [,3]
[1,] 1 7 13
[2,] 3 9 15
[3,] 5 11 17
以上是关于r语言中随机正态分布均值的主要内容,如果未能解决你的问题,请参考以下文章