python tabula获取pdf的列表数据
Posted Jason_WangYing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python tabula获取pdf的列表数据相关的知识,希望对你有一定的参考价值。
tabula的功能比camelot更加强大,可以同时对多个表格数据进行提取。项目的具体地址请参考:https://github.com/chezou/tabula-py
安装
tabula的安装是非常简单的:
pip install tabula-py # 安装python扩展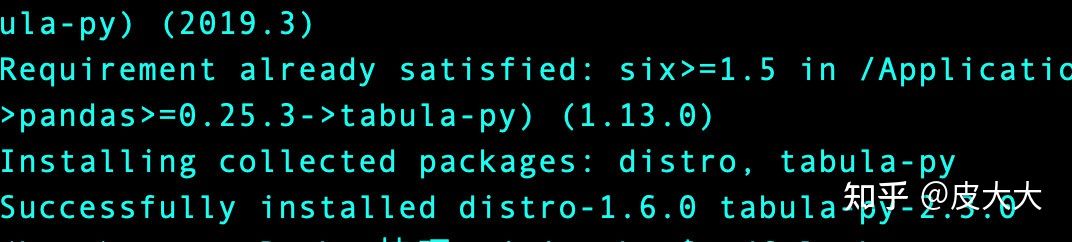
安装之后检验这个库是否安装成功:
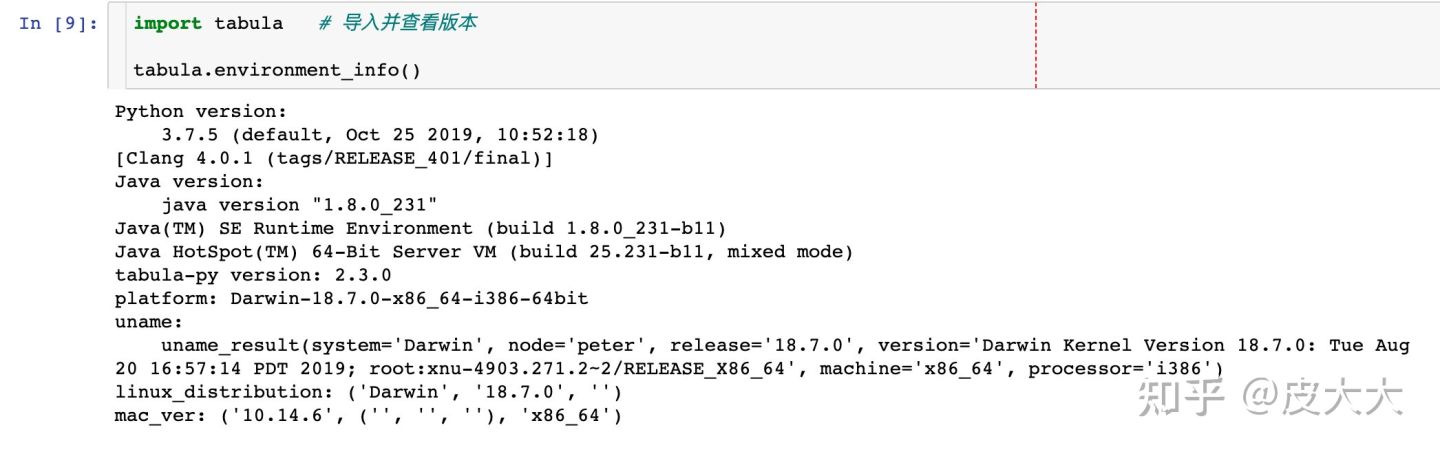
读取PDF文件
通过tabula这个库来读取PDF文件:
df1 = tabula.read_pdf("test.pdf",pages="all")
然后我们发现列表中唯一的一个元素就是dataframe:
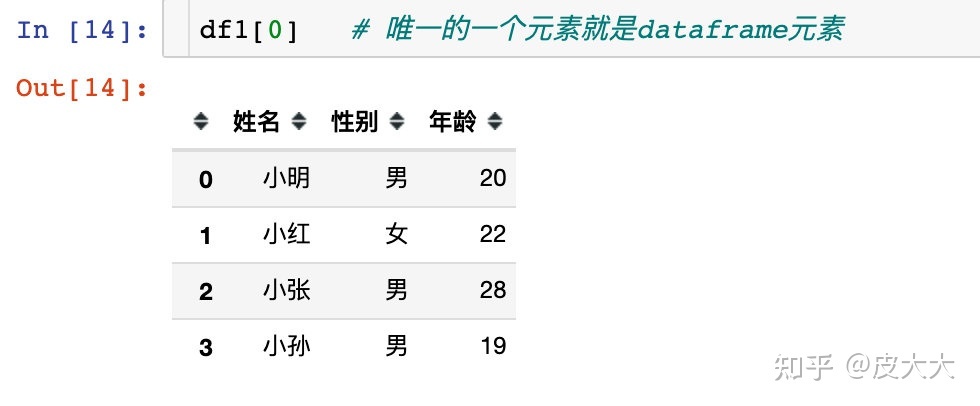
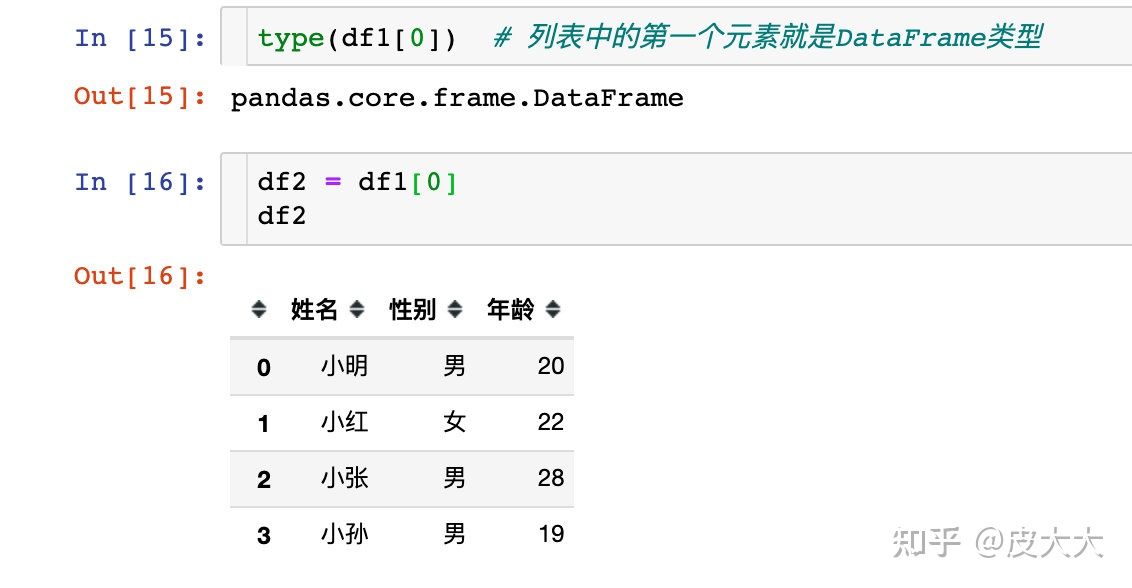
输出成csv文件
将读取到的数据输出成CSV格式的文件:
# 方式1:间接输出成csv格式
df2.to_csv("test2.csv")
# 方式2:直接输出成csv格式
tabula.convert_into("test.pdf","test3.csv",output_format="csv",pages='all')

上面读取的PDF文件是比较简单的,只有一页,而且刚好是一个很标准的表格形式的数据,下面看一个比较复杂的例子:
- PDF文件总共有3页
- 每页的表格数据格式有差异
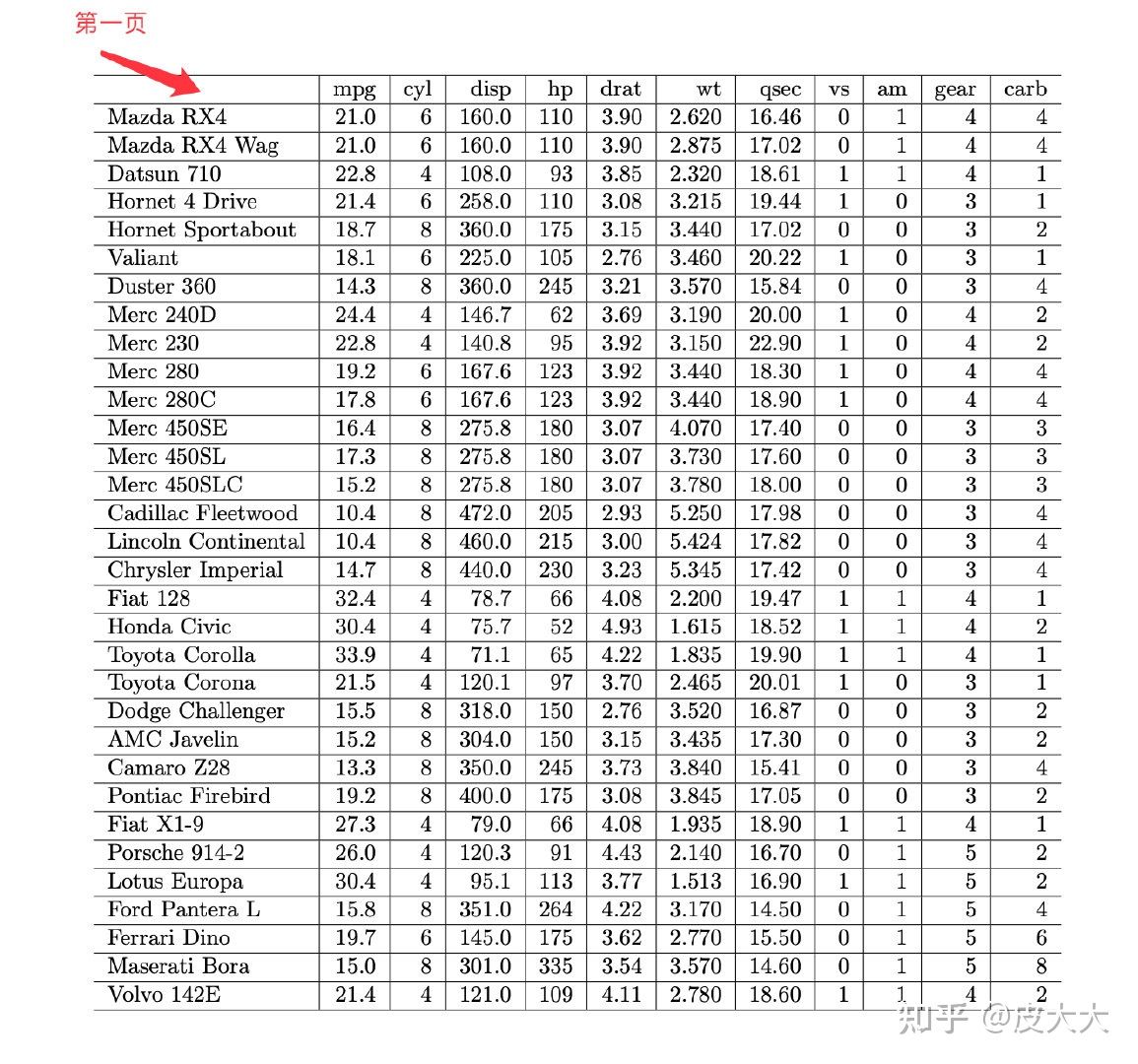
下面是第一页,第一列可以看成是索引:
在第二页中有两份表格,而且中间有很多的空白行:

第三页的数据比较标准:

这3页是在同一个PDF文件中,这3页是在同一个PDF文件中,这3页是在同一个PDF文件中
读取第一个表格
tab1 = tabula.read_pdf("data.pdf",stream=True)
len(tab1)
上面的红色提示中我们看到:当没有指定pages参数的时候,只会默认读取第一页的数据,所以列表的长度为1。
转成dataframe后将原来的索引变成新的一列(部分数据)

读取PDF全部数据
通过pages来读取全部数据:
tab2 = tabula.read_pdf("data.pdf",pages="all") # 获取全部数据all
len(tab2)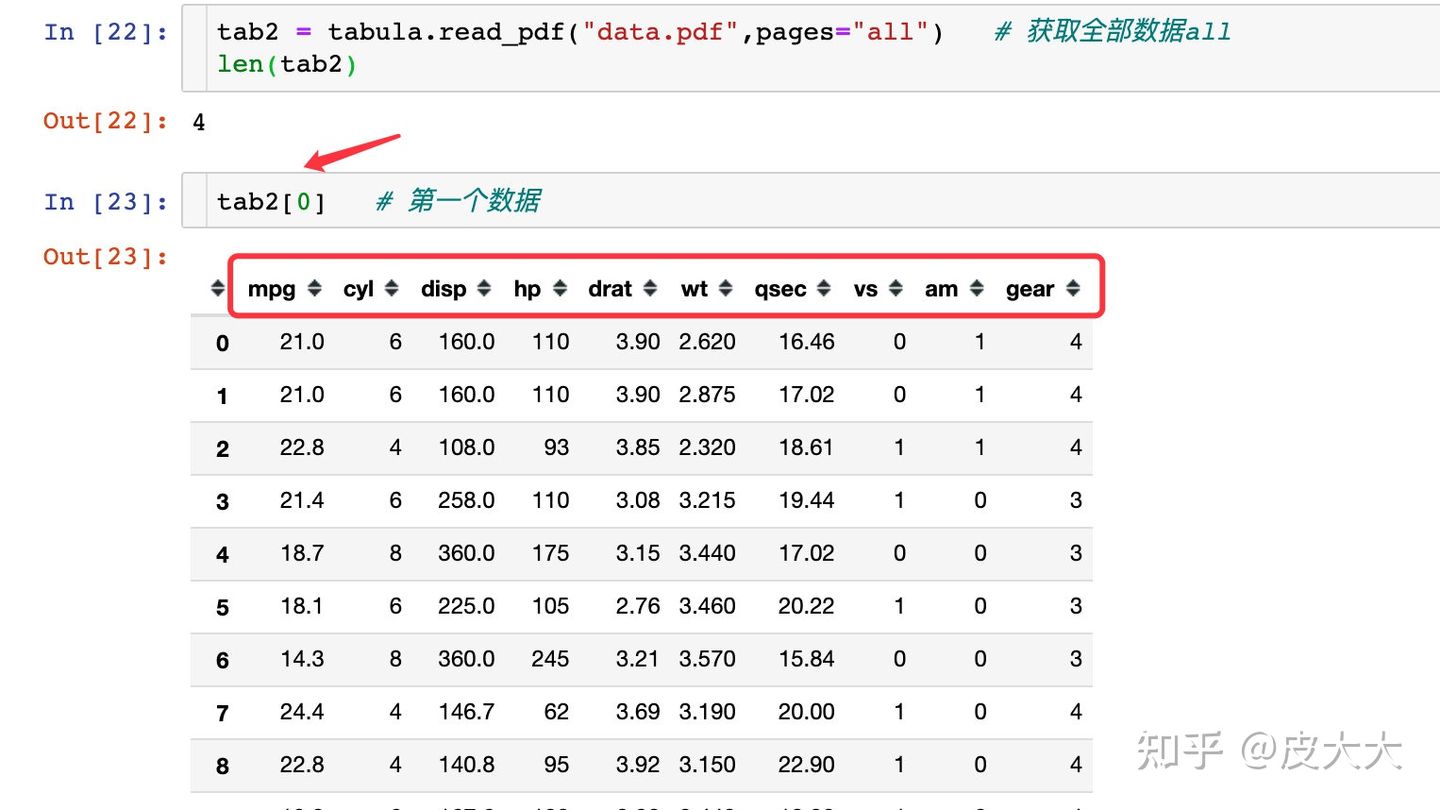
通过指定pages="all":
- 获取到了4个表格的数据,列表长度为4
- 第一个表格转成了dataframe数据后原来的行索引不存在,这个是和上面(没有pages参数)不同的地方
获取指定页面的数据
tab3 = tabula.read_pdf("data.pdf",
pages=3, # 表示第3页的数据
stream=True)
tab3[0]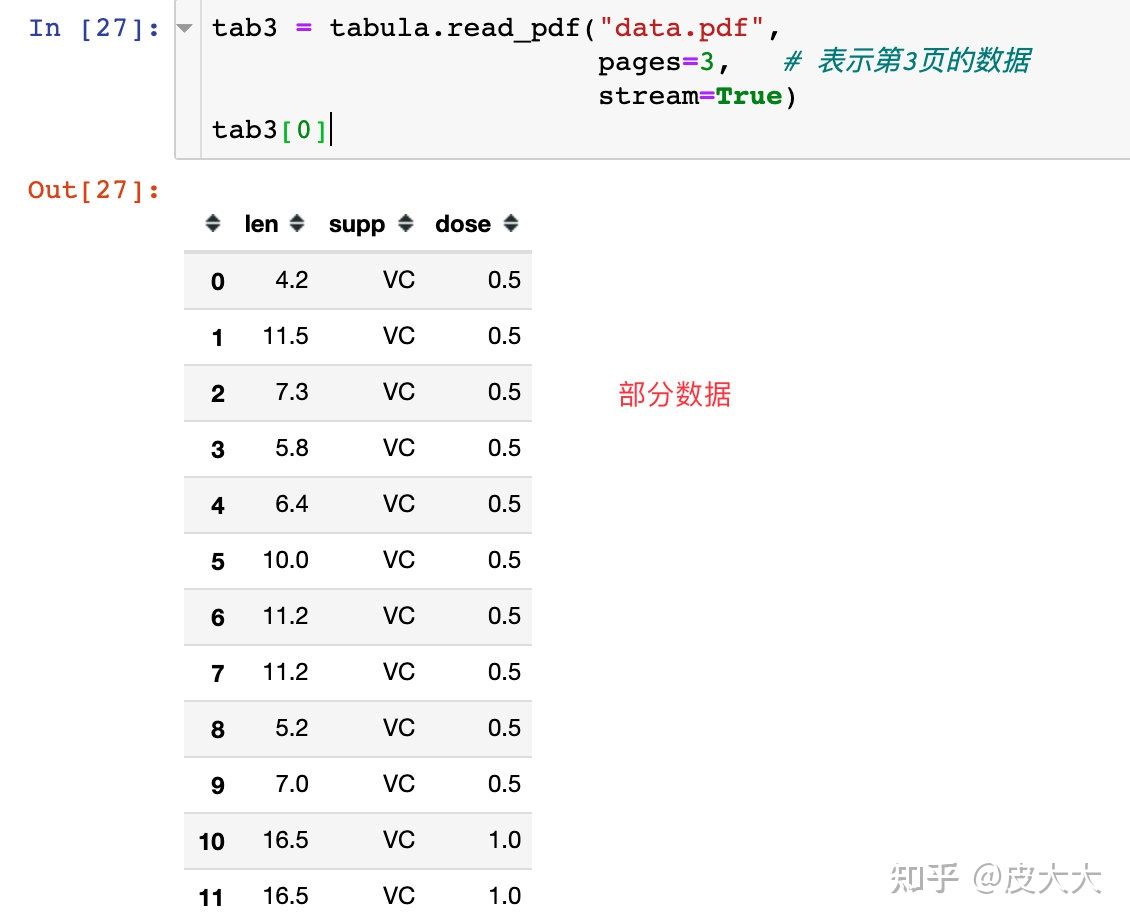
同时获取两个表格的数据:
tab4 = tabula.read_pdf("data.pdf",
pages="1,3", # 同时2个表格数据
stream=True)
len(tab4) # 长度为2
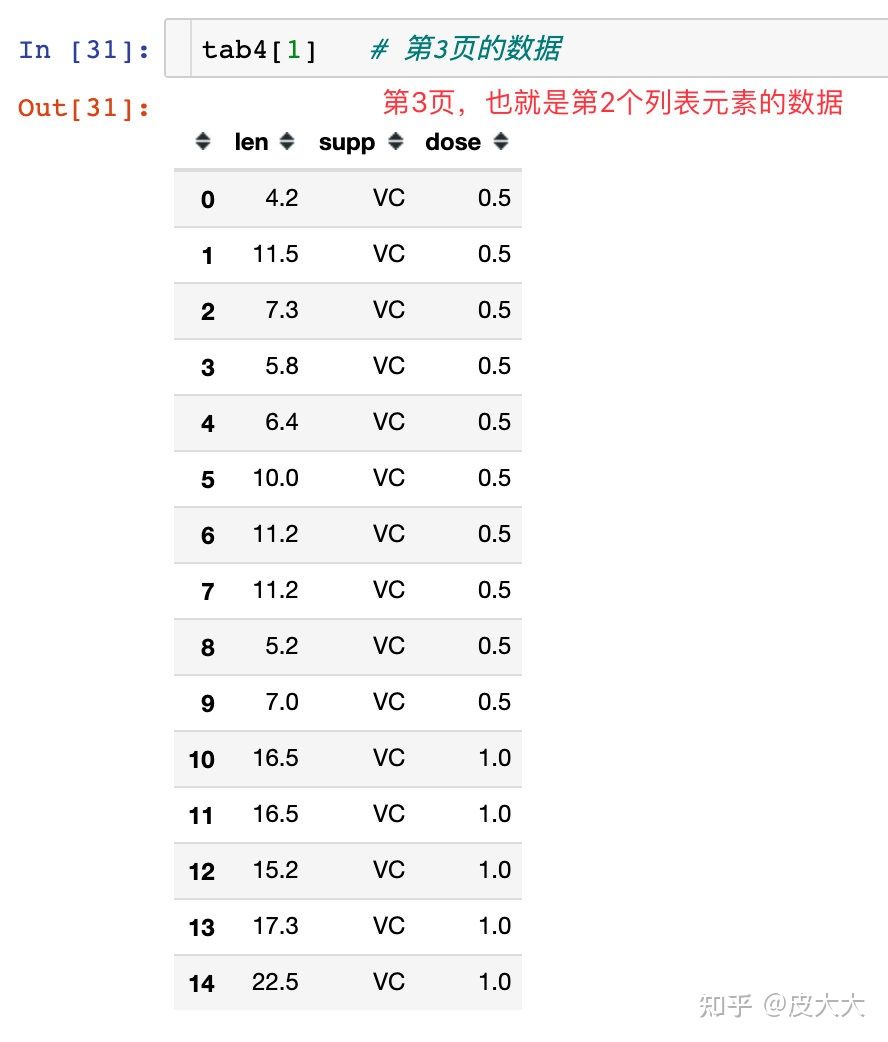
读取指定位置(面积)的数据
通过area参数来指定:

删除不需要的信息
删除在读取的表格中我们不需要的字段信息

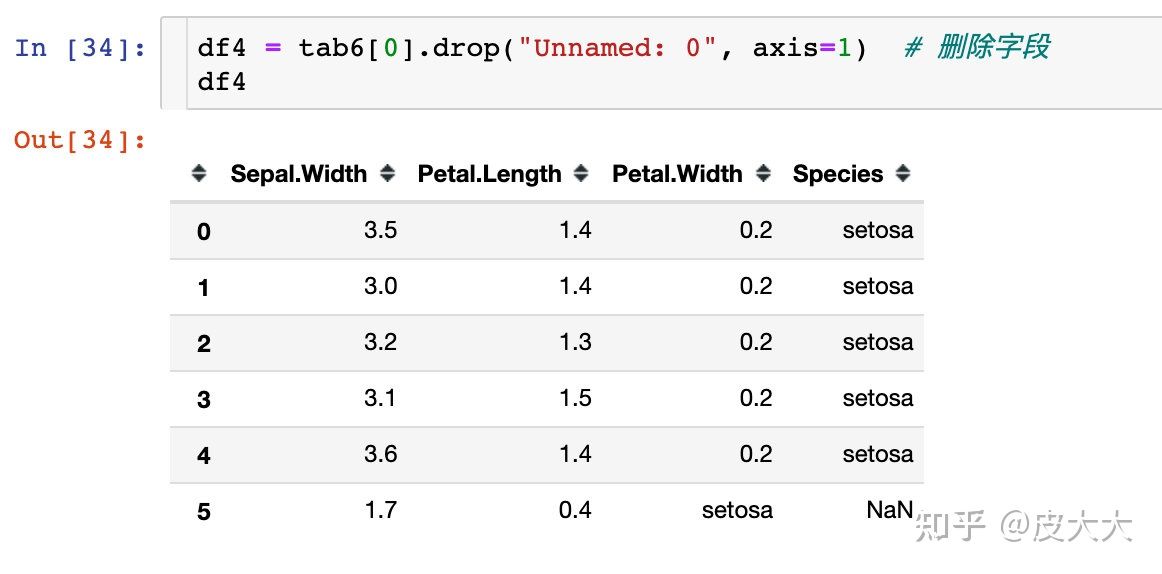
输出不同格式文件
可以将得到的数据输出成不同格式的文件,以json格式为例:
tabula.convert_into("data.pdf", # 源文件
"test4.json", # 输出文件名
output_format="json") # 文件格式以上是关于python tabula获取pdf的列表数据的主要内容,如果未能解决你的问题,请参考以下文章