零拷贝技术浅浅析kafka实现百万级吞吐量基础
Posted 负债程序猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了零拷贝技术浅浅析kafka实现百万级吞吐量基础相关的知识,希望对你有一定的参考价值。
家人们,这期的知识点可能会让你掉几根头发,为了尽可能让你理解,进入正题前我们先来看个栗子
给女朋友送礼物
如果,我是说如果啊,你有一个女朋友(没有的不要灰心,认真看完文章可以找博主领取)
情人节来了,你想在网上给女朋友买个礼物,但是吧,网上现成的礼物直接送过去显得没诚意,为了避免被发好人卡,你想先买回来DIY一下再送
受疫情影响,快递员不能进小区,你也不能出小区,快递员先把礼物放到小区快递点,你去快递点拿,拿回家DIY完后再放回快递点,快递员再从快递点拿到礼物送到女朋友家
简单画了个流程图
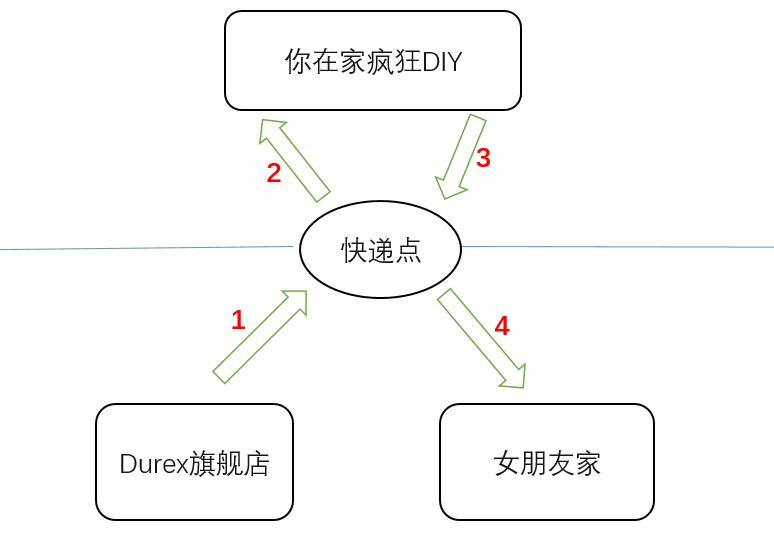
看看这个流程,有太多不合理的地方,人的时间和精力是宝贵的,应该用来打游戏,而不是送 / 拿快递
时间过了大概好几年,物流公司研发了送快递机器人,从此以后快递小哥不用再上门送件,于是流程变成了
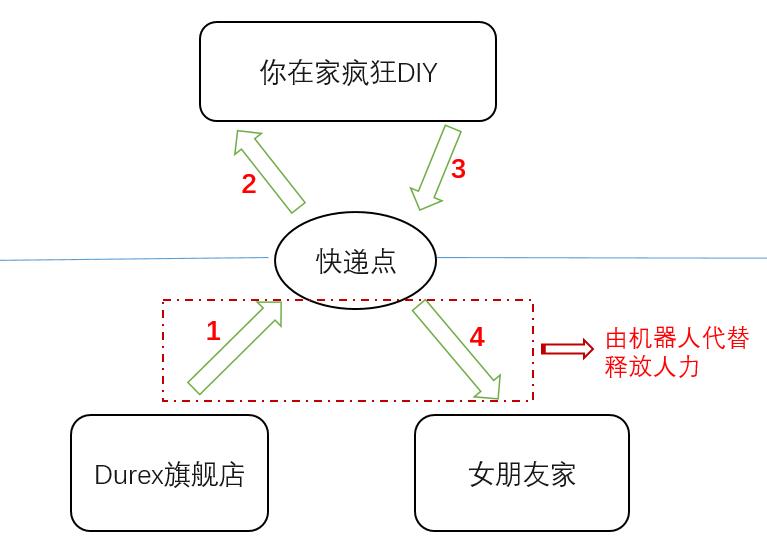
有了快递机器人,快递员解放了,但是你还需要去快递点拿礼物,DIY完了还得送回快递点,显然也不合理,有这时间我玩把中单亚索不香吗
于是你给礼物店老板提了个需求:能不能帮我DIY,然后直接寄到我女朋友家
老板觉得有道理,推出了新服务:需要DIY的用户,只需要在订单备注即可
于是流程变成了

你下单的时候,备注让店家帮你DIY,完事儿直接寄到女朋友家,女朋友收到快递感动到流了两斤眼泪
至此,你的两次出门也省了
回顾一下
从送礼物整个过程来看,最开始快递员需要跑路两次,你也需要跑路两次,到现在只需要机器人跑路两次
简单来说四次跑路变成了两次跑路,而这两次还都是机器人来完成,所以整个过程的人为跑路次数由4次变成了0次,这个过程我姑且称之 为零跑路
ok该来的始终还是来了,上面这个例子只是想引起你的兴趣,想要理解零拷贝,我们现在把术语代入
- 你家 ==> 应用程序缓存
- 快递点 ==> 操作系统内核缓存
- durex旗舰店 ==> 磁盘
- 女朋友家 ==> 目标磁盘或者socket
为什么要实现零拷贝
背景:文件操作属于危险操作,操作系统不可能直接把权限交给应用程序或者用户,只有内核才有权限
应用程序操作文件如复制、传输时,需要经历一下几个步骤:
从磁盘把文件复制到系统内核
从系统内核复制到应用程序
从应用程序复制到系统内核
从系统内核复制到磁盘、socket等消费端
简单画个流程图
说明:本文重点在于帮助大家理解零拷贝,关于操作系统内核方面的知识过于偏题,所以流程图画的很简单,如 “操作系统内核缓存” 其实还可细分为 “PageCache” 和 “Socket 缓冲区”,类似这些细节就不画了,而且画复杂了看着头疼
但请放心,虽然简单,但重点都没省略,丝毫不影响理解零拷贝
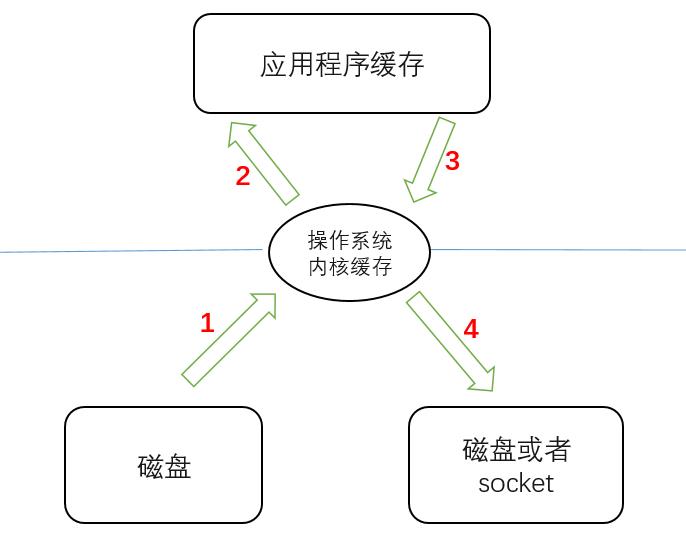
上面1、2、3、4几个步骤都是由cpu来完成,我们知道,cpu运算效率和磁盘不是一个量级
对服务器而言,cpu资源是很稀缺的,这四个复制操作一直占用cpu,显然会拉低整个系统性能
于是计算机界大佬们想了个办法,在主板上加了一块元件,叫 DMA(全称Direct Memory Access Controller,直接内存访问控制器),它是一块物理硬件,专门用于磁盘到操作系统内核缓存之间的数据复制
于是流程变成
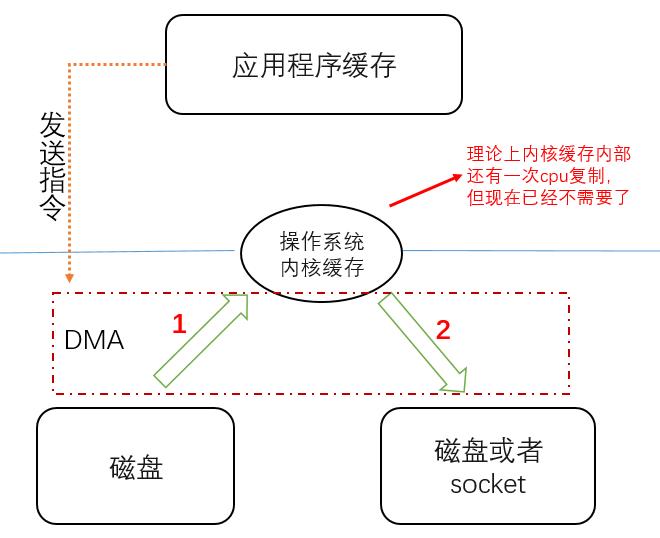
红字解释:目前的网卡几乎都支持 SG-DMA(The Scatter-Gather Direct Memory Access)技术(可以用ethtool -k eth0 | grep scatter-gather命令查看是否支持),关于这点了解即可,不需要深入研究,这已经是嵌入式开发领域的知识点了,咱没必要花太多时间在上面
如果到现在有点懵,没关系,你只需要记住,有了DMA,cpu不再亲自参与整个数据复制或传输过程,只需要给DMA发送指令,告知它应该把哪个文件复制或传输到哪里即可,等DMA完成数据操作后通知cpu
再来说说DMA吧,DMA的实现依赖于操作系统和硬件:
操作系统方面,os提供了sendfile()函数
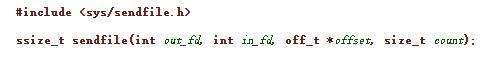
它接收四个参数:target端文件描述符、source端文件描述符、偏移量、数据长度
我们没有必要研究如何调用这个函数,因为Java已经帮我们做好了封装

你现在不需要管这个方法在哪个类中,我后面会写代码演示
kafka为什么能做到百万级吞吐量,靠的就是零拷贝模型,如果你仔细看过kafka源码,你会发现它最终调用了transferTo()方法
硬件方面,主板上增加了DMAC元件,其实不止主板,计算机发展到今天,几乎所有牵涉到io操作的地方都集成了DMAC
至此,我们可以做个小总结:所谓的零拷贝技术,其实可以理解成软件、硬件、语言的结合,目的在于减少cpu等待时间,提升数据传输效率
Talk is cheap,Show me the code
我们以复制文件为例,测试一下零拷贝模型带来的性能提升
新建一个测试文件
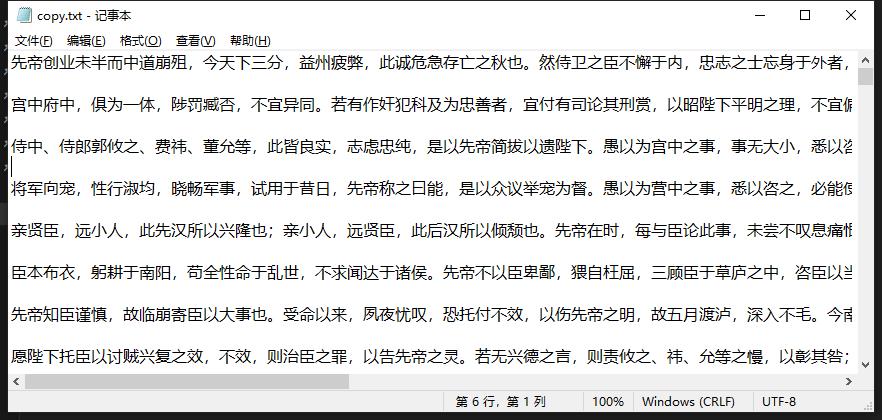
600MB
先来尝试下传统io复制(代码放在最后)
600MB花了800ms,这已经算是io中很快的了,如果用不带buffer的普通io,时间还得加3倍左右
再来看看零拷贝的nio
300ms左右,相对io提升了一倍多,看着不咋地,你想想高并发场景下,动不动上万次类似操作,这节约下来的时间足以让甲方激动到拍打轮椅
代码:
public class ZeroCopyTest
public static void main(String[] args) throws IOException, InterruptedException
long start = System.currentTimeMillis();
File source = new File("D:/fileTest/copy.txt");
File target = new File("D:/fileTest/copy2.txt");
ioCopy(source, target);
// ioCopyWithBuffer(source, target);
// nioCopy(source, target);
System.out.println(System.currentTimeMillis() - start);
Thread.sleep(200);
target.delete();
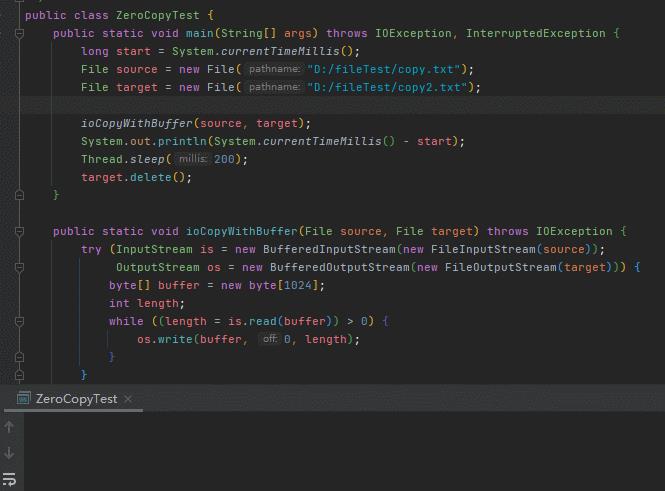
public static void ioCopy(File source, File target) throws IOException
try (InputStream is = new FileInputStream(source);
OutputStream os = new FileOutputStream(target))
byte[] buffer = new byte[1024];
int length;
while ((length = is.read(buffer)) > 0)
os.write(buffer, 0, length);
public static void ioCopyWithBuffer(File source, File target) throws IOException
try (InputStream is = new BufferedInputStream(new FileInputStream(source));
OutputStream os = new BufferedOutputStream(new FileOutputStream(target)))
byte[] buffer = new byte[1024];
int length;
while ((length = is.read(buffer)) > 0)
os.write(buffer, 0, length);
public static void nioCopy(File source, File target) throws IOException
try (FileChannel sourceChannel = new FileInputStream(source).getChannel();
FileChannel targetChannel = new FileOutputStream(target).getChannel())
for (long count = sourceChannel.size(); count > 0; )
long transferred = sourceChannel.transferTo(sourceChannel.position(), count, targetChannel);
sourceChannel.position(sourceChannel.position() + transferred);
count -= transferred;
两根头发又无了,嘤嘤嘤~
前面说的领女朋友,其实,是骗你们的

ok我话说完
以上是关于零拷贝技术浅浅析kafka实现百万级吞吐量基础的主要内容,如果未能解决你的问题,请参考以下文章