数据湖之Hudi:Hudi与Spark和HDFS的集成安装使用
Posted 电光闪烁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据湖之Hudi:Hudi与Spark和HDFS的集成安装使用相关的知识,希望对你有一定的参考价值。
目录
主要介绍的Apache原生的Hudi、HDFS、Spark等的集成使用
0. 相关文章链接
1. 编译Hudi源码
虽然对hudi的下载编译在博主的另一篇博文里有介绍,但这里是系统的介绍Hudi的体验使用,所以在介绍一遍。
1.1. Maven安装
将maven的安装包上传到centos7服务器上,并解压,然后配置系统环境变量即可,详情可以查看博主的另一篇博文:Maven的下载安装和使用_yang_shibiao的博客-CSDN博客
配置好软连接,完成之后如下图所示:

修改maven中的本地仓库和镜像,如下所示:
<localRepository>/opt/module/apache-maven/repository</localRepository>
<mirrors>
<!-- mirror
| Specifies a repository mirror site to use instead of a given repository. The repository that
| this mirror serves has an ID that matches the mirrorOf element of this mirror. IDs are used
| for inheritance and direct lookup purposes, and must be unique across the set of mirrors.
|
<mirror>
<id>mirrorId</id>
<mirrorOf>repositoryId</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://my.repository.com/repo/path</url>
</mirror>
-->
<mirror>
<id>aliyunCentralMaven</id>
<name>aliyun central maven</name>
<url>https://maven.aliyun.com/repository/central/</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>centralMaven</id>
<name>central maven</name>
<url>http://mvnrepository.com/</url>
<mirrorOf>central</mirrorOf>
</mirror>
</mirrors>修改环境变量:
export MAVEN_HOME=/opt/module/apache-maven
export PATH=$MAVEN_HOME/bin:$PATHsource环境变量,然后查看maven版本如下所示:

1.2. 下载并编译hudi
- 到Apache 软件归档目录下载Hudi 0.8源码包:http://archive.apache.org/dist/hudi/0.9.0/
- 编译Hudi源码步骤

- 上传源码包到 /opt/module 目录,并解压配置软连接:

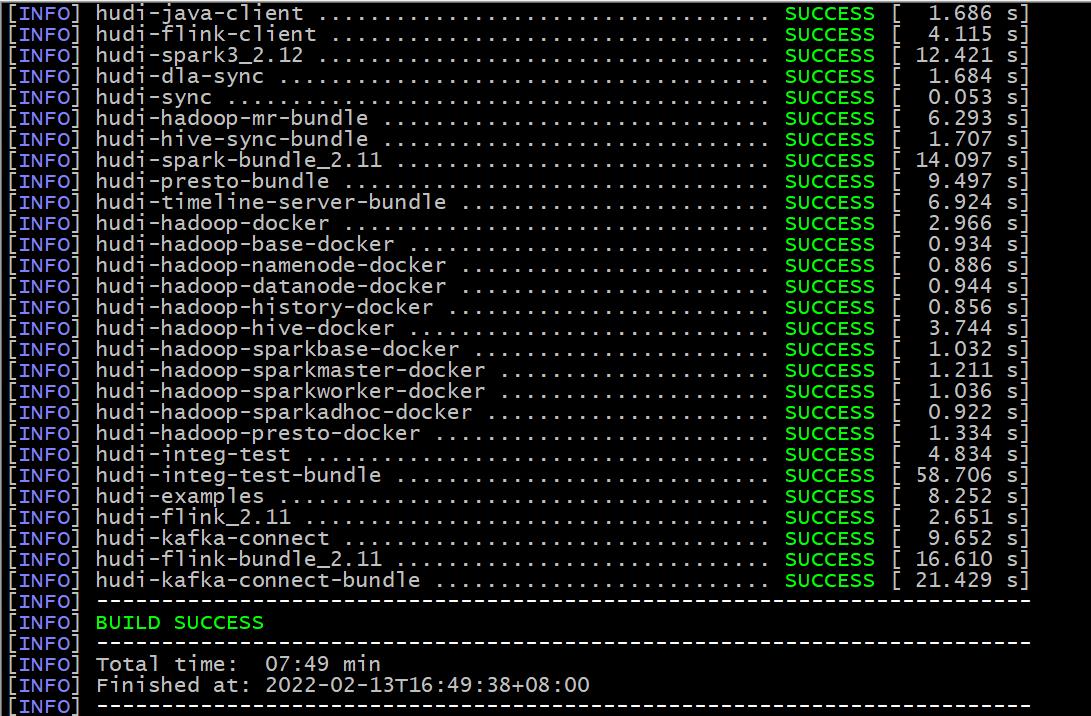
- 执行 mvn clean install -DskipTests -Dscala-2.12 -Dspark3 命令进行编译,成功后如下图所示:
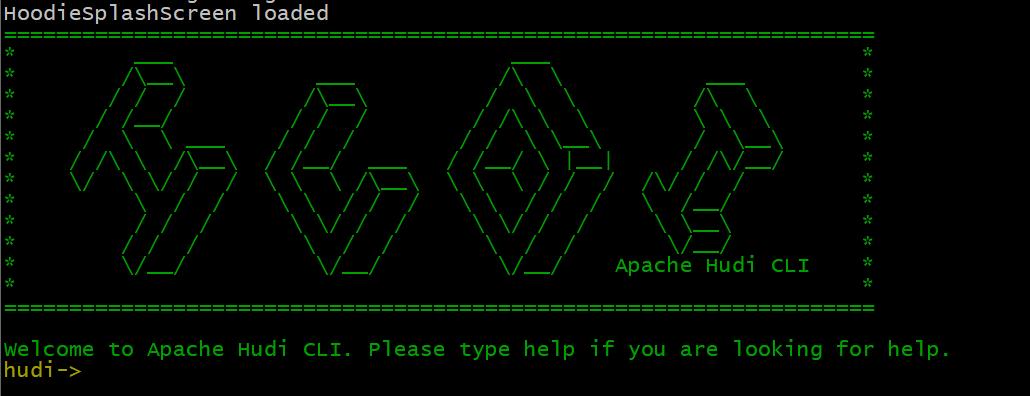
- 编译完成以后,进入$HUDI_HOME/hudi-cli目录,运行hudi-cli脚本,如果可以运行,说明编译成功,如下图所示:
2. 安装HDFS
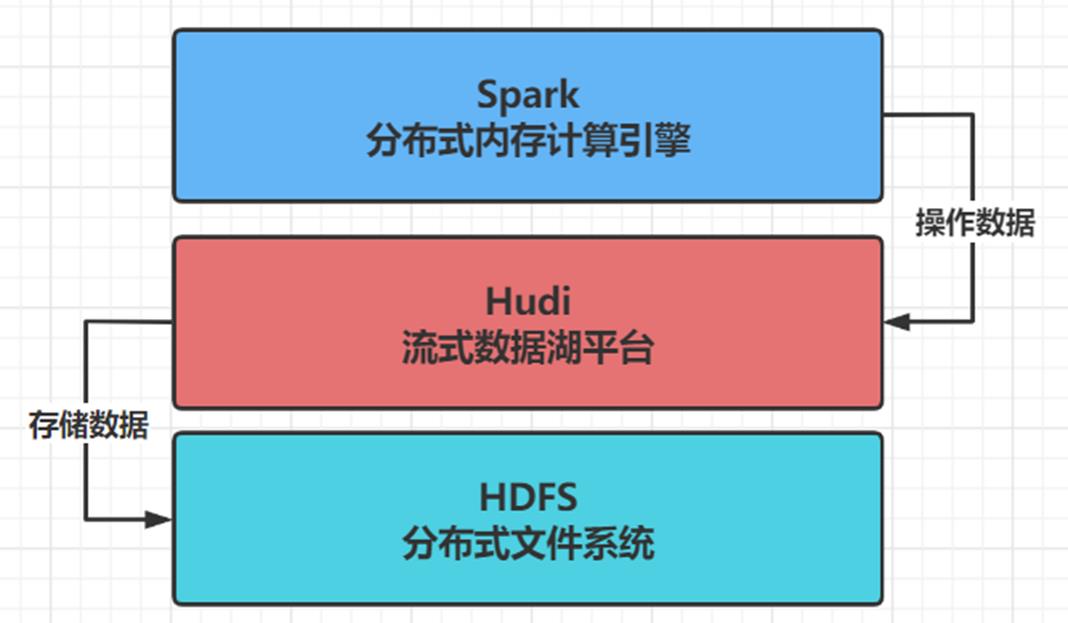
- step1:Hudi 流式数据湖平台,协助管理数据,借助HDFS文件系统存储数据,使用Spark操作数据
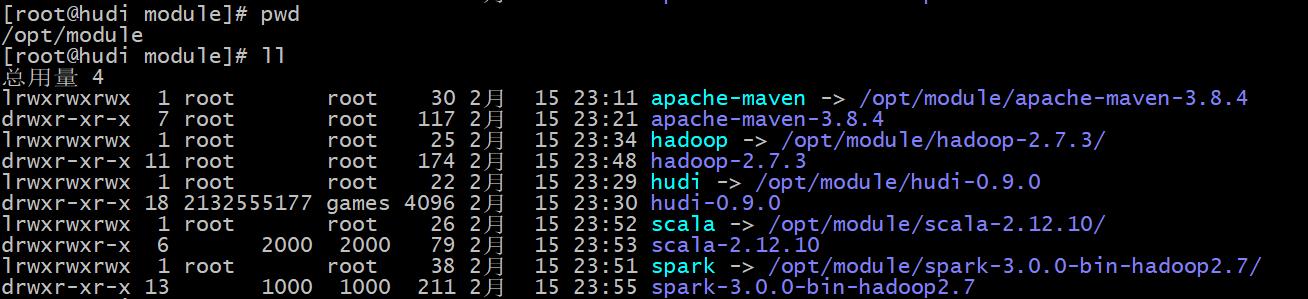
- step2:下载 hadoop-2.7.3 安装包,上传服务器,解压,并配置软连接,如下图所示:
- step3:配置环境变量(在Hadoop中,bin和sbin目录下的脚本、etc/hadoop下的配置文件,有很多配置项都会使用到HADOOP_*这些环境变量。如果仅仅是配置了HADOOP_HOME,这些脚本会从HADOOP_HOME下通过追加相应的目录结构来确定COMMON、HDFS和YARN的类库路径。)

# 在 /etc/profile 文件下添加如下配置
export HADOOP_HOME=/opt/module/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin- step4:配置hadoop-env.sh
# 在该 HADOOP_HOME/etc/hadoop/hadoop-evn.sh 下修改添加如下配置
export JAVA_HOME=/usr/java/jdk1.8.0_181
export HADOOP_HOME=/opt/module/hadoop- step5:配置core-site.xml,配置Hadoop Common模块公共属性,修改HADOOP_HOME/etc/hadoop/core-site.xml文件为如下所示,并根据配置创建对应的临时数据目录,创建命令:mkdir -p /opt/module/hadoop/datas/tmp
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hudi:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/datas/tmp</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
- step6:配置 HADOOP_HOME/etc/hadoop/hdfs-site.xml文件,配置HDFS分布式文件系统相关属性,并创建对应的数据目录,命令:mkdir -p /opt/module/hadoop/datas/dfs/nn , mkdir -p /opt/module/hadoop/datas/dfs/dn
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop/datas/dfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/module/hadoop/datas/dfs/dn</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>750</value>
</property>
</configuration>
- step7:配置HADOOP_HOME/etc/hadoop/slaves,在该配置中添加上配置的域名即可
hudi- step8:格式化HDFS,在第一次启动HDFS之前,需要先格式HDFS文件系统,执行如下命令即可
hdfs namenode -format- step9:配置启动停止脚本,用来启动或停止HDFS集群
vim hdfs-start.sh
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
================================================
hdfs-stop.sh
hadoop-daemon.sh stop datanode
hadoop-daemon.sh stop namenode- step10:查看HDFS的web ui(http://hudi:50070/explorer.html#),如下图所示:

- step11:HDFS 分布式文件系统安装,存储数据
3. 安装Spark
- step1:下载安装包并上传解压,如下图所示:
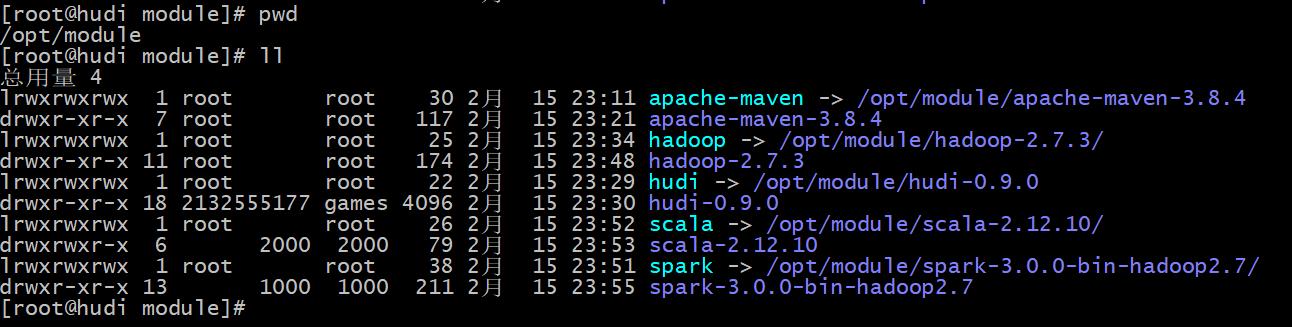
- step2:各个目录含义:

- step3:安装scala,下载上传并解压scala包,如第一步图所示,并配置scala的环境变量,验证如下图所示:
export SCALA_HOME=/opt/module/scala
export PATH=$PATH:$SCALA_HOME/bin
- step4:修改配置文件,$SPARK_HOME/conf/spark-env.sh,修改增加如下内容:
JAVA_HOME=/usr/java/jdk1.8.0_181
SCALA_HOME=/opt/module/scala
HADOOP_CONF_DIR=/opt/module/hadoop/etc/hadoop- step5:启动spark-shell,启动命令(spark-shell --master local[4]),如下图所示:

- step6:在web页面(http://hudi:4040/environment/)查看spark:

- step7:在spark-shell中执行spark的算子,验证是否能成功运行:
# 上传文件到HDFS集群
hdfs dfs -mkdir -p /datas/
hdfs dfs -put /opt/module/spark/README.md /datas
# 在spark-shell中读取文件
val datasRDD = sc.textFile("/datas/README.md")
# 查看该文件的条目数
datasRDD.count
# 获取第一条数据
datasRDD.first
4. 在spark-shell中运行hudi程序
首先使用spark-shell命令行,以本地模式(LocalMode:--master local[2])方式运行,模拟产生Trip乘车交易数据,将其保存至Hudi表,并且从Hudi表加载数据查询分析,其中Hudi表数据最后存储在HDFS分布式文件系统上。

在服务器中执行如下spark-shell命令,会在启动spark程序时,导入hudi包,请注意,执行此命令时需要联网,从远程仓库中下载对应的jar包:
spark-shell \\
--master local[4] \\
--packages org.apache.spark:spark-avro_2.12:3.0.1,org.apache.hudi:hudi-spark3-bundle_2.12:0.9.0 \\
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
启动后如下所示:


会将jar包下载到root命令下,如下图所示:

如果服务器不能联网,可以先将jar包上传到服务器,然后在通过spark-shell启动时,通过--jars命令指定jar包,如下所示:
spark-shell \\
--master local[4] \\
--jars /opt/module/Hudi/packaging/hudi-spark-bundle/target/hudi-spark3-bundle_2.12-0.8.0.jar \\
--packages org.apache.spark:spark-avro_2.12:3.0.1,org.apache.hudi:hudi-spark3-bundle_2.12:0.9.0 \\
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'在spark命令行中导入Hudi的相关包和定义变量(表的名称和数据存储路径):
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_trips_cow"
val basePath = "hdfs://hudi:8020/datas/hudi-warehouse/hudi_trips_cow"
val dataGen = new DataGenerator
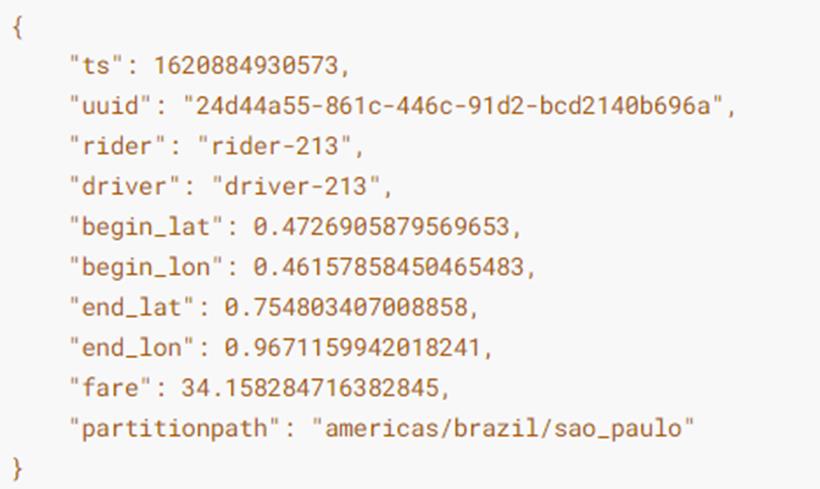
构建DataGenerator对象,用于模拟生成Trip乘车数据(10条json数据):
val inserts = convertToStringList(dataGen.generateInserts(10))
将模拟数据List转换为DataFrame数据集:
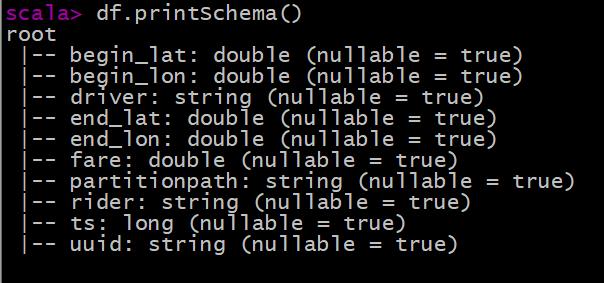
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
查看转换后DataFrame数据集的Schema信息:
选择相关字段,查看模拟样本数据:
df.select("rider", "begin_lat", "begin_lon", "driver", "fare", "uuid", "ts").show(10, truncate=false)
将模拟产生Trip数据,保存到Hudi表中,由于Hudi诞生时基于Spark框架,所以SparkSQL支持Hudi数据源,直接通过format指定数据源Source,设置相关属性保存数据即可。
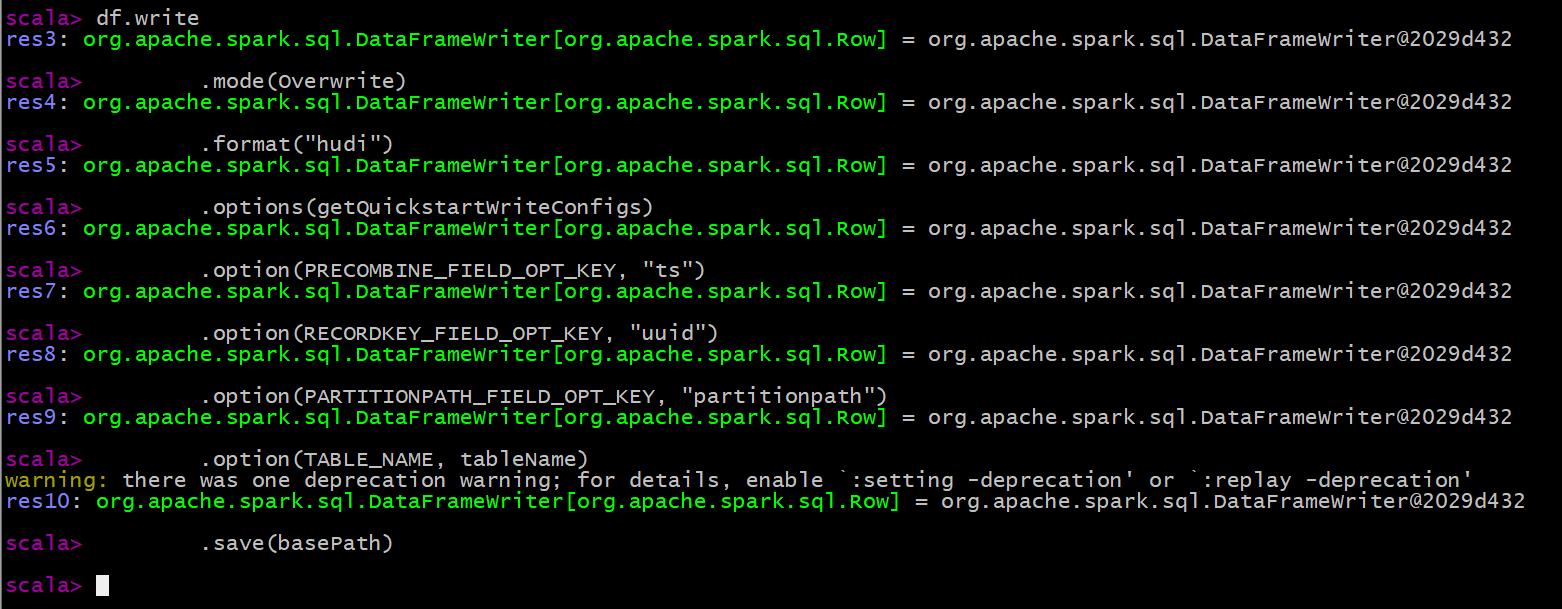
df.write
.mode(Overwrite)
.format("hudi")
.options(getQuickstartWriteConfigs)
.option(PRECOMBINE_FIELD_OPT_KEY, "ts")
.option(RECORDKEY_FIELD_OPT_KEY, "uuid")
.option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath")
.option(TABLE_NAME, tableName)
.save(basePath)
数据保存成功以后,查看HDFS文件系统目录:/datas/hudi-warehouse/hudi_trips_cow,结构如下,并且可以发现Hudi表数据存储在HDFS上,以PARQUET列式方式存储的:


参数:getQuickstartWriteConfigs,设置写入/更新数据至Hudi时,Shuffle时分区数目:

参数:PRECOMBINE_FIELD_OPT_KEY,数据合并时,依据主键字段

参数:RECORDKEY_FIELD_OPT_KEY,每条记录的唯一id,支持多个字段

参数:PARTITIONPATH_FIELD_OPT_KEY,用于存放数据的分区字段

从Hudi表中读取数据,同样采用SparkSQL外部数据源加载数据方式,指定format数据源和相关参数options:
val tripsSnapshotDF = spark.read.format("hudi").load(basePath + "/*/*/*/*")
其中指定Hudi表数据存储路径即可,采用正则Regex匹配方式,由于保存Hudi表属于分区表,并且为三级分区(相当于Hive中表指定三个分区字段),使用表达式:/*/*/*/* 加载所有数据:
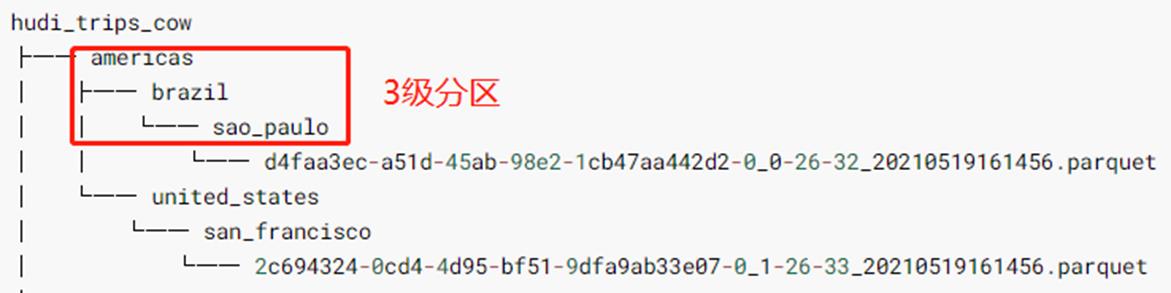
打印获取Hudi表数据的Schema信息(回发现比原先保存到Hudi表中数据多5个字段,这些字段属于Hudi管理数据时使用的相关字段):

将获取Hudi表数据DataFrame注册为临时视图,采用SQL方式依据业务查询分析数据:
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")查询业务一:乘车费用 大于 20 信息数据
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()
查询业务二:选取字段查询数据
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()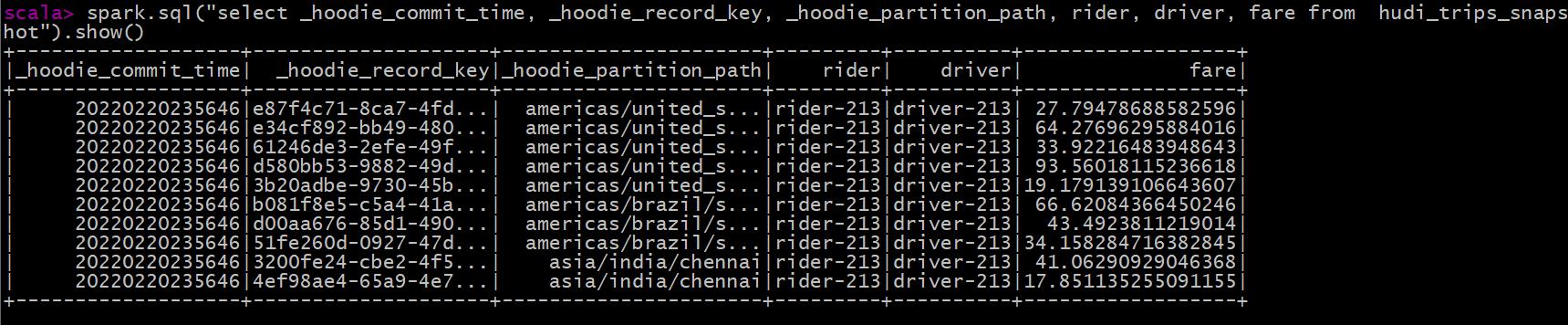
注:Hudi系列博文为通过对Hudi官网学习记录所写,其中有加入个人理解,如有不足,请各位读者谅解☺☺☺
注:其他相关文章链接由此进(包括Hudi在内的各大数据相关博文) -> 大数据基础知识点 文章汇总
以上是关于数据湖之Hudi:Hudi与Spark和HDFS的集成安装使用的主要内容,如果未能解决你的问题,请参考以下文章