万字详解Linux系列进程概念
Posted 山舟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了万字详解Linux系列进程概念相关的知识,希望对你有一定的参考价值。
文章目录
一、冯·诺依曼体系结构
1.冯·诺依曼体系结构
常见的计算机(如笔记本)、不常见的计算机(如服务器),大都遵守冯·诺依曼体系结构。那么什么是冯·诺依曼体系结构呢?
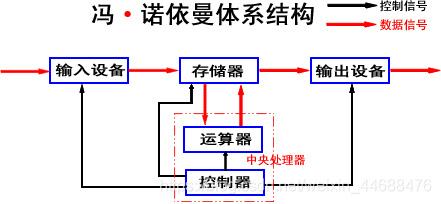
以C语言为例,当遇到加减乘除模运算时,运算器进行运算,当遇到逻辑判断、循环等时,控制器进行控制,这二者合起来称为中央处理器(CPU),它的运算速度非常快。
而输入输出设备是用户进行操作的,速度非常慢。
如果仅靠这些硬件组成一台设备,根据木桶原理,整个设备的运行速度都因为输出输入设备速度慢而变慢,所以这时存储器(也就是内存)出现了,可以很好地解决这一问题。
内存的处理速度居于输入输出设备和CPU之间,而且具有数据存储能力,可以预装一定量的数据。这样在CPU处理数据A时,内存可以把下一部分数据B甚至更多先从输入设备读入,当数据A处理结束后,直接从内存中读取B进行处理,这样就提高了整个设备的速度、提高效率。输出同理。
这样整个包含输入输出设备、存储器(内存)、CPU的结构成为冯·诺依曼体系结构。
注意:
1.这里的存储器指的是内存。
2.不考虑缓存情况,这里的CPU能且只能对内存进行读写,不能访问外设(即输入或输出设备)。
3.外设(输入或输出设备)要输入或者输出数据,也只能写入内存或者从内存中读取。
也就是说,所有设备都只能直接和内存互相访问。
下面是常见的输入输出设备:
常见的输入设备:网卡、硬盘、键盘、话筒、摄像头。
常见的输出设备:网卡、硬盘、显示器、音响。
2.从冯·诺依曼体系结构理解软件行为
这里举例子说明:
在QQ上输入一条消息并向好友发送。

如果是发送文件而不是消息呢?
发送文件与上面的过程大部分相同,但是在我发送文件时,由于文件是存储在硬盘上的,首先要拷贝一份并放入内存,然后通过网卡等等一系列上述过程发送到好友的网卡中,经过CPU处理后再放在好友设备的硬盘下完成发送。
二者区别仅仅是发送消息时输入设备是键盘,而发送文件时输入设备是硬盘。
二、操作系统(OS)
操作系统是一个进行软硬件资源管理的软件。
设计操作系统目的:
(1)与硬件交互,管理所有软硬件资源。
(2)为用户(应用程序)提供良好的执行环境。
下面是计算机的体系结构,可以看出操作系统在其中的位置和作用。

三、进程
1.概念
一个程序运行起来(被加载到内存),那么它就从一个程序变成了一个进程。
下面是正在运行的部分进程。

2.进程控制块PCB(process control block)
下面是一个可执行程序被运行的过程。
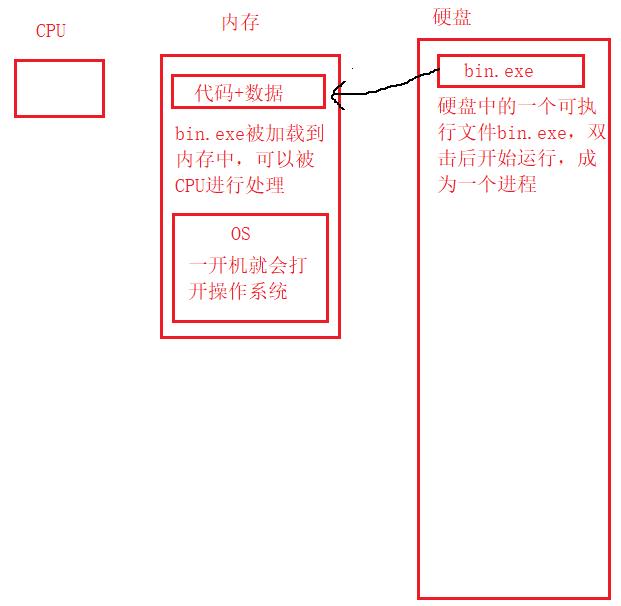
但是一般同一时刻有许许多多的进程,操作系统如何对他们进行管理呢?这里就要提到进程控制块PCB,每个进程被加载到内存中时,操作系统都会对应产生PCB来描述这个进程,PCB的本质是一个结构体,里面包含着一个进程的相关信息。
操作系统将一个个PCB连接成双链表来管理,结构如下。
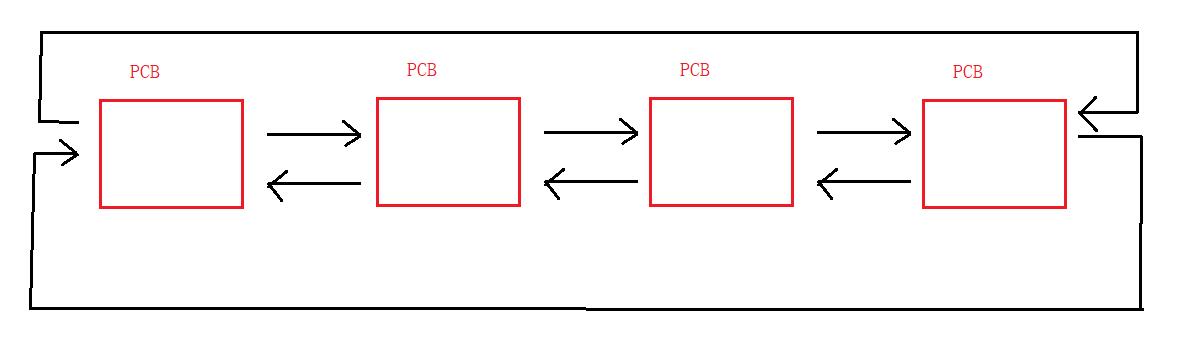
创建一个进程就是将新的进程产生对应的PCB并加入双链表中,关闭一个进程就是将该进程的PCB从双链表中删除。这样,对进程的管理变成了对PCB形成的双链表的增删查改。
四、task_struct
在Linux中描述进程的结构体叫做task_struct,也就是说task_struct是PCB的一种,PCB包括task_struct。
task_struct是Linux内核的一种数据结构,它会被装载到内存里且包含着进程的许多信息,所有运行在系统中的进程都以task_struct链表的形式存储。
下面介绍task_struct包含的一些较为重要的信息。
1.标示符
标示符是描述本进程的唯一标示符,用来区别其他进程。
在myproc.c中编写代码如下:
#include <stdio.h>
#include <unistd.h>
int main()
while(1)
printf("I am a process ... \\n");
sleep(1);
return 0;
make产生可执行文件并用./运行后,结果如下。

每隔一秒打印一行,表示该进程跑起来了。
那么如何找到这个进程呢?这里就要用到ps命令显示所有进程并用grep过滤出来想要看到的进程。
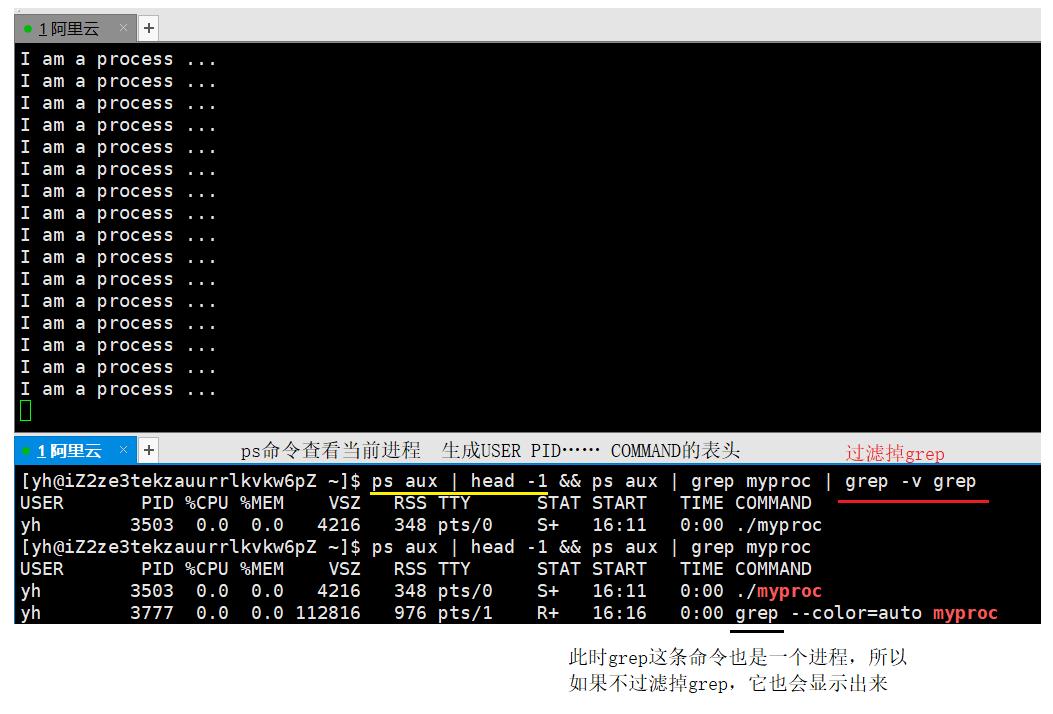
可以看到上面的对话框程序正在运行,下面的对话框用ps命令显示出了进程的信息。
myproc这一进程的PID是3503,这是当前时刻唯一确定的,不会有两个进程的PID相同。
如果要使某一进程停止,只需用kill命令。

可以看到下面的对话框通过kill命令使对应PID的进程停止。
在命令行中我们可以通过grep找到这一进程,那么在代码中如何获得PID呢?这里就需要getpid函数,这里顺带介绍getppid函数。

下面在代码中使用这两个函数:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
while(1)
printf("I am a process ..., pid : %d ppid %d\\n", getpid(), getppid());
sleep(1);
return 0;
运行后结果如下:

可以看到在代码中获取到的pid、ppid和命令行获取到的pid、ppid是相同的。
这里多次重新跑该进程。

发现pid一直在变,可以理解,但是ppid一直没有变化,这是为什么呢?下面看一下ppid为2698(这个ppid不一定必须是2698,只需要不变即可)的进程到底是什么。
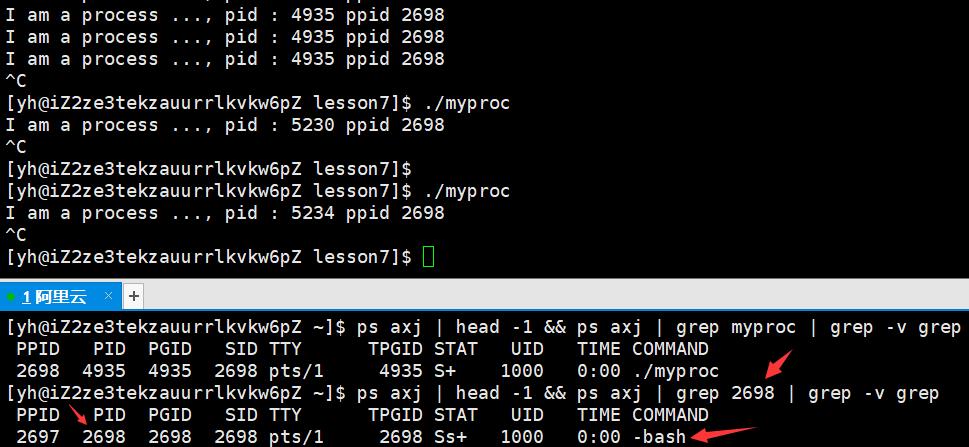
-bash可以让用户从命令行与操作系统交互,myproc是它的一个子进程。
如果在这里kill掉bash,那么上面的对话框就掉线了,无法与系统交互。
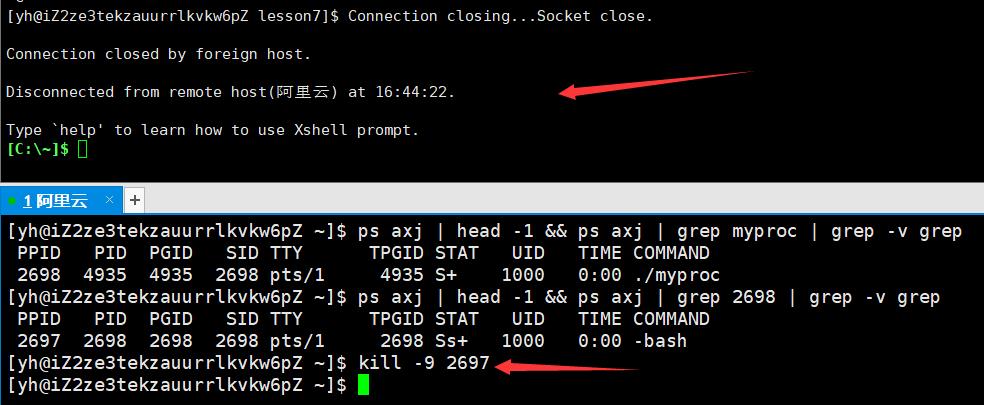
2.状态
状态可以显示出任务状态,退出代码,退出信号等。
前图中STAT就表示进程的状态。
(1)前台进程和后台进程
运行如下代码:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
while(1);
return 0;
此时myproc的状态为R+,前面几个进程的运行状态后面也都有’+'号,这说明该进程是前台进程,下图中运行后无法在命令行进行其他操作。

./运行时,在后面加上’&'即可使进程后台运行。后台进程可以有多个且不影响命令行的输入。
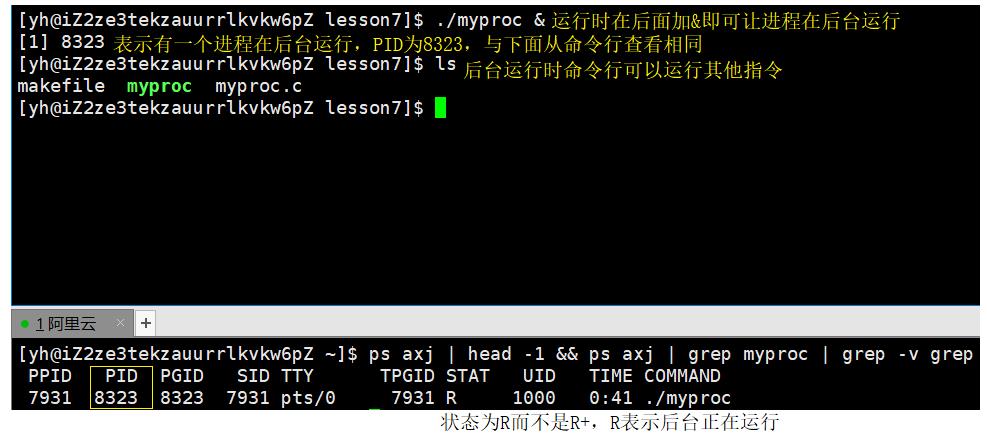
后台运行的进程不能通过Ctrl+c结束,只能通过kill命令来结束进程。
(2)fork
①定义
下面是man中关于fork的头文件、调用和返回值。


②用fork创建子进程
下面的代码与前面的只差一行fork(),但运行结果的差距就非常大了。
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
fork();
while(1)
printf("I am a process pid: %d ppid: %d\\n", getpid(), getppid());
sleep(1);
return 0;
运行结果如下:

由上:
1.fork会创建子进程,fork前的代码仅属于当前进程,fork后的代码子进程与当前进程都会执行。
2.当myproc(上图中我的可执行程序是这个名称)被执行时,硬盘中的可执行程序进入内存变成一个进程,同时内存中还多了属于它的代码和数据以及对应的task_struct,当执行到fork时,在内存上开辟子进程的task_struct,当前进程与子进程代码共享。
3.fork后产生了一个子进程,当前进程与子进程谁先被调度是不确定的,由操作系统的调度算法来决定。
③fork的返回值
fork函数有两个返回值,给当前进程返回子进程的pid,给子进程返回0。
运行如下代码:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
printf("I am a process ...\\n");
pid_t id = fork();
printf("pid : %d\\n", id);
sleep(1);
return 0;
代码中只打印了一次id,但多次运行发现始终打印两次id。

但这样父子进程都跑一份代码似乎不太有必要,所以要让父子进程实现不同的功能可以如下来实现。
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
printf("I am a process ...\\n");
pid_t id = fork();
printf("pid : %d\\n", id);
if(id == 0)//child
while(1)
printf("I am a child ... pid : %d\\n", id);
sleep(1);
else if(id > 0)//parent
while(1)
printf("I am a process ... pid : %d\\n", id);
sleep(2);
else//id < 0
printf("fork fail\\n");
sleep(1);
return 0;
结果如下,可以看出,当前进程和子进程“同时”在进行,可以做不同的事。

在不使用fork之前,if和else if的判断永远只能进行一个,因为只有一个执行流;但是通过fork的返回值便可以产生两个执行流根据判断条件做不同的事。
(3)进程状态
Linux内核源代码:一个进程可以有几个状态(在Linux内核里,进程有时候也叫做任务)。下面的状态在kernel源代码里定义(这些状态是Linux下的状态,在其它操作系统中可能不同)。
static const char * const task_state_array[] =
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */
"t (tracing stop)", /* 8 */
"X (dead)", /* 16 */
"Z (zombie)", /* 32 */
;
①R (running)状态
R状态在上面前台进程和后台进程中提到,这里不再举例。
进程是R状态不是代表正在运行,而是代表该进程可以被调度。
这里应该会注意到,由于只有R进程可以被调度,如果每次都在所有进程链接成的双链表中找R进程,那么效率会很低;所以Linux下所有R状态的进程还同时存在于一个全部都是R状态的链表中,调度时直接在该链表中遍历即可。
②S (sleeping)状态
S状态意味着进程在等待事件完成,该进程随时可以被唤起或通过kill命令杀掉(这里把该状态成为“浅度睡眠”,与D状态相对)。
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
printf("process is running\\n");
sleep(100);
printf("process over\\n");
return 0;

③D (disk sleep)状态
在D状态下进程无法被杀掉,即使是操作系统也不可以(把该状态成为“深度睡眠”,与S状态相对),在这个状态的进程通常会等待IO的结束。
该状态很难模拟,下面举个例子帮助理解:
A进程在运行时需要从磁盘输入数据,在磁盘输入这一过程中由于内存几乎已满(只是举一种可能的情况),操作系统必须杀掉闲置的进程,而在这种情况下A进程被看做闲置的进程被杀死,之后从磁盘输入的数据便不知道该去哪里,A进程也没有完成自己的任务。
上述情况是不允许发生的,所以在上述情况下,Linux将A进程设置为D状态,在A进程IO时不要杀死该进程,保证该进程正常运行。
④T (stopped)状态
可以通过kill命令发送 SIGSTOP 信号给进程来停止进程(T状态)。这个被暂停的进程可以通过发送 SIGCONT 信号让进程继续运行。
运行如下代码:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
while(1)
printf("running ...\\n");
sleep(1);
return 0;
运行后对进程的pid发送信号即可使其变为T状态。如果需要再度使其运行,只需要发送SIGCONT信号即可(下图未演示)。
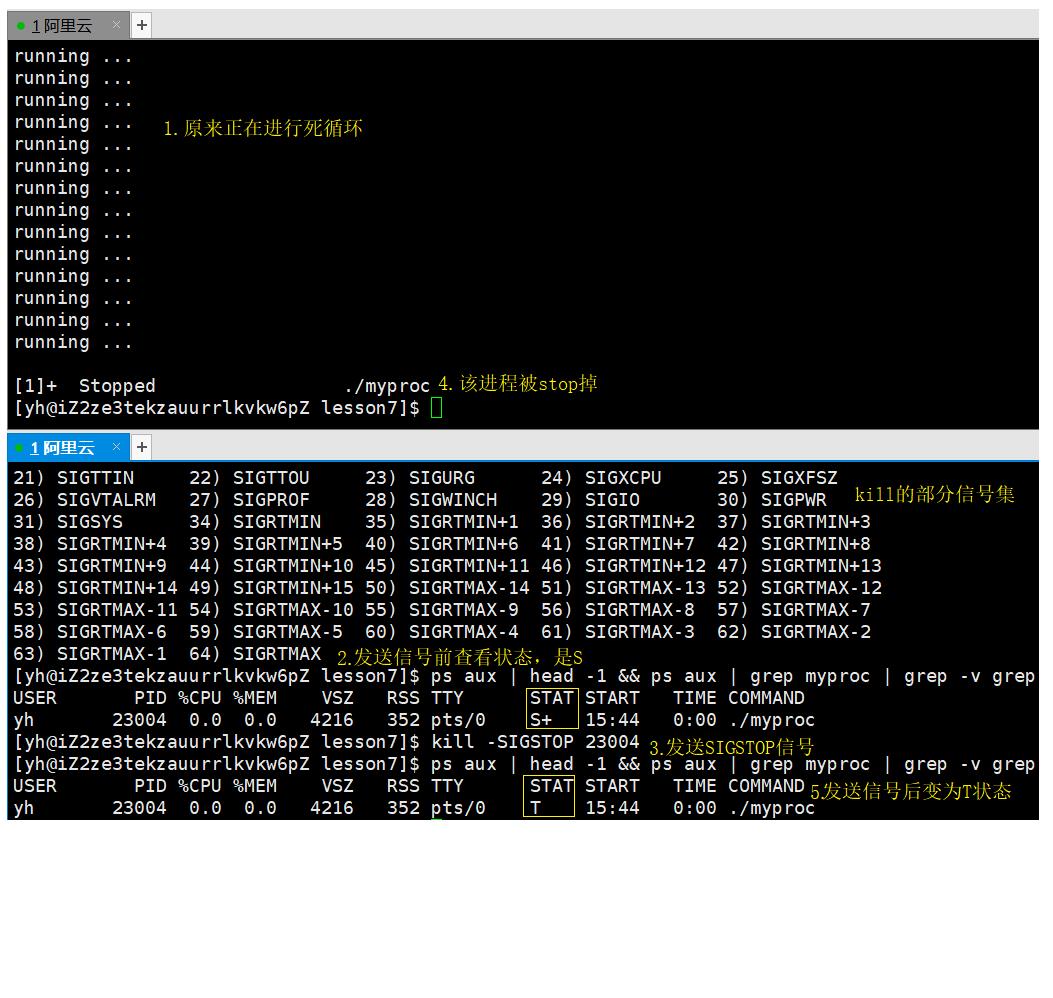
至于为什么一开始是S状态,这是因为每次打印后都会sleep一秒钟,在这一秒钟里CPU已经发送了许多次running到缓冲区,打印的速度远比CPU发送的速度慢,所以CPU是S状态。
⑤Z(zombie)状态
进程退出后,在系统层面来看该进程曾经申请的资源不会被立即释放,而是暂存一段时间,供父进程(或操作系统)进行读取,这个状态就是Z状态。
那么为什么要有这个状态呢?进程被创建的目的就是完成某种任务,那么任务完成时,一般情况下创建方应该了解进程运行的结果如何,这就是Z状态存在的原因。
下面模拟一个Z状态的进程:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main()
pid_t id = fork();
if (id == 0)
//child
int count = 3;
while (count--)
printf("I am a child pid:%d ppid:%d\\n", getpid(), getppid());
sleep(1);
printf("child quit\\n");
exit(1);
else if (id > 0)
//parent
while (1)
printf("I am a parent pid:%d ppid:%d\\n", getpid(), getppid());
sleep(1);
else
;//do nothing
return 0;
通过一个监测脚本观测进程的状态,可以看到子进程结束后,父进程没有读取它的信息,它处于Z状态。

注意:
1.维护退出状态本身就是要用数据维护,也属于进程基本信息,所以保存在task_struct(PCB)中,换句话说,Z状态一直不退出,PCB一直都要维护。
2.如果一个父进程创建许多子进程却一直不回收,那么就会造成内存资源的浪费。
3.优先级
由于CPU资源有限而进程非常多,所以需要给每个进程一个优先级,而本质上是给PCB排队,按照优先级执行。
优先级高的进程有优先执行权利。配置进程优先权对多任务环境的linux很有用,可以改善系统性能。
(1)PRI、NI
可以用ps -l命令查看进程优先级,PRI和NI值一起影响进程的优先级。

默认PRI为80,NI为0。
PRI即进程的优先级,或者通俗点说就是程序被CPU执行的先后顺序,值越小进程的优先级越高。
NI即nice值,表示进程优先级的修正数值,范围是-20~19,但NI不是优先级。
PRI与NI之和即为总的优先级,所以在Linux下,调整优先级就是调整NI值。
(2)top命令修改NI值
详见下图:

注意每次修改NI值与上次修改的值无关,最后的优先级都是PRI+NI的值。
4.程序计数器
CPU中包含一个寄存器(eip),他存储这程序中最近正在执行指令的下一条指令的地址。
CPU的工作就是循环地进行取指令、分析指令、执行指令。每次CPU都从cip中取指令,然后处理该指令,完成后再从eip中取下一条指令。
所以,函数跳转、分支判断、循环等等都是通过修改eip完成的。
5.上下文数据
进程执行时处理器的寄存器中的数据。
上下文数据的功能类似于书签,书签可以记录当前读到的位置,下次再回来看时可以直接找到上次读到的位置。
上下文数据也一样。由于CPU内只有一套寄存器,一般只运行一个进程,而CPU进行计算时需要将内存数据移动到CPU内的寄存器中,这就形成了当前进程的上下文数据。当进程被切换时(进程可能因时间片到了或被抢占而在任何时间点切换)保留上下文数据,下次再执行该进程时根据上下文数据从上次执行到的位置继续执行,这样可以提高效率。
补充:基于时间片的轮转算法
每个运行的进程,都有自己的时间片,一旦时间片到了,无论该进程是否被执行完,操作系统都会停止运行它并接着运行其它进程。
这样可以防止操作系统进行一些有问题的进程(比如死循环)时不会一直处理该进程而导致其它进程无法运行,在用户看来就是卡死。
6.内存指针
包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
7.IO状态信息
包括IO请求,分配给进程的IO设备和被进程使用的文件列表。
8.记账信息
可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
比如a、b进程同时要被处理,但a进程已经被运行过10h,而b进程还未被运行过,那么一般会优先运行b进程。
感谢阅读,如有错误请批评指正
以上是关于万字详解Linux系列进程概念的主要内容,如果未能解决你的问题,请参考以下文章