PySpark与GraphFrames的安装与使用
Posted 小小明-代码实体
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PySpark与GraphFrames的安装与使用相关的知识,希望对你有一定的参考价值。
PySpark环境搭建
配置hadoop
spark访问本地文件并执行运算时,可能会遇到权限问题或是dll错误。这是因为spark需要使用到Hadoop的winutils和hadoop.dll,首先我们必须配置好Hadoop相关的环境。可以到github下载:https://github.com/4ttty/winutils
gitcode提供了镜像加速:https://gitcode.net/mirrors/4ttty/winutils
我选择了使用这个仓库提供的最高的Hadoop版本3.0.0将其解压到D:\\deploy\\hadoop-3.0.0目录下,然后配置环境变量:

我们还需要将对应的hadoop.dll复制到系统中,用命令表达就是:
copy D:\\deploy\\hadoop-3.0.0\\bin\\hadoop.dll C:\\Windows\\System32
不过这步需要拥有管理员权限才可以操作。
为了能够在任何地方使用winutils命令工具,将%HADOOP_HOME%\\bin目录加入环境变量中:
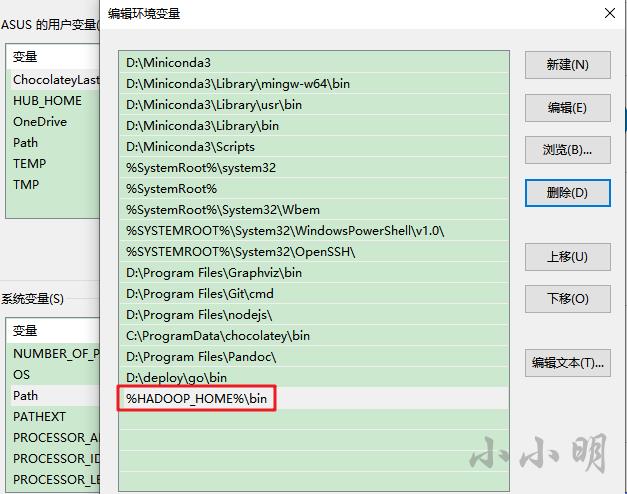
安装pyspark与Java
首先,我们安装spark当前(2022-2-17)的最新版本:
pip install pyspark==3.2.1
需要注意pyspark的版本决定了jdk的最高版本,例如假如安装2.4.5版本的pyspark就只能安装1.8版本的jdk,否则会报出java.lang.IllegalArgumentException: Unsupported class file major version 55的错误。
这是因为pyspark内置了Scala,而Scala是基于jvm的编程语言,Scala与jdk的版本存在兼容性问题,JDK与scala的版本兼容性表:
| JDK version | Minimum Scala versions | Recommended Scala versions |
|---|---|---|
| 17 | 2.13.6, 2.12.15 (forthcoming) | 2.13.6, 2.12.15 (forthcoming) |
| 16 | 2.13.5, 2.12.14 | 2.13.6, 2.12.14 |
| 13, 14, 15 | 2.13.2, 2.12.11 | 2.13.6, 2.12.14 |
| 12 | 2.13.1, 2.12.9 | 2.13.6, 2.12.14 |
| 11 | 2.13.0, 2.12.4, 2.11.12 | 2.13.6, 2.12.14, 2.11.12 |
| 8 | 2.13.0, 2.12.0, 2.11.0, 2.10.2 | 2.13.6, 2.12.14, 2.11.12, 2.10.7 |
| 6, 7 | 2.11.0, 2.10.0 | 2.11.12, 2.10.7 |
当前3.2.1版本的pyspark内置的Scala版本为2.12.15,意味着jdk17与其以下的所有版本都支持。
这里我依然选择安装jdk8的版本:

测试一下:
>java -version
java version "1.8.0_201"
Java(TM) SE Runtime Environment (build 1.8.0_201-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode)
jdk11的详细安装教程(jdk1.8在官网只有安装包,无zip绿化压缩包):
绿化版Java11的环境配置与Python调用Java
https://xxmdmst.blog.csdn.net/article/details/118366166
graphframes安装
pip安装当前最新的graphframes:
pip install graphframes==0.6
然后在官网下载graphframes的jar包。
下载地址:https://spark-packages.org/package/graphframes/graphframes
由于安装的pyspark版本是3.2,所以这里我选择了这个jar包:
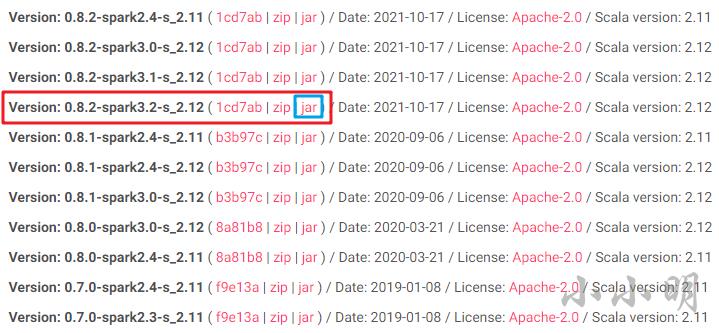
然后将该jar包放入pyspark安装目录的jars目录下:
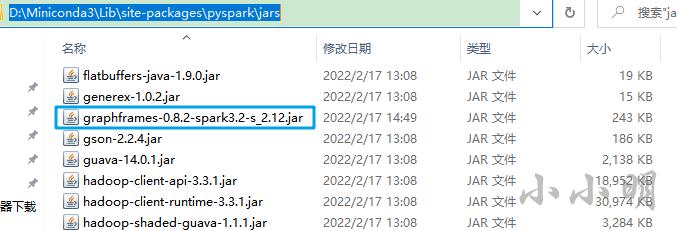
pyspark安装位置可以通过pip查看:
C:\\Users\\ASUS>pip show pyspark
Name: pyspark
Version: 3.2.1
Summary: Apache Spark Python API
Home-page: https://github.com/apache/spark/tree/master/python
Author: Spark Developers
Author-email: dev@spark.apache.org
License: http://www.apache.org/licenses/LICENSE-2.0
Location: d:\\miniconda3\\lib\\site-packages
Requires: py4j
Required-by:
使用方法
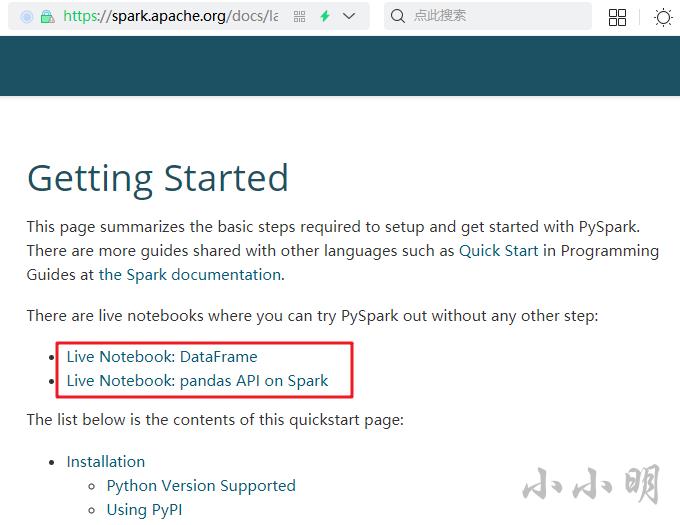
学习pyspark的最佳路径是官网:https://spark.apache.org/docs/latest/quick-start.html
在下面的网页,官方提供了在线jupyter:
https://spark.apache.org/docs/latest/api/python/getting_started/index.html
启动spark并读取数据
本地模式启动spark:
from pyspark.sql import SparkSession, Row
spark = SparkSession \\
.builder \\
.appName("Python Spark") \\
.master("local[*]") \\
.getOrCreate()
sc = spark.sparkContext
spark

SparkSession输出的内容中包含了spark的web页面,新标签页打开页面后大致效果如上。
点击Environment选项卡可以查看当前环境中的变量:
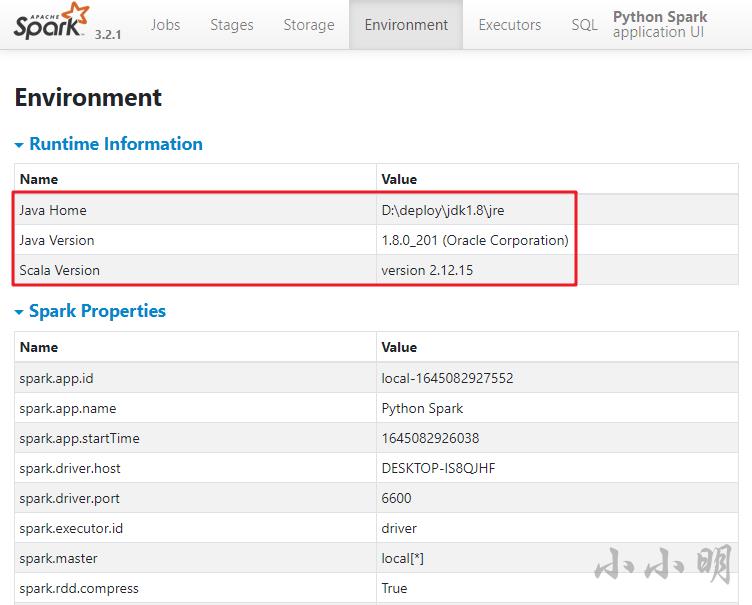
启动hive支持
找到pyspark的安装位置,例如我的电脑在D:\\Miniconda3\\Lib\\site-packages\\pyspark
手动创建conf目录并将hive-site.xml配置文件复制到其中。如果hive使用了mysql作为原数据库,则还需要将MySQL对应的驱动jar包放入spark的jars目录下。
创建spark会话对象时可通过enableHiveSupport()开启hive支持:
from pyspark.sql import SparkSession
from pyspark.sql import Row
spark = SparkSession \\
.builder \\
.appName("Python Spark SQL Hive integration example") \\
.enableHiveSupport() \\
.getOrCreate()
sc = spark.sparkContext
spark
spark访问hive自己创建的表有可能会出现如下的权限报错:
Caused by: java.lang.RuntimeException: The root scratch dir: /tmp/hive on HDFS s
hould be writable. Current permissions are: rwx------
是因为当前用户不具备对\\tmp\\hive的操作权限:
>winutils ls \\tmp\\hive
drwx------ 1 BUILTIN\\Administrators XIAOXIAOMING\\None 0 May 4 2020 \\tmp\\hive
把\\tmp\\hive目录的权限改为777即可顺利访问:
>winutils chmod 777 \\tmp\\hive
>winutils ls \\tmp\\hive
drwxrwxrwx 1 BUILTIN\\Administrators XIAOXIAOMING\\None 0 May 4 2020 \\tmp\\hive
Spark的DataFrame与RDD
从spark2.x开始将RDD和DataFrame的API统一抽象成dataset,DataFrame就是Dataset[Row],RDD则是Dataset.rdd。可以将DataFrame理解为包含结构化信息的RDD。
将含row的RDD转换为DataFrame只需要调用toDF方法或SparkSession的createDataFrame方法即可,也可以传入schema覆盖类型或名称设置。
DataFrame的基础api
DataFrame默认支持DSL风格语法,例如:
//查看DataFrame中的内容
df.show()
//查看DataFrame部分列中的内容
df.select(df['name'], df['age'] + 1).show()
df.select("name").show()
//打印DataFrame的Schema信息
df.printSchema()
//过滤age大于等于 21 的
df.filter(df['age'] > 21).show()
//按年龄进行分组并统计相同年龄的人数
personDF.groupBy("age").count().show()
将DataFrame注册成表或视图之后即可进行纯SQL操作:
df.createOrReplaceTempView("people")
//df.createTempView("t_person")
//查询年龄最大的前两名
spark.sql("select * from t_person order by age desc limit 2").show()
//显示表的Schema信息
spark.sql("desc t_person").show()
Pyspark可以直接很方便的注册udf并直接使用:
strlen = spark.udf.register("len", lambda x: len(x))
print(spark.sql("SELECT len('test') length").collect())
print(spark.sql("SELECT 'foo' AS text").select(strlen("text").alias('length')).collect())
执行结果:
[Row(length='4')]
[Row(length='3')]
RDD的简介
DataFrame的本质是对RDD的包装,可以理解为DataFrame=RDD[Row]+schema。
RDD(A Resilient Distributed Dataset)叫做弹性可伸缩分布式数据集,是Spark中最基本的数据抽象。它代表一个不可变、自动容错、可伸缩性、可分区、里面的元素可并行计算的集合。
在每一个RDD内部具有五大属性:
- 具有一系列的分区
- 一个计算函数操作于每一个切片
- 具有一个对其他RDD的依赖列表
- 对于 key-value RDDs具有一个Partitioner分区器
- 存储每一个切片最佳计算位置
一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
**一个计算每个分区的函数。**Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
**RDD之间的依赖关系。**RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
**一个Partitioner,即RDD的分片函数。**当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
**一个列表,存储存取每个Partition的优先位置(preferred location)。**对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
RDD的API概览
RDD包含Transformation API和 Action API,Transformation API都是延迟加载的只是记住这些应用到基础数据集上的转换动作,只有当执行Action API时这些转换才会真正运行。
Transformation API产生的两类RDD最重要,分别是MapPartitionsRDD和ShuffledRDD。
产生MapPartitionsRDD的算子有map、keyBy、keys、values、flatMap、mapValues 、flatMapValues、mapPartitions、mapPartitionsWithIndex、glom、filter和filterByRange 。其中用的最多的是map和flatMap,但任何产生MapPartitionsRDD的算子都可以直接使用mapPartitions或mapPartitionsWithIndex实现。
产生ShuffledRDD的算子有combineByKeyWithClassTag、combineByKey、aggregateByKey、foldByKey 、reduceByKey 、distinct、groupByKey、groupBy、partitionBy、sortByKey 和 repartitionAndSortWithinPartitions。
combineByKey到groupByKey 底层均是调用combineByKeyWithClassTag方法:
@Experimental
def combineByKeyWithClassTag[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C)(implicit ct: ClassTag[C]): RDD[(K, C)] = self.withScope
combineByKeyWithClassTag(createCombiner,mergeValue,mergeCombiners
,defaultPartitioner(self))
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)] = self.withScope
combineByKeyWithClassTag(createCombiner, mergeValue, mergeCombiners)(null)
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] = self.withScope
val createCombiner = (v: V) => CompactBuffer(v)
val mergeValue = (buf: CompactBuffer[V], v: V) => buf += v
val mergeCombiners = (c1: CompactBuffer[V], c2: CompactBuffer[V]) => c1 ++= c2
val bufs = combineByKeyWithClassTag[CompactBuffer[V]](
createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine = false)
bufs.asInstanceOf[RDD[(K, Iterable[V])]]
三个重要参数的含义:
- createCombiner:根据每个分区的第一个元素操作产生一个初始值
- mergeValue:对每个分区内部的元素进行迭代合并
- mergeCombiners:对所有分区的合并结果进行合并
groupByKey的partitioner未指定时会传入默认的defaultPartitioner。例如:
val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "spider", "eagle"), 2).keyBy(_.length)
a.groupByKey.collect
res9: Array[(Int, Iterable[String])] = Array((4,CompactBuffer(lion)), (6,CompactBuffer(spider)), (3,CompactBuffer(dog, cat)), (5,CompactBuffer(tiger, eagle)))
aggregateByKey:每个分区使用zeroValue作为初始值,迭代每一个元素用seqOp进行合并,对所有分区的结果用combOp进行合并。例如:
val pairRDD = sc.parallelize(List( ("cat",2), ("cat", 5), ("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)), 2)
pairRDD.aggregateByKey(0)(math.max(_, _), _ + _).collect
res6: Array[(String, Int)] = Array((dog,12), (cat,17), (mouse,6))
pairRDD.aggregateByKey(100)(math.max(_, _), _ + _).collect
res7: Array[(String, Int)] = Array((dog,100), (cat,200), (mouse,200))
reduceByKey :每个分区迭代每一个元素用func进行合并,对所有分区的结果用func再进行合并,例如:
val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), 2)
val b = a.map(x => (x.length, x))
b.reduceByKey(_ + _).collect
Action API有:
| 动作 | 含义 |
|---|---|
| reduce(func) | 通过func函数聚集RDD中的所有元素,这个功能必须是课交换且可并联的 |
| collect() | 在驱动程序中,以数组的形式返回数据集的所有元素 |
| count() | 返回RDD的元素个数 |
| first() | 返回RDD的第一个元素(类似于take(1)) |
| take(n) | 返回一个由数据集的前n个元素组成的数组 |
| takeSample(withReplacement*,*num, [seed]) | 返回一个数组,该数组由从数据集中随机采样的num个元素组成,可以选择是否用随机数替换不足的部分,seed用于指定随机数生成器种子 |
| takeOrdered(n, [ordering]) | 排序并取前N个元素 |
| saveAsTextFile(path) | 将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
| saveAsSequenceFile(path) | 将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
| saveAsObjectFile(path) | 将RDD中的元素用NullWritable作为key,实际元素作为value保存为sequencefile格式 |
| countByKey() | 针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
| foreach(func) | 在数据集的每一个元素上,运行函数func进行更新。 |
spark模拟实现mapreduce版wordcount:
object MapreduceWordcount
def main(args: Array[String]): Unit =
import org.apache.spark._
val sc: SparkContext = new SparkContext(new SparkConf().setAppName("wordcount").setMaster("local[*]"))
sc.setLogLevel("WARN")
import org.apache.hadoop.io.LongWritable, Text
import org.apache.hadoop.mapred.TextInputFormat
import org.apache.spark.rdd.HadoopRDD
import scala.collection.mutable.ArrayBuffer
def map(k: LongWritable, v: Text, collect: ArrayBuffer[(String, Int)]) =
for (word <- v.toString.split("\\\\s+"))
collect += ((word, 1))
def reduce(key: String, value: Iterator[Int], collect: ArrayBuffer[(String, Int)]) =
collect += ((key, value.sum))
val rdd = sc.hadoopFile("/hdfs/wordcount/in1/*", classOf[TextInputFormat], classOf[LongWritable], classOf[Text], 2)
.asInstanceOf[HadoopRDD[LongWritable, Text]]
.mapPartitionsWithInputSplit((split, it) =>
val collect: ArrayBuffer[(String, Int)] = ArrayBuffer[(String, Int)]()
it.foreach(kv => map(kv._1, kv._2, collect))
collect.toIterator
)
.repartitionAndSortWithinPartitions(new HashPartitioner(2))
.mapPartitions(it =>
val collect: ArrayBuffer[(String, Int)] = ArrayBuffer[(String, Int)]()
var lastKey: String = ""
var values: ArrayBuffer[Int] = ArrayBuffer[Int]()
for ((currKey, value) <- it)
if (!currKey.equals(lastKey))
if (values.length != 0)
reduce(lastKey, values.toIterator, collect)
values.clear()
values += value
lastKey = currKey
if (values.length != 0) reduce(lastKey, values.toIterator, collect)
collect.toIterator
)
rdd.foreach(println)
各类RDD

-
ShuffledRDD :表示需要走Shuffle过程的网络传输
-
CoalescedRDD :用于将一台机器的多个分区合并成一个分区
-
CartesianRDD :对两个RDD的所有元素产生笛卡尔积
-
MapPartitionsRDD :用于对每个分区的数据进行特定的处理
-
CoGroupedRDD :用于将2~4个rdd,按照key进行连接聚合
-
SubtractedRDD :用于对2个RDD求差集
-
UnionRDD和PartitionerAwareUnionRDD :用于对2个RDD求并集
-
ZippedPartitionsRDD2:zip拉链操作产生的RDD
-
ZippedWithIndexRDD:给每一个元素标记一个自增编号
-
PartitionwiseSampledRDD:用于对rdd的元素按照指定的百分比进行随机采样
当我们需要给Datafream添加自增列时,可以使用zipWithUniqueId方法:
from pyspark.sql.types import StructType, LongType
schema = data.schema.add(StructField("id", LongType()))
rowRDD = data.rdd.zipWithUniqueId().map(lambda t: t[0]+Row(t[1]))
data = rowRDD.toDF(schema)
data.show()
API用法详情可参考:https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.RDD.html#pyspark.RDD
cache&checkpoint
RDD通过persist方法或cache方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
rdd.persist()
checkpoint的源码注释可以看到:
- 标记该RDD作为检查点。
- 它将被保存在通过SparkContext#setCheckpointDir方法设置的检查点目录中
- 它所引用的所有父RDD引用将全部被移除
- 这个方法在这个RDD上必须在所有job执行前运行。
- 强烈建议将这个RDD缓存在内存中,否则这个保存文件的计算任务将重新计算。
从中我们得知,在执行checkpoint方法时,最好同时,将该RDD缓存起来,否则,checkpoint也会产生一个计算任务。
sc.setCheckpointDir("checkpoint")
rdd.cache()
rdd.checkpoint()
graphframes 的用法
GraphFrame是将Spark中的Graph算法统一到DataFrame接口的Graph操作接口,为Scala、Java和Python提供了统一的图处理API。
Graphframes是开源项目,源码工程如下:https://github.com/graphframes/graphframes
可以参考:
- 官网:https://graphframes.github.io/graphframes/docs/_site/index.html
- GraphFrames用户指南-Python — Databricks文档:https://docs.databricks.com/spark/latest/graph-analysis/graphframes/user-guide-python.html
在GraphFrames中图的顶点(Vertex)和边(edge)都是以DataFrame形式存储的:
- 顶点DataFrame:必须包含列名为“id”的列,用于作为顶点的唯一标识
- 边DataFrame:必须包含列名为“src”和“dst”的列,根据唯一标识id标识关系
创建图的示例:
from graphframes import GraphFrame
vertices = spark.createDataFrame([
("a", "Alice", 34),
("b", "Bob", 36),
("c", "Charlie", 30),
("d", "David", 29),
("e", "Esther", 32),
("f", "Fanny", 36),
("g", "Gabby", 60)], ["id", "name", "age"])
edges = spark.createDataFrame([
("a", "b", "friend"),
("b", "c", "follow"),
("c", "b", "follow"),
("f", "c", "follow"),
("e", "f", "follow"),
("e", "d", "friend"),
("d", "a", "friend"),
("a", "e", "friend")
], ["src", "dst", "relationship"])
# 生成图
g = GraphFrame(vertices, edges)
GraphFrame提供三种视图:
print("顶点表视图:")
graph.vertices.show() # graph.vertices 就是原始的vertices
print("边表视图:")
graph.以上是关于PySpark与GraphFrames的安装与使用的主要内容,如果未能解决你的问题,请参考以下文章