PointPillars论文解析和代码实现
Posted NNNNNathan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PointPillars论文解析和代码实现相关的知识,希望对你有一定的参考价值。
PointPillars是一个来自工业界的模型,整体思想基于图片的处理框架,直接将点云从俯视图的视角划分为一个个的Pillar(立方柱体),从而构成了类似图片的数据,然后在使用2D的检测框架进行特征提取和密集的框预测得到检测框,从而使得该模型在速度和精度都达到了一个很好的平衡。
PointPillars网络结构总览:

网络速度精度对比:
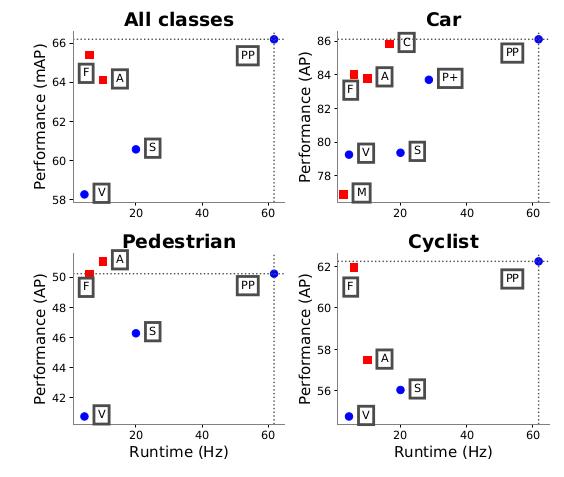
注:(PP代表pointpillars,M代表MV3D, A代表AVOD,C代表ContFuse,V代表VoxelNet,
F代表Frustum Pointnet,S代表SECOND ,P+代表PIXOR++)
本文将会以OpenPCDet的代码基础,详细解析PointPillars的每一行代码实现以及原因。
读者可以下载OpenPCDet后根据文章进行阅读和理解。
由于本人才疏学浅,解析中难免会出现不足之处,欢迎指正、讨论,有好的建议或意见都可以在评论区留言。谢谢大家!
PointPillars的论文地址为:
https://arxiv.org/pdf/1812.05784.pdf
解析参考代码:
https://github.com/open-mmlab/OpenPCDet
一 : 综述
3D检测算法通常有以下几种形式:
(1)将点云数据划纳入一个个体素(Voxel)中,构成规则的、密集分布的体素集,如有VoxelNet和SECOND。
(2)从前视和俯视角度对点云数据进行投影映射处理,获得一个个伪图片的数据。常见的模型有MV3D和AVOD。
(3)直接将点云数据映射到鸟瞰图后,再直接使用2D的检测框架的处理方法进行特征提取和RPN,实现3D的检测,如PIXOR、本文的主角pointpillar。
(4)使用pointnet直接从点云中对数据进行特征提取后获取proposals,然后根据获取的proposals进行微调,如Pointrcnn
二 : PP网络点云数据处理

这里的处理过程直接将3D的点云信息直接从以俯视图的形式进行获取,在点云中假设有N*3个点的信息,所有的这些点都在kitti lidar坐标系xyz中(单位是米,其中x向前,y向左,z向上)。所有的这些点都会分配到均等大小的x-y平面的立方柱体中,这个立方柱就被称为pillar。如下图所示
左相机前视图

点云俯视图 将点云分布到的均匀的立方柱体中

(注:此处偷懒,没有将点云转换到FOV视角中,直接从3D点云俯视图截图,仅为pillar解释)
kitti的点云数据是4维度的数据包含(x, y, z, r)其中xyz是改点在点云中的坐标,r代表了改点的反射强度(与物体材质和激光入射角度等有关);并且在将所有点放入每个pillar中的时候不需要像voxel那样考虑高度,可以将一个pillar理解为就是一个z轴上所有voxel组成在一起的。
在进行PP的数据增强时候,需要对pillar中的数据进行增强操作,需要将每个pillar中的点增加5个维度的数据,包含 x c , y c , z c , x p 和 y p,其中下标c代表了每个点云到改点所对应pillar中所有点平均值的偏移量,下标p代表了该点距离所在pillar中心点的x,y的偏移量。所有经过数据增强操作后每个点的维度是9维;包含了x,y,z, x c , y c , z c , x p 和 y p(注在openpcdet的代码实现中是10维,多了一个zp,也就是该点在z轴上与该点所处pillar的z轴中心的偏移量)
经过上述操作之后,就可以把原始的点云结构(N*3)变换成了(D,P,N),其中D代表了每个点云的特征维度,也就是每个点云9个特征,P代表了所有非空的立方柱体,N代表了每个pillar中最多会有多少个点。
注:
1、在实现的过程中,每个pillar的长宽是0.16米,在pcdet的实现中,我们只会截取前视图的部分,进行训练,因为kitti的标注是根据2号相机进行标注的,所有x轴的负方向(即车的后方)是没有标注数据的,我们会截取掉后面的数据;同时为了保证检测的可靠性,距离太远的点,由于点云过于稀疏,也会被截取。所以在pcdet的实现中,点云空间的选取范围xyz的最小值是=[0, -39.68,-3], xyz选取的最大值是[69.12, 39.68, 1]。
2、其中每个pillar中的最大点云数量是32,如果一个pillar中的点云数量超过32,那么就会随机采样,选取32个点;如果一个pillar中的点云数量少于32;那么会对这个pillar使用0样本填充。
在经过映射后,就获得了一个(D,P,N)的张量;接下来这里使用了一个简化版的pointnet网络对点云的数据进行特征提取(即将这些点通过MLP升维,然后跟着BN层和Relu激活层),得到一个(C,P,N)形状的张量,之后再使用maxpool操作提取每个pillar中最能代表该pillar的点。那么输出会变成(C,P,N)->(C,P);在经过上述操作编码后的点,需要重新放回到原来对应pillar的x,y位置上生成伪图象数据。
下面看这部分的代码实现:
预处理实现代码 pcdet/datasets/processor/data_processor.py
def transform_points_to_voxels(self, data_dict=None, config=None):
"""
将点云转换为pillar,使用spconv的VoxelGeneratorV2
因为pillar可是认为是一个z轴上所有voxel的集合,所以在设置的时候,
只需要将每个voxel的高度设置成kitti中点云的最大高度即可
"""
#初始化点云转换成pillar需要的参数
if data_dict is None:
# kitti截取的点云范围是[0, -39.68, -3, 69.12, 39.68, 1]
# 得到[69.12, 79.36, 4]/[0.16, 0.16, 4] = [432, 496, 1]
grid_size = (self.point_cloud_range[3:6] - self.point_cloud_range[0:3]) / np.array(config.VOXEL_SIZE)
self.grid_size = np.round(grid_size).astype(np.int64)
self.voxel_size = config.VOXEL_SIZE
# just bind the config, we will create the VoxelGeneratorWrapper later,
# to avoid pickling issues in multiprocess spawn
return partial(self.transform_points_to_voxels, config=config)
if self.voxel_generator is None:
self.voxel_generator = VoxelGeneratorWrapper(
#给定每个pillar的大小 [0.16, 0.16, 4]
vsize_xyz=config.VOXEL_SIZE,
#给定点云的范围 [0, -39.68, -3, 69.12, 39.68, 1]
coors_range_xyz=self.point_cloud_range,
#给定每个点云的特征维度,这里是x,y,z,r 其中r是激光雷达反射强度
num_point_features=self.num_point_features,
#给定每个pillar中最多能有多少个点 32
max_num_points_per_voxel=config.MAX_POINTS_PER_VOXEL,
#最多选取多少个pillar,因为生成的pillar中,很多都是没有点在里面的
# 可以重上面的可视化图像中查看到,所以这里只需要得到那些非空的pillar就行
max_num_voxels=config.MAX_NUMBER_OF_VOXELS[self.mode], # 16000
)
points = data_dict['points']
# 生成pillar输出
voxel_output = self.voxel_generator.generate(points)
# 假设一份点云数据是N*4,那么经过pillar生成后会得到三份数据
# voxels代表了每个生成的pillar数据,维度是[M,32,4]
# coordinates代表了每个生成的pillar所在的zyx轴坐标,维度是[M,3],其中z恒为0
# num_points代表了每个生成的pillar中有多少个有效的点维度是[m,],因为不满32会被0填充
voxels, coordinates, num_points = voxel_output
if not data_dict['use_lead_xyz']:
voxels = voxels[..., 3:] # remove xyz in voxels(N, 3)
data_dict['voxels'] = voxels
data_dict['voxel_coords'] = coordinates
data_dict['voxel_num_points'] = num_points
return data_dict
# 下面是使用spconv生成pillar的代码
class VoxelGeneratorWrapper():
def __init__(self, vsize_xyz, coors_range_xyz, num_point_features, max_num_points_per_voxel, max_num_voxels):
try:
from spconv.utils import VoxelGeneratorV2 as VoxelGenerator
self.spconv_ver = 1
except:
try:
from spconv.utils import VoxelGenerator
self.spconv_ver = 1
except:
from spconv.utils import Point2VoxelCPU3d as VoxelGenerator
self.spconv_ver = 2
if self.spconv_ver == 1:
self._voxel_generator = VoxelGenerator(
voxel_size=vsize_xyz,
point_cloud_range=coors_range_xyz,
max_num_points=max_num_points_per_voxel,
max_voxels=max_num_voxels
)
else:
self._voxel_generator = VoxelGenerator(
vsize_xyz=vsize_xyz,
coors_range_xyz=coors_range_xyz,
num_point_features=num_point_features,
max_num_points_per_voxel=max_num_points_per_voxel,
max_num_voxels=max_num_voxels
)
def generate(self, points):
if self.spconv_ver == 1:
voxel_output = self._voxel_generator.generate(points)
if isinstance(voxel_output, dict):
voxels, coordinates, num_points = \\
voxel_output['voxels'], voxel_output['coordinates'], voxel_output['num_points_per_voxel']
else:
voxels, coordinates, num_points = voxel_output
else:
assert tv is not None, f"Unexpected error, library: 'cumm' wasn't imported properly."
voxel_output = self._voxel_generator.point_to_voxel(tv.from_numpy(points))
tv_voxels, tv_coordinates, tv_num_points = voxel_output
# make copy with numpy(), since numpy_view() will disappear as soon as the generator is deleted
voxels = tv_voxels.numpy()
coordinates = tv_coordinates.numpy()
num_points = tv_num_points.numpy()
return voxels, coordinates, num_points在经过上面的预处理之后,就需要使用简化版的pointnet网络对每个pillar中的数据进行特征提取了。
代码在pcdet/models/backbones_3d/vfe/pillar_vfe.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from .vfe_template import VFETemplate
class PFNLayer(nn.Module):
def __init__(self,
in_channels,
out_channels,
use_norm=True,
last_layer=False):
super().__init__()
self.last_vfe = last_layer
self.use_norm = use_norm
if not self.last_vfe:
out_channels = out_channels // 2
if self.use_norm:
# 根据论文中,这是是简化版pointnet网络层的初始化
# 论文中使用的是 1x1 的卷积层完成这里的升维操作(理论上使用卷积的计算速度会更快)
# 输入的通道数是刚刚经过数据增强过后的点云特征,每个点云有10个特征,
# 输出的通道数是64
self.linear = nn.Linear(in_channels, out_channels, bias=False)
# 一维BN层
self.norm = nn.BatchNorm1d(out_channels, eps=1e-3, momentum=0.01)
else:
self.linear = nn.Linear(in_channels, out_channels, bias=True)
self.part = 50000
def forward(self, inputs):
if inputs.shape[0] > self.part:
# nn.Linear performs randomly when batch size is too large
num_parts = inputs.shape[0] // self.part
part_linear_out = [self.linear(inputs[num_part * self.part:(num_part + 1) * self.part])
for num_part in range(num_parts + 1)]
x = torch.cat(part_linear_out, dim=0)
else:
# x的维度由(M, 32, 10)升维成了(M, 32, 64)
x = self.linear(inputs)
torch.backends.cudnn.enabled = False
# BatchNorm1d层:(M, 64, 32) --> (M, 32, 64)
# (pillars,num_point,channel)->(pillars,channel,num_points)
# 这里之所以变换维度,是因为BatchNorm1d在通道维度上进行,对于图像来说默认模式为[N,C,H*W],通道在第二个维度上
x = self.norm(x.permute(0, 2, 1)).permute(0, 2, 1) if self.use_norm else x
torch.backends.cudnn.enabled = True
x = F.relu(x)
# 完成pointnet的最大池化操作,找出每个pillar中最能代表该pillar的点
# x_max shape :(M, 1, 64)
x_max = torch.max(x, dim=1, keepdim=True)[0]
if self.last_vfe:
# 返回经过简化版pointnet处理pillar的结果
return x_max
else:
x_repeat = x_max.repeat(1, inputs.shape[1], 1)
x_concatenated = torch.cat([x, x_repeat], dim=2)
return x_concatenated
class PillarVFE(VFETemplate):
"""
model_cfg:NAME: PillarVFE
WITH_DISTANCE: False
USE_ABSLOTE_XYZ: True
USE_NORM: True
NUM_FILTERS: [64]
num_point_features:4
voxel_size:[0.16 0.16 4]
POINT_CLOUD_RANGE: [0, -39.68, -3, 69.12, 39.68, 1]
"""
def __init__(self, model_cfg, num_point_features, voxel_size, point_cloud_range, **kwargs):
super().__init__(model_cfg=model_cfg)
self.use_norm = self.model_cfg.USE_NORM
self.with_distance = self.model_cfg.WITH_DISTANCE
self.use_absolute_xyz = self.model_cfg.USE_ABSLOTE_XYZ
num_point_features += 6 if self.use_absolute_xyz else 3
if self.with_distance:
num_point_features += 1
self.num_filters = self.model_cfg.NUM_FILTERS
assert len(self.num_filters) > 0
num_filters = [num_point_features] + list(self.num_filters)
pfn_layers = []
for i in range(len(num_filters) - 1):
in_filters = num_filters[i]
out_filters = num_filters[i + 1]
pfn_layers.append(
PFNLayer(in_filters, out_filters, self.use_norm, last_layer=(i >= len(num_filters) - 2))
)
# 加入线性层,将10维特征变为64维特征
self.pfn_layers = nn.ModuleList(pfn_layers)
self.voxel_x = voxel_size[0]
self.voxel_y = voxel_size[1]
self.voxel_z = voxel_size[2]
self.x_offset = self.voxel_x / 2 + point_cloud_range[0]
self.y_offset = self.voxel_y / 2 + point_cloud_range[1]
self.z_offset = self.voxel_z / 2 + point_cloud_range[2]
def get_output_feature_dim(self):
return self.num_filters[-1]
def get_paddings_indicator(self, actual_num, max_num, axis=0):
"""
计算padding的指示
Args:
actual_num:每个voxel实际点的数量(M,)
max_num:voxel最大点的数量(32,)
Returns:
paddings_indicator:表明一个pillar中哪些是真实数据,哪些是填充的0数据
"""
# 扩展一个维度,使变为(M,1)
actual_num = torch.unsqueeze(actual_num, axis + 1)
# [1, 1]
max_num_shape = [1] * len(actual_num.shape)
# [1, -1]
max_num_shape[axis + 1] = -1
# (1,32)
max_num = torch.arange(max_num, dtype=torch.int, device=actual_num.device).view(max_num_shape)
# (M, 32)
paddings_indicator = actual_num.int() > max_num
return paddings_indicator
def forward(self, batch_dict, **kwargs):
"""
batch_dict:
points:(N,5) --> (batch_index,x,y,z,r) batch_index代表了该点云数据在当前batch中的index
frame_id:(4,) --> (003877,001908,006616,005355) 帧ID
gt_boxes:(4,40,8)--> (x,y,z,dx,dy,dz,ry,class)
use_lead_xyz:(4,) --> (1,1,1,1)
voxels:(M,32,4) --> (x,y,z,r)
voxel_coords:(M,4) --> (batch_index,z,y,x) batch_index代表了该点云数据在当前batch中的index
voxel_num_points:(M,)
image_shape:(4,2) 每份点云数据对应的2号相机图片分辨率
batch_size:4 batch_size大小
"""
voxel_features, voxel_num_points, coords = batch_dict['voxels'], batch_dict['voxel_num_points'], batch_dict[
'voxel_coords']
# 求每个pillar中所有点云的和 (M, 32, 3)->(M, 1, 3) 设置keepdim=True的,则保留原来的维度信息
# 然后在使用求和信息除以每个点云中有多少个点来求每个pillar中所有点云的平均值 points_mean shape:(M, 1, 3)
points_mean = voxel_features[:, :, :3].sum(dim=1, keepdim=True) / voxel_num_points.type_as(voxel_features).view(
-1, 1, 1)
# 每个点云数据减去该点对应pillar的平均值得到差值 xc,yc,zc
f_cluster = voxel_features[:, :, :3] - points_mean
# 创建每个点云到该pillar的坐标中心点偏移量空数据 xp,yp,zp
f_center = torch.zeros_like(voxel_features[:, :, :3])
# coords是每个网格点的坐标,即[432, 496, 1],需要乘以每个pillar的长宽得到点云数据中实际的长宽(单位米)
# 同时为了获得每个pillar的中心点坐标,还需要加上每个pillar长宽的一半得到中心点坐标
# 每个点的x、y、z减去对应pillar的坐标中心点,得到每个点到该点中心点的偏移量
f_center[:, :, 0] = voxel_features[:, :, 0] - (
coords[:, 3].to(voxel_features.dtype).unsqueeze(1) * self.voxel_x + self.x_offset)
f_center[:, :, 1] = voxel_features[:, :, 1] - (
coords[:, 2].to(voxel_features.dtype).unsqueeze(1) * self.voxel_y + self.y_offset)
# 此处偏移多了z轴偏移 论文中没有z轴偏移
f_center[:, :, 2] = voxel_features[:, :, 2] - (
coords[:, 1].to(voxel_features.dtype).unsqueeze(1) * self.voxel_z + self.z_offset)
# 如果使用绝对坐标,直接组合
if self.use_absolute_xyz:
features = [voxel_features, f_cluster, f_center]
# 否则,取voxel_features的3维之后,在组合
else:
features = [voxel_features[..., 3:], f_cluster, f_center]
# 如果使用距离信息
if self.with_distance:
# torch.norm的第一个2指的是求2范数,第二个2是在第三维度求范数
points_dist = torch.norm(voxel_features[:, :, :3], 2, 2, keepdim=True)
features.append(points_dist)
# 将特征在最后一维度拼接 得到维度为(M,32,10)的张量
features = torch.cat(features, dim=-1)
# 每个pillar中点云的最大数量
voxel_count = features.shape[1]
"""
由于在生成每个pillar中,不满足最大32个点的pillar会存在由0填充的数据,
而刚才上面的计算中,会导致这些
由0填充的数据在计算出现xc,yc,zc和xp,yp,zp出现数值,
所以需要将这个被填充的数据的这些数值清0,
因此使用get_paddings_indicator计算features中哪些是需要被保留真实数据和需要被置0的填充数据
"""
# 得到mask维度是(M, 32)
# mask中指名了每个pillar中哪些是需要被保留的数据
mask = self.get_paddings_indicator(voxel_num_points, voxel_count, axis=0)
# (M, 32)->(M, 32, 1)
mask = torch.unsqueeze(mask, -1).type_as(voxel_features)
# 将feature中被填充数据的所有特征置0
features *= mask
for pfn in self.pfn_layers:
features = pfn(features)
# (M, 64), 每个pillar抽象出一个64维特征
features = features.squeeze()
batch_dict['pillar_features'] = features
return batch_dict
在经过简化版的pointnet网络提取出每个pillar的特征信息后,就需要将每个的pillar数据重新放回原来的坐标分布中来组成伪图像数据了。
代码在pcdet/models/backbones_2d/map_to_bev/pointpillar_scatter.py
import torch
import torch.nn as nn
class PointPillarScatter(nn.Module):
"""
对应到论文中就是stacked pillars,将生成的pillar按照坐标索引还原到原空间中
"""
def __init__(self, model_cfg, grid_size, **kwargs):
super().__init__()
self.model_cfg = model_cfg
self.num_bev_features = self.model_cfg.NUM_BEV_FEATURES # 64
self.nx, self.ny, self.nz = grid_size # [432,496,1]
assert self.nz == 1
def forward(self, batch_dict, **kwargs):
"""
Args:
pillar_features:(M,64)
coords:(M, 4) 第一维是batch_index 其余维度为xyz
Returns:
batch_spatial_features:(batch_size, 64, 496, 432)
"""
# 拿到经过前面pointnet处理过后的pillar数据和每个pillar所在点云中的坐标位置
# pillar_features 维度 (M, 64)
# coords 维度 (M, 4)
pillar_features, coords = batch_dict['pillar_features'], batch_dict['voxel_coords']
# 将转换成为伪图像的数据存在到该列表中
batch_spatial_features = []
batch_size = coords[:, 0].max().int().item() + 1
# batch中的每个数据独立处理
for batch_idx in range(batch_size):
# 创建一个空间坐标所有用来接受pillar中的数据
# self.num_bev_features是64
# self.nz * self.nx * self.ny是生成的空间坐标索引 [496, 432, 1]的乘积
# spatial_feature 维度 (64,214272)
spatial_feature = torch.zeros(
self.num_bev_features,
self.nz * self.nx * self.ny,
dtype=pillar_features.dtype,
device=pillar_features.device) # (64,214272)-->1x432x496=214272
# 从coords[:, 0]取出该batch_idx的数据mask
batch_mask = coords[:, 0] == batch_idx
# 根据mask提取坐标
this_coords = coords[batch_mask, :]
# this_coords中存储的坐标是z,y和x的形式,且只有一层,因此计算索引的方式如下
# 平铺后需要计算前面有多少个pillar 一直到当前pillar的索引
"""
因为前面是将所有数据flatten成一维的了,相当于一个图片宽高为[496, 432]的图片
被flatten成一维的图片数据了,变成了496*432=214272;
而this_coords中存储的是平面(不需要考虑Z轴)中一个点的信息,所以要
将这个点的位置放回被flatten的一位数据时,需要计算在该点之前所有行的点总和加上
该点所在的列即可
"""
# 这里得到所有非空pillar在伪图像的对应索引位置
indices = this_coords[:, 1] + this_coords[:, 2] * self.nx + this_coords[:, 3]
# 转换数据类型
indices = indices.type(torch.long)
# 根据mask提取pillar_features
pillars = pillar_features[batch_mask, :]
pillars = pillars.t()
# 在索引位置填充pillars
spatial_feature[:, indices] = pillars
# 将空间特征加入list,每个元素为(64, 214272)
batch_spatial_features.append(spatial_feature)
# 在第0个维度将所有的数据堆叠在一起
batch_spatial_features = torch.stack(batch_spatial_features, 0)
# reshape回原空间(伪图像) (4, 64, 214272)--> (4, 64, 496, 432)
batch_spatial_features = batch_spatial_features.view(batch_size, self.num_bev_features * self.nz, self.ny,
self.nx)
# 将结果加入batch_dict
batch_dict['spatial_features'] = batch_spatial_features
return batch_dict
三、使用2D BackBone提取特征
经过上面的映射操作,将原来的pillar提取最大的数值后放回到相应的坐标后,就可以得到类似于图像的数据了;只有在有pillar非空的坐标处有提取的点云数据,其余地方都是0数据,所以得到的一个(batch_size,64, 432, 496)的张量还是很稀疏的。
下图是对得到的张量数据使用2D中的特征提取手段进行多尺度的特征提取和拼接融合。
这没有好解析的就是常规的卷积操作然后进行拼接即可,注意一下维度变换就可以。
最终经过所有上采样层得到的3个尺度的的信息 每个尺度的 shape 都是 (batch_size, 128, 248, 216) 在第一个维度上进行拼接得到x 维度是 (batch_size, 384, 248, 216)

代码在pcdet/models/backbones_2d/base_bev_backbone.py
import numpy as np
import torch
import torch.nn as nn
class BaseBEVBackbone(nn.Module):
def __init__(self, model_cfg, input_channels):
super().__init__()
self.model_cfg = model_cfg
# 读取下采样层参数
if self.model_cfg.get('LAYER_NUMS', None) is not None:
assert len(self.model_cfg.LAYER_NUMS) == len(self.model_cfg.LAYER_STRIDES) == len(
self.model_cfg.NUM_FILTERS)
layer_nums = self.model_cfg.LAYER_NUMS
layer_strides = self.model_cfg.LAYER_STRIDES
num_filters = self.model_cfg.NUM_FILTERS
else:
layer_nums = layer_strides = num_filters = []
# 读取上采样层参数
if self.model_cfg.get('UPSAMPLE_STRIDES', None) is not None:
assert len(self.model_cfg.UPSAMPLE_STRIDES) == len(self.model_cfg.NUM_UPSAMPLE_FILTERS)
num_upsample_filters = self.model_cfg.NUM_UPSAMPLE_FILTERS
upsample_strides = self.model_cfg.UPSAMPLE_STRIDES
else:
upsample_strides = num_upsample_filters = []
num_levels = len(layer_nums) # 2
c_in_list = [input_channels, *num_filters[:-1]] # (256, 128) input_channels:256, num_filters[:-1]:64,128
self.blocks = nn.ModuleList()
self.deblocks = nn.ModuleList()
for idx in range(num_levels): # (64,64)-->(64,128)-->(128,256) # 这里为cur_layers的第一层且stride=2
cur_layers = [
nn.ZeroPad2d(1),
nn.Conv2d(
c_in_list[idx], num_filters[idx], kernel_size=3,
stride=layer_strides[idx], padding=0, bias=False
),
nn.BatchNorm2d(num_filters[idx], eps=1e-3, momentum=0.01),
nn.ReLU()
]
for k in range(layer_nums[idx]): # 根据layer_nums堆叠卷积层
cur_layers.extend([
nn.Conv2d(num_filters[idx], num_filters[idx], kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(num_filters[idx], eps=1e-3, momentum=0.01),
nn.ReLU()
])
# 在block中添加该层
# *作用是:将列表解开成几个独立的参数,传入函数 # 类似的运算符还有两个星号(**),是将字典解开成独立的元素作为形参
self.blocks.append(nn.Sequential(*cur_layers))
if len(upsample_strides) > 0: # 构造上采样层 # (1, 2, 4)
stride = upsample_strides[idx]
if stride >= 1:
self.deblocks.append(nn.Sequential(
nn.ConvTranspose2d(
num_filters[idx], num_upsample_filters[idx],
upsample_strides[idx],
stride=upsample_strides[idx], bias=False
),
nn.BatchNorm2d(num_upsample_filters[idx], eps=1e-3, momentum=0.01),
nn.ReLU()
))
else:
stride = np.round(1 / stride).astype(np.int)
self.deblocks.append(nn.Sequential(
nn.Conv2d(
num_filters[idx], num_upsample_filters[idx],
stride,
stride=stride, bias=False
),
nn.BatchNorm2d(num_upsample_filters[idx], eps=1e-3, momentum=0.01),
nn.ReLU()
))
c_in = sum(num_upsample_filters) # 512
if len(upsample_strides) > num_levels:
self.deblocks.append(nn.Sequential(
nn.ConvTranspose2d(c_in, c_in, upsample_strides[-1], stride=upsample_strides[-1], bias=False),
nn.BatchNorm2d(c_in, eps=1e-3, momentum=0.01),
nn.ReLU(),
))
self.num_bev_features = c_in
def forward(self, data_dict):
"""
Args:
data_dict:
spatial_features : (4, 64, 496, 432)
Returns:
"""
spatial_features = data_dict['spatial_features']
ups = []
ret_dict =
x = spatial_features
for i in range(len(self.blocks)):
x = self.blocks[i](x)
stride = int(spatial_features.shape[2] / x.shape[2])
ret_dict['spatial_features_%dx' % stride] = x
if len(self.deblocks) > 0: # (4,64,248,216)-->(4,128,124,108)-->(4,256,62,54)
ups.append(self.deblocks[i](x))
else:
ups.append(x)
# 如果存在上采样层,将上采样结果连接
if len(ups) > 1:
"""
最终经过所有上采样层得到的3个尺度的的信息
每个尺度的 shape 都是 (batch_size, 128, 248, 216)
在第一个维度上进行拼接得到x 维度是 (batch_size, 384, 248, 216)
"""
x = torch.cat(ups, dim=1)
elif len(ups) == 1:
x = ups[0]
# Fasle
if len(self.deblocks) > len(self.blocks):
x = self.deblocks[-1](x)
# 将结果存储在spatial_features_2d中并返回
data_dict['spatial_features_2d'] = x
return data_dict
四、检测头实现
PiontPillars中的检测头采用了类似SSD的检测头设置,在openpcdet的实现中,直接使用了一个网络训练车、人、自行车三个类别;没有像原论文中对车、人使用两种不同的网络结构。因此在检测头的先验框设置上,一共有三个类别的先验框,每个先验框都有两个方向分别是BEV视角下的0度和90度,每个类别的先验证只有一种尺度信息;分别是车 [3.9, 1.6, 1.56]、人[0.8, 0.6, 1.73]、自行车[1.76, 0.6, 1.73](单位:米)。
在anchor匹配GT的过程中,使用的是2D IOU匹配方式,直接从生成的特征图也就是BEV视角进行匹配;不需要考虑高度信息。原因有二:1、因为在kitti数据集中所有的物体都是在三维空间的同一个平面中的,没有车在车上面的一个情况。 2、所有类别物体之间的高度差别不是很大,直接使用SmoothL1回归就可以得到很好的结果。 其次是每个anchor被设置为正负样本的iou阈值是:
车匹配iou阈值大于等于0.65为正样本,小于0.45为负样本,中间的不计算损失。
人匹配iou阈值大于等于0.5为正样本,小于0.35为负样本,中间的不计算损失。
自行车匹配iou阈值大于等于0.5为正样本,小于0.35为负样本,中间的不计算损失。
其中每个anchor都需要预测7个参数,分别是 (x, y, z, w, l, h, θ),其中x, y, z预测一个anchor的中心坐标在点云中的位置, w,l,h分别预测了一个anchor的长宽高数据,θ预测了box的偏移角度。
同时,因为在角度预测时候不可以区分两个完全相反的box,所以PiontPillars的检测头中还添加了对一个anchor的方向预测;这里使用了一个基于softmax的方向分类box的两个朝向信息。
代码在 pcdet/models/dense_heads/anchor_head_single.py
import numpy as np
import torch.nn as nn
from .anchor_head_template import AnchorHeadTemplate
class AnchorHeadSingle(AnchorHeadTemplate):
"""
Args:
model_cfg: AnchorHeadSingle的配置
input_channels: 384 输入通道数
num_class: 3
class_names: ['Car','Pedestrian','Cyclist']
grid_size: (432, 496, 1)
point_cloud_range: (0, -39.68, -3, 69.12, 39.68, 1)
predict_boxes_when_training: False
"""
def __init__(self, model_cfg, input_channels, num_class, class_names, grid_size, point_cloud_range,
predict_boxes_when_training=True, **kwargs):
super().__init__(
model_cfg=model_cfg, num_class=num_class, class_names=class_names, grid_size=grid_size,
point_cloud_range=point_cloud_range,
predict_boxes_when_training=predict_boxes_when_training
)
# 每个点有3个尺度的个先验框 每个先验框都有两个方向(0度,90度) num_anchors_per_location:[2, 2, 2]
self.num_anchors_per_location = sum(self.num_anchors_per_location) # sum([2, 2, 2])
# Conv2d(512,18,kernel_size=(1,1),stride=(1,1))
self.conv_cls = nn.Conv2d(
input_channels, self.num_anchors_per_location * self.num_class,
kernel_size=1
)
# Conv2d(512,42,kernel_size=(1,1),stride=(1,1))
self.conv_box = nn.Conv2d(
input_channels, self.num_anchors_per_location * self.box_coder.code_size,
kernel_size=1
)
# 如果存在方向损失,则添加方向卷积层Conv2d(512,12,kernel_size=(1,1),stride=(1,1))
if self.model_cfg.get('USE_DIRECTION_CLASSIFIER', None) is not None:
self.conv_dir_cls = nn.Conv2d(
input_channels,
self.num_anchors_per_location * self.model_cfg.NUM_DIR_BINS,
kernel_size=1
)
else:
self.conv_dir_cls = None
self.init_weights()
# 初始化参数
def init_weights(self):
pi = 0.01
# 初始化分类卷积偏置
nn.init.constant_(self.conv_cls.bias, -np.log((1 - pi) / pi))
# 初始化分类卷积权重
nn.init.normal_(self.conv_box.weight, mean=0, std=0.001)
def forward(self, data_dict):
# 从字典中取出经过backbone处理过的信息
# spatial_features_2d 维度 (batch_size, 384, 248, 216)
spatial_features_2d = data_dict['spatial_features_2d']
# 每个坐标点上面6个先验框的类别预测 --> (batch_size, 18, 200, 176)
cls_preds = self.conv_cls(spatial_features_2d)
# 每个坐标点上面6个先验框的参数预测 --> (batch_size, 42, 200, 176) 其中每个先验框需要预测7个参数,分别是(x, y, z, w, l, h, θ)
box_preds = self.conv_box(spatial_features_2d)
# 维度调整,将类别放置在最后一维度 [N, H, W, C] --> (batch_size, 200, 176, 18)
cls_preds = cls_preds.permute(0, 2, 3, 1).contiguous()
# 维度调整,将先验框调整参数放置在最后一维度 [N, H, W, C] --> (batch_size ,200, 176, 42)
box_preds = box_preds.permute(0, 2, 3, 1).contiguous()
# 将类别和先验框调整预测结果放入前向传播字典中
self.forward_ret_dict['cls_preds'] = cls_preds
self.forward_ret_dict['box_preds'] = box_preds
# 进行方向分类预测
if self.conv_dir_cls is not None:
# # 每个先验框都要预测为两个方向中的其中一个方向 --> (batch_size, 12, 200, 176)
dir_cls_preds = self.conv_dir_cls(spatial_features_2d)
# 将类别和先验框方向预测结果放到最后一个维度中 [N, H, W, C] --> (batch_size, 248, 216, 12)
dir_cls_preds = dir_cls_preds.permute(0, 2, 3, 1).contiguous()
# 将方向预测结果放入前向传播字典中
self.forward_ret_dict['dir_cls_preds'] = dir_cls_preds
else:
dir_cls_preds = None
"""
如果是在训练模式的时候,需要对每个先验框分配GT来计算loss
"""
if self.training:
# targets_dict =
# 'box_cls_labels': cls_labels, # (4,211200)
# 'box_reg_targets': bbox_targets, # (4,211200, 7)
# 'reg_weights': reg_weights # (4,211200)
#
targets_dict = self.assign_targets(
gt_boxes=data_dict['gt_boxes'] # (4,39,8)
)
# 将GT分配结果放入前向传播字典中
self.forward_ret_dict.update(targets_dict)
# 如果不是训练模式,则直接生成进行box的预测
if not self.training or self.predict_boxes_when_training:
# 根据预测结果解码生成最终结果
batch_cls_preds, batch_box_preds = self.generate_predicted_boxes(
batch_size=data_dict['batch_size'],
cls_preds=cls_preds, box_preds=box_preds, dir_cls_preds=dir_cls_preds
)
data_dict['batch_cls_preds'] = batch_cls_preds # (1, 211200, 3) 70400*3=211200
data_dict['batch_box_preds'] = batch_box_preds # (1, 211200, 7)
data_dict['cls_preds_normalized'] = False
return data_dict
五、loss计算
在Pointpillars的loss计算中,使用了与SECOND相同的loss计算方式,每个GT框都包含了 (x, y, z, w, l, h, θ)这7个参数。
1、loss理论计算
1.定位任务的回归残差定义如下:
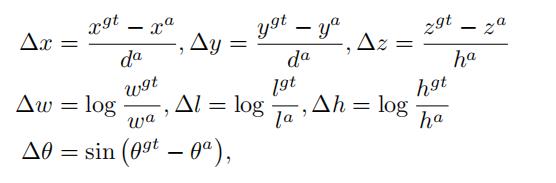
其中x^gt代表了标注框的x长度 ;x^a代表了先验框的长度信息,d^a表示先验框长度和宽度的对角线距离,定义为: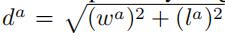 。
。
因此得到的总回归损失是: 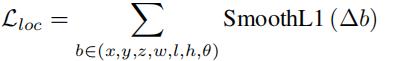 。
。
2.类别分类任务
对于每个先验框的物体类别分类,PointPillars使用了focal loss,来完成调节正负样本均衡,和难样本挖掘。公式定义如下:

其中,aplha参数和gamma参数都和RetinaNet中的设置一样,分别为0.25和2。
3.先验框方向分类
由于在角度回归的时候,不可以完全区分两个两个方向完全相反的预测框,所以在实现的时候,作者加入了对先验框的方向分类,使用softmax函数预测方向的类别。
因此总损失定义如下: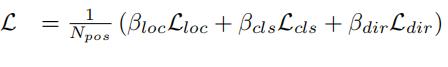
其中,系数Beta_loc为2,Beta_cls为1,Beta_dir为0.2。
2、loss计算代码实现
在loss计算的代码实现中涉及的代码量比较多,因此解析分为如下三个部分分别完成
1、先验框的生成
2、GT和先验框的匹配
3、loss计算实现
1、先验框的生成
代码在pcdet/models/dense_heads/target_assigner/anchor_generator.py
import torch
class AnchorGenerator(object):
def __init__(self, anchor_range, anchor_generator_config):
super().__init__()
self.anchor_generator_cfg = anchor_generator_config # list:3
# 得到anchor在点云中的分布范围[0, -39.68, -3, 69.12, 39.68, 1]
self.anchor_range = anchor_range
# 得到配置参数中所有尺度anchor的长宽高
# list:3 --> 车、人、自行车[[[3.9, 1.6, 1.56]],[[0.8, 0.6, 1.73]],[[1.76, 0.6, 1.73]]]
self.anchor_sizes = [config['anchor_sizes'] for config in anchor_generator_config]
# 得到anchor的旋转角度,这是是弧度,也就是0度和90度
# list:3 --> [[0, 1.57],[0, 1.57],[0, 1.57]]
self.anchor_rotations = [config['anchor_rotations'] for config in anchor_generator_config]
# 得到每个anchor初始化在点云中z轴的位置,其中在kitti中点云的z轴范围是-3米到1米
# list:3 --> [[-1.78],[-0.6],[-0.6]]
self.anchor_heights = [config['anchor_bottom_heights'] for config in anchor_generator_config]
# 每个先验框产生的时候是否需要在每个格子的中间,
# 例如坐标点为[1,1],如果需要对齐中心点的话,需要加上0.5变成[1.5, 1.5]
# 默认为False
# list:3 --> [False, False, False]
self.align_center = [config.get('align_center', False) for config in anchor_generator_config]
assert len(self.anchor_sizes) == len(self.anchor_rotations) == len(self.anchor_heights)
self.num_of_anchor_sets = len(self.anchor_sizes) # 3
def generate_anchors(self, grid_sizes):
assert len(grid_sizes) == self.num_of_anchor_sets
# 1.初始化
all_anchors = []
num_anchors_per_location = []
# 2.三个类别的先验框逐类别生成
for grid_size, anchor_size, anchor_rotation, anchor_height, align_center in zip(
grid_sizes, self.anchor_sizes, self.anchor_rotations, self.anchor_heights, self.align_center):
# 2 = 2x1x1 --> 每个位置产生2个anchor,这里的2代表两个方向
num_anchors_per_location.append(len(anchor_rotation) * len(anchor_size) * len(anchor_height))
# 不需要对齐中心点来生成先验框
if align_center:
x_stride = (self.anchor_range[3] - self.anchor_range[0]) / grid_size[0]
y_stride = (self.anchor_range[4] - self.anchor_range[1]) / grid_size[1]
# 中心对齐,平移半个网格
x_offset, y_offset = x_stride / 2, y_stride / 2
else:
# 2.1计算每个网格的在点云空间中的实际大小
# 用于将每个anchor映射回实际点云中的大小
# (69.12 - 0) / (216 - 1) = 0.3214883848678234 单位:米
x_stride = (self.anchor_range[3] - self.anchor_range[0]) / (grid_size[0] - 1)
# (39.68 - (-39.68.)) / (248 - 1) = 0.3212955490297634 单位:米
y_stride = (self.anchor_range[4] - self.anchor_range[1]) / (grid_size[1] - 1)
# 由于没有进行中心对齐,所有每个点相对于左上角坐标的偏移量都是0
x_offset, y_offset = 0, 0
# 2.2 生成单个维度x_shifts,y_shifts和z_shifts
# 以x_stride为step,在self.anchor_range[0] + x_offset和self.anchor_range[3] + 1e-5,
# 产生x坐标 --> 216个点 [0, 69.12]
x_shifts = torch.arange(
self.anchor_range[0] + x_offset, self.anchor_range[3] + 1e-5, step=x_stride, dtype=torch.float32,
).cuda()
# 产生y坐标 --> 248个点 [0, 79.36]
y_shifts = torch.arange(
self.anchor_range[1] + y_offset, self.anchor_range[4] + 1e-5, step=y_stride, dtype=torch.float32,
).cuda()
"""
new_tensor函数可以返回一个新的张量数据,该张量数据与指定的有相同的属性
如拥有相同的数据类型和张量所在的设备情况等属性;
并使用anchor_height数值个来填充这个张量
"""
# [-1.78]
z_shifts = x_shifts.new_tensor(anchor_height)
# num_anchor_size = 1
# num_anchor_rotation = 2
num_anchor_size, num_anchor_rotation = anchor_size.__len__(), anchor_rotation.__len__() # 1, 2
# [0, 1.57] 弧度制
anchor_rotation = x_shifts.new_tensor(anchor_rotation)
# [[3.9, 1.6, 1.56]]
anchor_size = x_shifts.new_tensor(anchor_size)
# 2.3 调用meshgrid生成网格坐标
x_shifts, y_shifts, z_shifts = torch.meshgrid([
x_shifts, y_shifts, z_shifts
])
# meshgrid可以理解为在原来的维度上进行扩展,例如:
# x原来为(216,)-->(216,1, 1)--> (216,248,1)
# y原来为(248,)--> (1,248,1)--> (216,248,1)
# z原来为 (1, ) --> (1,1,1) --> (216,248,1)
# 2.4.anchor各个维度堆叠组合,生成最终anchor(1,432,496,1,2,7)
# 2.4.1.堆叠anchor的位置
# [x, y, z, 3]-->[216, 248, 1, 3] 代表了每个anchor的位置信息
# 其中3为该点所在映射tensor中的(z, y, x)数值
anchors = torch.stack((x_shifts, y_shifts, z_shifts), dim=-1)
# 2.4.2.将anchor的位置和大小进行组合,编程为将anchor扩展并复制为相同维度(除了最后一维),然后进行组合
# (216, 248, 1, 3) --> (216, 248, 1 , 1, 3)
# 维度分别代表了: z,y,x, 该类别anchor的尺度数量,该个anchor的位置信息
anchors = anchors[:, :, :, None, :].repeat(1, 1, 1, anchor_size.shape[0], 1)
# (1, 1, 1, 1, 3) --> (216, 248, 1, 1, 3)
anchor_size = anchor_size.view(1, 1, 1, -1, 3).repeat([*anchors.shape[0:3], 1, 1])
# anchors生成的最终结果需要有位置信息和大小信息 --> (216, 248, 1, 1, 6)
# 最后一个纬度中表示(z, y, x, l, w, h)
anchors = torch.cat((anchors, anchor_size), dim=-1)
# 2.4.3.将anchor的位置和大小和旋转角进行组合
# 在倒数第二个维度上增加一个维度,然后复制该维度一次
# (216, 248, 1, 1, 2, 6) 长, 宽, 深, anchor尺度数量, 该尺度旋转角个数,anchor的6个参数
anchors = anchors[:, :, :, :, None, :].repeat(1, 1, 1, 1, num_anchor_rotation, 1)
# (216, 248, 1, 1, 2, 1) 两个不同方向先验框的旋转角度
anchor_rotation = anchor_rotation.view(1, 1, 1, 1, -1, 1).repeat(
[*anchors.shape[0:3], num_anchor_size, 1, 1])
# [z, y, x, num_size, num_rot, 7] --> (216, 248, 1, 1, 2, 7)
# 最后一个纬度表示为anchors的位置+大小+旋转角度(z, y, x, l, w, h, theta)
anchors = torch.cat((anchors, anchor_rotation), dim=-1) # [z, y, x, num_size, num_rot, 7]
# 2.5 置换anchor的维度
# [z, y, x, num_anchor_size, num_rot, 7]-->[x, y, z, num_anchor_zie, num_rot, 7]
# 最后一个纬度代表了 : [x, y, z, dx, dy, dz, rot]
anchors = anchors.permute(2, 1, 0, 3, 4, 5).contiguous()
# 使得各类anchor的z轴方向从anchor的底部移动到该anchor的中心点位置
# 车 : -1.78 + 1.56/2 = -1.0
# 人、自行车 : -0.6 + 1.73/2 = 0.23
anchors[..., 2] += anchors[..., 5] / 2
all_anchors.append(anchors)
# all_anchors: [(1,248,216,1,2,7),(1,248,216,1,2,7),(1,248,216,1,2,7)]
# num_anchors_per_location:[2,2,2]
return all_anchors, num_anchors_per_location
2、GT和先验框的匹配(target assignment)
3、loss计算实现
六、PointPillars推理详解
七、PointPillars测试结果和总结
待续
以上是关于PointPillars论文解析和代码实现的主要内容,如果未能解决你的问题,请参考以下文章