如何备份redhat linux系统?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何备份redhat linux系统?相关的知识,希望对你有一定的参考价值。
如何备份linux系统呢?在XP系统下可以把C盘内容备份到D/E盘中,重做系统即可恢复数据。但在linux系统中如何备份系统备份数据呢?备份的东西放在哪?重做系统后又如何恢复数据呢?
备份linux系统,不像Windows,Linux不限制根用户存取任何东西,因此,你完全可以把一个分区上每一个的文件放入一个TAR文件中。来实施这一方法,用这个成为根用户:sudo su
接着去你的文件系统的根目录(在我们的例子中,我们使用它,不过你可以去你希望备份的任何地方,包括远程或可移动驱动器。)
cd /
然后,下面就是我用来备份我的系统的完整的命令:
tar cvpzf backup.tgz / --exclude=/proc --exclude=/lost+found --exclude=/backup.tgz --exclude=/mnt --exclude=/sys
接着,让我们稍微解释一下:
很明显,'tar'部分就是我们将要使用的软件。
'cvpfz'是我们给tar加的选项,像“创建一个压缩文档”(这是显然的),“保存权限”(以便使每一个相同的文件有相同的权限),以及“gzip”(缩减大小)。
接下来,是压缩文档将获得的名称,在我们的例子中是backup.tgz。
紧随其后的是我们想要备份的根目录。既然我们想备份所有东西:/
接着就是我们要剔除的目录了。我们不想备份每一样东西,因为包括有些目录不是非常有用。同时确保你没有把备份文件本身也加进去了,否则,你会得到怪异的结果的。你也许同样不打算把/mnt文件夹包括进来——如果你在那儿挂载了其他分区——否则最终你会把那些也备份的。同时确保你没有任何东西挂载在 /media(即没有挂载任何cd或可移动介质)。否则,剔除/media。
如果你想排除所有的其他分区,你可以使用 'l' 参数代替 --exclude, 上面的命令看起来象这样:
tar cvpzlf backup.tgz / --exclude=/lost+found --exclude=/backup.tgz
按:kvidell在论坛主题里建议也剔除/dev目录。不过,我有其他证据表明这样做是不明智的。
好了,如果命令适合你的话,敲击确定键(或者回车键,管它叫什么名字),然后什么都不用干,放松一下。备份也许会花上一段时间。
完了以后,在你的文件系统的根目录会有一个叫作backup.tgz的文件——很可能相当巨大。现在你可以把烧录到DVD上,或者移动到另一台机器,你可以做任何你想做的事情。
按2:在进程的最后,你也许会得到一条信息,写着“tar:由于先前错误的耽搁而存在错误”或者其他什么,不过大多数情况下你可以仅仅忽略它。
作为选择,你可以使用Bzip来压缩你的备份。这意味着较高的压缩比但是也意味着较低的速度。如果压缩比对你很重要,只需用“j”替换命令中的“z”, 同时给备份命一个相应的扩展名。这些会使命令变成这样:
tar cvpjf backup.tar.bz2 / --exclude=/proc --exclude=/lost+found --exclude=/backup.tar.bz2 --exclude=/mnt --exclude=/sys
2.1. 通过网络备份如果空白的文件系统太少了并且你又不能挂载其它的文件系统来保存备份文件,你有可能使用 netcat 来完成备份.
在接受端你必须设置 netcat 用于写备份文件,象这样:
nc -l -p 1024 > backup.tar.bz2
然后你传送 tar 命令,不带 'f' 参数通过 netcat 在发送端,象这样:
tar cvpj / | nc -q 0 1024
在上面的命令中 1024 仅仅是一个随机的端口号, 任何从 1024 或以上的都可以工作.
如果安全的通过网络备份不依赖文件系统完成备份. 事实上一个真正快的网络比写备份文件到磁盘要快.
在上面的讲述中 (由于我刚刚发呆,因此我不能证实它是可靠的) 是这个命令:
tar cvpj / | ssh "cat > backup.tar.bz2"
3. 恢复警告:看在上帝的份上,在这一部分请小心谨慎。如果你不理解你在这里干了什么,你可能最终毁坏了对你而言很重要的东西,所以请小心谨慎。 那么,我们将紧接着上一章的例子:在分区的根目录下的backup.tgz文件
再一次确保你是根用户以及备份文件在文件系统的根目录。
Linux美妙的地方之一就是这一项工作甚至可以在一个正在运行的系统上进行;没必要被引导cd或者任何东西搞得晕头转向。当然,如果你使你的系统无法被引导了。你也许别无选择,只能使用一张live-cd了,但是结果是一样的。你甚至可以在Linux系统正在运行的时候,移除它里面所有文件。可是我不告诉你那个命令!
好了,言归正传。这是我要用的命令:
tar xvpfz backup.tgz -C /
如果你使用 bz2
tar xvpfj backup.tar.bz2 -C /
警告:这会把你分区里所有文件替换成压缩文档里的文件!
只要敲一下确定/回车/你的兄弟/随便什么,然后去看焰火吧。同样,这会花一段时间。等它完成了,你就有了一个完全恢复的Ubuntu系统!只需确保在你做其他任何事情之前,重新创建你剔除的目录:
mkdir proc mkdir lost+found mkdir mnt mkdir sys etc...
当你重启以后,所以的事情都会和你备份的时候一模一样。
3.1. 恢复 GRUB那么,如果你想把你的系统移动到一块新硬盘上,或者,你想对你的GRUB做一些糟糕的事情(比方说,安装Windows),你也将需要重装GRUB。在这个论坛里,有不少如何做这个的非常好的指导,所以我不会从头重新做起。相反,看一下这里(论坛) 或者这儿:RecoveringUbuntuAfterInstallingWindows
在这个论坛主题中,提出了一些方法。我个人建议第二个,remmelt贴出来的,因为我发现它每次都管用。
对,就是那个!我希望它有帮助!
4. 其他方法也许你也想看一下这些能帮助你自动备份系统的程序
Partimage
Mondo Rescue 参考技术A

Red Hat Linux操作系统,是Linux操作系统的一个发行版。那么针对linux Red Hat 这类操作系统的备份与恢复,或者数据迁移,需要借助一款工具,UCache灾备云!它既是一个高效的云容灾备份平台、又可以作为一款强大的数据迁移工具。首先需要在UCache云灾备平台上申请一个管理账号,并联系客服索要agent代理端下载链接,在服务器里安装完agent,之后就可以切换回UCache灾备云平台的管理后台进行相应的操作了。
在UCache灾备云控制台首页,左侧菜单栏有五类选项: 持续数据保护、 定时数据保护 、个人信息、任务告警、资源模块。主要功能:
(1)持续数据保护:
持续数据保护(英文名:continuous data protection,CDP),也称作持续备份(continuous backup),是一个在任何变化发生时,能备份企业所有的数据的存储系统。实时备份在任意时间间隔内对数据进行备份,无备份时间窗口,保障数据的零丢失。可以针对需要做实时备份的数据进行任务添加,比如应用级数据库就可以在这里添加实时备份的任务。
举例:利用UCache灾备云平台对linux Red Hat服务器系统备份时,保护的客户端为:redhat6.5,保护的应用类型可以选择:文件系统、mysql数据库、Oracle数据库、DB2数据库,然后新建备份任务。(如下图:)
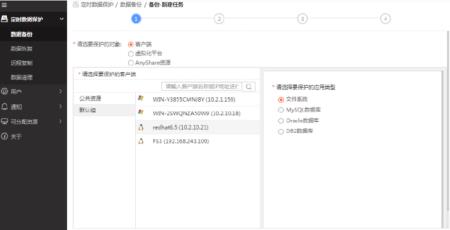
备份redhat linux系统 — 新建备份任务
选择要进行备份的文件目录和文件内容,可以全选和分选,还可以利用UCACHE灾备云控制台的“文件过滤”“目录过滤”“时间过滤”功能进行不必要的数据不进行备份策略添加。为了备份效率不建议两个任务包含同一文件。选择完要过滤的数据之后点击下一步,可进行下一步备份的高级功能选择,比如:永久增量备份、数据保留策略、传输和存储加密、数据压缩、重复数据删除等。任务添加后,在web控制台可以看到刚已添架的备份任务。
注意:在第一次备份任务执行时需要选择“完整备份”“差异化备份”两种备份方式,默认首次备份只能执行完整数据备份,在第二次备份时可以进行服务器差异化备份方式。备份执行完毕,会得到系统的执行反馈。
另外,相应的也会涉及到这类数据的实时复制、接管演练、策略模板、数据恢复、数据清理等,这些操作也都是对应这次实时备份任务建立后的连续的动作,产生了实时备份的数据,才可以对其选择相应的时间戳进行恢复,最快可以达到秒级恢复。
当生产服务器文件数据被损坏或者意外丢失时,UCACHE灾备云使用之前的文件系统备份集,可以利用备份产生时的时间戳,来实现文件数据的完整恢复、差异化数据恢复,达到生产数据还原的目的。当然,这个场景也适用于当我们需要做数据迁移时用到,或者生产数据出现问题需要恢复到另一个客户端的时候,或直接在云端进行业务接管时,都会用得上。
(2)定时数据保护
定时备份是对数据进行周期性备份,存在备份时间窗口。 对关键业务数据及系统按策略进行定时备份。这种场景适用于用户有些数据可能希望每天或者每周备份一次即可,频率可以根据用户需要对其进行设置添加备份任务。备份时既可以错开用户业务高峰,对设备的CPU、内存等计算资源及带宽不会在用户业务高峰时占用资源。
接下来的一波操作与上面讲到的实时备份任务的添加过程类似,可以一步一步进行相应的设置。任务建立后则对用户的数据进行定时的自动备份。假如我们设置的备份频率为5分钟/次的备份任务,那么当生产服务器文件数据被损坏或者意外丢失时,或遭遇“勒索病毒”时,根据我们添加的任务计划,按天按时定点进行备份/恢复,我们就可以选择相应的时间节点来选择5分钟前服务器数据没丢失或没被“勒索病毒”感染时的数据点恢复,即可。
另外:数据恢复的路径有2种选择,一种是原路径恢复,但原路径有可能服务器或环境出现问题导致我们不能进行原路径恢复,那么我们还可以选择恢复到另一个客户端,或者这时候任务接管就起了作用。我们可以把生产环境立刻切换到新的生产环境,总之,通过UCache灾备云技术方案可以保证我们的RTO(复原时间目标)和RPO(复原点目标)值最小。
(3)个人信息
这个不用解释了吧,里面有需要绑定邮件作为邮件告警时发送邮件使用的目的邮箱地址。
(4)任务告警
这个是根据我们执行完毕的备份任务,设定告警监控策略,如备份成功了邮件告警,或者备份任务失败时告警,或者账号管理账号登录时邮件告警,总之邮件告警的策略内容丰富,根据用户需要添加即可。
(5)资源模块
因为UCache平台的数据备份与自动恢复的功能不止是针对对linux Red Hat服务器系统备份与恢复的时候有应用场景,显示占用资源及重删资源。另外,UCache灾备云自动备份与恢复的场景还包括了:公有云、虚拟环境、物理环境以及私有云和混合云状态下的数据级、应用级的定时备份、差异化备份等内容。
参考技术B使用dd命令
找一个linux live cd的 u盘,然后U盘启动,进入U盘上的Linux系统,打开命令行,执行:
sudo fdisk -u -l 来查看硬件的分区情况。
然后执行dd if=/dev/你的linux分区 of=你要保存的地址/img.iso
要想恢复只需要执行 dd if=你保存的镜像地址/img.iso of=你要恢复的分区
同样,此命令也适用于非linux的系统,你可以把你的windows分区备份下来
dd命令详解:
dd命令是非常强大的命令,简介如下:
dd 是 Linux/UNIX 下的一个非常有用的命令,作用是用指定大小的块拷贝一个文件,并在拷贝的同时进行指定的转换。dd 的主要选项:
指定数字的地方若以下列字符结尾乘以相应的数字:
b=512, c=1, k=1024, w=2, xm=number m
if=file
输入文件名,缺省为标准输入。
of=file
输出文件名,缺省为标准输出。
ibs=bytes
一次读入 bytes 个字节(即一个块大小为 bytes 个字节)。
obs=bytes
一次写 bytes 个字节(即一个块大小为 bytes 个字节)。
bs=bytes
同时设置读写块的大小为 bytes ,可代替 ibs 和 obs 。
cbs=bytes
一次转换 bytes 个字节,即转换缓冲区大小。
skip=blocks
从输入文件开头跳过 blocks 个块后再开始复制。
seek=blocks
从输出文件开头跳过 blocks 个块后再开始复制。(通常只有当输出文件是磁盘或磁带时才有效)
count=blocks
仅拷贝 blocks 个块,块大小等于 ibs 指定的字节数。
conv=conversion[,conversion...]
用指定的参数转换文件。
转换参数:
ascii 转换 EBCDIC 为 ASCII。
ebcdic 转换 ASCII 为 EBCDIC。
ibm 转换 ASCII 为 alternate EBCDIC.
block 把每一行转换为长度为 cbs 的记录,不足部分用空格填充。
unblock
使每一行的长度都为 cbs ,不足部分用空格填充。
lcase 把大写字符转换为小写字符。
ucase 把小写字符转换为大写字符。
swab 交换输入的每对字节。 Unlike the
Unix dd, this works when an odd number of
bytes are read. If the input file contains
an odd number of bytes, the last byte is
simply copied (since there is nothing to
swap it with).
noerror
出错时不停止。
notrunc
不截短输出文件。
sync 把每个输入块填充到ibs个字节,不足部分用空(NUL)字符补齐。
由于 dd 命令允许二进制方式读写,所以特别适合在原始物理设备上进行输入/输出。例如可以用下面的命令为软盘建立镜像文件:
dd if=/dev/fd0 of=disk.img bs=1440k
有趣的是,这个镜像文件能被 HD-Copy ,Winimage 等工具软件读出。再如把第一个硬盘的前 512 个字节存为一个文件:
dd if=/dev/hda of=disk.mbr bs=512 count=1
来自http://www.cnblogs.com/reddusty/p/4746091.html
当你的系统损坏后,利用光盘或者U盘进入系统,原后删除以前的所有文件,再解压缩就行了。
当然,这是我的笨办法,有更高明的办法请网友也教教我啊!!!!
备份步骤:
cd /
mkdir backup
tar -jcvpf sysbak.tar.bz2 / --exclude=/proc,sys,backup
还原关键步骤参考:
tar -jxvpf sysbak.tar.bz2 -C /
欢迎共同学习Linux,我的博客:www.itwhy.org
linux 数据备份(NFS映射方法)
环境:Red Hat 4.8.3-9(主机) ip地址:192.168.1.1
Ubuntu 4.8.4-2(从机) IP地址:192.168.1.2
用途:将从机数据备份到主机,因从机空间较小,选择使用NFS网络磁盘映射的方法完成
NFS 是Network File System的缩写,即网络文件系统
【主机】
安装NFS服务
nfs-utils-* :包括基本的NFS命令与监控程序
portmap-* :支持安全NFS RPC服务的连接(该服务改名为rpcbind)
#查看是否已安装该服务 [[email protected] /]# rpm -qa|grep nfs [[email protected] /]# rpm -qa|grep portmap #安装nfs服务,光盘中有安装包 [[email protected] /]# yum install -y nfs-utils-*
注意:发现并没有安装portmap包,但使用yum list命令也未查找到,经过确认,该服务名称改为rpcbind。
NFS系统守护进程
nfsd:它是基本的NFS守护进程,主要功能是管理客户端是否能够登录服务器;
mountd:它是RPC安装守护进程,主要功能是管理NFS的文件系统。当客户端顺利通过nfsd登录NFS服务器后,在使用NFS服务所提供的文件前,还必须通过文件使用权限的验证。它会读取NFS的配置文件/etc/exports来对比客户端权限。
portmap:主要功能是进行端口映射工作。当客户端尝试连接并使用RPC服务器提供的服务(如NFS服务)时,portmap会将所管理的与服务对应的端口提供给客户端,从而使客户可以通过该端口向服务器请求服务。
NFS服务器配置
/etc/exports NFS服务的主要配置文件
/usr/sbin/exportfs NFS服务的管理命令
/usr/sbin/showmount 客户端的查看命令
/var/lib/nfs/etab 记录NFS分享出来的目录的完整权限设定值
/var/lib/nfs/xtab 记录曾经登录过的客户端信息
NFS服务的配置文件为 /etc/exports,这个文件是NFS的主要配置文件,不过系统并没有默认值,所以这个文件不一定会存在,可能要使用vim手动建立,然后在文件里面写入配置内容。
/etc/exports文件内容格式:
<输出目录> [客户端1 选项(访问权限,用户映射,其他)] [客户端2 选项(访问权限,用户映射,其他)]
a. 输出目录:
输出目录是指NFS系统中需要共享给客户机使用的目录;
b. 客户端:
客户端是指网络中可以访问这个NFS输出目录的计算机
客户端常用的指定方式
指定ip地址的主机:192.168.0.200
指定子网中的所有主机:192.168.0.0/24 192.168.0.0/255.255.255.0
指定域名的主机:david.bsmart.cn
指定域中的所有主机:*.bsmart.cn
所有主机:*
c. 选项:
选项用来设置输出目录的访问权限、用户映射等。
NFS主要有3类选项:
访问权限选项
设置输出目录只读:ro
设置输出目录读写:rw
用户映射选项
all_squash:将远程访问的所有普通用户及所属组都映射为匿名用户或用户组(nfsnobody);
no_all_squash:与all_squash取反(默认设置);
root_squash:将root用户及所属组都映射为匿名用户或用户组(默认设置);
no_root_squash:与rootsquash取反;
anonuid=xxx:将远程访问的所有用户都映射为匿名用户,并指定该用户为本地用户(UID=xxx);
anongid=xxx:将远程访问的所有用户组都映射为匿名用户组账户,并指定该匿名用户组账户为本地用户组账户(GID=xxx);
其它选项
secure:限制客户端只能从小于1024的tcp/ip端口连接nfs服务器(默认设置);
insecure:允许客户端从大于1024的tcp/ip端口连接服务器;
sync:将数据同步写入内存缓冲区与磁盘中,效率低,但可以保证数据的一致性;
async:将数据先保存在内存缓冲区中,必要时才写入磁盘;
wdelay:检查是否有相关的写操作,如果有则将这些写操作一起执行,这样可以提高效率(默认设置);
no_wdelay:若有写操作则立即执行,应与sync配合使用;
subtree:若输出目录是一个子目录,则nfs服务器将检查其父目录的权限(默认设置);
no_subtree:即使输出目录是一个子目录,nfs服务器也不检查其父目录的权限,这样可以提高效率;
简单实例:
/home/locoldir 192.168.1.0/24(rw)
NFS服务器的启动与停止
在对exports文件进行了正确的配置后,就可以启动NFS服务器了。
1、启动NFS服务器
为了使NFS服务器能正常工作,需要启动rpcbind和nfs两个服务,并且rpcbind一定要先于nfs启动
[[email protected] /]#service rpcbind restart [[email protected] /]#service nfs restart
【从机】
启动mount命令,将服务器目录mount到本地进行访问
mount -a 192.16.1.1:/test /test1
[email protected]:/opt/backup# mount -a 192.16.1.1:/test /test1 mount: wrong fs type, bad option, bad superblock on 192.16.1.1:/test, missing codepage or helper program, or other error (for several filesystems (e.g. nfs, cifs) you might need a /sbin/mount.<type> helper program) In some cases useful info is found in syslog - try dmesg | tail or so
执行后报以上错误,错误原因未安装nfs-common服务
本文出自 “grace的技术小窝” 博客,请务必保留此出处http://jimann.blog.51cto.com/3295893/1918945
以上是关于如何备份redhat linux系统?的主要内容,如果未能解决你的问题,请参考以下文章