踩坑笔记(pytorch-bert,dataframe,交叉熵)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了踩坑笔记(pytorch-bert,dataframe,交叉熵)相关的知识,希望对你有一定的参考价值。
参考技术A 1、pytorch bert输出的问题。2、dataframe的筛选问题。
输出:值为False的列没有被选中。
3、交叉熵损失函数
可以直接 认为是这样的一个概率和,
如果是多分类,假设真实标签[0,1,2,1,1,2,1]
那就是
Java笔记Tomcat登陆案例踩坑 凸(艹皿艹 )
用户登录案例需求:
1.编写login.html登录页面
username & password 两个输入框
2.使用Druid数据库连接池技术,操作mysql,testdemo数据库中user表
3.使用JdbcTemplate技术封装JDBC
4.登录成功跳转到SuccessServlet展示:登录成功!用户名,欢迎您
5.登录失败跳转到FailServlet展示:登录失败,用户名或密码错误
项目结构:
①UserDao:操作数据库中表的类(查询、修改、删除)。使用JdbcTamplate框架。
②User:一个Bean类,其中包括对应表中记录的属性类型:Id、name、password
③UserTest:使用Junit单元测试的测试类,用于测试UserDao的功能。
④JDBCUtils:JDBCUtils工具类,封装了获取连接对象、获取连接池、释放资源的方法。
⑤LoginServlet:登陆页面请求参数发送给这个Servlet,并由它调用UserDao中login方法,来查询数据库中是否存在对应用户名和密码。
问题:
当开启Tomcat服务器,在登陆页面输入并提交后,发送错误:
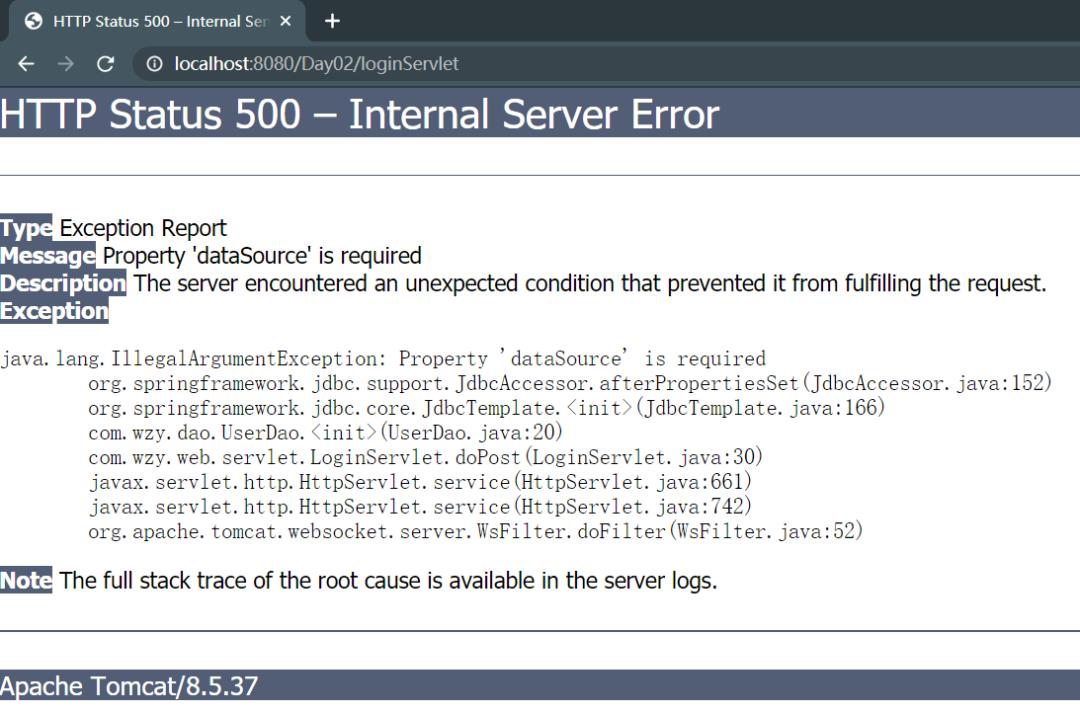
网页上报错
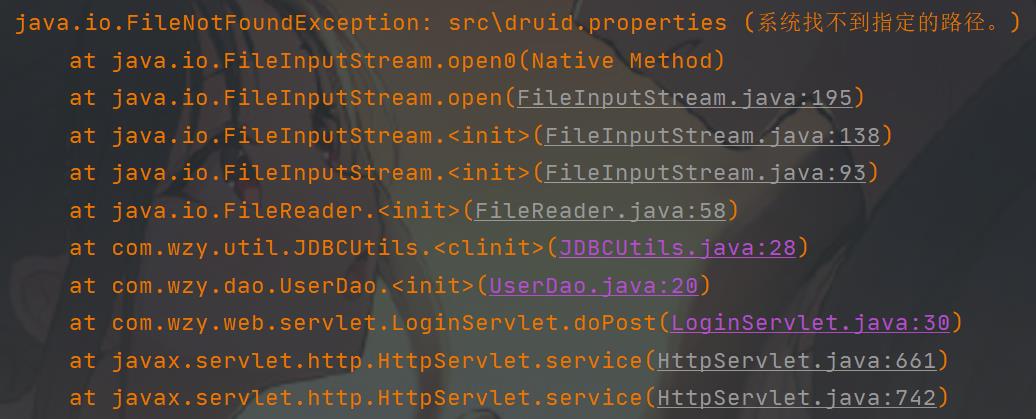
服务器报错
从服务器报错可看出异常出现的位置:JDBCUtils.java: 28
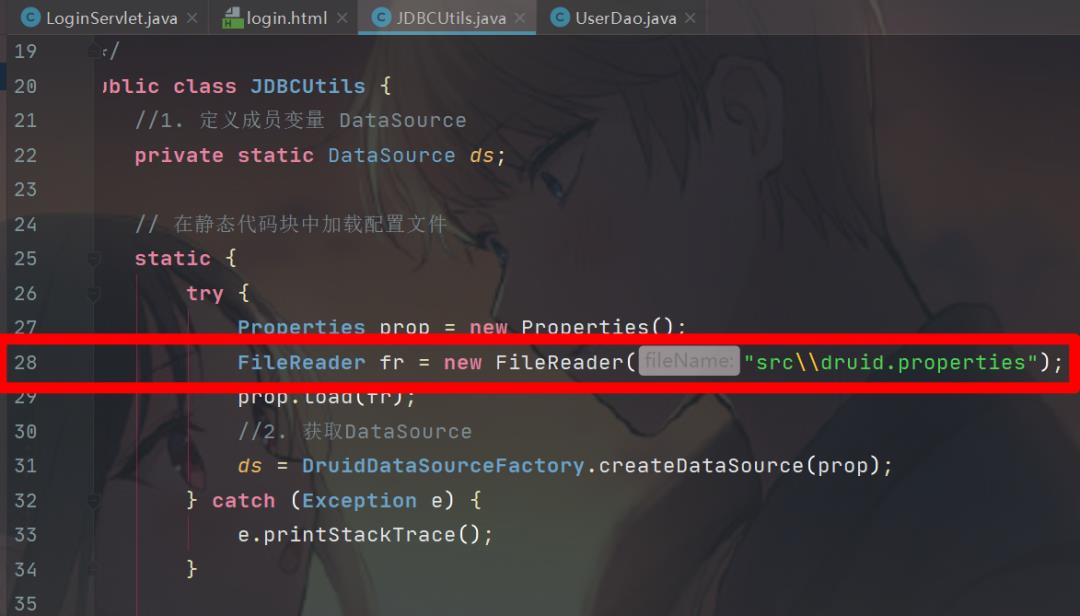
可以发现,报错的语句是加载Druid连接池的配置文件获取流的语句。
问题在于,之前在测试类UserTest中测试时是没有问题的,但是打开服务器后发生了无法找到文件的异常。
原因不明
解决方案:
在加载配置文件时,不使用FileReader获取文件路径的方式,而是使用类加载器中的方法:
getResourceAsStream(String name):查找具有给定名称的资源。
即将报错语句更改为:
InputStream fr = JDBCUtils.class.getClassLoader().getResourceAsStream("druid.properties");使用这个方法依旧可以将druid.properties配置文件放置在任意路径下(至少在src目录下可以)
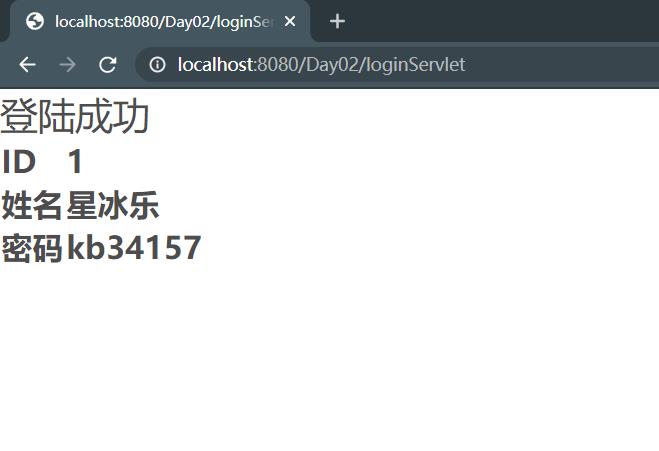
登陆成功
图源未知
(洛琪希永远的神
以上是关于踩坑笔记(pytorch-bert,dataframe,交叉熵)的主要内容,如果未能解决你的问题,请参考以下文章