Day537&538.scrapy爬虫框架 -python
Posted 阿昌喜欢吃黄桃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Day537&538.scrapy爬虫框架 -python相关的知识,希望对你有一定的参考价值。
scrapy爬虫框架
一、scrapy
-
scrapy是什么?
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。 -
安装scrapy
pip install scrapy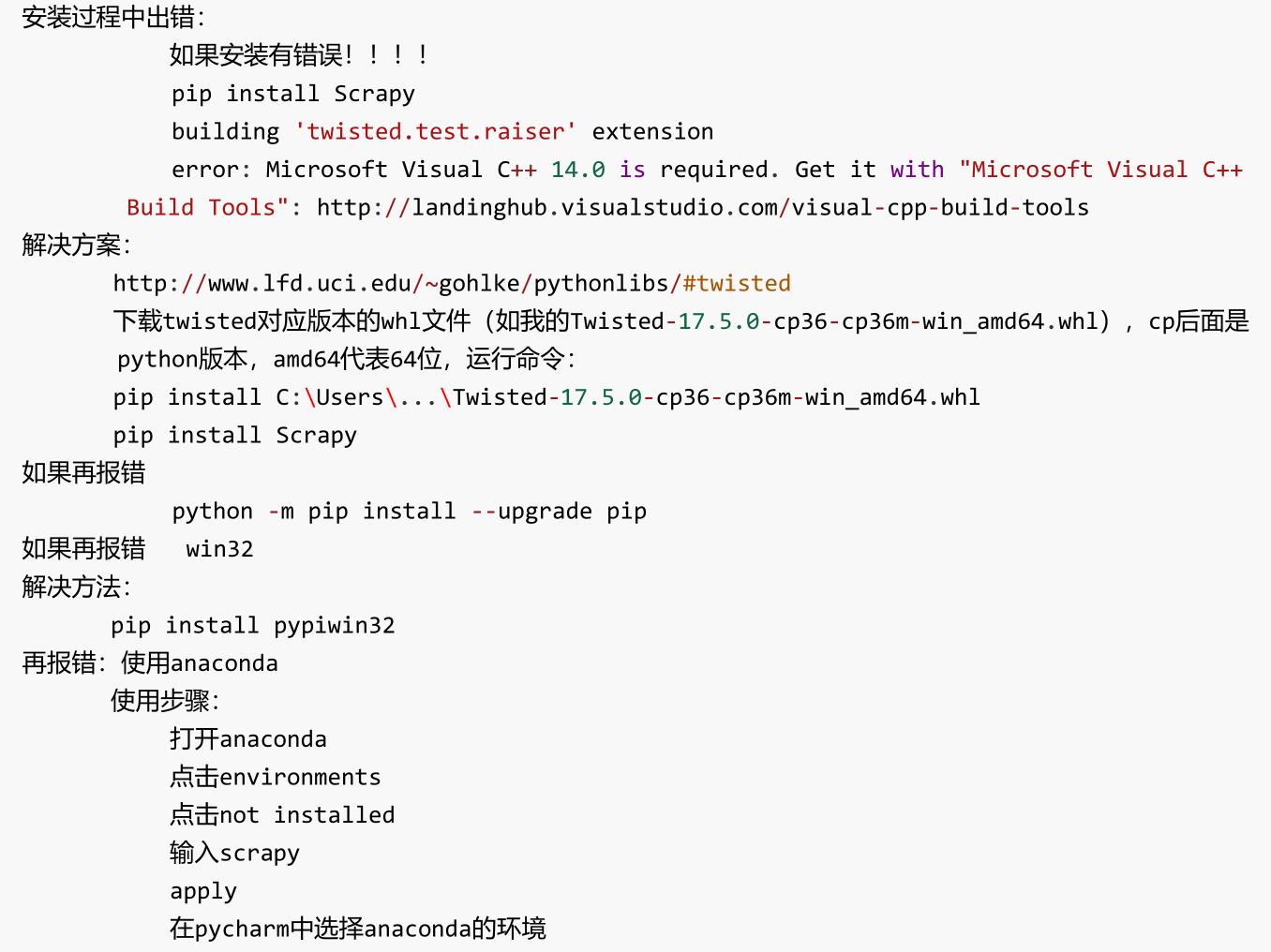
1、scrapy项目的创建以及运行
①创建scrapy项目
终端输入 scrapy startproject 项目名称
②项目组成
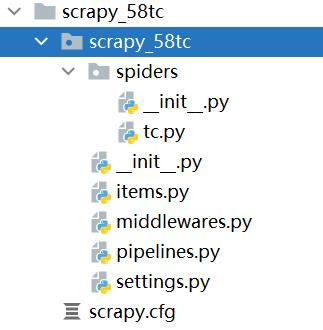

③创建爬虫文件
- 跳转到spiders文件夹
cd 目录名字/目录名字/spiders
- 创建爬虫文件.py
scrapy genspider 爬虫名字 网页的域名
# 比如
scrapy genspider achang http://achang.cc
- 爬虫文件的基本组成:
继承scrapy.Spider类

class BaiduSpider(scrapy.Spider):
# 爬虫的名字
name = 'baidu'
# 运行访问的域名
allowed_domains = ['www.baidu.com']
# 起始的url地址,指的是第一次访问的域名
# start_urls 是在allowed_domains前面添加了'http://'
# 在allowed_domains后面添加了'/'
start_urls = ['http://www.baidu.com/']
# 执行了start_urls之后 执行的方法 方法中的response就是返回的那个对象(相当于response = urllib.request.urlopen)
def parse(self, response):
print('阿昌来也')
④运行爬虫文件
scrapy crawl 爬虫名称
# 例如
scrapy crawl achang
注意:应在spiders文件夹内执行
2、scrapy架构组成

3、scrapy工作原理


- 案例:汽车之家
scrapy genspider carhome car.autohome.com.cn/price/brand-12.html

注掉君子协议
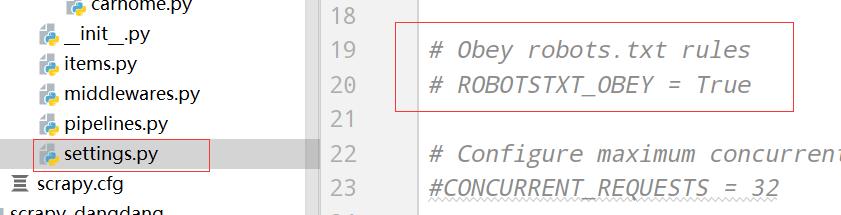
carhome.py:
class CarhomeSpider(scrapy.Spider):
name = 'carhome'
allowed_domains = ['https://car.autohome.com.cn/price/brand-12.html']
start_urls = ['https://car.autohome.com.cn/price/brand-12.html']
def parse(self, response):
name_list = response.xpath('//div[@class="main-title"]/a/text()')
for item in name_list:
print(item.extract())
二、yield

简要理解:
yield就是 return 返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后(下一行)开始
1、案例:
① 当当网
(1)yield(2).管道封装(3).多条管道下载 (4)多页数据下载
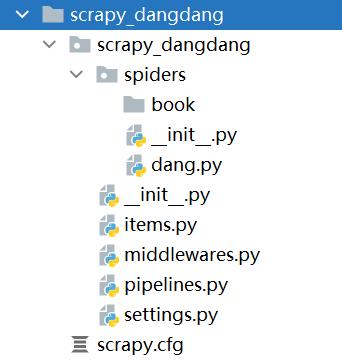
- settings.py: 设置项,设置多管道爬取
ITEM_PIPELINES =
# 管道可以有很多,那么管道是有优先级的,优先级为0-1000,值小 优先级越高
'scrapy_dangdang.pipelines.ScrapyDangdangPipeline': 300,
'scrapy_dangdang.pipelines.DangDangDownloadPipeline': 301,#多条管道

- pipelines.py :管道,多管道爬取,一个下载对应的json,一个爬取下载对应的图片
import urllib.request
class ScrapyDangdangPipeline:
# 爬虫开始执行
def open_spider(self,spider):
self.fp = open('book.json','a',encoding='utf-8')
# item就是yield返回的book对象
def process_item(self, item, spider):
# 操作文件过于频繁,不推荐
# with open('book.json','a',encoding='utf-8') as fp:
# fp.write(str(item))
self.fp.write(str(item))
return item
# 爬虫结束执行
def close_spider(self,spider):
self.fp.close()
# 开启多管道
# 1、定义管道类
# 2、在settings.py开启管道
# 'scrapy_dangdang.pipelines.DangDangDownloadPipeline': 301,#多条管道
class DangDangDownloadPipeline:
def process_item(self, item, spider):
filename = './book/'+item.get('name')+'.jpg'
urllib.request.urlretrieve(url=item.get('src'),filename=filename)
return item
- items.py 用于操作传递的模型(这里是爬取对应的数据)
class ScrapyDangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 你要下载的数据都有什么?
# 图片
src = scrapy.Field()
# 书名
name = scrapy.Field()
# 价格
price = scrapy.Field()
- dang.py :爬虫主要业务逻辑
import scrapy
from scrapy_dangdang.items import ScrapyDangdangItem
class DangSpider(scrapy.Spider):
name = 'dang'
# 如果是多页下载的话,就必须跳转 allowed_domains 的范围,一般情况就写域名
allowed_domains = ['ategory.dangdang.com']
start_urls = ['http://category.dangdang.com/cp01.28.02.93.00.00.html']
base_url = 'http://category.dangdang.com/cp'
page = 1
def parse(self, response):
# 【书写爬虫逻辑】
print('阿昌-----------来也')
# pipelines.py 下载数据
# items.py 定义数据结构
# src = '//ul[@id="component_59"]/li//img/@src'
# name = '//ul[@id="component_59"]/li//img/@alt'
# price = '//ul[@id="component_59"]/li//p[@class="price"]/span[@class="search_now_price"]/text()'
li_list = response.xpath('//ul[@id="component_59"]/li')
for item in li_list:
src = 'http:' + str(item.xpath('.//img/@data-original').extract_first())
if src:
src = src
else:
src = item.xpath('.//img/@src').extract_first()
name = item.xpath('.//img/@alt').extract_first()
price = item.xpath('.//p[@class="price"]/span[@class="search_now_price"]/text()').extract_first()
# print(src, name, price)
if src == 'http:None':
src = 'http://img3m6.ddimg.cn/33/9/20531346-1_b_7.jpg'
book = ScrapyDangdangItem(src=src, name=name, price=price)
# yield是迭代器,将封装的book交给pipelines
yield book
# 【页码爬取的回调】
# 每一页爬取的业务逻辑都是一样的,所有只需要修改页码并再次调用即可
if self.page < 100:
# 根据对应规律整理出下次回调的url地址
self.page = self.page + 1
url = self.base_url + str(self.page) + '-cp01.28.02.93.00.00.html'
# scrapy.Request 就是get请求
# url就是请求地址
# callback就是回调,也就是要执行的函数
print(url, '我是url回调地址')
yield scrapy.Request(url=url, callback=self.parse,dont_filter=True)
②爬虫电影1天2堂
https://www.dytt8.net/html/gndy/dyzz/list_23_1.html
创建项目:
scrapy startproject scrapy_movies
创建爬虫:
scrapy genspider mv https://www.dytt8.net/html/gndy/dyzz/list_23_1.html
启动爬虫
scrapy crawl mv
settings.py:打开管道,这里也可以定义多个管道,模仿上面的当当网案例

pipelines.py:
class ScrapyMoviesPipeline:
def open_spider(self,spider):
self.fp = open('movie.json','w',encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self,spider):
self.fp.close()
items.py: 指定要封装的爬取数据数据结构
class ScrapyMoviesItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
src = scrapy.Field()
spiders.mv.py:爬取第一页的电影名和在第一页中对应二级页的图片url
import scrapy
from scrapy_movies.items import ScrapyMoviesItem
class MvSpider(scrapy.Spider):
name = 'mv'
allowed_domains = ['www.dytt8.net']
start_urls = ['https://www.dytt8.net/html/gndy/dyzz/list_23_1.html']
def parse(self, response):
print('--------')
# 要第一页的电影名字和 第二页的图片地址
a_list = response.xpath('//div[@class="co_content8"]//tr[2]/td[2]/b/a')
print(a_list)
for item in a_list:
# 获取第一页name和之后第二页的地址
name = item.xpath('./text()').extract_first()
url = 'https://www.dytt8.net'+item.xpath('./@href').extract_first()
# 对第二页连接发起访问,获取里面对应的图片
# 通过meta='name':name 来为先调用的方法传递参数
yield scrapy.Request(url=url,callback=self.parse_second,meta='name':name)
# 如果还要爬取第二页就在这里通过 yield再回调一次parse,并封装好后几页的url
# yield scrapy.Request(url=’后面页数的url地址‘, callback=self.parse,dont_filter=True)
# 获取第二页访问电影图片的爬虫逻辑
# 此时response 就是访问第二页的响应内容
def parse_second(self,response):
# 注意:如果拿不到数据的情况下,一定要检查的xpath语法是否正确
src = response.xpath('//div[@id="Zoom"]//img/@src').extract_first()
# 从上面的meta中获取对应的name值
name = response.meta['name']
# 封装对象
movie = ScrapyMoviesItem(src=src,name=name)
# 将封装的对象返回给管道
yield movie
以上是关于Day537&538.scrapy爬虫框架 -python的主要内容,如果未能解决你的问题,请参考以下文章