javaSynchronousQueue源码分析
Posted 九师兄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了javaSynchronousQueue源码分析相关的知识,希望对你有一定的参考价值。

1.概述
转载:jdk11源码–SynchronousQueue源码分析
SynchronousQueue是一个同步阻塞队列,每一个 put操作都必须等待一个take操作。每一个take操作也必须等待一个put操作。
SynchronousQueue是没有容量的,无法存储元素节点信息,不能通过peek方法获取元素,peek方法会直接返回null。由于没有元素,所以不能被迭代,它的iterator方法会返回一个空的迭代器Collections.emptyIterator();。
SynchronousQueue比较适合线程通信、传递信息、状态切换等应用场景,一个线程必须等待另一个线程传递某些信息给他才可以继续执行。
SynchronousQueue这个队列不常用,但是线程池中有用到该队列,所以也分析一下。
Executors.newCachedThreadPool()方法中使用到了SynchronousQueue:
public static ExecutorService newCachedThreadPool()
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
SynchronousQueue的实现是W.N.Scherer III和M.L.Scott的“Nonblocking Concurrent Objects with Condition Synchronization”中描述的双栈和双队列算法的扩展。算法英文原文描述参见:原文
(Lifo)堆栈用于非公平模式,而(Fifo)队列用于公平模式。 两者的表现大致相似。 Fifo支持更高的吞吐量,Lifo可以保持更高的线程局部性(thread locality)。
线程局部性(thread locality):

上述引自一篇硕士论文:基于即时编译器的Java语言同步优化研究
SynchronousQueue类图:
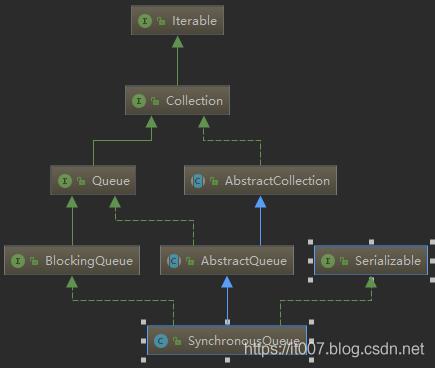
2.Transferer
Transferer是SynchronousQueue的内部抽象类,双栈和双队列算法共享该类。他只有一个transfer方法,用于转移元素,从生产者转移到消费者;或者消费者调用该方法从生产者取数据。
这里借用生产者和消费者的概念,其实SynchronousQueue也是一种特殊的生产者消费者实现。
abstract static class Transferer<E>
abstract E transfer(E e, boolean timed, long nanos);
由于SynchronousQueue队列没有容量,故而生产者和消费者的操作会比较类似,jdk作者这里将其进行抽象为一个方法,来实现put和take两个操作。简化了代码,但是会提高一点阅读难度。
transfer的第一个参数e:若不为空,就是put数据,但是当前线程需要等待消费者取走数据才可以返回。
若为空,就是消费者来取数据,如果没有数据可以取就阻塞。他取走的数据就是生产者put进来的数据。
timed:是否设置超时时间。
nanos:超时时间。
transfer方法返回值如果为空,代表超时或者中断。
Transferer有两个实现类:TransferQueue和TransferStack。
这两个类的区别就在于是否公平。TransferQueue是公平的,TransferStack非公平。
public SynchronousQueue()
this(false);
//构造函数指定公平策略。默认是非公平
public SynchronousQueue(boolean fair)
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();

接下来分析一下公平模式TransferQueue的源码。
3.TransferQueue
TransferQueue是Scherer-Scott双队列算法的扩展,他使用内部节点来代替标记指针。
重要属性:
// 队列的头尾节点
transient volatile QNode head;
transient volatile QNode tail;
/**
* 指向已经取消的节点,这个节点可能还没有从队列中取消连接,因为他是取消时最后一个插入的节点
*/
transient volatile QNode cleanMe;
两个主要方法:
public void put(E e) throws InterruptedException
if(e == null) throw new NullPointerException();
if (transferer.transfer(e, false, 0) == null) //返回值为空,代表超时或者中断
Thread.interrupted();//重置中断状态然后抛出中断异常
throw new InterruptedException();
public E take() throws InterruptedException
E e = transferer.transfer(null, false, 0);
if (e != null)
return e;
Thread.interrupted();//重置中断状态然后抛出中断异常
throw new InterruptedException();
put: 将制定元素添加到队列,等待有线程来将其取走
take::从对头取走一个元素,如果队列为空则等待另一个线程插入节点
4.QNode
QNode是TransferQueue内部类,代表内部节点。他只有一个next指针,典型的单向链表结构。
static final class QNode
volatile QNode next;
volatile Object item; // 使用CAS操作来设置item值,从null设置为某个值,或者将其设置为null
volatile Thread waiter; // 等待的线程,该字段用来控制park后者unpark操作
final boolean isData; // 用于判断是写线程(生产者)还是读线程(消费者)
5.transfer方法
transfer的基本思想:
循环处理下面两种情况:
-
如果队列是空的,或者队列中都是相同模式(same-mode)的节点,则将当前节点添加到等待队列。等待完成或取消,然后返回匹配的item -
如果队列中已经存在等待的节点,并且等待的节点与当前节点的模式不同,则将等待队列对头节点出队,返回匹配项。
可能翻译的不太好,这里将英文原文贴一下:
- If queue apparently empty or holding same-mode nodes, try to add node to queue of waiters,
wait to be fulfilled (or cancelled) and return matching item. - If queue apparently contains waiting items, and this call is of complementary mode,
try to fulfill by CAS’ing item field of waiting node and dequeuing it, and then returning matching item.
其实也比较好理解的,由于SynchronousQueue是同步阻塞队列,他又不存储任何的数据(等待队列中存的是线程,不是数据队列),那么当队列空时,来了一个put请求,那么他就入队,等待take将数据取走。如果一个put请求来时,队列中已经存在了很多的put线程等待,那么这个线程直接入队,如果已经有很多take线程等待,说明有很多线程等着取数据,那么直接将数据给等待的第一个线程即可。
反之亦然。
这里隐含告诉我们:如果队列不为空,那么他们的模式(读还是写)肯定相同。
//构造函数初始化TransferQueue时,会初始化一个虚拟节点,head和tail都指向该节点
TransferQueue()
QNode h = new QNode(null, false); // initialize to dummy node.
head = h;
tail = h;
E transfer(E e, boolean timed, long nanos)
QNode s = null; // constructed/reused as needed
//isData : true表示写,false表示读
boolean isData = (e != null);//e不为空,说明是带着数据来的,是写线程(生产者)
for (;;)
QNode t = tail;
QNode h = head;
if (t == null || h == null) // 如果head和tail都为空,则一直循环,直到有一个不为空。
continue;
if (h == t || t.isData == isData) // 如果队列为空,或者模式(读或者写)相同
QNode tn = t.next;
if (t != tail) // 再次校验t是否和tail一致,因为没有加锁,多线程,tail指针可能会改变
continue;
if (tn != null) // 同样,这里可能由于多线程的原因使t.next有了值,试想一下,另一个线程添加了一个新的节点,tail向后移了一位,而此时t还是指向老的tail,那么t.next就有值了。???
advanceTail(t, tn);//
continue;
if (timed && nanos <= 0L) // can't wait
return null;
if (s == null)
s = new QNode(e, isData);//新建节点,用于添加到等待队列
if (!t.casNext(null, s)) // CAS设置next节点,如果设置失败,则重试
continue;
advanceTail(t, s); // 移动队尾指针
Object x = awaitFulfill(s, e, timed, nanos);
if (x == s) // wait was cancelled
clean(t, s);
return null;
if (!s.isOffList()) // not already unlinked
advanceHead(t, s); // unlink if head
if (x != null) // and forget fields
s.item = s;
s.waiter = null;
return (x != null) ? (E)x : e;
else // complementary-mode
QNode m = h.next; // node to fulfill
if (t != tail || m == null || h != head)
continue; // inconsistent read
Object x = m.item;
if (isData == (x != null) || // m already fulfilled
x == m || // m cancelled
!m.casItem(x, e)) // lost CAS
advanceHead(h, m); // dequeue and retry
continue;
advanceHead(h, m); // successfully fulfilled
LockSupport.unpark(m.waiter);
return (x != null) ? (E)x : e;
void advanceTail(QNode t, QNode nt)
if (tail == t)
QTAIL.compareAndSet(this, t, nt);
Object awaitFulfill(QNode s, E e, boolean timed, long nanos)
/* Same idea as TransferStack.awaitFulfill */
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
int spins = (head.next == s)
? (timed ? MAX_TIMED_SPINS : MAX_UNTIMED_SPINS)
: 0;
for (;;)
if (w.isInterrupted())
s.tryCancel(e);
Object x = s.item;
if (x != e)
return x;
if (timed)
nanos = deadline - System.nanoTime();
if (nanos <= 0L)
s.tryCancel(e);
continue;
if (spins > 0)
--spins;
Thread.onSpinWait();
else if (s.waiter == null)
s.waiter = w;
else if (!timed)
LockSupport.park(this);
else if (nanos > SPIN_FOR_TIMEOUT_THRESHOLD)
LockSupport.parkNanos(this, nanos);
以上是关于javaSynchronousQueue源码分析的主要内容,如果未能解决你的问题,请参考以下文章
#tensorflow object detection api 源码分析