短视频内容理解与生成技术在美团的创新实践
Posted LiveVideoStack_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了短视频内容理解与生成技术在美团的创新实践相关的知识,希望对你有一定的参考价值。

点击上方“LiveVideoStack”关注我们
美团围绕丰富的本地生活服务电商场景,积累了海量视频数据。如何通过计算机视觉技术用相关数据,为用户和商家提供更好的服务,是一项重要的研发课题。本次LiveVideoStackCon 2021音视频技术大会 北京站,我们邀请到了美团高级算法专家马彬老师来分享短视频内容理解与生成技术,在美团业务场景的落地实践。
文 | 马彬
整理 | LiveVideoStack
大家好,我是马彬,在美团主要负责短视频相关的算法研发,很荣幸能够来到LVS跟各位分享我们在美团业务场景下的短视频理解与生成技术实践。

本次分享分为三个部分:背景介绍,技术与应用场景,总结展望。
01
背 景 介 绍
1.1
美团场景下的短视频示例

这里展示了美团业务场景下的一个菜品评论示例。可以看到,视频相较于文本和图像可以提供更加丰富的信息,创意菜“冰与火之歌”中火焰与巧克力和冰淇淋的动态交互,通过短视频形式进行了生动的呈现,进而给商家和用户提供多元化的内容展示和消费指引。
1.2
视频行业发展
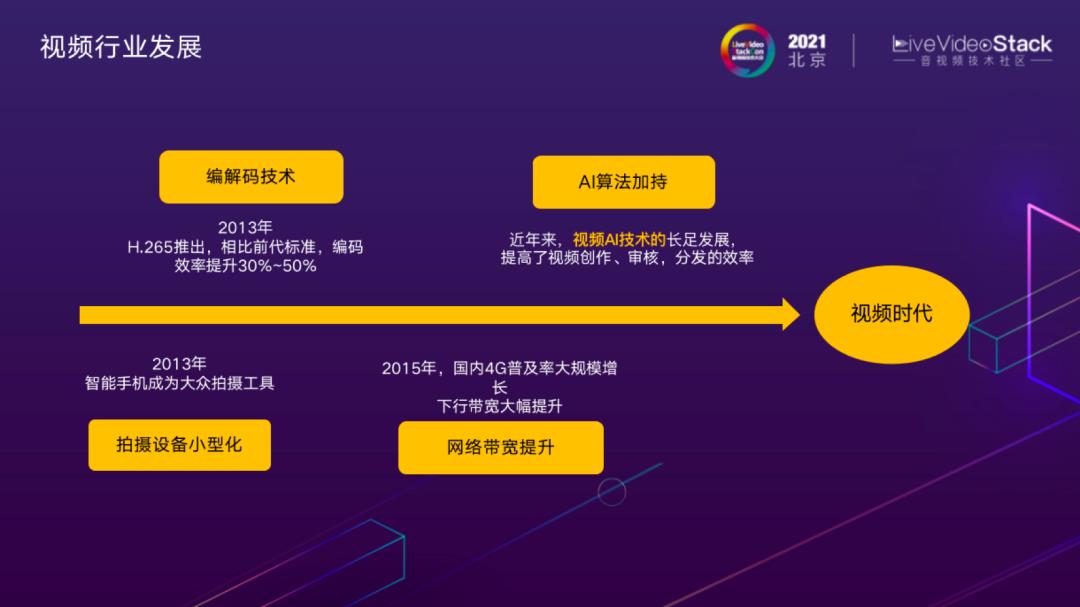
众所周知,多个方面的技术进步,成就了我们当前所处的视频爆炸时代,包括:拍摄采集设备,视频编解码技术的进步,网络通信技术的提升等。本次分享主要围绕AI算法,这一部分通过视频AI技术,提高视频内容创作生产和分发的效率。
1.3
美团AI——“场景驱动技术”

说到美团,大家用其点外卖的场景会较多,美团的业务场景非常丰富,有200多条业务线,涵盖“吃”、“住”、“行”、“玩”等生活服务,以及“美团优选”“团好货”等零售电商。丰富的业务场景带来了多样化的数据以及丰富的落地场景,驱动底层创新技术迭代。同时,底层技术的沉淀,又可以赋能各业务的数智化升级,形成互相促进的正向循环。
1.4
美团业务场景短视频
1.4.1
丰富的内容和展示形式(C端)
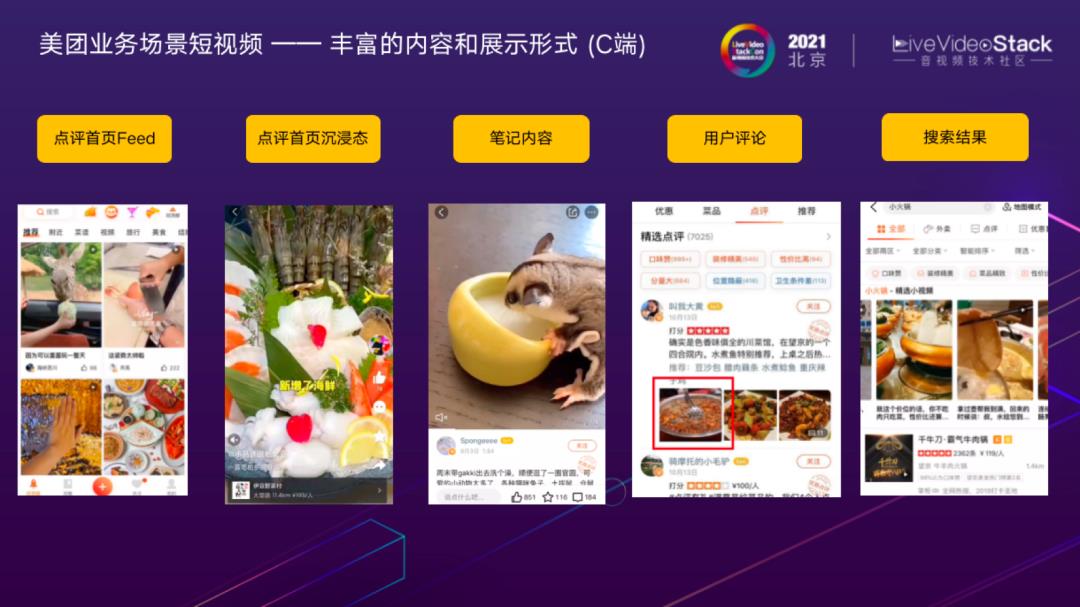
本次分享的一些技术实践案例,主要围绕着“吃”来展开。美团在每个场景站位都有内容布局和展示形式,列举了一些大家日常从大众点评APP可以看到的短视频在C端的应用场景,例如:点评首页Feed流的视频卡片,沉浸态视频,视频笔记,用户评论,搜索结果页等。这些视频内容在呈现给用户之前,经过了很多算法模型的理解和处理。
1.4.2
丰富的内容和展示形式(B端)
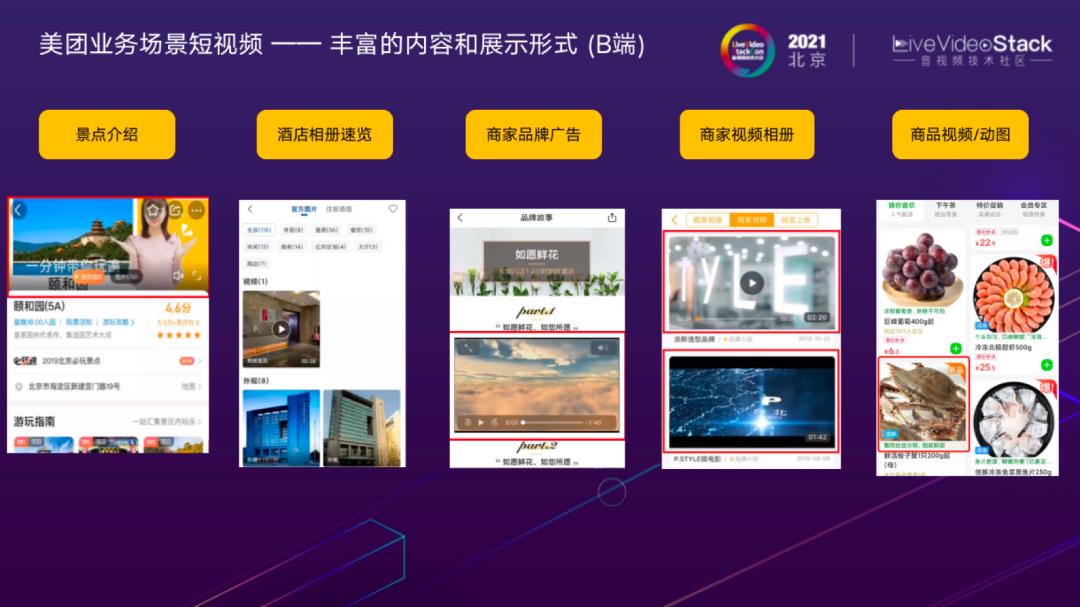
这里展示了一些商家端的视频内容展示形式,包括:景点介绍,给消费者做更加立体的展示;酒店相册速览,将相册中的静态图像合成视频,更好地展示酒店信息,它自动生成的技术会在下文中介绍;商家品牌广告;商家视频相册,商家可以自行上传丰富的视频内容;商品视频/动图,刚提到美团的业务范围也包括零售电商,这部分对于商品信息展示非常有优势。举个例子,生鲜类商品,例如螃蟹、虾的运动信息很难通过静态图像呈现,通过动图的形式为用户提供更多参考信息。
1.5
短视频技术应用场景

从应用场景来看,短视频在线上的应用场景主要包括:内容运营管理、内容搜索推荐、广告营销、创意生产。底层的支撑技术,主要可以分为两类:内容理解和内容生产。内容理解主要回答,视频中什么时间点,出现什么样的内容的问题。内容生产通常建立在内容理解基础上,对视频素材进行加工处理。典型的技术包括,视频智能封面、智能剪辑。下面我将分别介绍这两类技术在美团场景下的创新实践。
02
短视频内容理解与生成技术实践
2.1
短视频内容理解

视频标签
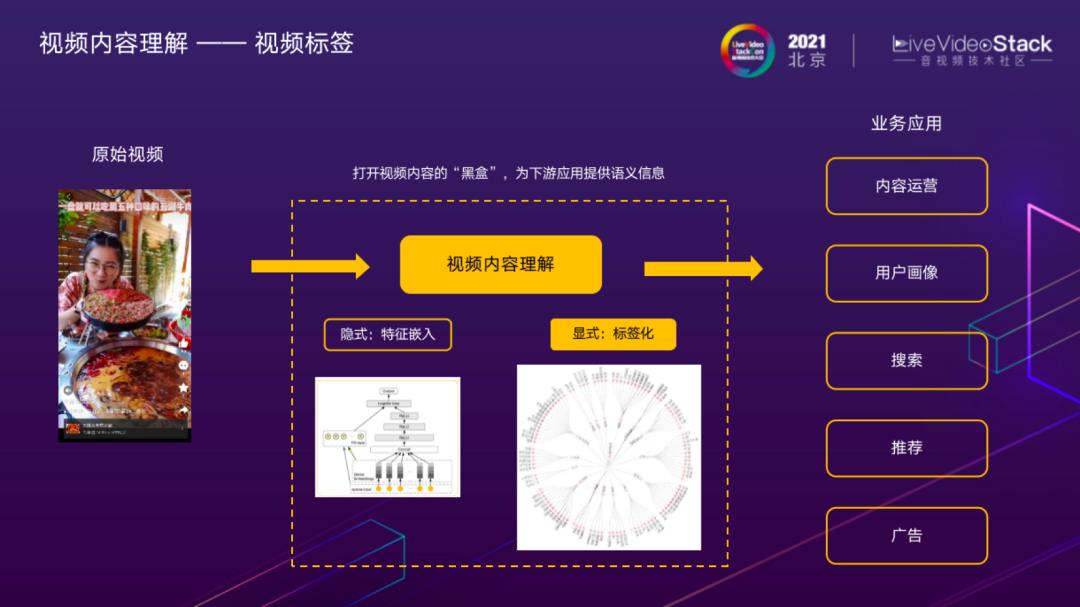
视频内容理解的主要目标是,概括视频中出现的重要概念,打开视频内容的“黑盒”,让机器知道盒子里有什么,为下游应用提供语义信息,以便更好地对视频做管理和分发。根据结果的形式,内容理解可以分为显式和隐式两种。其中,显式是指通过视频分类相关技术,给视频打上人可以理解的文本标签。隐式主要指以向量形式表示的嵌入特征,在推荐、搜索等场景下与模型结合直接面向最终任务建模。可以粗略地理解为,前者主要面向人,后者主要面向机器学习算法。
显式的视频内容标签在很多场景下是必要的,例如:内容运营场景,运营人员需要根据标签,开展供需分析,高价值内容圈选等工作。上图中展示的是内容理解为视频打标签的概要流程,这里的每个标签都是可供人理解的一个关键词。通常情况下,为了更好地维护和使用,大量标签会根据彼此之间的逻辑关系,组织成标签体系。
视频标签的不同维度与粒度

接下来分享视频标签的应用场景和背后的技术难点。这里展示了一个美团场景下比较有代表性的例子,视频讲述的是博主围绕美食场景的探店,内容非常丰富。
标签体系的设定是关键点,打什么样的标签描述视频内容。这里的标签定义需要产品、运营、算法多方面的视角共同确定。在这个例子中,共有三层标签,越上层越抽象。主题标签对整体视频内容概括能力越强;中间层会进一步拆分,描述拍摄场景相关内容;最底层拆分成细粒度实体,理解到宫保鸡丁还是番茄炒鸡蛋的粒度。不同层的标签有不同应用,对于最上层视频主题标签有一些高价值内容的筛选、运营手段。它的主要难点是抽象程度高,“美食探店”这个词概括程度很高,人在看过视频后可以理解,但从视觉特征建模的角度,需要具备什么特点才能算美食探店,对模型的学习能力提出了比较大的挑战。
基础表征学习
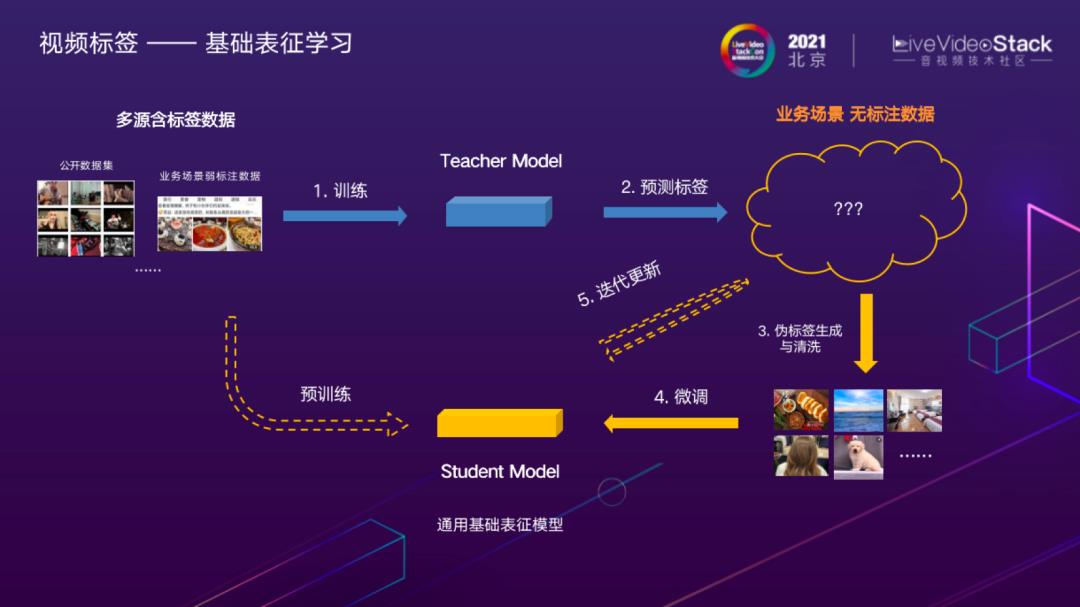
解决方案主要关注两方面:一方面是与标签无关的通用基础表征提升,另一方面是面向特定标签的分类性能提升。初始模型需要有比较好基础表征能力,这部分不涉及下游最终任务(例如:识别是否是美食探店视频),而是模型权重的预训练。学习好的基础表征对于分业务的改进事半功倍。标签数据的标注代价非常昂贵,需要考虑的是尽量少用业务全监督标注数据的情况下学习更好的基础特征。从左上角开始,有很多多源含标签数据可以利用。这里值得一提的是美团业务场景下弱标注数据,例如:用户在餐厅中做点评,图片和视频上层抽象标签是美食,它的评论会具体提到店里吃的菜,这是可挖掘的数据,通过使用这部分数据做预训练,可以得到一个初始的Teacher Model,给业务场景无标注数据打上伪标签。比较关键的是由于预测结果不完全准确,需要基于分类置信度等信息做伪标签清洗,随后拿到增量数据与Teacher Model一起做业务场景下更好的特征表达,迭代清洗得到Student Model,作为下游任务的基础表征模型。在实践中,我们发现数据迭代相较于模型结构的改进收益更大。
模型迭代
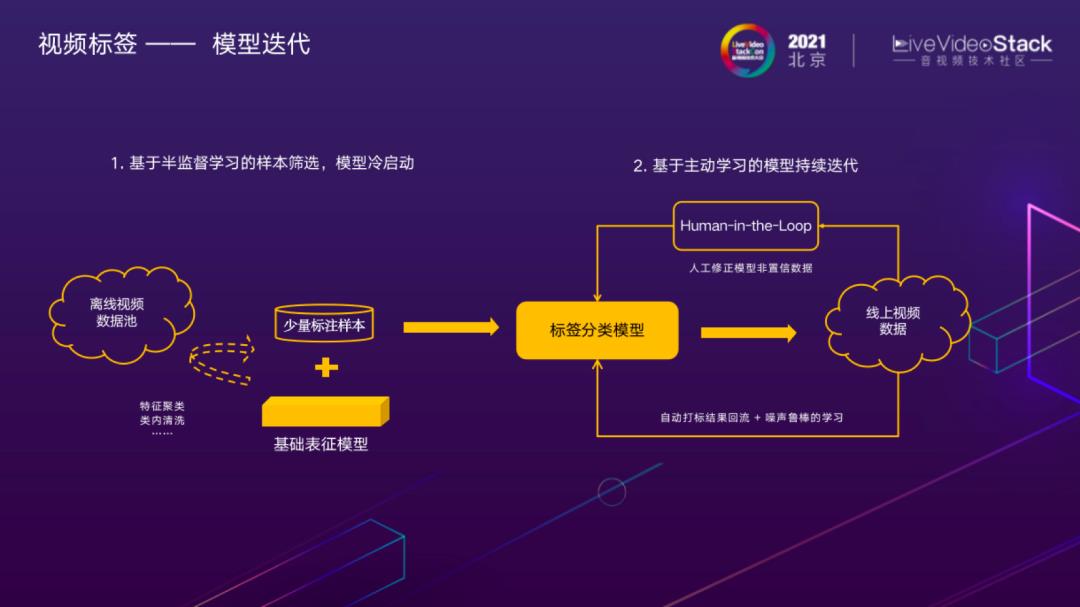
面向具体标签的性能提升主要应对的问题是,如何在基础表征模型的基础上,高效迭代目标类别的样本数据,提升标签分类模型的性能。样本的迭代分为离线和在线两部分,以美食探店标签为例,首先需要离线标注少量正样本,微调基础表征模型得到初始分类模型。这时模型的识别准确率通常较低,但即便如此,对样本的清洗、迭代也很有帮助。设想如果标注员从存量样本池里漫无目的地筛选,可能看了成百上千个视频都很难发现一个目标类别的样本,而通过初始模型做预筛选,可以每看几个视频就能筛出一个目标样本,对标注效率有显著的提升。
第二步如何持续迭代更多线上样本,提升标签分类模型准确率至关重要。我们对于模型线上预测的结果分两条回流路径。线上模型预测结果非常置信,或是若干个模型认知一致,可以自动回流模型预测标签加入模型训练,对于高置信但错误的噪声标签,可以通过模型训练过程中的一些抵抗噪声的技术,如:置信学习进行自动剔除。更有价值的是在实践中发现对于模型性能提升ROI更高的是人工修正模型非置信数据,例如三个模型预测结果差异较大的样本,筛出后交给人工确认。这种主动学习的方式,可以避免在大量简单样本上浪费标注人力,针对性地扩充对模型性能提升更有价值的标注数据。
视频主题标签应用——高价值内容筛选聚合

分享一些上述标签的应用场景。最代表性的是高价值内容的圈选,这是和点评推荐业务合作的应用案例。点评App首页信息流有达人探店的Tab,运营同学通过标签筛选出美食探店的视频进行展示。可以让用户以更好地体验方式更全面地了解到店内的信息,同时也为商家提供了一个很好的窗口,起到宣传引流的作用。
视频标签的不同维度与粒度
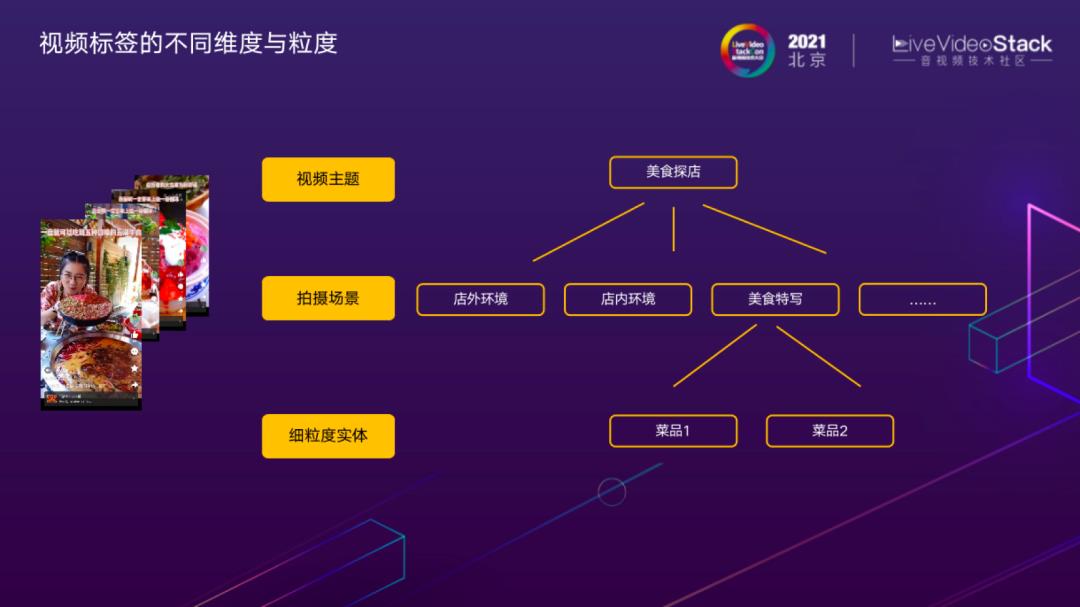
继续回到这张图,不同维度标签对于技术有不同要求,其中细粒度实体理解,需要识别具体是哪道菜,与上层粗粒度标签非常不同,需要考虑如何应对技术挑战。首先是细粒度识别任务,需要对视觉特征进行更精细的建模;其次,视频中的菜品理解相较于单张图像中的菜品识别更有挑战,需要应对数据的跨域问题。
菜品图像识别能力向视频领域的迁移

抽象出关键问题后,分别作出应对。首先在细粒度识别问题上,菜品的视觉相似性度量挑战在于不同食材的特征、及位置关系没有标准化的定义,同一道菜不同的师傅很可能做出两种完全不同的样子。这就需要模型既能够聚焦局部细粒度特征,又能够融合全局信息进行判别。为了解决这个问题,我们提出了一种堆叠式全局-局部注意力网络,同时捕捉形状纹理线索和局部的食材差异,对菜品识别效果有显著提升,相关成果发表在ACM MM国际会议上。
右图中展示的是第二部分挑战。图像和视频帧中的相同物体常常有着不同的外观表现,例如:图片中的螃蟹常常是煮熟了摆在盘中,而视频帧中经常出现烹饪过程中鲜活的螃蟹,它们在视觉层面差别很大。我们主要从数据分布的角度去应对这部分跨域差异。业务场景积累了大量有标注的美食图像,这些样本预测结果的判别性通常较好,但由于数据分布差异,视频帧中的螃蟹则不能被很确信地预测。对此我们希望提升视频帧场景中预测结果的判别性。一方面,利用核范数最大化的方法,获取更好的预测分布。另一方面,利用知识蒸馏的方式,不断通过强大的模型来指导轻量化网络的预测。再结合视频帧数据的半自动标注,即可获得在视频场景下较好的性能。
细粒度菜品图像识别能力

基于以上在美食场景内容理解的积累,我们在ICCV2021上举办了Large-Scale Fine-Grained Food Analysis比赛。菜品图像来自美团的实际业务场景,包含1500类中餐菜品,竞赛数据集持续开放:https://foodai-workshop.meituan.com/foodai2021.html#index,欢迎大家下载使用,共同提升挑战性场景下的识别性能。
菜品细粒度标签应用——按搜出封面

在视频中识别出细粒度的菜品名称有什么应用呢?这里跟大家分享一个,点评搜索业务场景的应用——按搜出封面,实现的效果是根据用户输入的搜索关键词,为同一套视频内容展示不同的封面。图中的离线部分展示了视频片段的切分和优选过程,首先通过关键帧提取,基础质量过滤筛选出适合展示的画面,通过菜品细粒度标签识别理解到在什么时间点出现什么菜品。作为候选封面素材,存储在数据库中。
线上用户对感兴趣内容进行搜索时,根据视频的多个封面候选与用户查询词的相关性,为用户展现最契合的封面,提升搜索体验。

这是线上效果的例子,同样是搜索“火锅”,左图是默认封面,右图是“按搜出封面”的结果。可以看到,左边的结果有一些以人物为主体的封面,与用户搜索火锅视频预期看到的内容不符,直观感觉像是不相关的bad case。而按搜出封面的展示结果,搜索到的内容都是火锅体验会很好。这也是对视频片段理解到细粒度标签,在美团场景下的创新应用。
挖掘更为丰富的视频片段标签

说到这里,讲的都是美食方面,美团还有很多其他的业务场景。如何自动挖掘更为丰富的视频标签,让标签体系本身能够自动扩展,而不是全部依赖人工整理定义,是一个重要的课题。我们基于点评丰富的用户评论数据开展相关工作。上图中的例子是用户的笔记,可以看到内容中既包含视频又包含若干张图片,还有一大段描述,这几个模态具有关联性,存在共性的概念。通过一些统计学习的方式,在视觉和文本两个模态之间做交叉验证,可以挖掘出视频片段和标签的对应关系。
视频片段语义标签挖掘结果示例

这里展示了通过提到算法自动挖掘出的视频片段和标签的例子。左图展示标签出现的频率,呈现了明显的长尾分布。比较值得注意的是,通过这种方式,算法能够发掘到粒度较细的有意义标签,例如右图中的“丝巾画”。

我们通过这种方式可以在尽量减少人工参与的前提下,发现美团场景的更多重要标签。
2.2
短视频内容生成

另外一部分是如何在内容理解基础上做内容生产。内容生产是在短视频AI应用场景非常重要的部分。本次分享更多涉及到视频素材的解构与理解。
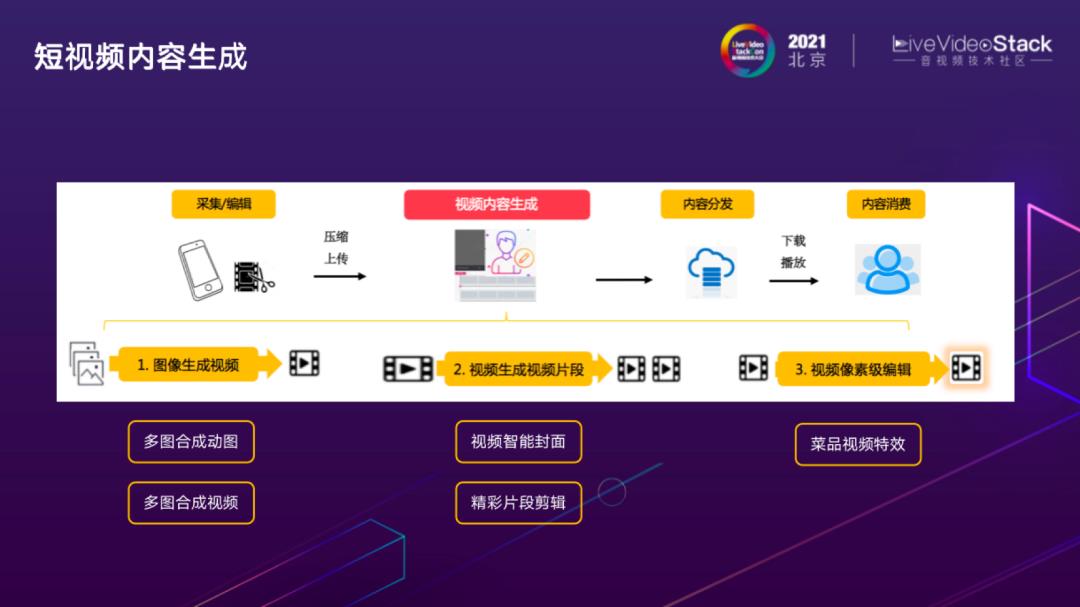
上图展示了视频内容生产的流程链路,内容生成部分主要是视频上传到云端后,作为素材进行二次加工,更好发挥内容的潜在价值。根据应用形式分为三类:图片生成视频,常见的形式有相册速览视频自动生成;视频生成视频片段,典型案例是长视频精彩片段剪辑,变成更精简的短视频做二次分发;视频像素级编辑,主要涉及精细化的画面特效编辑。
2.2.1
图像生成视频——餐饮场景 美食动图生成
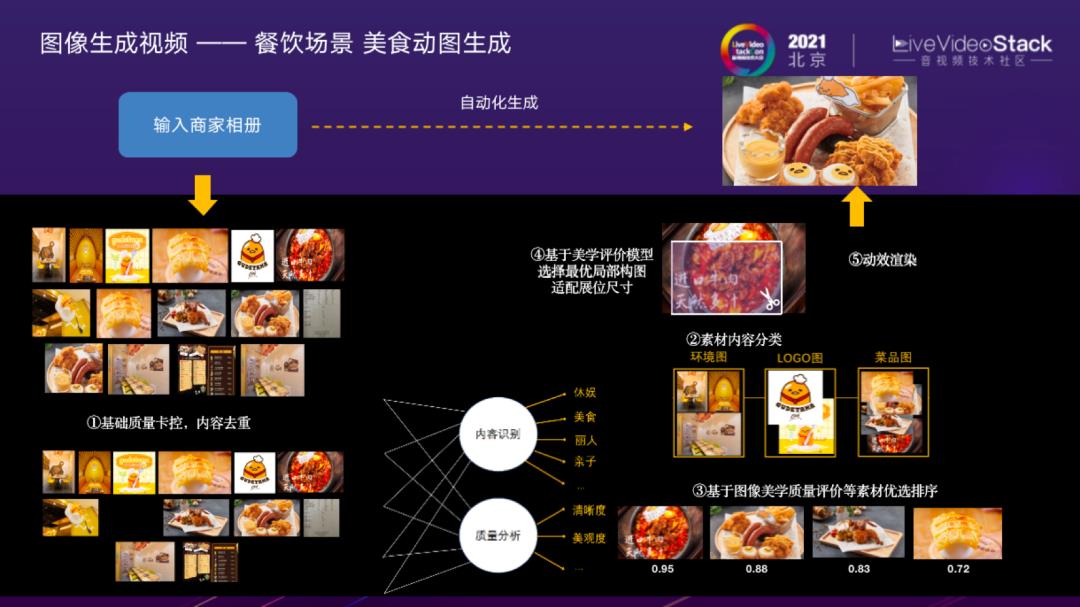
第一种图像生成视频,该部分要做的更多是针对图像素材的理解和加工,使用户对技术细节无感的前提下,一键端到端生成理想素材。如上图所示,商家只需要输入生产素材的图像相册,一切交给AI算法:首先自动去除拍摄质量较差的,不适合展示的图片。进一步做内容识别,质量分析。内容识别包括内容标签,质量分析包括清晰度、美学分;由于原始图像素材的尺寸难以直接适配目标展位,需要根据美学评价模型,对图像进行智能裁切;最终,叠加Ken-Burns、转场等特效,得到渲染结果。
2.2.2
图像生成视频——酒店场景 相册速览视频生成
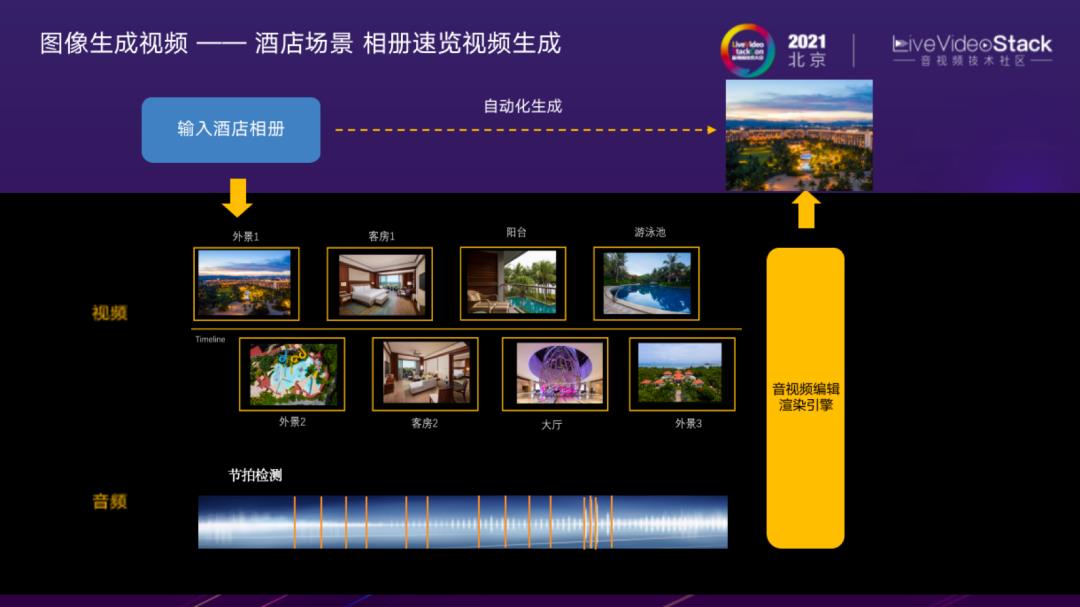
这是酒店场景下相册速览视频生成的例子,相比动图,需要结合音频与转场特效的配合。同时,视频对优先展示什么样的内容有更高要求,需要结合业务场景的特点,根据设计师制定的脚本模板,通过算法自动筛选特定类型的图像填充到模板相应位置。
2.2.3
视频生成视频片段
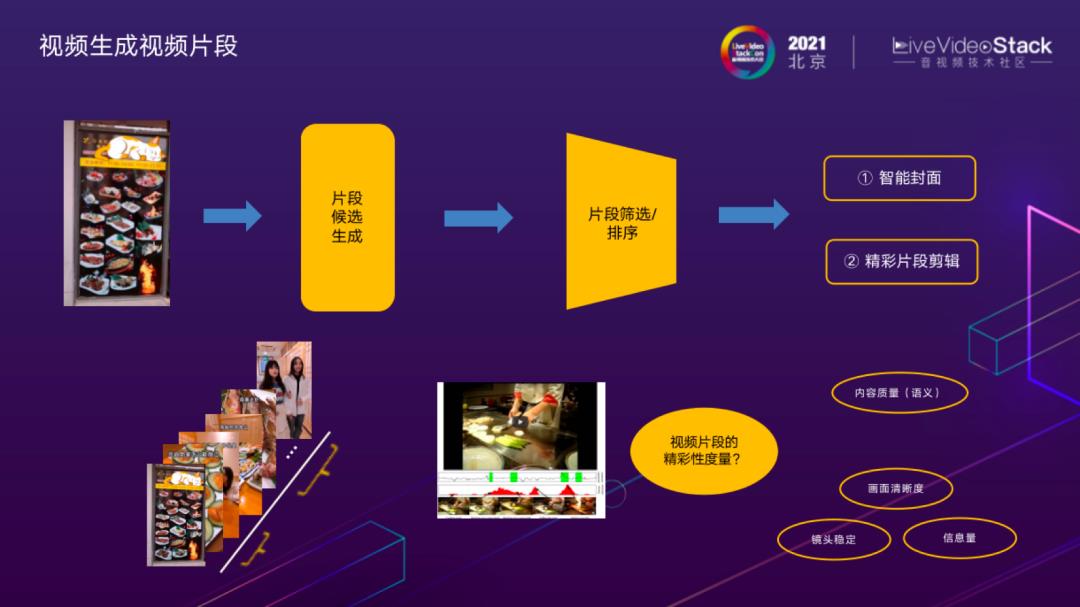
视频生成视频片段应用,主要是将长视频切分并优选出若干片更精彩、符合用户预期的内容作展示。从算法上阶段划分主要是片段生成和片段筛选排序。片段生成部分,通过时序切分算法,获取镜头片段、关键帧。片段排序是比较关键的技术,决定了视频优先顺序。这是比较困难的一部分,有几个维度:通用质量维度,包含清晰度,美学分等;语义维度,例如:在美食视频中,菜品成品展示,制作过程等通常是比较精彩的片段。语义维度的理解主要是采用前面介绍的内容理解模型来支持。
智能封面与精彩片段

这种情况下我们做了两种应用场景。一是智能动态封面,主要基于通用基础质量优选:清晰度更高,有动态信息量,无闪烁卡顿的视频片段,相比默认片段的效果会更好。

2.2.4
视频像素级编辑处理——菜品视频特效

视频像素级编辑处理方面,这里展示了一个基于视频物体分割(VOS,Video Object Segmentation)技术的菜品创意特效。背后的关键技术,是美团自研的高效语义分割方法。

像素级编辑处理最重要技术之一是语义分割,在应用场景面临的主要技术挑战是既要保证分割模型时效性,也要保证分辨率,保持高频细节信息。我们对于经典的BiSeNet方法做出了进一步改进,提出了基于细节引导的高效语义分割方法。
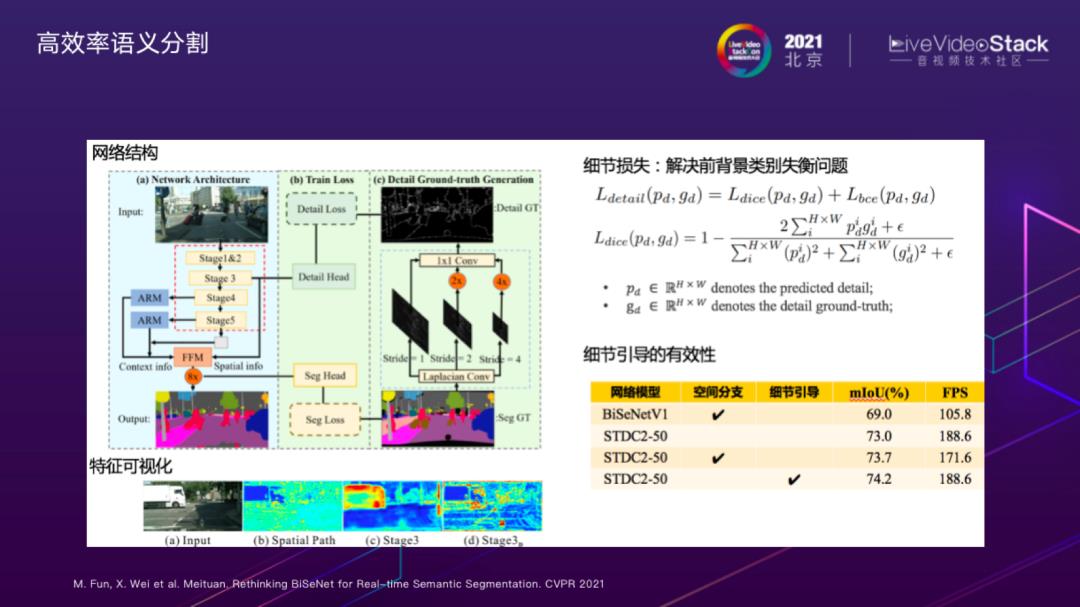
具体的做法如网络结构所示,左边浅蓝色部分是网络的推理框架,沿用了BiSeNet Context分支的设计,Context分支的主干选用了我们自研的主干STDCNet。与BiSeNet不同的是,我们对Stage3进行一个细节引导的训练, 如右边的浅绿色部分所示,引导Stage3学习细节特征;浅绿色部分只参与训练,不参与模型推理,因此不会造成额外的时间消耗。首先对于分割的Ground Truth,我们通过不同步长的Laplacian卷积,获取一个富集图像边缘和角点信息的细节真值;之后通过细节真值和设计的细节Loss来引导Stage3的浅层特征学习细节特征;
由于图像的细节真值前后背景分布严重不均衡,因此我们采用的是DICE loss和BCE loss联合训练的方式;为了验证细节引导的有效性,我们做了这个实验,从特征可视化的结果中可以看出我们多尺度获取的的细节真值对网络进行细节引导能获得最好的结果,细节信息引导对模型的性能也有提升。

效果方面,通过对比可以看出我们的方法,对于分割细节的高频信息保持具有优势。
03
总 结 展 望

最后简单总结展望。

本次主要分享了美团在视频标签、视频方面与剪辑、视频细粒度像素级编,通过与业务场景的结合期望为商家和用户提供更加智能的信息展示和获取方式。
展望未来,短视频在美团丰富的业务场景,包括本地生活服务、零售电商,都会发挥更大的潜在价值。
在视频理解技术方面,多模态自监督训练,对于缓解标注数据依赖,提升模型在复杂业务场景的泛化性能方面非常有价值,我们也在做一些尝试。
以上就是我本次分享的全部内容,谢谢!
扫描图中二维码或点击阅读原文
了解大会更多信息

喜欢我们的内容就点个“在看”吧!

以上是关于短视频内容理解与生成技术在美团的创新实践的主要内容,如果未能解决你的问题,请参考以下文章