Linux文本处理命令的Sort命令
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux文本处理命令的Sort命令相关的知识,希望对你有一定的参考价值。
参考技术Asort命令的功能是对文件中的各行进行排序。sort命令有许多非常实用的选项,这些选项最初是用来对数据库格式的文件内容进行各种排序操作的。实际上,sort命令可以被认为是一个非常强大的数据管理工具,用来管理内容类似数据库记录的文件。
Sort命令将逐行对文件中的内容进行排序,如果两行的首字符相同,该命令将继续比较这两行的下一字符,如果还相同,将继续进行比较。
语法:
sort [选项] 文件
说明:sort命令对指定文件中所有的行进行排序,并将结果显示在标准输出上。如不指定输入文件或使用“- ”,则表示排序内容来自标准输入。
sort排序是根据从输入行抽取的一个或多个关键字进行比较来完成的。排序关键字定义了用来排序的最小的字符序列。缺省情况下以整行为关键字按ASCII字符顺序进行排序。
改变缺省设置的选项主要有:
- m 若给定文件已排好序,合并文件。
- c 检查给定文件是否已排好序,如果它们没有都排好序,则打印一个出错信息,并以状态值1退出。
- u 对排序后认为相同的行只留其中一行。
- o 输出文件 将排序输出写到输出文件中而不是标准输出,如果输出文件是输入文件之一,sort先将该文件的内容写入一个临时文件,然后再排序和写输出结果。
改变缺省排序规则的选项主要有:
- d 按字典顺序排序,比较时仅字母、数字、空格和制表符有意义。
- f 将小写字母与大写字母同等对待。
- I 忽略非打印字符。
- M 作为月份比较:“JAN”<“FEB” p>
- r 按逆序输出排序结果。
+posl - pos2 指定一个或几个字段作为排序关键字,字段位置从posl开始,到pos2为止(包括posl,不包括pos2)。如不指定pos2,则关键字为从posl到行尾。字段和字符的位置从0开始。
- b 在每行中寻找排序关键字时忽略前导的空白(空格和制表符)。
- t separator 指定字符separator作为字段分隔符。
下面通过几个例子来讲述sort的使用。
用sort命令对text文件中各行排序后输出其结果。请注意,在原文件的第二、三行上的第一个单词完全相同,该命令将从它们的第二个单词vegetables与fruit的首字符处继续进行比较。
$ cat text
vegetable soup
fresh vegetables
fresh fruit
lowfat milk
$ sort text
fresh fruit
fresh vegetables
lowfat milk
vegetable soup
用户可以保存排序后的文件内容,或把排序后的文件内容输出至打印机。下例中用户把排序后的文件内容保存到名为result的文件中。
$ sort text>result
以第2个字段作为排序关键字对文件example的内容进行排序。
$ sort +1-2 example
对于file1和file2文件内容反向排序,结果放在outfile中,利用第2个字段的第一个字符作为排序关键字。
$ sort -r -o outfile +1.0 -1.1 example
sort排序常用于在管道中与其他命令连用,组合完成比较复杂的功能,如利用管道将当前工作目录中的文件送给sort进行排序,排序关键字是第6个至第8个字段。
$ ls - l | sort +5 - 7
sort命令也可以对标准输入进行操作。例如,如果您想把几个文件文本行合并,并对合并后的文本行进行排序,您可以首先用命令cat把多个文件合并,然后用管道操作把合并后的文本行输入给命令sort,sort命令将输出这些合并及排序后的文本行。在下面的例子中,文件veglist与文件fruitlist的文本行经过合并与排序后被保存到文件clist中。
$ cat veglist fruitlist | sort > clist
Linux基础之sort命令
sort命令用于将文本文件内容加以排序
sort可以针对文本文件内容,以行为单位来排序。
参数:
-b:忽略每行前面开始出现的空格字符
-c:检查文件是否已经按照顺序排序
-d:排序时,处理英文字母、数字及空格字符外,忽略其它字符。
-f:排序时,将小写字母视为大写字母
-i:排序时,除了040至176之间的ASCII字符外
-m:将几个排序好的文件进行合并
-M:将前面三个字母依照月份的缩写进行排序
-n:依照数值大小进行排序
-o<输出文件>:将排序后的结果存入指定文件
-r:以相反的顺序来排序
-t<分割字符>:指定排序时所用的分隔符
+<起始栏位>-<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位
--help 显示帮助。
实例:
1.以ASCII顺序排序文件test1sort test1
2.忽略文件相同行
sort -u test1
或
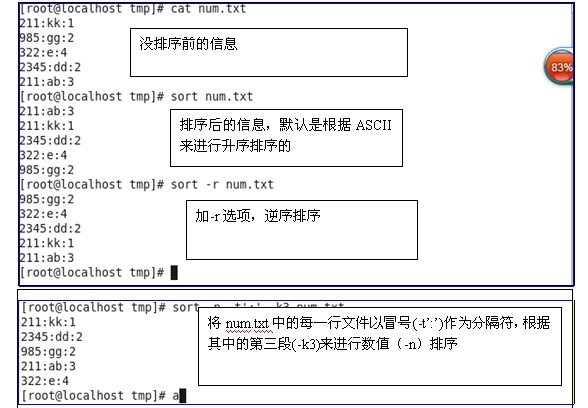
uniq test13.sort -n -r -k -t的使用
先查看一个文件sort.txt
cat sort.txt
AAA:BB:CC
aaa:30:1.6
ccc:50:3.3
ddd:20:4.2
bbb:10:2.5
eee:40:5.4
eee:60:5.1#将BB列按照数字从小到大顺序排列:
sort -nk 2 -t: sort.txt
AAA:BB:CC
bbb:10:2.5
ddd:20:4.2
aaa:30:1.6
eee:40:5.4
ccc:50:3.3
eee:60:5.1#将CC列数字从大到小顺序排列:
sort -nrk 3 -t: sort.txt
eee:40:5.4
eee:60:5.1
ddd:20:4.2
ccc:50:3.3
bbb:10:2.5
aaa:30:1.6
AAA:BB:CC-n是按照数字大小排序,-r是以相反顺序,-k是指定需要爱排序的栏位,-t指定栏位分隔符为冒号
-k选项的具体语法格式:
-k选项的语法格式:
FStart.CStart Modifie,FEnd.CEnd Modifier
-------Start--------,-------End--------
FStart.CStart 选项 , FEnd.CEnd 选项这个语法格式可以被其中的逗号,分为两大部分,Start部分和End部分。Start部分也由三部分组成,其中的Modifier部分就是我们之前说过的类似n和r的选项部分。我们重点说说Start部分的FStart和C.Start。C.Start也是可以省略的,省略的话就表示从本域的开头部分开始。FStart.CStart,其中FStart就是表示使用的域,而CStart则表示在FStart域中从第几个字符开始算“排序首字符”。同理,在End部分中,你可以设定FEnd.CEnd,如果你省略.CEnd,则表示结尾到“域尾”,即本域的最后一个字符。或者,如果你将CEnd设定为0(零),也是表示结尾到“域尾”。
1.从公司英文名称的第二个字母开始进行排序:
sort -t ‘ ‘ -k 1.2 book.txt ##以空格为分隔符
baidu 100 5000
sohu 100 4500
google 110 5000
guge 50 3000使用k 1.2表示第一个域的第二个字符开始到本域的最后一个字符为止的字符串进行排序。sohu与google第二个字符相同,所以按照第三个字符来对这两字符谁前谁后排序。
2.只针对公司英文名称的第二个字母进行排序,如果相同的按照员工工资进行降序排序: sort -t ‘ ‘ -k 1.2,1.2 -nrk 3,3 book.txt
由于只针对1.2进行排序,所以这里用1.2,1.2来表示
以上是关于Linux文本处理命令的Sort命令的主要内容,如果未能解决你的问题,请参考以下文章