scikit-learn : 线性回归,多元回归,多项式回归
Posted 搬砖小工053
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scikit-learn : 线性回归,多元回归,多项式回归相关的知识,希望对你有一定的参考价值。
匹萨的直径与价格的数据
%matplotlib inline
import matplotlib.pyplot as plt
def runplt():
plt.figure()
plt.title(u'diameter-cost curver')
plt.xlabel(u'diameter')
plt.ylabel(u'cost')
plt.axis([0, 25, 0, 25])
plt.grid(True)
return plt
plt = runplt()
X = [[6], [8], [10], [14], [18]]
y = [[7], [9], [13], [17.5], [18]]
plt.plot(X, y, 'k.')
plt.show()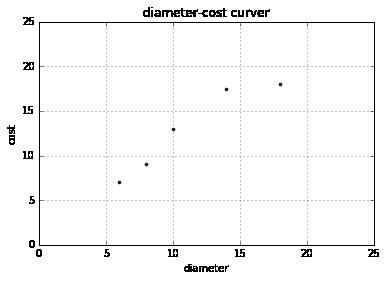
训练模型
from sklearn.linear_model import LinearRegression
import numpy as np
# 创建并拟合模型
model = LinearRegression()
model.fit(X, y)
print('预测一张12英寸匹萨价格:$%.2f' % model.predict(np.array([12]).reshape(-1, 1))[0])预测一张12英寸匹萨价格:$13.68
一元线性回归假设解释变量和响应变量之间存在线性关系;这个线性模型所构成的空间是一个超平面(hyperplane)。
超平面是n维欧氏空间中余维度等于一的线性子空间,如平面中的直线、空间中的平面等,总比包含它的空间少一维。
在一元线性回归中,一个维度是响应变量,另一个维度是解释变量,总共两维。因此,其超平面只有一维,就是一条线。
上述代码中sklearn.linear_model.LinearRegression类是一个估计器(estimator)。估计器依据观测值来预测结果。在scikit-learn里面,所有的估计器都带有:
- fit()
- predict()
fit()用来分析模型参数,predict()是通过fit()算出的模型参数构成的模型,对解释变量进行预测获得的值。
因为所有的估计器都有这两种方法,所有scikit-learn很容易实验不同的模型。
一元线性回归模型:
y=α+βx
一元线性回归拟合模型的参数估计常用方法是:
- 普通最小二乘法(ordinary least squares )
- 线性最小二乘法(linear least squares)
首先,我们定义出拟合成本函数,然后对参数进行数理统计。
plt = runplt()
plt.plot(X, y, 'k.')
X2 = [[0], [10], [14], [25]]
model = LinearRegression()
model.fit(X, y)
y2 = model.predict(X2)
plt.plot(X, y, 'k.')
plt.plot(X2, y2, 'g-')
plt.show()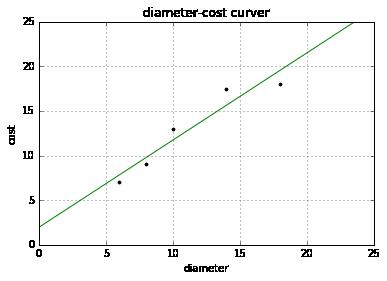
plt = runplt()
plt.plot(X, y, 'k.')
y3 = [14.25, 14.25, 14.25, 14.25]
y4 = y2 * 0.5 + 5
model.fit(X[1:-1], y[1:-1])
y5 = model.predict(X2)
plt.plot(X, y, 'k.')
plt.plot(X2, y2, 'g-.')
plt.plot(X2, y3, 'r-.')
plt.plot(X2, y4, 'y-.')
plt.plot(X2, y5, 'o-')
plt.show()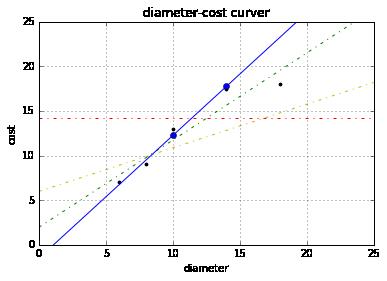
成本函数(cost function)也叫损失函数(loss function),用来定义模型与观测值的误差。模型预测的价格与训练集数据的差异称为残差(residuals)或训练误差(training errors)。后面我们会用模型计算测试集,那时模型预测的价格与测试集数据的差异称为预测误差(prediction errors)或训练误差(test errors)。
模型的残差是训练样本点与线性回归模型的纵向距离,如下图所示:
plt = runplt()
plt.plot(X, y, 'k.')
X2 = [[0], [10], [14], [25]]
model = LinearRegression()
model.fit(X, y)
y2 = model.predict(X2)
plt.plot(X, y, 'k.')
plt.plot(X2, y2, 'g-')
# 残差预测值
yr = model.predict(X)
for idx, x in enumerate(X):
plt.plot([x, x], [y[idx], yr[idx]], 'r-')
plt.show()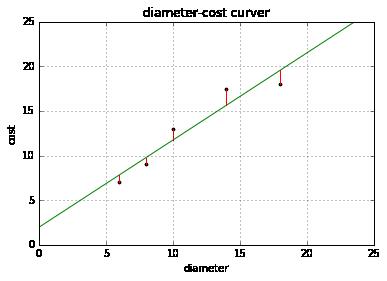
我们可以通过残差之和最小化实现最佳拟合,也就是说模型预测的值与训练集的数据最接近就是最佳拟合。对模型的拟合度进行评估的函数称为残差平方和(residual sum of squares)成本函数。就是让所有训练数据与模型的残差的平方之和最小化,如下所示:
SSres=∑i=1n(yi−f(xi))2
其中, yi 是观测值, f(xi)f(xi) 是预测值。
import numpy as np
print('残差平方和: %.2f' % np.mean((model.predict(X) - y) ** 2))残差平方和: 1.75
解一元线性回归的最小二乘法
通过成本函数最小化获得参数,我们先求相关系数 ββ 。按照频率论的观点,我们首先需要计算 xx 的方差和 xx 与 yy 的协方差。
方差是用来衡量样本分散程度的。如果样本全部相等,那么方差为0。方差越小,表示样本越集中,反正则样本越分散。方差计算公式如下:
Numpy里面有var方法可以直接计算方差,ddof参数是贝塞尔(无偏估计)校正系数(Bessel’s correction),设置为1,可得样本方差无偏估计量。
print(np.var([6, 8, 10, 14, 18], ddof=1))23.2
协方差表示两个变量的总体的变化趋势。如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。 如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。如果两个变量不相关,则协方差为0,变量线性无关不表示一定没有其他相关性。协方差公式如下:
cov(x,y)=∑ni=1(xi−x¯)(yi−y¯)n−1
其中,
x¯
是直径
x
的均值,
import numpy as np
print(np.cov([6, 8, 10, 14, 18], [7, 9, 13, 17.5, 18])[0][1])22.65
现在有了方差和协方差,就可以计算相关系统 β 了。
β=cov(x,y)var(x)
算出 β 后,我们就可以计算 α 了:
α=y¯−βx¯
将前面的数据带入公式就可以求出 α 了:
α=12.9−0.9762931×11.2=1.9655
模型评估
前面我们用学习算法对训练集进行估计,得出了模型的参数。有些度量方法可以用来评估预测效果,我们用R方(r-squared)评估匹萨价格预测的效果。R方也叫确定系数(coefficient of determination),表示模型对现实数据拟合的程度。计算R方的方法有几种。一元线性回归中R方等于皮尔逊积矩相关系数(Pearson product moment correlation coefficient或Pearson’s r)的平方。种方法计算的R方一定介于0~1之间的正数。其他计算方法,包括scikit-learn中的方法,不是用皮尔逊积矩相关系数的平方计算的,因此当模型拟合效果很差的时候R方会是负值。下面我们用scikit-learn方法来计算R方。