FlinkCheckpoint 机制和状态恢复
Posted 九师兄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FlinkCheckpoint 机制和状态恢复相关的知识,希望对你有一定的参考价值。

1.概述
转载:Flink 源码阅读笔记(11)- Checkpoint 机制和状态恢复
在上一篇文章中,我们对 Flink 状态管理相关的代码逻辑进行了分析,但为了实现任务的故障恢复以及数据一致性的效果,还需要借助于检查点(Checkpoint)机制。
简单地说,Checkpoint 是一种分布式快照:在某一时刻,对一个 Flink 作业所有的 task 做一个快照(snapshot),并且将快照保存在 memory / file system 等存储系统中。这样,在任务进行故障恢复的时候,就可以还原到任务故障前最近一次检查点的状态,从而保证数据的一致性。当然,为了保证 exactly-once / at-least-once 的特性,还需要数据源支持数据回放。
Flink 的 checkpoint 机制基于 chandy-lamda 算法,具体的实现可以参考 Flink 官方的文档以及 Flink 团队发表的论文 State Management in Apache Flink。这里先做一下概要性的介绍。
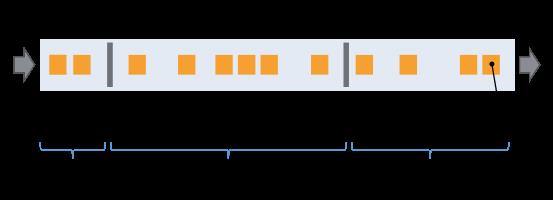
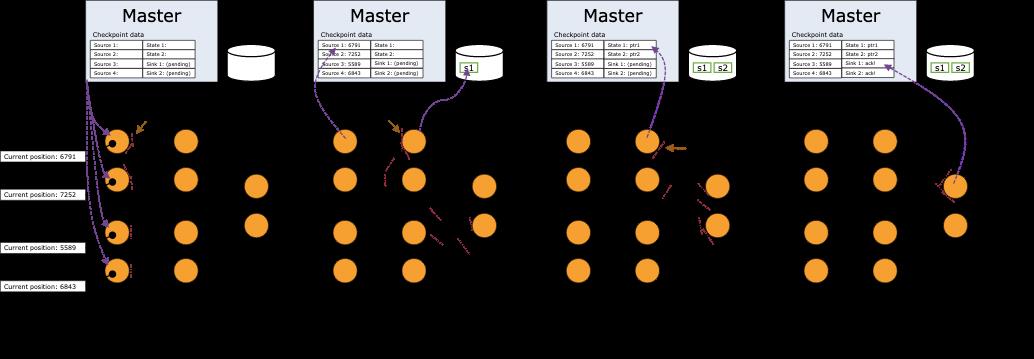
Flink 分布式快照的核心在与 stream barrier,barrier 是一种特殊的标记消息,会和正常的消息记录一起在数据流中向前流动。Checkpoint Coordinator 在需要触发检查点的时候要求数据源向数据流中注入 barrie, barrier 和正常的数据流中的消息一起向前流动,相当于将数据流中的消息切分到了不同的检查点中。当一个 operator 从它所有的 input channel 中都收到了 barrier,则会触发当前 operator 的快照操作,并向其下游 channel 中发射 barrier。当所有的 sink 都反馈完成了快照之后,Checkpoint Coordinator 认为检查点创建完毕。
2.Checkpoint 的发起流程
CheckpointCoordinator 是 Flink 分布式快照流程的“协调者”,它主要负责:
-
发起 checkpoint 触发的消息,并接收不同 task 对 checkpoint 的响应信息(Ack)
-
维护 Ack 中附带的状态句柄(state-handle)的全局视图
在 StreamingJobGraphGenerator 中,生成 JobGraph 之后会调用 configureCheckpointing 方法进行 Checkpoint 相关的配置。
这其中会有三个列表:
List<JobVertexID> triggerVertices
List<JobVertexID> ackVertices
List<JobVertexID> commitVertices
其中, triggerVertices 只包含那些作为 source 的节点,ackVertices 和 commitVertices 均包含所有的节点:
private void configureCheckpointing()
// .........
// collect the vertices that receive "trigger checkpoint" messages.
// currently, these are all the sources
List<JobVertexID> triggerVertices = new ArrayList<>();
// collect the vertices that need to acknowledge the checkpoint
// currently, these are all vertices
List<JobVertexID> ackVertices = new ArrayList<>(jobVertices.size());
// collect the vertices that receive "commit checkpoint" messages
// currently, these are all vertices
List<JobVertexID> commitVertices = new ArrayList<>(jobVertices.size());
for (JobVertex vertex : jobVertices.values())
if (vertex.isInputVertex())
triggerVertices.add(vertex.getID());
commitVertices.add(vertex.getID());
ackVertices.add(vertex.getID());
//...............
在 ExecutionGraphBuilder#buildGraph 中,如果作业开启了 checkpoint,则会调用 ExecutionGraph.enableCheckpointing() 方法, 这里会创建 CheckpointCoordinator 对象,并注册一个作业状态的监听 CheckpointCoordinatorDeActivator, CheckpointCoordinatorDeActivator 会在作业状态发生改变时得到通知。
class ExecutionGraph
public void enableCheckpointing(
long interval,
long checkpointTimeout,
long minPauseBetweenCheckpoints,
int maxConcurrentCheckpoints,
CheckpointRetentionPolicy retentionPolicy,
List<ExecutionJobVertex> verticesToTrigger,
List<ExecutionJobVertex> verticesToWaitFor,
List<ExecutionJobVertex> verticesToCommitTo,
List<MasterTriggerRestoreHook<?>> masterHooks,
CheckpointIDCounter checkpointIDCounter,
CompletedCheckpointStore checkpointStore,
StateBackend checkpointStateBackend,
CheckpointStatsTracker statsTracker)
// simple sanity checks
ExecutionVertex[] tasksToTrigger = collectExecutionVertices(verticesToTrigger);
ExecutionVertex[] tasksToWaitFor = collectExecutionVertices(verticesToWaitFor);
ExecutionVertex[] tasksToCommitTo = collectExecutionVertices(verticesToCommitTo);
// create the coordinator that triggers and commits checkpoints and holds the state
checkpointCoordinator = new CheckpointCoordinator(
jobInformation.getJobId(),
interval,
checkpointTimeout,
minPauseBetweenCheckpoints,
maxConcurrentCheckpoints,
retentionPolicy,
tasksToTrigger,
tasksToWaitFor,
tasksToCommitTo,
checkpointIDCounter,
checkpointStore,
checkpointStateBackend,
ioExecutor,
SharedStateRegistry.DEFAULT_FACTORY);
// register the master hooks on the checkpoint coordinator
for (MasterTriggerRestoreHook<?> hook : masterHooks)
if (!checkpointCoordinator.addMasterHook(hook))
LOG.warn("Trying to register multiple checkpoint hooks with the name: ", hook.getIdentifier());
checkpointCoordinator.setCheckpointStatsTracker(checkpointStatsTracker);
// interval of max long value indicates disable periodic checkpoint,
// the CheckpointActivatorDeactivator should be created only if the interval is not max value
if (interval != Long.MAX_VALUE)
// the periodic checkpoint scheduler is activated and deactivated as a result of
// job status changes (running -> on, all other states -> off)
registerJobStatusListener(checkpointCoordinator.createActivatorDeactivator());
当状态变为 RUNNING 时,CheckpointCoordinatorDeActivator会得到通知,并且通过 CheckpointCoordinator.startCheckpointScheduler 启动 checkpoint 的定时器。
/**
* This actor listens to changes in the JobStatus and activates or deactivates the periodic
* checkpoint scheduler.
*
* CheckpointCoordinatorDeActivator是actor的实现类,监听JobStatus的变化,启动和停止周期性的checkpoint调度任务。
* actor的实现类,监听JobStatus的变化,激活和取消周期性的checkpoint调度任务。
*
* Job 状态监听器:用于开启和关闭 CheckpointCoordinator
*/
public class CheckpointCoordinatorDeActivator implements JobStatusListener
private final CheckpointCoordinator coordinator;
public CheckpointCoordinatorDeActivator(CheckpointCoordinator coordinator)
this.coordinator = checkNotNull(coordinator);
@Override
public void jobStatusChanges(
JobID jobId, JobStatus newJobStatus, long timestamp, Throwable error)
if (newJobStatus == JobStatus.RUNNING)
// start the checkpoint scheduler
// todo: 启动检查点调度任务,一旦监听到JobStatus变为RUNNING,就会启动定时任务
coordinator.startCheckpointScheduler();
else
// anything else should stop the trigger for now
// todo:停止检查点调度任务
coordinator.stopCheckpointScheduler();
定时任务被封装为 ScheduledTrigger, 运行时会调用 CheckpointCoordinator.triggerCheckpoint() 触发一次 checkpoint。CheckpointCoordinator.triggerCheckpoint 方法代码逻辑很长,概括地说,包括以下几个步骤:
-
检查是否可以触发 checkpoint,包括是否需要强制进行 checkpoint,当前正在排队的并发 checkpoint 的数目是否超过阈值,距离上一次成功 checkpoint 的间隔时间是否过小等,如果这些条件不满足,则当前检查点的触发请求不会执行
-
检查是否所有需要触发 checkpoint 的 Execution 都是 RUNNING 状态
-
生成此次
checkpoint的checkpointID(id 是严格自增的),并初始化CheckpointStorageLocation,CheckpointStorageLocation是此次checkpoint存储位置的抽象,通过CheckpointStorage.initializeLocationForCheckpoint()创建(CheckpointStorage 目前有两个具体实现,分别为FsCheckpointStorage 和 MemoryBackendCheckpointStorage),CheckpointStorage 则是从 StateBackend 中创建 -
生成
PendingCheckpoint,这表示一个处于中间状态的 checkpoint,并保存在 checkpointId -> PendingCheckpoint 这样的映射关系中 -
注册一个调度任务,在 checkpoint 超时后取消此次 checkpoint,并重新触发一次新的 checkpoint
-
调用 Execution.triggerCheckpoint() 方法向所有需要 trigger 的 task 发起 checkpoint 请求
savepoint 和 checkpoint 的处理逻辑基本一致,只是 savepoint 是强制触发的,需要调用 Execution.triggerSynchronousSavepoint() 进行触发。
在CheckpointCoordinator 内部也有三个列表:
ExecutionVertex[] tasksToTrigger;
ExecutionVertex[] tasksToWaitFor;
ExecutionVertex[] tasksToCommitTo;
这就对应了前面 JobGraph 中的三个列表,在触发 checkpoint 的时候,只有作为 source 的 Execution 会调用 Execution.triggerCheckpoint() 方法。会通过 RPC 调用通知对应的 RpcTaskManagerGateway 调用 triggerCheckpoint。
3.Checkpoint 的执行
3.1 barrier 的流动
CheckpointCoordinator 发出触发 checkpoint 的消息,最终通过 RPC 调用 TaskExecutorGateway.triggerCheckpoint,即请求执行 TaskExecutor.triggerCheckpoin()。 因为一个 TaskExecutor 中可能有多个 Task 正在运行,因而要根据触发 checkpoint 的 ExecutionAttemptID 找到对应的 Task,然后调用 Task.triggerCheckpointBarrier() 方法。只有作为 source 的 Task 才会触发 triggerCheckpointBarrier() 方法的调用。
在 Task 中,checkpoint 的触发被封装为一个异步任务执行,
class Task
public void triggerCheckpointBarrier(
final long checkpointID,
final long checkpointTimestamp,
final CheckpointOptions checkpointOptions,
final boolean advanceToEndOfEventTime)
......
if (executionState == ExecutionState.RUNNING && invokable != null)
// build a local closure
final String taskName = taskNameWithSubtask;
final SafetyNetCloseableRegistry safetyNetCloseableRegistry =
FileSystemSafetyNet.getSafetyNetCloseableRegistryForThread();
Runnable runnable = new Runnable()
@Override
public void run()
// set safety net from the task's context for checkpointing thread
FileSystemSafetyNet.setSafetyNetCloseableRegistryForThread(safetyNetCloseableRegistry);
try
//真正的调用逻辑
boolean success = invokable.triggerCheckpoint(checkpointMetaData, checkpointOptions, advanceToEndOfEventTime);
if (!success)
checkpointResponder.declineCheckpoint(
getJobID(), getExecutionId(), checkpointID,
new CheckpointDeclineTaskNotReadyException(taskName));
catch (Throwable t)
if (getExecutionState() == ExecutionState.RUNNING)
failExternally(new Exception(
"Error while triggering checkpoint " + checkpointID + " for " +
taskNameWithSubtask, t));
else
LOG.debug("Encountered error while triggering checkpoint for " +
" () while being not in state running.", checkpointID,
taskNameWithSubtask, executionId, t);
finally
FileSystemSafetyNet.setSafetyNetCloseableRegistryForThread(null);
;
//异步执行
executeAsyncCallRunnable(
runnable,
String.format("Checkpoint Trigger for %s (%s).", taskNameWithSubtask, executionId),
checkpointOptions.getCheckpointType().isSynchronous());
else
// send back a message that we did not do the checkpoint
checkpointResponder.declineCheckpoint(jobId, executionId, checkpointID,
new CheckpointDeclineTaskNotReadyException(taskNameWithSubtask));
Task 执行 checkpoint 的真正逻辑被封装在 AbstractInvokable.triggerCheckpoint(...) 中,AbstractInvokable 中有两个触发 checkpoint 的方法:
triggerCheckpoint
triggerCheckpointOnBarrier
其中 triggerCheckpoint 是触发 checkpoint 的源头,会向下游注入 CheckpointBarrier;而下游的其他任务在收到 CheckpointBarrier 后调用 triggerCheckpointOnBarrier 方法。这两个方法的具体实现有一些细微的差异,但主要的逻辑是一致的,在 StreamTask.performCheckpoint() 方法中: 1)先向下游发送 barrier, 2)存储检查点快照。
一旦 StreamTask.triggerCheckpoint() 或 StreamTask.triggerCheckpointOnBarrier() 被调用,就会通过 OperatorChain.broadcastCheckpointBarrier() 向下游发送 barrier:
class OperatorChain
public void broadcastCheckpointBarrier(long id, long timestamp, CheckpointOptions checkpointOptions) throws IOException
//创建一个 CheckpointBarrier
CheckpointBarrier barrier = new CheckpointBarrier(id, timestamp, checkpointOptions);
//向所有的下游发送
for (RecordWriterOutput<?> streamOutput : streamOutputs)
streamOutput.broadcastEvent(barrier);
我们已经知道,每一个 Task 的通过 InputGate 消费上游 Task 产生的数据,而实际上在 StreamInputProcessor 和 StreamTwoInputProcessor 中会创建 CheckpointBarrierHandler, CheckpointBarrierHandler 是对 InputGate 的一层封装,增加了对 CheckpointBarrier 等事件的处理。CheckpointBarrierHandler 有两个具体的实现,即 BarrierTracker 和 BarrierBuffer,分别对应 AT_LEAST_ONCE 和 EXACTLY_ONCE 这两种模式。
StreamInputProcessor 和 StreamTwoInputProcessor 循环调用 CheckpointBarrierHandler.getNextNonBlocked() 获取新数据,因而在 CheckpointBarrierHandler 获得 CheckpointBarrier 后可以及时地进行 checkpoint 相关的操作。
我们先来看一下 AT_LEAST_ONCE 模式下的 BarrierTracker,它仅仅追踪从每一个 input channel 接收到的 barrier,当所有 input channel 的 barrier 都被接收时,就可以触发 checkpoint 了:
public class BarrierTracker implements CheckpointBarrierHandler
@Override
public BufferOrEvent getNextNonBlocked() throws Exception
while (true)
Optional<BufferOrEvent> next = inputGate.getNextBufferOrEvent();
if (!next.isPresent())
// buffer or input exhausted
return null;
BufferOrEvent bufferOrEvent = next.get();
if (bufferOrEvent.isBuffer())
return bufferOrEvent;
else if (bufferOrEvent.getEvent().getClass() == CheckpointBarrier.class)
// 接收到 CheckpointBarrier
processBarrier((CheckpointBarrier) bufferOrEvent.getEvent(), bufferOrEvent.getChannelIndex());
else if (bufferOrEvent.getEvent().getClass() == CancelCheckpointMarker.class)
// 接收到 CancelCheckpointMarker
processCheckpointAbortBarrier((CancelCheckpointMarker) bufferOrEvent.getEvent(), bufferOrEvent.getChannelIndex());
else
// some other event
return bufferOrEvent;
private void processBarrier(CheckpointBarrier receivedBarrier, int channelIndex) throws Exception
final long barrierId = receivedBarrier.getId();
// fast path for single channel trackers
if (totalNumberOfInputChannels == 1)
notifyCheckpoint(barrierId, receivedBarrier.getTimestamp(), receivedBarrier.getCheckpointOptions());
return;
// find the checkpoint barrier in the queue of pending barriers
CheckpointBarrierCount cbc = null;
int pos = 0;
for (CheckpointBarrierCount next : pendingCheckpoints)
if (next.checkpointId == barrierId)
cbc = next;
break;
pos++;
if (cbc != null)
// add one to the count to that barrier and check for completion
int numBarriersNew = cbc.incrementBarrierCount();
if (numBarriersNew == totalNumberOfInputChannels)
// checkpoint can be triggered (or is aborted and all barriers have been seen)
// first, remove this checkpoint and all all prior pending
// checkpoints (which are now subsumed)
// 在当前 barrierId 前面的所有未完成的 checkpoint 都可以丢弃了
for (int i = 0; i <= pos; i++)
pendingCheckpoints.pollFirst();
// notify the listener
if (!cbc.isAborted())
//通知进行 checkpoint
notifyCheckpoint(receivedBarrier.getId(), receivedBarrier.getTimestamp(), receivedBarrier.getCheckpointOptions());
else
// first barrier for that checkpoint ID
// add it only if it is newer than the latest checkpoint.
// if it is not newer than the latest checkpoint ID, then there cannot be a
// successful checkpoint for that ID anyways
if (barrierId > latestPendingCheckpointID)
latestPendingCheckpointID = barrierId;
pendingCheckpoints.addLast(new CheckpointBarrierCount(barrierId));
// make sure we do not track too many checkpoints
if (pendingCheckpoints.size() > MAX_CHECKPOINTS_TO_TRACK)
pendingCheckpoints.pollFirst();
而对于 EXACTLY_ONCE 模式下的 BarrierBuffer,它除了要追踪每一个 input channel 接收到的 barrier 之外,在接收到所有的 barrier 之前,先收到 barrier 的 channel 要进入阻塞状态。当然为了避免进入“反压”状态,BarrierBuffer 会继续接收数据,但会对接收到的数据进行缓存,直到所有的 barrier 都到达。
public class BarrierBuffer implements CheckpointBarrierHandler
/** To utility to write blocked data to a file channel. */
private final BufferBlocker bufferBlocker; //用于缓存被阻塞的channel接收的数据
/**
* The sequence of buffers/events that has been unblocked and must now be consumed before
* requesting further data from the input gate.
*/
private BufferOrEventSequence currentBuffered; //当前缓存的数据
@Override
public BufferOrEvent getNextNonBlocked() throws Exception
while (true)
// process buffered BufferOrEvents before grabbing new ones
// 先处理缓存的数据
Optional<BufferOrEvent> next;
if (currentBuffered == null)
next = inputGate.getNextBufferOrEvent();
else
next = Optional.ofNullable(currentBuffered.getNext());
if (!next.isPresent())
completeBufferedSequence();
return getNextNonBlocked();
if (!next.isPresent())
if (!endOfStream)
// end of input stream. stream continues with the buffered data
endOfStream = true;
releaseBlocksAndResetBarriers();
return getNextNonBlocked();
else
// final end of both input and buffered data
return null;
BufferOrEvent bufferOrEvent = next.get();
if (isBlocked(bufferOrEvent.getChannelIndex()))
// 如果当前 channel 是 block 状态,先写入缓存
// if the channel is blocked, we just store the BufferOrEvent
bufferBlocker.add(bufferOrEvent);
checkSizeLimit();
else if (bufferOrEvent.isBuffer())
return bufferOrEvent;
else if (bufferOrEvent.getEvent().getClass() == CheckpointBarrier.class) 以上是关于FlinkCheckpoint 机制和状态恢复的主要内容,如果未能解决你的问题,请参考以下文章