SpringBoot整合Elasticsearch之索引,映射,文档,搜索的基本操作案例分析
Posted 活跃的咸鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SpringBoot整合Elasticsearch之索引,映射,文档,搜索的基本操作案例分析相关的知识,希望对你有一定的参考价值。
索引,映射,文档,DSL增删改查
一)环境准备
1. ES版本:7.12.1
2. SpringBoot版本:2.5.8
<parent>
<artifactId>spring-boot-parent</artifactId>
<groupId>org.springframework.boot</groupId>
<version>2.5.8</version>
</parent>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
二)ES的基本介绍
1. Elasticsearch 是什么
Elaticsearch,简称为 ES,ES 是一个开源的高扩展的分布式全文搜索引擎,是整个 Elastic Stack 技术栈的核心。它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。

The Elastic Stack, 包括 Elasticsearch、Kibana、Beats 和 Logstash(也称为 ELK Stack)。能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。
2. Eelasticsearch的作用
Elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容。
- 在GitHub搜索代码
- 用于搜索引擎中搜索内容
- 各大电商网站搜索商品
- 打车软件搜索附近的车辆
3. Elasticsearch,Solr和Lucene三者之间的关系
目前市面上流行的搜索引擎软件,主流的就两款:Elasticsearch 和 Solr,这两款都是基于 Lucene 搭建的,可以独立部署启动的搜索引擎服务软件。
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。
Elasticsearch和Solr对比
| 特征 | Solr/SolrCloud | Elasticsearch |
|---|---|---|
| 社区和开发者 | Apache软件基金和社区支持 | 单一商业实体及其员工 |
| 节点发现 | Apache Zookeeper.在大量项目中成熟且经过实战测试 | Zen内置于Elasticsearch本身,需要专用的主节点才能进行裂脑保护 |
| 碎片放置 | 本质上是静态,需要手动工作来迁移分片,从Solr 7开始- AutoscalingAPI允许一些动态操作 | 动态,可以根据群集状态按需移动分片 |
| 高速缓存 | 全局,每个段更改无效 | 每段,更适合动态更改数据 |
| 分析引擎性能 | 非常适合精确计算的静态数据 | 结果的准确性取决于数据放置 |
| 全文搜索功能 | 基于Lucene的语言分析,多建议,拼写检查,丰富的高亮显示支持 | 基于Lucene的语言分析,单一建议API实现, 高亮显示重新计算 |
| DevOps支持 | 尚未完全,但即将到来 | 非常好的API |
| 非平面数据处理 | 嵌套文档和父子支持 | 嵌套和对象类型的自然支持允许几乎无限的嵌套和父-子支持 |
| 查询DSL | JSON (有限),XML (有限)或URL参数 | JSON |
| 机器学习 | 内置-在流聚合之上,专注于逻辑回归和学习排名贡献模块 | 商业功能,专注于异常和异常值以及时间序列数据 |
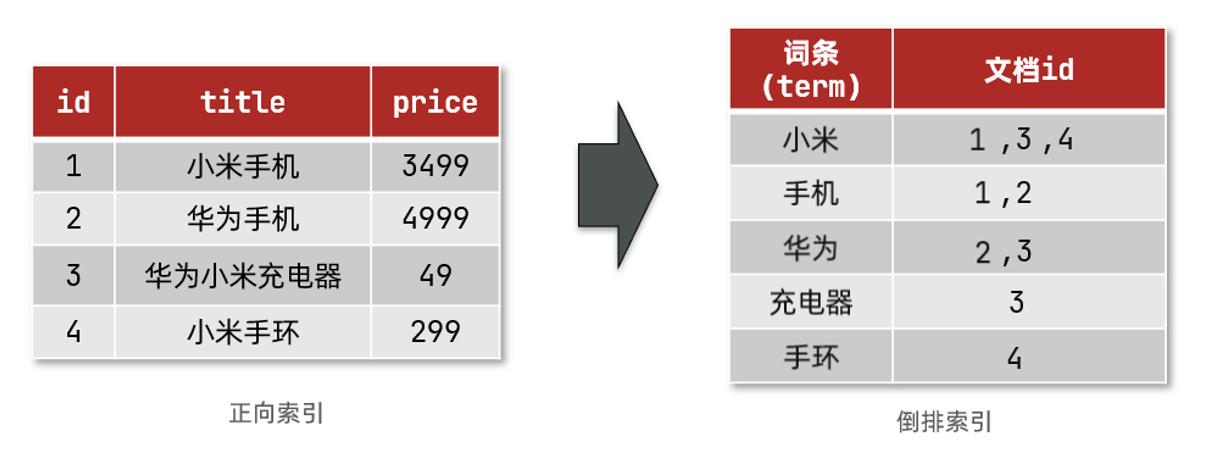
4. Elasticsearch的索引结构–倒排索引
倒排索引的概念是基于mysql这样的正向索引而言的。
正向索引
那么什么是正向索引呢?例如给下表(tb_goods)中的id创建索引:

如果是根据id查询,那么直接走索引,查询速度非常快。
但如果是基于title做模糊查询,只能是逐行扫描数据,流程如下:
1)用户搜索数据,条件是title符合"%手机%"
2)逐行获取数据,比如id为1的数据
3)判断数据中的title是否符合用户搜索条件
4)如果符合则放入结果集,不符合则丢弃。回到步骤1
逐行扫描,也就是全表扫描,随着数据量增加,其查询效率也会越来越低。当数据量达到数百万时,就是一场灾难。
倒排索引
倒排索引中有两个非常重要的概念:
- 文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息。 - 词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
创建倒排索引是对正向索引的一种特殊处理,流程如下:
- 将每一个文档的数据利用算法分词,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引
如图:
倒排索引的搜索流程如下(以搜索"华为手机"为例):
1)用户输入条件"华为手机"进行搜索。
2)对用户输入内容分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档。
如图:

虽然要先查询倒排索引,再查询倒排索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。
正向索引和倒排索引比较
-
正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
-
而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
正向索引:
- 优点:
- 可以给多个字段创建索引
- 根据索引字段搜索、排序速度非常快
- 缺点:
- 根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
倒排索引:
- 优点:
- 根据词条搜索、模糊搜索时,速度非常快
- 缺点:
- 只能给词条创建索引,而不是字段
- 无法根据字段做排序
5. ES中的一些基本概念
elasticsearch中有很多独有的概念,与mysql中略有差别,但也有相似之处。
结点和集群
结点(Node):每个es实例称为一个节点。节点名自动分配,也可以手动配置。
集群(cluster):包含一个或多个启动着es实例的机器群。通常一台机器起一个es实例。同一网络下,集名一样的多个es实例自动组成集群,自动均衡分片等行为。默认集群名为“elasticsearch”。
分片和副本
分片 ( shard ): index数据过大时,将index里面的数据,分为多个shard,分布式的存储在各个服务器上面。可以支持海量数据和高并发,提升性能和吞吐量,充分利用多台机器的cpu。
副本( replica ) : 在分布式环境下,任何一台机器都会随时宕机,如果宕机,index的一个分片没有,导致此index不能搜索。所以,为了保证数据的安全,我们会将每个index的分片经行备份,存储在另外的机器上。保证少数机器宕机es集群仍可以搜索。
能正常提供查询和插入的分片我们叫做主分片(primary shard),其余的我们就管他们叫做备份的分片(replica shard)。
文档和字段
elasticsearch是面向文档(Document) 存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:

而Json文档中往往包含很多的字段(Field),类似于数据库中的列。
索引和映射
索引(Index),就是相同类型的文档的集合。
例如:
- 所有用户文档,就可以组织在一起,称为用户的索引;
- 所有商品的文档,可以组织在一起,称为商品的索引;
- 所有订单的文档,可以组织在一起,称为订单的索引;

因此,我们可以把索引当做是数据库中的表。
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
mysql与elasticsearch比较
我们统一的把mysql与elasticsearch的概念做一下对比:
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
是不是说,我们学习了elasticsearch就不再需要mysql了呢?
并不是如此,两者各自有自己的擅长支出:
-
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
-
Elasticsearch:擅长海量数据的搜索、分析、计算
因此在企业中,往往是两者结合使用:
- 对安全性要求较高的写操作,使用mysql实现
- 对查询性能要求较高的搜索需求,使用elasticsearch实现
- 两者再基于某种方式,实现数据的同步,保证一致性
数据同步思路分析
常见的数据同步方案有三种:
- 同步调用
- 异步通知
- 监听binlog
1.同步调用
方案一:同步调用
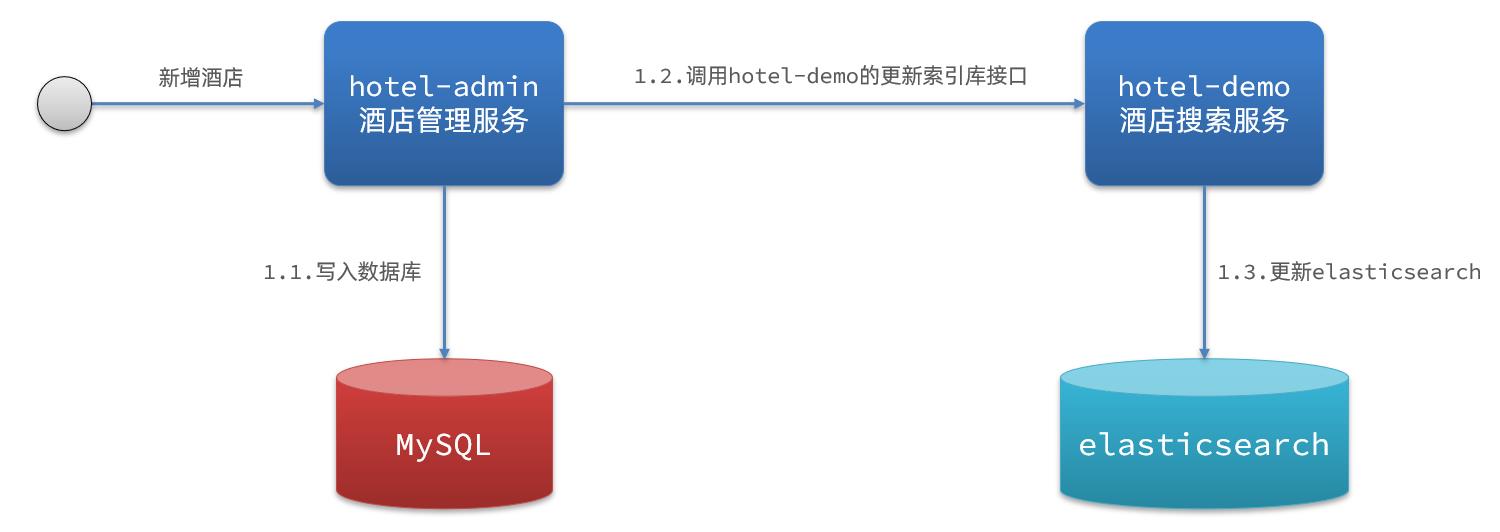
基本步骤如下:
- hotel-demo对外提供接口,用来修改elasticsearch中的数据
- 酒店管理服务在完成数据库操作后,直接调用hotel-demo提供的接口,
2.异步通知
方案二:异步通知

流程如下:
- hotel-admin对mysql数据库数据完成增、删、改后,发送MQ消息
- hotel-demo监听MQ,接收到消息后完成elasticsearch数据修改
3.监听binlog
方案三:监听binlog
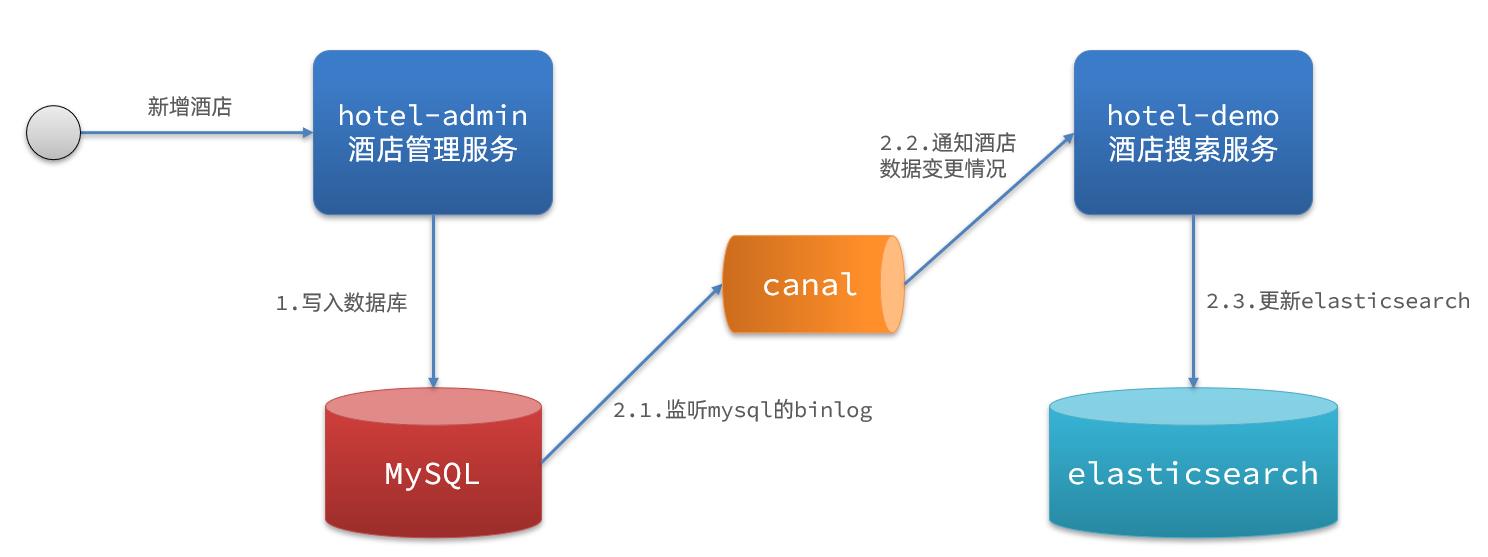
流程如下:
- 给mysql开启binlog功能
- mysql完成增、删、改操作都会记录在binlog中
- hotel-demo基于canal监听binlog变化,实时更新elasticsearch中的内容
4.选择
方式一:同步调用
- 优点:实现简单,粗暴
- 缺点:业务耦合度高
方式二:异步通知
- 优点:低耦合,实现难度一般
- 缺点:依赖mq的可靠性
方式三:监听binlog
- 优点:完全解除服务间耦合
- 缺点:开启binlog增加数据库负担、实现复杂度高
三)ES索引的增删改查
索引库就类似数据库表,mapping映射就类似表的结构。我们要向es中存储数据,必须先创建“库”和“表”。
1. mapping映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- store:是否将数据进行独立存储,默认为 false
原始的文本会存储在_source 里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source 里面提取出来的。当然你也可以独立的存储某个字段,只要设置"store": true 即可,获取独立存储的字段要比从_source 中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置。 - properties:该字段的子字段
2. 索引库的创建
基本语法:
- 请求方式:PUT
- 请求路径:/索引库名,可以自定义
- 请求参数:mapping映射
格式:
PUT /索引库名称
"mappings":
"properties":
"字段名":
"type": "text",
"analyzer": "ik_smart"
,
"字段名2":
"type": "keyword",
"index": "false"
,
"字段名3":
"properties":
"子字段":
"type": "keyword"
,
// ...略
示例:
PUT /xianyu
"mappings":
"properties":
"info":
"type": "text",
"analyzer": "ik_smart"
,
"email":
"type": "keyword",
"index": "falsae"
,
"name":
"properties":
"firstName":
"type": "keyword"
,
// ... 略
RestAPI基本步骤:
//1.创建请求
CreateIndexRequest request=new CreateIndexRequest("hotel");
//2.准备请求参数
request.source(HotelConstants.MAPPING_TEMPLATE, XContentType.JSON);
//3.发送请求
client.indices().create(request, RequestOptions.DEFAULT);
1.同步创建:
//创建索引对象
CreateIndexRequest createIndexRequest = new CreateIndexRequest("itheima_book");
//设置参数
createIndexRequest.settings(Settings.builder().put("number_of_shards", "1").put("number_of_replicas", "0"));
//指定映射1
createIndexRequest.mapping(" \\n" +
" \\t\\"properties\\": \\n" +
" \\"name\\":\\n" +
" \\"type\\":\\"keyword\\"\\n" +
" ,\\n" +
" \\"description\\": \\n" +
" \\"type\\": \\"text\\"\\n" +
" ,\\n" +
" \\"price\\":\\n" +
" \\"type\\":\\"long\\"\\n" +
" ,\\n" +
" \\"pic\\":\\n" +
" \\"type\\":\\"text\\",\\n" +
" \\"index\\":false\\n" +
" \\n" +
" \\t\\n" +
"", XContentType.JSON);
//指定映射2
```
// Map<String, Object> message = new HashMap<>();
// message.put("type", "text");
// Map<String, Object> properties = new HashMap<>();
// properties.put("message", message);
// Map<String, Object> mapping = new HashMap<>();
// mapping.put("properties", properties);
// createIndexRequest.mapping(mapping);
```
//指定映射3
```
// XContentBuilder builder = XContentFactory.jsonBuilder();
// builder.startObject();
//
// builder.startObject("properties");
//
// builder.startObject("message");
//
// builder.field("type", "text");
//
// builder.endObject();
//
// builder.endObject();
//
// builder.endObject();
// createIndexRequest.mapping(builder);
```
//设置别名
createIndexRequest.alias(new Alias("itheima_index_new"));
// 额外参数
//设置超时时间
createIndexRequest.setTimeout(TimeValue.timeValueMinutes(2));
//设置主节点超时时间
createIndexRequest.setMasterTimeout(TimeValue.timeValueMinutes(1));
//在创建索引API返回响应之前等待的活动分片副本的数量,以int形式表示
createIndexRequest.waitForActiveShards(ActiveShardCount.from(2));
createIndexRequest.waitForActiveShards(ActiveShardCount.DEFAULT);
//操作索引的客户端
IndicesClient indices = client.indices();
//执行创建索引库
CreateIndexResponse createIndexResponse = indices.create(createIndexRequest, RequestOptions.DEFAULT);
//得到响应(全部)
boolean acknowledged = createIndexResponse.isAcknowledged();
//得到响应 指示是否在超时前为索引中的每个分片启动了所需数量的碎片副本
boolean shardsAcknowledged = createIndexResponse.isShardsAcknowledged();
System.out.println("!!!!!!!!!!!!!!!!!!!!!!!!!!!" + acknowledged);
System.out.println(shardsAcknowledged);
2.异步创建:
//创建索引对象
CreateIndexRequest createIndexRequest = new CreateIndexRequest("itheima_book2");
//设置参数
createIndexRequest.settings(Settings.builder().put("number_of_shards", "1").put("number_of_replicas", "0"));
//指定映射1
createIndexRequest.mapping(" \\n" +
" \\t\\"properties\\": \\n" +
" \\"name\\":\\n" +
" \\"type\\":\\"keyword\\"\\n" +
" ,\\n" +
" \\"description\\": \\n" +
" \\"type\\": \\"text\\"\\n" +
" ,\\n" +
" \\"price\\":\\n" +
" \\"type\\":\\"long\\"\\n" +
" ,\\n" +
" \\"pic\\":\\n" +
" \\"type\\":\\"text\\",\\n" +
" \\"index\\":false\\n" +
" \\n" +
" \\t\\n" +
"", XContentType.JSON);
//监听方法
ActionListener<CreateIndexResponse> listener =
new ActionListener<CreateIndexResponse>()
@Override
public void onResponse(CreateIndexResponse createIndexResponse)
System.out.println("!!!!!!!!创建索引成功");
System.out.println(createIndexResponse.toString());
@Override
public void onFailure(Exception e)
System.out.println("!!!!!!!!创建索引失败");
e.printStackTrace();
;
//操作索引的客户端
IndicesClient indices = client.indices();
//执行创建索引库
indices.createAsync(createIndexRequest, RequestOptions.DEFAULT, listener);
try
Thread.sleep(5000);
catch (InterruptedException e)
e.printStackTrace();
3.SpringData自动创建
// 可以通过注解@Document @Filed @Setting 来自定义配置
@Document(indexName = "book")
@Data
public class Book
// 必须有 id,这里的 id 是全局唯一的标识,等同于 es 中的"_id"
@Id
private String id;
@Field(type = FieldType.Keyword, analyzer = "ik_max_word",searchAnalyzer= "ik_smart")
private String bookName;
@Field(type = FieldType.Text, analyzer = "ik_max_word",searchAnalyzer= "ik_smart")
private String bookDesc;
@Field(type = FieldType.Double, index = false)
private Double bookPrice;
@Field(type = FieldType.Long, index = false)
private Integer bookNumber;
3. 查询索引库
基本语法:
-
请求方式:GET
-
请求路径:/索引库名
-
请求参数:无
格式:
GET /索引库名
示例:
GET /xianyu
"xianyu"【索引名】:
"aliases"【别名】: ,
"mappings"【映射】: ,
"settings"【设置】:
"index"【设置 - 索引】:
"creation_date"【设置 - 索引 - 创建时间】: "1614265373911",
"number_of_shards"【设置 - 索引 - 主分片数量】: "1",
"number_of_replicas"【设置 - 索引 - 副分片数量】: "1",
"uuid"【设置 - 索引 - 唯一标识】: "eI5wemRERTumxGCc1bAk2A",
"version"【设置 - 索引 - 版本】:
"created": "7080099"
,
"provided_name"【设置 - 索引 - 名称】: "xianyu"
查询所有的索引库
#查询所有的索引库
GET /_cat/indices?v

| 表头 | 含义 |
|---|---|
| health 当前服务器健康状态: | green(集群完整) yellow(单点正常、集群不完整)red(单点不正常) |
| status | 索引打开、关闭状态 |
| index | 索引名 |
| uuid | 索引统一编号 |
| pri | 主分片数量以上是关于SpringBoot整合Elasticsearch之索引,映射,文档,搜索的基本操作案例分析的主要内容,如果未能解决你的问题,请参考以下文章 |