机器翻译评估标准介绍和计算方法
Posted 寒小阳
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器翻译评估标准介绍和计算方法相关的知识,希望对你有一定的参考价值。
对于翻译系统翻译出来的结果,我们当然可以人工判断其好坏,但这有很多限制。首先,每个人的评判标准不一样;然后,这对于评判人自身的英语水平也是有一定的要求的。近年来国际上也出了一些用于机器评判翻译结果好坏的标准,下面一一介绍一下这些标准及其计算方法:
一、BLEU评测方法
BLEU(Bilingual Evaluation understudy)方法由IBM提出,这种方法认为如果熟译系统魏译文越接近人工翻翻译结果,那么它的翻译质量越高。所以,评测关键就在于如何定义系统译文与参考译文之间的相似度。BLEU采用的方式是比较并统计共现的n元词的个数,即统计同时出现在系统译文和参考译文中的n元词的个数,最后把匹配到的n元词的数目除以系统译文的单词数目,得到评测结果。
最开始提出的BLEU法虽然简单易行,但是它没有考虑到翻译的召回率。
后对BLEU做了修正,首先计算出一个n元词在一个句子中最大可能出现的次数MaxRefCount(n-gram),然后跟候选译文中的这个n元词出现的次数作比较,取它们之间最小值作为这个n元词的最终匹配个数。
公式如下:
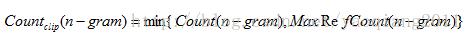
其中Count(n-gram)是某个n元词在候选译文中的出现次数,而MaxRefCount(n-gram)是该n元词在参考译文中出现的最大次数。最终统计结果是两者中的较小值。然后在把这个匹配结果除以系统译文的n元词的个数。对于上面的例子来说,修正后的一元词统计结果就是2/7。
共现n元词的精度Pn定义为:
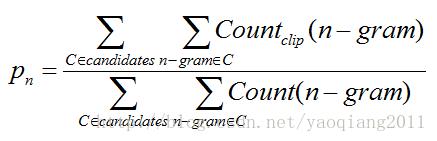
BLEU方法在得到上述结果之后,其评价分数可通过下式来计算:
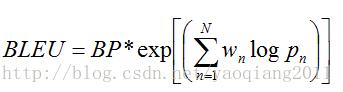
其中Wn表示共现n元词的权重,BP(Brevity Penalty)是惩罚因子:
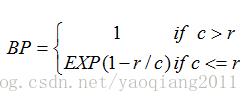
二、NIST评测方法
NIST(National Institute of standards and Technology)方法是在BLEU方法上的一种改进。它并不是简单的将匹配的n—gram片段数目累加起来,而是求出每个n-gram的信息量(information),然后累加起来再除以整个译文的n-gram片段数目。信息量的计算公式是:
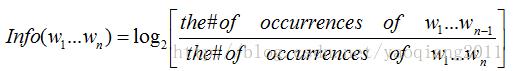
上式中分母是n元词在参考译文中出现的次数,分子是对应的n-l元词在参考译文中的出现次数。对于一元词汇,分子的取值就是整个参考译文的长度。
计算信息量之后,就可以对每一个共现n元词乘以它的信息量权重,再进行
加权求平均得出最后的评分结果:
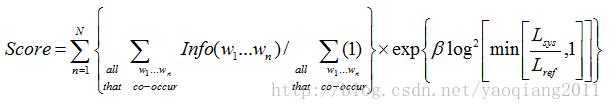
NIST采用的是算术平均方式,Lsys是使系统译文的长度,而Lref是参考译文的平均长度,是一个经验阈值,它使整个惩罚值在系统译文的长度是参考译文长度的2/3时为0.5。
三、错词率
错词率(The Word error rate, WER) 是一个基于Levenshtein距离(http://en.wikipedia.org/wiki/Levenshtein_distance)的准则, 但是Levenshtein距离一般是在字符级别上计算的, 而此处的WER 是在词的基础上计算的. 事实上,最开始的时候,WER是用作判别语音识别系统识别结果好坏的标准, 后被沿用到机器翻译结果好坏判定上了. 标准的大致算法是评估我们的机器翻译结果和给定的标准答案之间的差别词数.
有一个与之对应的位置无关单词错误率评测标准PER, 这个标准能够容许翻译时候的词或者短语位置变化。
四、METEOR
METEOR测度的目的是解决一些BLEU标准中固有的缺陷。METEOR标准基于单精度的加权调和平均数和单字召回率。该标准是2004年Lavir发现在评价指标中召回率的意义后被提出的。他们的研究表明,召回率基础上的标准相比于那些单纯基于精度的标准(例如BLEU和NIST),其结果和人工判断的结果有较高相关性。
METEOR也包括其他指标没有发现一些其他功能,如同义词匹配,而不是只在确切的词形式匹配,匹配度量也对同义词。例如,“好”的参考渲染为“好”的翻译是一个比赛。度量也包括词干分析器,它lemmatises在lemmatised形式的话,比赛。度量标准的实施,是模块化的,这场比赛的话作为模块实现的算法,以及新的模块,实现不同的匹配策略可以很容易地添加。
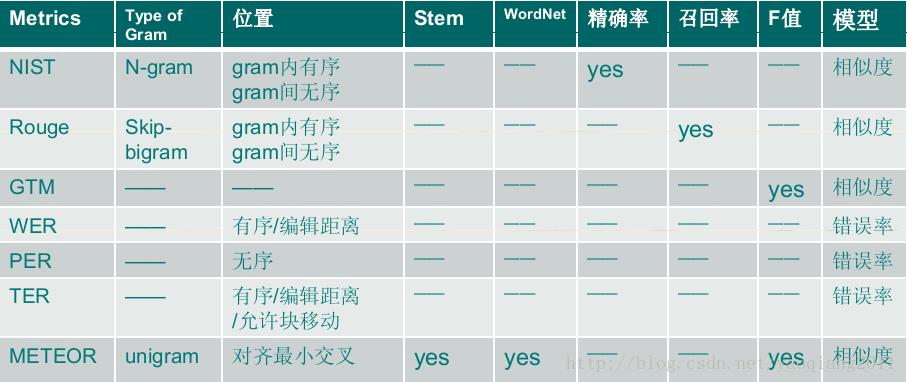
常用的评价准则可参见下表:
以上是关于机器翻译评估标准介绍和计算方法的主要内容,如果未能解决你的问题,请参考以下文章