python 爬虫提取新闻标题?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 爬虫提取新闻标题?相关的知识,希望对你有一定的参考价值。
import requests
from bs4 import BeautifulSoup
response = requests.get('http://www.yicai.com/data/')
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text,'html.parser')
for news in soup.select('.dl-item'):
print(news.select('h3')[0].text)
各位,重点在print打印出的是H3 list中的0的标题纯文字,请问如何print出全部标题文字呢?如果不适用[0]那么打印出的就是全部带标签的标题,我最终的目的是想提取纯文字
这个链接的新闻标题标签应该是h2吧
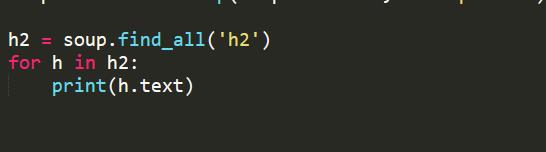
试试这个
参考技术A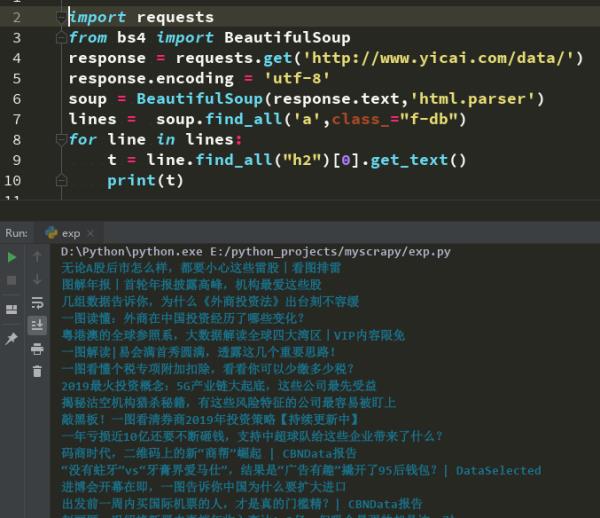
python2.7 爬虫初体验爬取新浪国内新闻_20161130
python2.7 爬虫初学习
模块:BeautifulSoup requests
1、获取新浪国内新闻标题
2、获取新闻url
3、还没想好,想法是把第2步的url 获取到下载网页源代码 再去分析源代码 获取新闻详情页 发表时间 新闻来源等数据 结合MySQLdb模块导入到数据库
4、疑惑:期望是整体获取这些字段 发表时间 发布标题 新闻详情内容 新闻来源
任重而道远。。都想拜个老师带带了。。
#coding:utf-8
import requests
from bs4 import BeautifulSoup as bs
url=‘http://news.sina.com.cn/china/‘
res=requests.get(url)
res.encoding=‘utf-8‘
html=res.text
soup=bs(html,‘html.parser‘)
title=soup.select(‘.blk12‘)[0].text
print title
t=soup.select(‘.blk12 a‘)
for i in range(len(t)):
url=t[i][‘href‘]
print url
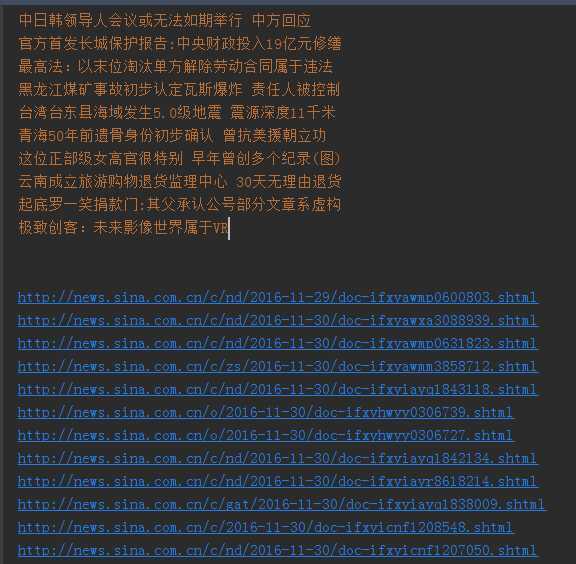
以上是关于python 爬虫提取新闻标题?的主要内容,如果未能解决你的问题,请参考以下文章