关于抓包返回数据正常,浏览器请求报403错误的解决方法
Posted xiangzhihong8
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于抓包返回数据正常,浏览器请求报403错误的解决方法相关的知识,希望对你有一定的参考价值。
不知道大家遇到过没有,我们使用诸如Fiddler、Charles进行抓包的时候是正常的,但是当我们将请求的Url链接拷贝到浏览器中进行请求的时候,就会403错误。403错误是我们网络请求中常见的【禁止访问】错误。如下所示,我们在Charles中是正常的,但是在浏览器中或者使用Postman进行访问时就会出现403错误。
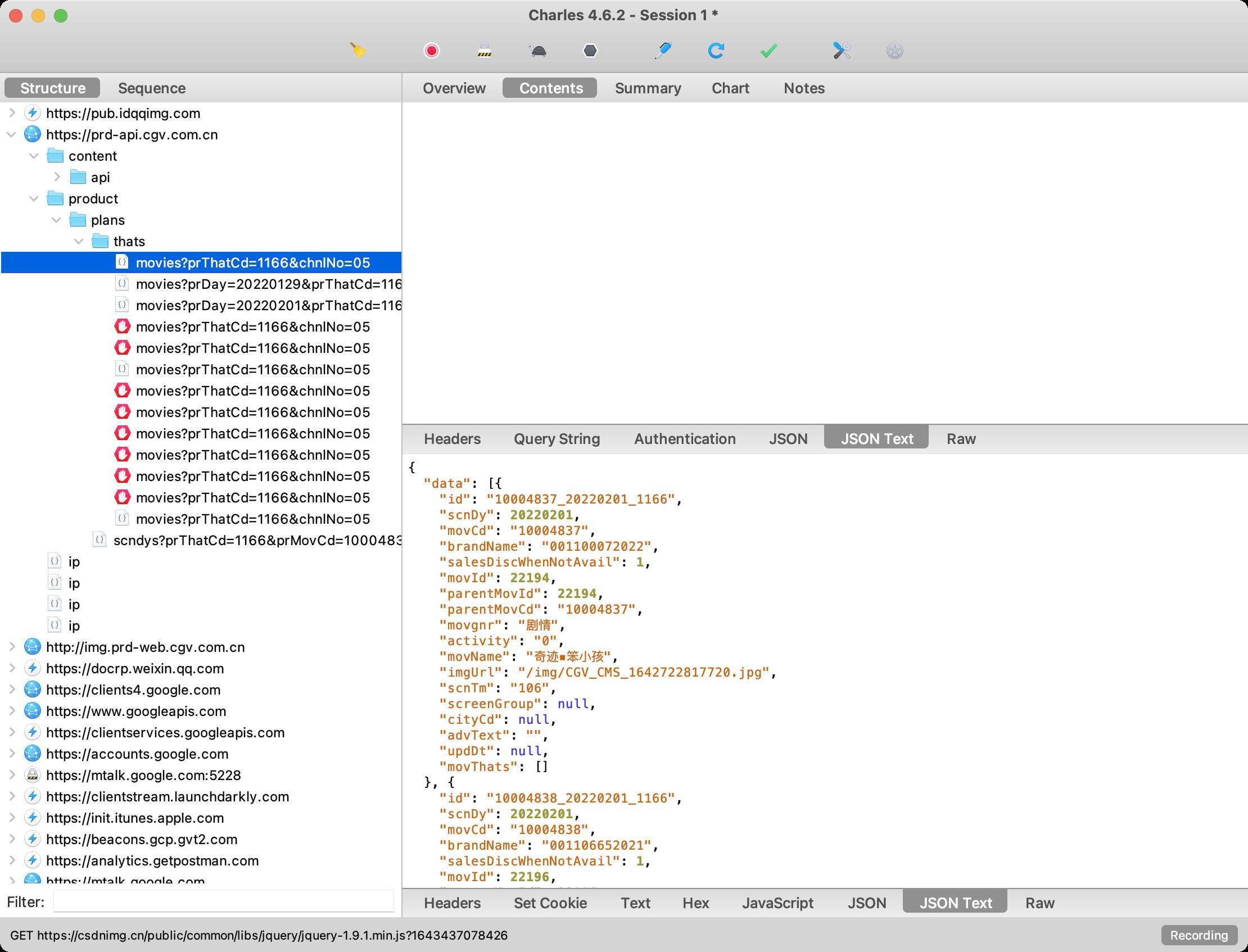
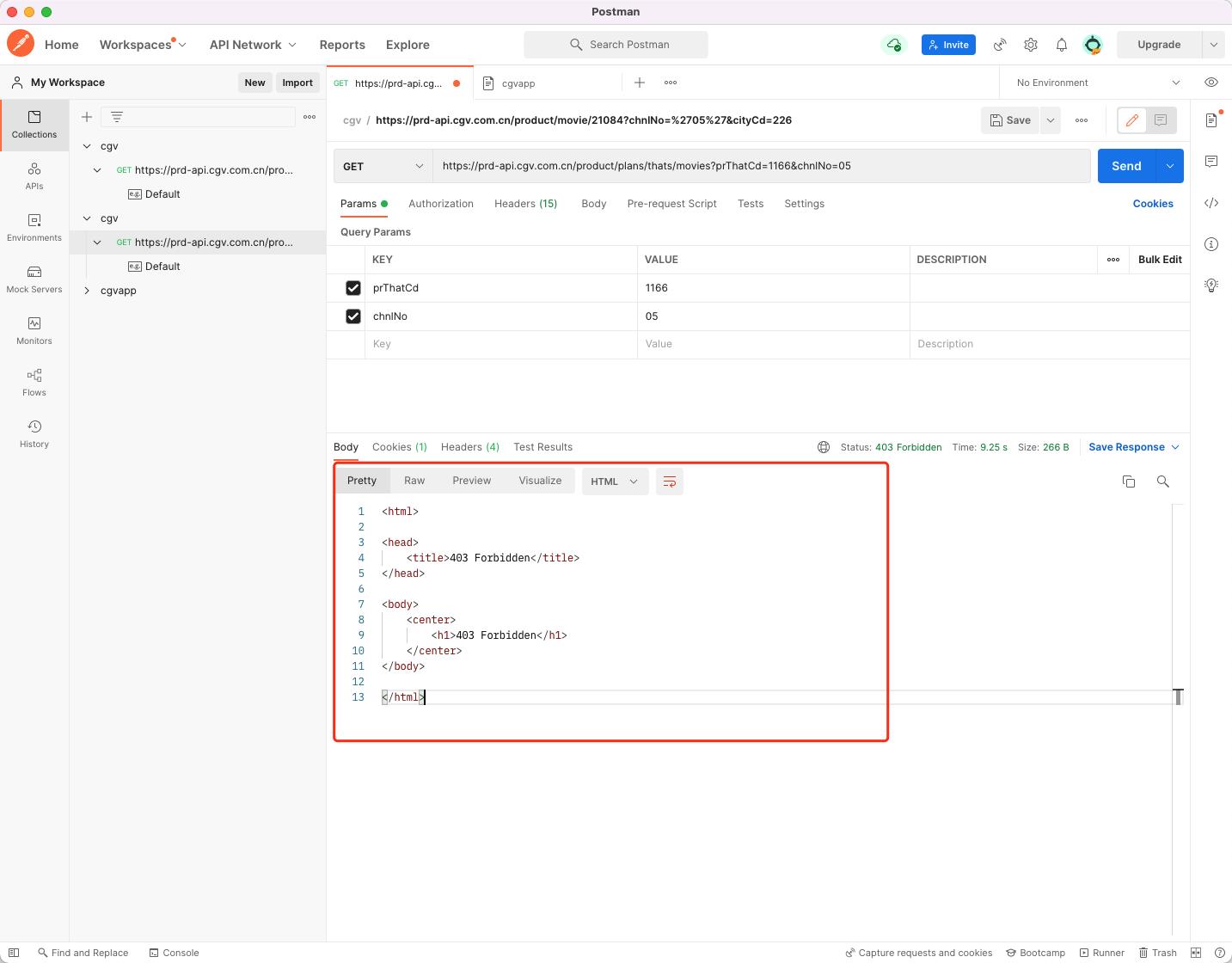
对于这种403禁止访问的错误,我们一般只需要加上对应的header参数即可。具体需要哪些参数,可以将完整的请求拷贝过来,然后进行头信息分析。通常需要的参数如下:
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/39.0.2171.95 Safari/537.36")
req.add_header("GET",url)
req.add_header("Host","blog.xxx.net")
req.add_header("Referer","http://www.xxx.net/")
比如,前面的示例,我将需要的header参数都添加后,就可以请求了。
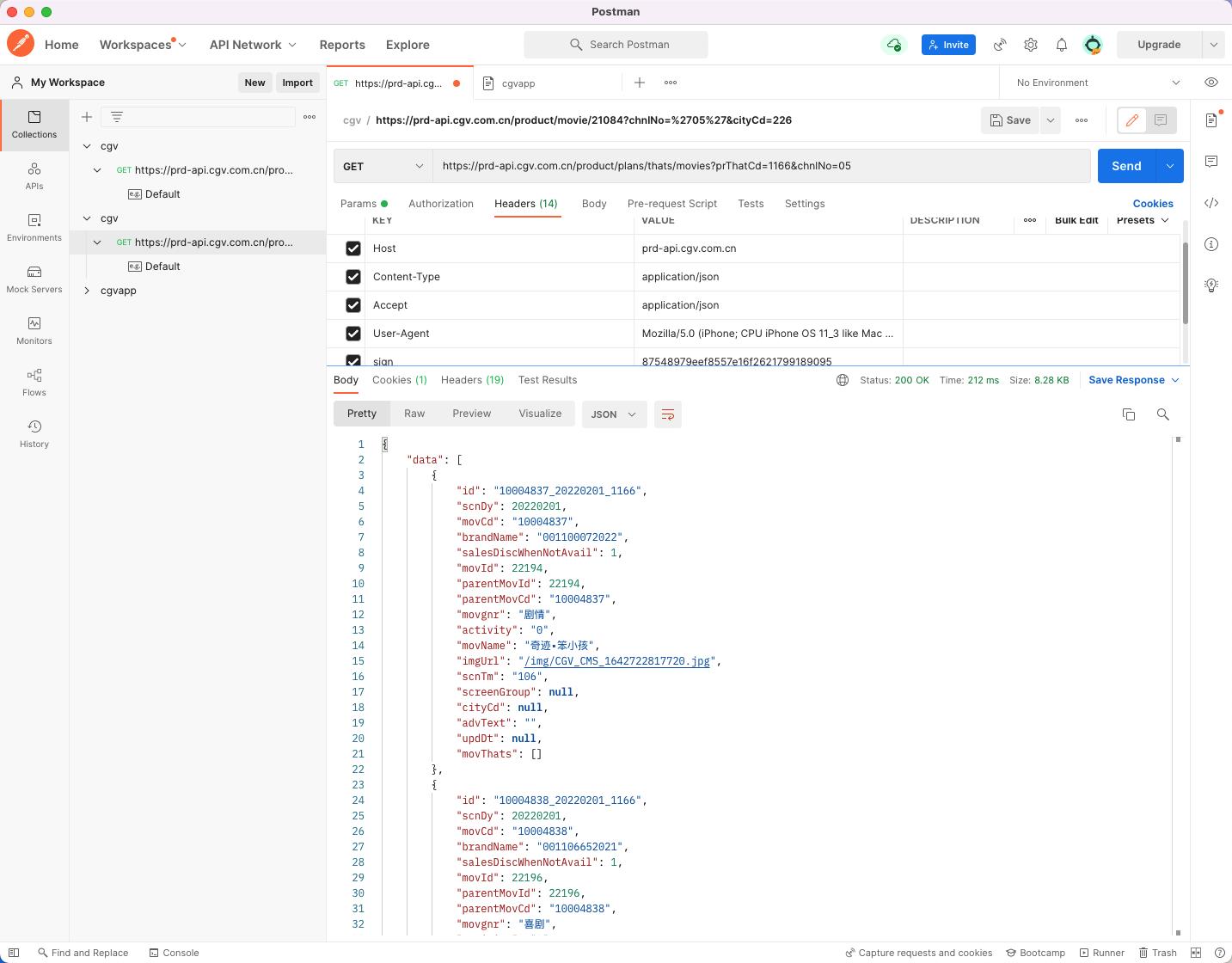
以上是关于关于抓包返回数据正常,浏览器请求报403错误的解决方法的主要内容,如果未能解决你的问题,请参考以下文章