如何保证数据库与redis缓存数据一致性
Posted 在京奋斗者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何保证数据库与redis缓存数据一致性相关的知识,希望对你有一定的参考价值。
既然要解决这个问题,那么首先要大概了解为啥会出现数据不一致呢?根本原因是我们无法将数据库更新操作与缓存更新操作放在同一个事务内同步成功,同步失败!
一、常见操作及问题
1.1、先更新数据库,后更新缓存

问题:假如有两个请求,请求1先更新数据库,将库存更新为1,这时CPU切换给了请求2,请求2将库存更新为2并且将库存更新为了2,这时CPU又切换到了请求1,这时将库存更新为1,这样最终数据库中库存数量是2,而缓存中库存数量却为1,导致了两者不一致,因此这种操作是无法保证两者一致的。
1.2、先更新缓存后更新数据库
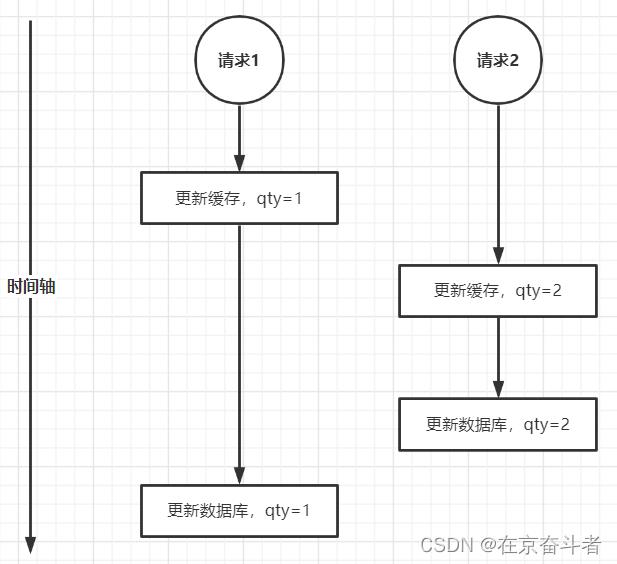
问题:假如有两个请求,请求1先更新缓存为1,然后这时CPU切换到请求2上了,更新缓存为2,更新数据库库存也为2,然后CPU又切换到了请求1上,这时请求1更新数据库库存为1,最终缓存中库存为2,数据库中库存为1。两者数据不一致。
1.3、先删除缓存,后更新数据库
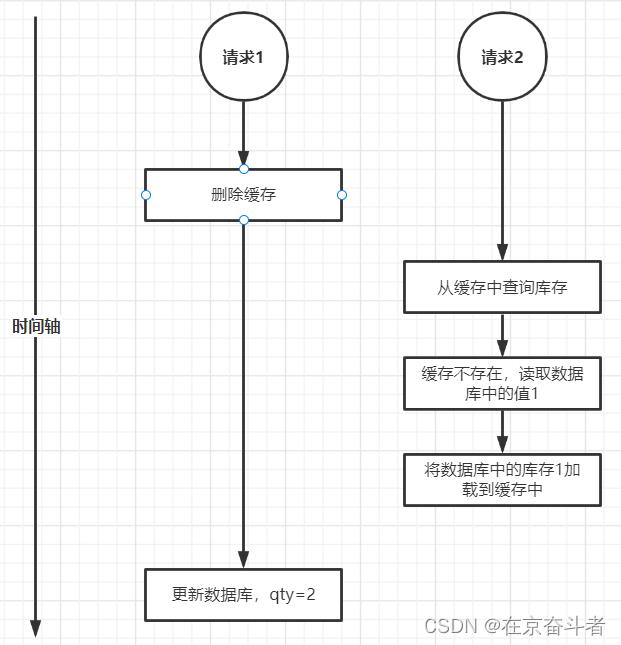
问题:假如请求1先删除缓存,这时CPU切换到请求2,请求2从缓存中读取查询库存,发现缓存中不存在,那么就会去读取数据库中的库存,数据库中当前库存是1,那么就会把1加载到缓存中。然后CPU切换到了请求1上,它去更新数据库将库存更新为2,这样最后缓存中值是1,数据库中值是2,两者不一致。
1.4、先更新数据库,后删除缓存

问题:假如有3个请求,请求1先更新数据库库存为1,随后就删掉了缓存。CPU切换到请求3,请求3查询数据库,发现数据库中数据不存在,因此就读取数据库中的库存,值为1。这时CPU又切给了请求2,请求2先更新数据库库存为2,随后就再次尝试删除缓存(这时缓存中没值)。这时CPU又切给了请求3,请求3把刚才从数据库中查询出来的库存1加载到缓存中。这就又导致了最终缓存与数据库中的数据不一致。虽然先更新数据库然后删除缓存依然有问题,但相比于上面3个出现的概率会比较小(一般数据库更新操作要比查询数据库并填充到缓存的时间要长,不过当查询数据库即将要向缓存中填充的时候出现ygc的话就可能发生不一致的情况)
二、方案进阶
2.1、延迟双删

问题:线程1先删除缓存,然后更新数据库中库存为2(原来是1),然后再次删除缓存,接着CPU切到线程2,线程2从从库中查询库存还是老数据1,然后将库存1加载到缓存。接着CPU切换到线程3,线程3将主库库存2同步到从库上,这样最终数据库中库存是2,而缓存中库存为1,两者不一致。延迟双删之所以难以解决数据一致性问题,主要在于我们无法确定延迟多久来第二次删除缓存,当我们遇到数据库主从延迟的时候,很难估计一个合理的时间出来。
2.2、redis读写锁
2.2.1 读多写少
public void testUpdate(String lockKey)
//先获取读写锁
RReadWriteLock readWriteLock = redissonClient.getReadWriteLock(lockKey);
//加一把写锁
RLock lock = readWriteLock.writeLock();
try
//考虑到可能瞬时有非常多的读请求并有部分写请求,这里加上写锁会与读操作互斥,这样会导致读操作都排队等候,
//为防止积压太多请求,这里尝试获取锁只等待1秒钟,如果1秒钟之内能获取到锁,那么返回true,
//如果1秒钟之内无法获取锁,那么返回false,这样我们就可以把积压的读写请求限制在了可控的范围内,那么拿不到
//锁的请求都直接响应给请求端网络繁忙请稍后重试的提示了。
if (lock.tryLock(1, TimeUnit.SECONDS))
try
//更新数据库
catch(Exception ex)
finally
//当获取锁成功时最后一定要记住finally去关闭锁
lock.unlock(); //释放锁
else
//没有加到锁,直接给请求端响应即可,不需要释放锁
throw new RuntimeException("网络繁忙,请稍后重试!");
catch (InterruptedException e)
e.printStackTrace();
throw new RuntimeException("加锁出现异常");
public void testQuery(String lockKey)
//先获取读写锁
RReadWriteLock readWriteLock = redissonClient.getReadWriteLock(lockKey);
//加一把读锁
RLock lock = readWriteLock.readLock();
try
//考虑到可能瞬时有非常多的读请求,如果这时没有对当前商品加写锁的操作,那么读操作是不互斥的,可以并发查询,这样可以保证
//绝大多数场景下可以支持比较高的并发。如果当前商品有写锁,那么读请求需要排队等候获取锁,如果1秒钟之内无法获取锁,那么
//返回false,这样我们就可以把积压的读写请求限制在了可控的范围内,那么拿不到锁的请求都直接响应给请求端网络繁忙请稍后重试的提示了。
if (lock.tryLock(1, TimeUnit.SECONDS))
try
//先从缓存中查询库存,如果缓存中没有则从数据库中查询库存并把查到的结果放到缓存当中
catch(Exception ex)
finally
//当获取锁成功时最后一定要记住finally去关闭锁
lock.unlock(); //释放锁
else
//没有加到锁,直接给请求端响应即可,不需要释放锁
throw new RuntimeException("网络繁忙,请稍后重试!");
catch (InterruptedException e)
e.printStackTrace();
throw new RuntimeException("加锁出现异常");
说明:对于一般中小企业,量级不算太大的话,可以采用上面说的方法来解决缓存与数据库一致性问题。因为绝大多数情况下都是读,因此效率还是很高的。
2.2.2 读多写也多
假如我们应对像秒杀这样的场景的话,显然库存的变更是非常多的而且并发非常高,每秒可能有几十万甚至上百万请求,这种情况下,更新数据库接着操作缓存的这种方式显然就非常不合适了,因为数据库压根没有办法支撑瞬间几十万的并发,因此秒杀场景下(写多读也多)我们扣减库存其实操作的是缓存,然后异步通过RocktMq的方式发给我们的服务器,消费者以可接受的速度消费订单扣减库存。秒杀是一个非常大的课题,牵扯的内容很多,感兴趣的可以学习相关内容。
2.3、异步监听binlog删除 + 重试
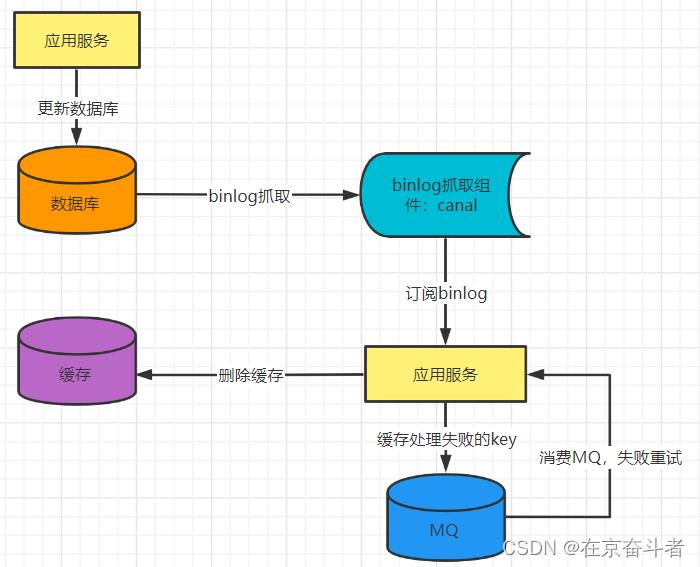
存在的问题:
1)脏数据时间窗口“较大”
这个脏数据时间窗口较大,是相对同步删除来说。在你收到binlog之前,他中间要经过:binlog从主库同步到从库、binlog从库到binlog监听组件、binlog从监听组件发送到MQ、消费MQ消息,这些操作每个都是有一定的耗时的,可能是几十毫秒甚至几百毫秒,所以说它其实整体是有一个脏数据的时间窗口。
而同步删除是在更新完数据库后马上删除,时间窗口大概也就是1毫秒左右,所以说binlog的方式相对于同步删除,可能存在的脏数据窗口会稍微大一点。
2)极端场景下存在长期脏数据问题
binlog抓取组件宕机导致脏数据。该方案强依赖于监听binlog的组件,如果监听binlog组件出现宕机,则会导致大量脏数据。
拆库拆表流程中可能存在并发脏数据
拆库拆表流程中并发脏数据问题
我们来看下面这个例子:
表A正在进行数据库拆分,当前进行到灰度切读流量阶段:部分读新库,部分读老库
数据库拆分大致流程:增量数据同步(双写)、全量数据迁移、数据一致性校验、灰度切读、切读完毕后停写老库。
此时表A存在数据 a=1,并发情况下可能有以下流程

以上是关于如何保证数据库与redis缓存数据一致性的主要内容,如果未能解决你的问题,请参考以下文章