动手学习VGG16
Posted 费费川
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了动手学习VGG16相关的知识,希望对你有一定的参考价值。
VGG 论文
《Very Deep Convolutional Networks for Large-Scale Image Recognition》
论文地址:https://arxiv.org/abs/1409.1556
使用重复元素的网络(VGG)
以学习VGG的收获、VGG16的复现二大部分,简述VGG16网络。
一. 学习VGG的收获
- VGG网络明确指出并实践证明了,浅而大的卷积核不如深而小的卷积核。
假设卷积块a、b的输入输出维度相同(不妨设维度=C),其中卷积块a(1个7 * 7的卷积层),卷积块b(由3个3 * 3的卷积层组成)。
特征方面:不论h、w是否发生改变,对于卷积块a都只能得到浅层的特征(轮廓),而卷积块b能得到深层的特征(轮廓,波纹,花边等等)。当h、w发生改变的时候,卷积块a和卷积块b都具有相同的感受野。
参数方面:卷积块a的参数Pa = 7 * 7 * C^2 = 49 * C^2,卷积块b的参数Pb = 3 * (3 * 3 * C^2) = 3 * 9 * C^2 = 27 * C^2,明显 Pa > Pb。
-
图片的尺度N(h * w)决定了VGG网络的性能,多尺度N训练有助于提升VGG网络的性能。
VGG网络结构图如下所示。
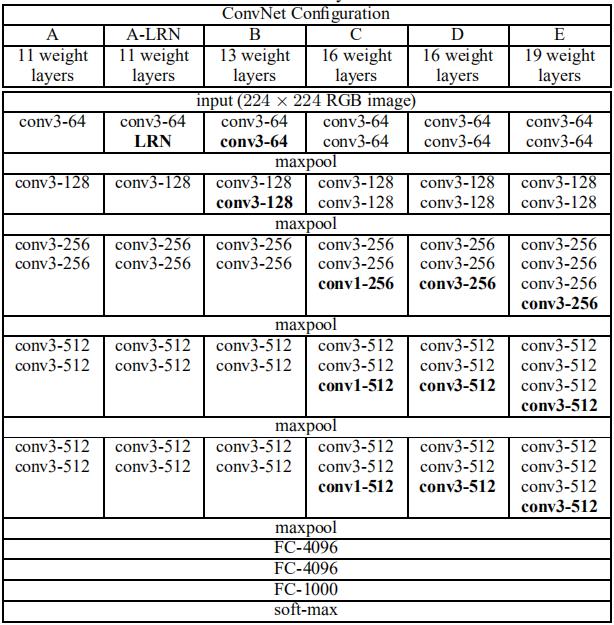
VGG16网络由5个卷积块和1个全连接块组成,每个卷积块后接一个步幅为2的2 * 2的最大池化层,根据图片卷积后的尺寸计算公式:
h
′
=
(
h
−
F
+
2
P
)
/
S
+
1
h' = (h-F+2P)/S+1
h′=(h−F+2P)/S+1
w
′
=
(
w
−
F
+
2
P
)
/
S
+
1
w' = (w-F+2P)/S+1
w′=(w−F+2P)/S+1
其中输入图片的尺度W(h, w),Filter大小(卷积层或池化层的卷积核大小) F * F,步幅 S,填充 P,输出图片的尺度N(h’, w’)。
VGG16网的输入图片的尺度必须为32的整数倍。由于组成VGG16的卷积块都是由数个步幅为1,填充为1的3 * 3的卷积层组成,不会改变图片的尺度。对于卷积块后接步幅为2的2 * 2最大池化层,图片的尺度缩小为原尺度的1/2,有5个步幅为2的2 * 2最大池化层,因此图片的尺度缩小为原尺度的(1/2)^5=1/32。
不妨设输入图片的尺度为N,采用多尺度(N-32, N, N+32)可以显著提升VGG16网络的性能。
二. VGG16网络的复现
- 数据预处理
VGG网络采用极为简单的处理方式,RGB三通道分别减去样本RGB三通道的均值。
样本数量较少时
"""
path 为文件路径的前缀
folders 为一个字典(类别kind,列表list),其中列表内存放着图片名
"""
# 样本数量较少
import cv2
import numpy as np
means = [0., 0., 0.]
stdevs = [0., 0., 0.]
img_list = []
for string in folders:
path_next = path + "\\\\" + string
for file in folders[string]:
file = path_next + "\\\\" + file
#opencv 读入的矩阵是BGR
img = cv2.imread(file)
img = img[:, :, :, np.newaxis]
# print(img.shape)
# img.shape = (h, w, 3, 1)
img_list.append(img)
imgs = np.concatenate(img_list, axis=3)
# print(imgs.shape)
# imgs.shape = (h, w, 3, n)
imgs = imgs.astype(np.float32) / (255.)
for i in range(3):
pixels = imgs[:, :, i, :].ravel() # 拉成一行
# pixels.shape = (h*w*n, )
means[i] += np.mean(pixels)
stdevs[i] += np.std(pixels)
# BGR --> RGB , CV读取的需要转换,PIL读取的不用转换
# 也可以这么思考,opencv读取的是BGR,PIL读取的是RGB,如果交叉使用则需要使用。
means.reverse()
stdevs.reverse()
样本数量过多时
样本数量过多时,采用《概率论与数理统计》中的参数估计的方法。
对于样本x1,x2,x3,…,xn,期望u1,u2,u3,…,un,方差 v1^2, v2^2, v3^2,…, vn^2,都来源于同一个样本X采用随机取样得到。
不妨设 u1,u2,u3,…,un的均值为u,v1^2, v2^2, v3^2,…, vn^2的均值为v。
NX = x1+x2+x3+…+xn
E(NX) = u1+u2+u3+…+un = nu
D(NX) = v1^2 + v2^2 + v3^2 +…+ vn^2 = nv^2
X = NX/n = (x1+x2+x3+…+xn)/n
E(X) = E(NX)/n = u
D(X) = D(NX)/(n*n) = v^2/n
样本X的期望为u,标准差为v/sqrt(n)。
# 样本数量过多
import cv2
import random
import math
import numpy as np
means = [0., 0., 0.]
stdevs = [0., 0., 0.]
for epoch in range(1000):
img_list = []
for string in folders:
path_next = path + "\\\\" + string
for file in folders[string]:
random_num = np.random.uniform() # np.random.uniform(0,1) 0-1之间按照均匀分布采样
if random_num < 0.001:
file = path_next + "\\\\" + file
img = cv2.imread(file)
#opencv 读入的矩阵是BGR
img = img[:, :, :, np.newaxis]
# print(img.shape)
# img.shape = (h, w, 3, 1)
img_list.append(img)
imgs = np.concatenate(img_list, axis=3)
#print(imgs.shape)
# imgs.shape = (h, w, 3, n)
imgs = imgs.astype(np.float32) / (255.)
for i in range(3):
pixels = imgs[:, :, i, :].ravel() # 拉成一行
# print(pixels.shape)
# pixels.shape = (h*w*n, )
means[i] += np.mean(pixels)
stdevs[i] += np.std(pixels)
#if (epoch+1)%100 == 0:
#print("normMean = ".format(means))
#print("normStd = ".format(stdevs))
# BGR --> RGB , CV读取的需要转换,PIL读取的不用转换
# 也可以这么思考,opencv读取的是BGR,PIL读取的是RGB,如果交叉使用则需要使用。
means.reverse()
stdevs.reverse()
use_means = [0., 0., 0.]
use_stdevs = [0., 0., 0.]
for i in range(3):
use_means[i] = means[i] / 1000
use_stdevs[i] = stdevs[i] / math.sqrt(1000)
print(use_means)
print(use_stdevs)
- 参数控制
batch_size = 8 # 每次喂入的数据量,batch_size可以根据电脑的配置调整
lr = 0.01 # 学习率
step_size = 1 # 每n个epoch更新一次学习率,数据集过大因此调小
epoch_num = 50 # 总迭代次数
num_print = 1120 # 每n次batch打印一次,数据集过大因此调大
num_check = 1 # 每n个epoch验证一次模型,若效果更优则保存模型,数据集过大因此调小
- 数据集构建
"""
train_path、verification_path、test_path 同为字典(类别kind,列表list),其中列表内存放着图片的绝对路径。
labels 也是一个字典(类别kind,序号number),序号为1~n的数字
"""
import torch
from torch.autograd import Variable
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
import cv2
# 独立设置尺寸,有利于VGG网络的多尺度训练
size = 224
# 均值和标准差均是按照VGG论文设置的,减去样本均值,标准差设置为1。
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5142455680072308, 0.4990353952050209, 0.5186490820050239), (1.0, 1.0, 1.0))
])
# -----------------ready the dataset--------------------------
def default_loader(path, img_size):
img = cv2.imread(path)
if img_size is not None:
img = cv2.resize(img,(img_size,img_size),interpolation=cv2.INTER_NEAREST)
return img
class MyDataset(Dataset):
# 构造函数
def __init__(self, path, transform=None, target_transform=None, loader=default_loader, img_size = None):
imgs = []
for classification in path:
for i in range(len(path[classification])):
img_path = path[classification][i]
img_label = labels[classification]
imgs.append((img_path,int(img_label)))#imgs中包含有图像路径和标签
self.path = path
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
self.loader = loader
self.img_size = img_size
# hash_map建立
def __getitem__(self, index):
img_path, img_label = self.imgs[index]
# 调用 opencv 打开图片
img = self.loader(img_path,self.img_size)
if self.transform is not None:
img = self.transform(img)
img_label -= 1
return img, img_label
def __len__(self):
return len(self.imgs)
train_data = MyDataset(train_path, transform=transform, img_size=size)
verification_data = MyDataset(verification_path, transform=transform, img_size=size)
test_data = MyDataset(test_path, transform=transform, img_size=size)
#train_data 、verification_data和test_data包含多有的训练、验证与测试数据,调用DataLoader批量加载
train_loader = DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True)
verification_loader = DataLoader(dataset=verification_data, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(dataset=test_data, batch_size=batch_size, shuffle=False)
- VGG16网络构建
import torch
from torch import optim
import torchvision
import matplotlib.pyplot as plt
import numpy as np
from torchvision.utils import make_grid
import time
关于多尺度训练的问题,有两个思路。
思路1:采用模型加载函数model.load_state_dict(torch.load(PATH), strict=False)。在加载部分模型参数进行预训练的时候,很可能会碰到键不匹配的情况(模型权重都是按键值对的形式保存并加载回来的)。因此,无论是缺少键还是多出键的情况,都可以通过在load_state_dict()函数中设定strict参数为False来忽略不匹配的键。(不推荐)
思路2:参照《动手学深度学习》的卷积神经网络NiN、GoogLeNet、ResNet、DenseNet等网络,对VGG16网络的全连接块进行魔改,采用卷积块temp代替全连接块的思路。卷积块temp由2个1 * 1的卷积层及1个全局平均池化层组成,最后接2(其中1层为塑造类别的全连接层)个全连接层。
思路1代码实现
from torch import nn
from torchsummary import summary
class VGG16Net(nn.Module):
def __init__(self):
super(VGG16Net,self).__init__()
# 第一层,2个卷积层和1个最大池化层
self.layer1 = nn.Sequential(
# 输入3通道,卷积核3*3,输出64通道(如224*224*3的样本图片,(224+2*1-3)/1+1=224,输出224*224*64)
nn.Conv2d(3,64,3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# 输入64通道,卷积核3*3,输出64通道(输入224*224*64,卷积3*3*64*64,输出224*224*64)
nn.Conv2d(64,64,3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# 输入224*224*64,输出112*112*64
nn.MaxPool2d(kernel_size=2,stride=2)
)
# 第二层,2个卷积层和1个最大池化层
self.layer2 = nn.Sequential(
# 输入64通道,卷积核3*3,输出128通道
nn.Conv2d(64,128,3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
# 输入128通道,卷积核3*3,输出128通道
nn.Conv2d(128,128,3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
# 输入112*112*128,输出56*56*128
nn.MaxPool2d(kernel_size=2,stride=2)
)
# 第三层,3个卷积层和1个最大池化层
self.layer3 = nn.Sequential(
# 输入128通道,卷积核3*3,输出256通道
nn.Conv2d(128,256,3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
# 输入256通道,卷积核3*3,输出256通道
nn.Conv2d(256,256,3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
# 输入256通道,卷积核3*3,输出256通道
nn.Conv2d(256,256,3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
#输入56*56*256,输出28*28*256
nn.MaxPool2d(kernel_size=2,stride=2)
)
# 第四层,3个卷积层和1个最大池化层
self.layer4 = nn.Sequential(
# 输入256通道,卷积核3*3,输出512通道
nn.Conv2d(256,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# 输入512通道,卷积核3*3,输出512通道
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# 输入512通道,卷积核3*3,输出512通道
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
#输入28*28*512,输出14*14*256
nn.MaxPool2d(kernel_size=2,stride=2)
)
# 第五层,3个卷积层和1个最大池化层
self.layer5 = nn.Sequential(
# 输入512通道,卷积核3*3,输出512通道
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# 输入512通道,卷积核3*3,输出512通道
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# 输入512通道,卷积核3*3,输出512通道
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
#输入14*14*512,输出7*7*256
nn.MaxPool2d(kernel_size=2,stride=2)
)
# VGG16--13个卷积层
self.conv_layer = nn.Sequential(
self.layer1,
self.layer2,
self.layer3,
self.layer4,
self.layer5
)
# VGG16--3个全连接层
self.fc = nn.Sequential(
"""
多尺度训练,代表训练3次
分别把第一个全连接层,设置成如下
A、nn.Linear(512 * 6 * 6, 4096)
B、nn.Linear(512 * 8 * 8, 4096)
C、nn.Linear(512 * 7 * 7, 4096)
保证C为最后一次训练即可。
"""
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),# 随机丢弃50%的神经元
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),# 随机丢弃50%的神经元
"""
第一种方法
nn.Linear(4096, n)
shape = (-1, n),n表示类别的数量
第二种方法如下,在VGG16后接1个全连接层
"""
nn.Linear(4096, 1000),
# 后接1个全连接层,shape = (-1, n),n表示类别的数量
nn.Linear(1000, 29)
)
def forward(self,x):
x = self.conv_layer(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
if __name__ == "__main__":
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu'以上是关于动手学习VGG16的主要内容,如果未能解决你的问题,请参考以下文章