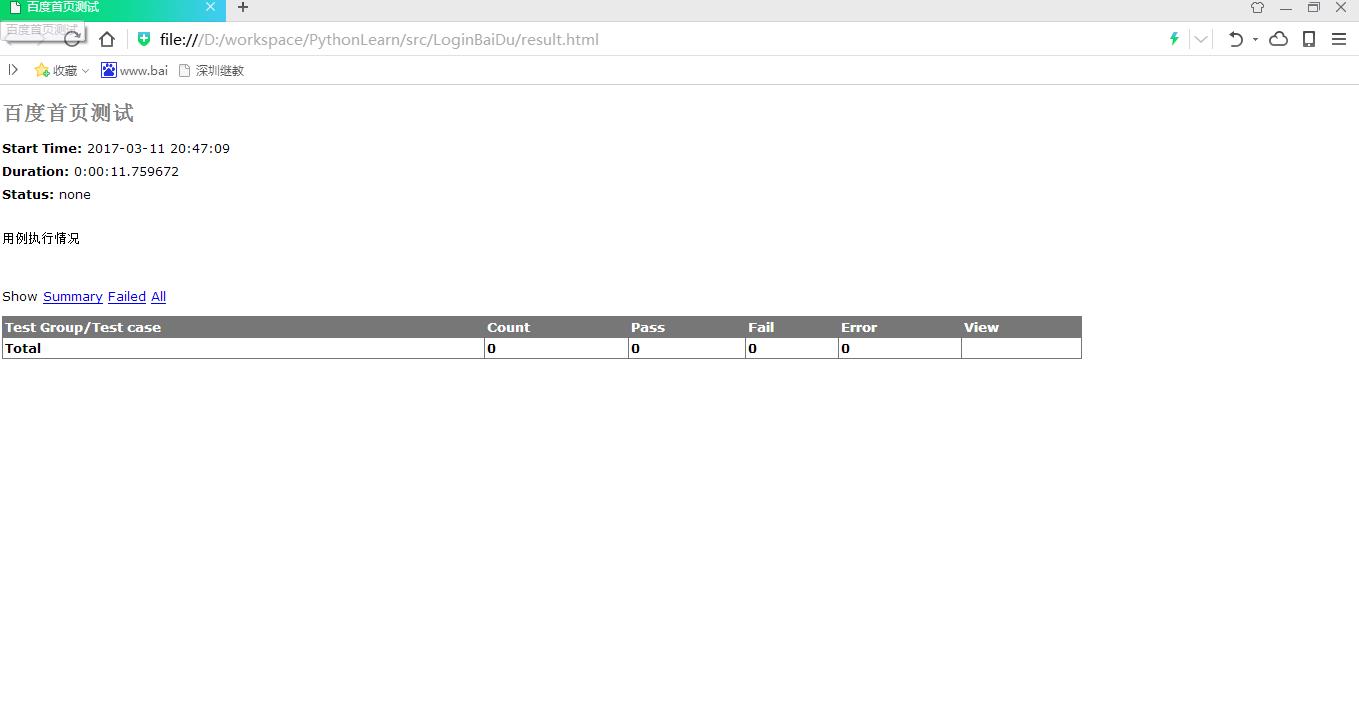
HTMLTestRunner生成的测试报告中的执行用例条数为0,成功数为0,失败数为0
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HTMLTestRunner生成的测试报告中的执行用例条数为0,成功数为0,失败数为0相关的知识,希望对你有一定的参考价值。
python+unittest+htmlTestRunner自动化代码执行后,提示“vector smash protection is enabled”,HTMLTestRunner生成的测试报告中的执行用例条数为0,成功数为0,失败数为0
开头
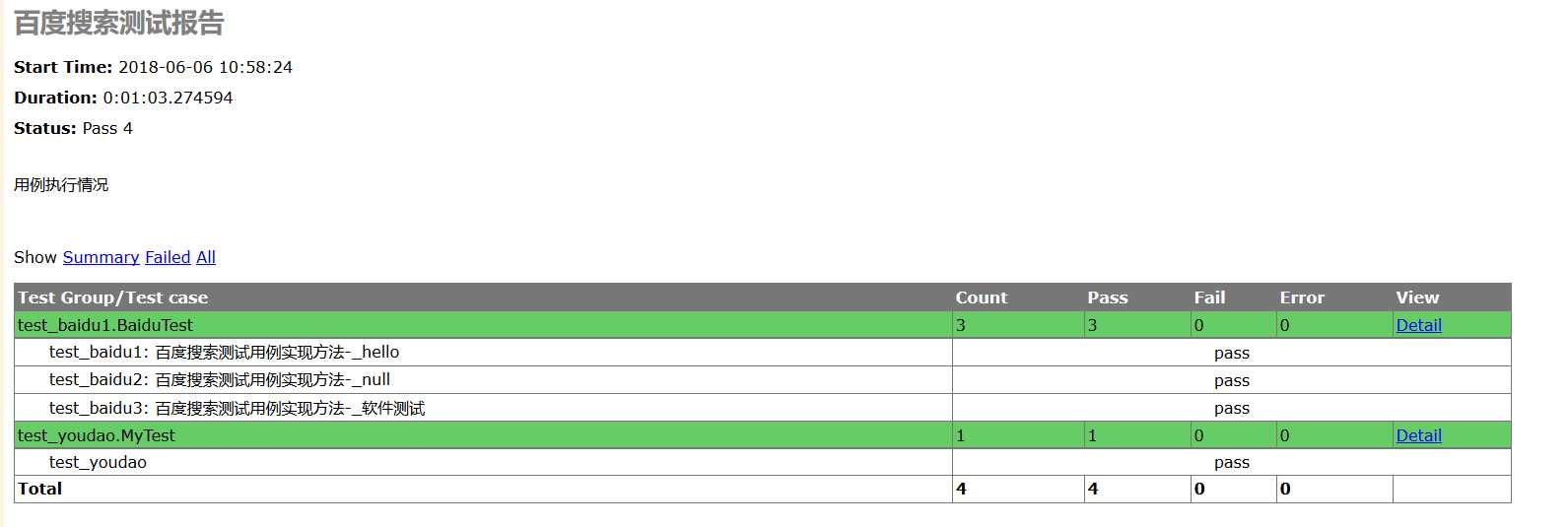
selenium之百度搜索+有道翻译的简单testcase执行-----用例报告(HTMLTestRunner)
本篇主要实现selenium自动化测试之百度搜索+有道翻译的简单测试用例执行,并通过HTML TestRunner生成html测试报告.这是前不久跟着视频学习的时候,练习的第一个HTMLTestRunner脚本,基于python3的脚本。
test_baidu,py
#coding=utf-8 import unittest import HTMLTestRunner import time # 定义测试文件查找的目录 test_dir=‘E:\\\\pycode\\\\unittest_baidu\\\\test_case‘ #定义discover 方法的参数 discover=unittest.defaultTestLoader.discover(test_dir, pattern =‘test_b*.py‘, top_level_dir=None) now=time.strftime(‘%Y_%m_%d %H_%M_%S‘) print(now) #定义报告存放路径 filename=‘E:\\\\pycode\\\\unittest_baidu\\\\report\\\\‘+now+‘result.html‘ fp=open(filename,‘wb‘) if __name__ == ‘__main__‘: # 定义测试报告 runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=u‘百度搜索测试报告‘, description=u‘用例执行情况‘) #运行测试用例 runner.run(discover) #关闭报告文件 fp.close()
test_youdao.py
# coding=utf-8 from selenium import webdriver import unittest from time import sleep class MyTest(unittest.TestCase): def setUp(self): self.driver = webdriver.Firefox() self.driver.maximize_window() self.base_url = "http://www.youdao.com" sleep(5) def test_youdao(self): driver = self.driver driver.get(self.base_url + "/") driver.find_element_by_id("translateContent").clear() driver.find_element_by_id("translateContent").send_keys("webdriver") driver.find_element_by_id("translateContent").submit() sleep(2) title = driver.title self.assertEqual(u"【webdriver】什么意思_英语webdriver的翻译_音标_读音_用法_例句_在线翻译_有道词典", title) def tearDown(self): self.driver.quit() if __name__ == "__main__": unittest.main()
all_test.py
#coding=utf-8 import unittest import HTMLTestRunner import time # 定义测试文件查找的目录 test_dir=‘E:\\\\pycode\\\\unittest_baidu\\\\test_case‘ #定义discover 方法的参数 discover=unittest.defaultTestLoader.discover(test_dir, pattern =‘test_*.py‘, top_level_dir=None) now=time.strftime(‘%Y_%m_%d %H_%M_%S‘) print(now) #定义报告存放路径 filename=‘E:\\\\pycode\\\\unittest_baidu\\\\report\\\\‘+now+‘result.html‘ fp=open(filename,‘wb‘) if __name__ == ‘__main__‘: # 定义测试报告 runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=u‘百度搜索测试报告‘, description=u‘用例执行情况‘) #运行测试用例 runner.run(discover) #关闭报告文件 fp.close()
脚本可以正常运行,如果运行失败,先查看一下环境配置是否ok,浏览器驱动等是否正确安装。
以上是关于HTMLTestRunner生成的测试报告中的执行用例条数为0,成功数为0,失败数为0的主要内容,如果未能解决你的问题,请参考以下文章
使用HTMLTestRunner生成测试报告并发送邮件,但每次都是等到执行完邮件发送的代码才能生成测试报告?
Python 同一文件中,有unittest不执行“if __name__ == '__main__”,不生成HTMLTestRunner测试报告的解决方案
为啥python+htmltestrunner生成的测试报告有问题
为啥python+htmltestrunner生成的测试报告有问题