使用 Carla 和 Python 的自动驾驶汽车第 5 部分 —— 长期模型结果
Posted Alex_996
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用 Carla 和 Python 的自动驾驶汽车第 5 部分 —— 长期模型结果相关的知识,希望对你有一定的参考价值。
欢迎来到第六部分的自动驾驶汽车/自动驾驶汽车和强化学习Carla, Python和TensorFlow。在这一部分中,我们将讨论我们工作中的一些初步发现。我会用"我们"这个词因为这是我和丹尼尔·库基拉的共同努力。
一开始,这个问题被有意地保持得非常简单。代理可以采取三种行动中的一种:左转,右转,直走。
我选择了Xception模式,因为我在《侠盗猎车手》中创造了自动驾驶汽车并获得了成功。
对于奖励,我们设置如下:
每帧+1以>50KMH行驶
每帧-1以<50KMH行驶
发生碰撞,-200,此轮结束
我们发现的第一件事是损失和q值基本上都是爆炸性的:
这似乎是,现在很明显,由于巨大的规模的撞车惩罚相比其他所有。也可能是边界超出了范围。例如,如果我们做一些类似这样的事情,我们可能会更成功:
每帧+0.005以>50KMH行驶
每帧-0.005以<50KMH行驶
发生碰撞,-1,此轮结束
这似乎减少了Q值和损失的爆炸性,但我们仍然发现,当给定为0时,agents毫无疑问只会持续地执行1个动作。
然后我们尝试将速度输入到神经网络中。这似乎有点帮助,但仍然不是主要问题。
然后我们考虑了这个模型。也许早该考虑到这一点。强化学习和监督学习有很大的不同,主要是因为监督学习是纯粹的基本真理(或者至少是期望)。
你提供给它的所有图像和标签都是100%准确的。在强化学习中,情况并非如此。我们拟合了一个模型,是的,但我们也拟合了Q值。它的操作要复杂得多,而且对模型来说,事情会变得更加“模糊”。没有理由也有高度复杂的神经网络。
当我们检查Xception模型(使用我们的速度层)时,它基本上有2300万个可训练参数:
Total params: 22,962,155
Trainable params: 22,907,627
Non-trainable params: 54,528
那太多了!
我们发现我们的模型的精度相当高(80-95%),所以这告诉我,我们几乎可以肯定每次都是过拟合。
好吧,那我们怎么办?历史上我成功使用的进化类型模型都是64x3的卷积神经。所以为什么不再做一次呢?因此,在本例中,一个64x3卷积神经网络更像是300万个可训练参数(包括速度层等):
Total params: 3,024,643
Trainable params: 3,024,643
Non-trainable params: 0
def model_base_64x3_CNN(input_shape):
model = Sequential()
model.add(Conv2D(64, (3, 3), input_shape=input_shape, padding='same'))
model.add(Activation('relu'))
model.add(AveragePooling2D(pool_size=(5, 5), strides=(3, 3), padding='same'))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(AveragePooling2D(pool_size=(5, 5), strides=(3, 3), padding='same'))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(AveragePooling2D(pool_size=(5, 5), strides=(3, 3), padding='same'))
model.add(Flatten())
return model.input, model.output
一个更简单的模型。
这个模型就这样训练了几天,结果是:

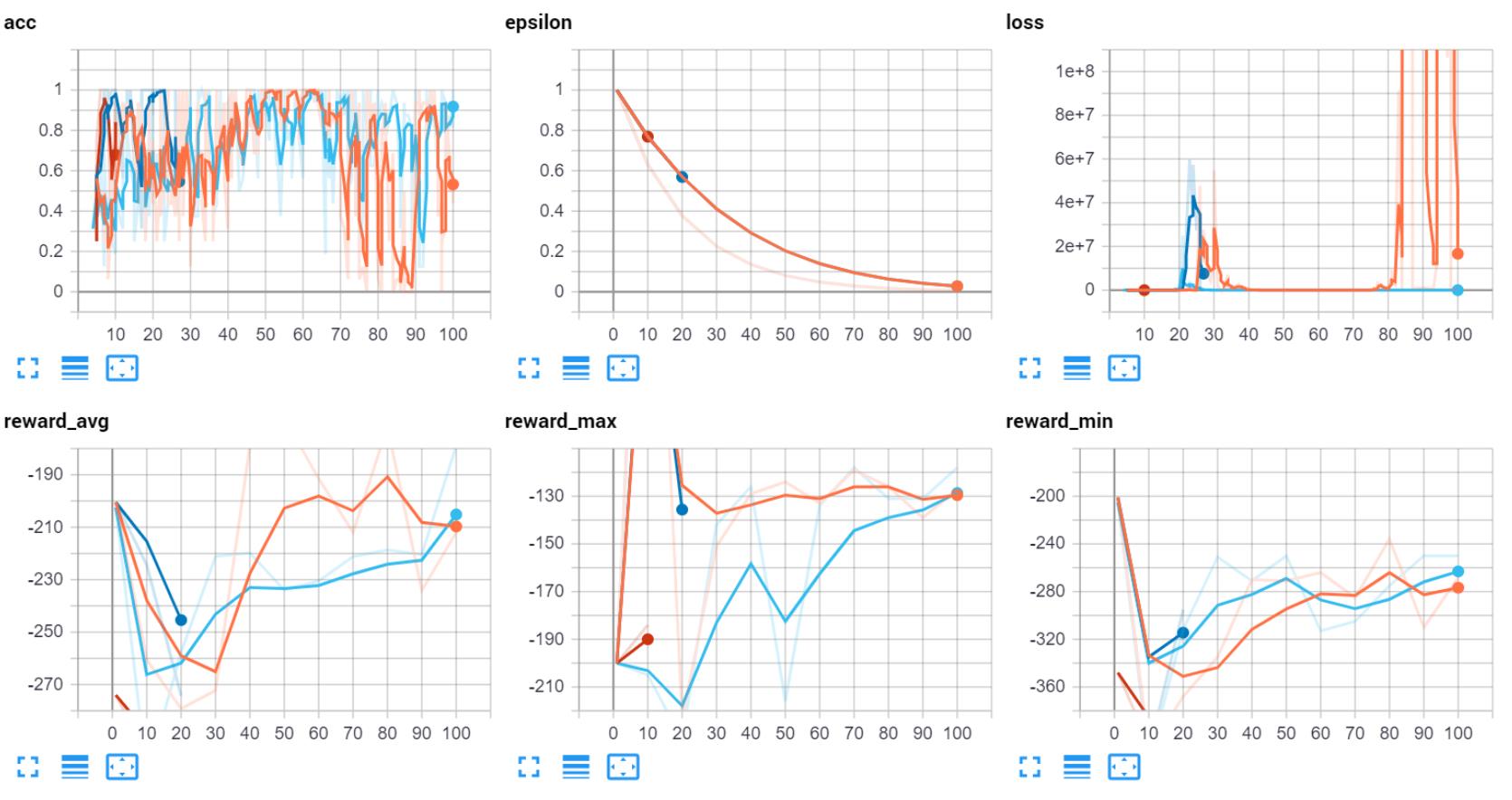
我将一次展示一些统计数据,因为我们正在追踪大量统计数据。首先我们有准确性。在DQN中,你不会像在监督学习中那样沉迷于准确性。这很重要,但你真正想要的只是像样的东西。如果你的模型有90%的准确性,那就真的值得高度怀疑,而不是高兴了。
记住,你的代理正在执行大量的随机操作,并且正在缓慢地学习Q值。神经网络是操作的一部分,但一个高度精确的神经网络,特别是在开始阶段将是一个危险的信号。
FPS是很重要的。当提到像驾驶汽车这样的游戏时,FPS越高越好。我们的目标是平均15FPS左右,通过我们决定刷出多少代理来控制它。如果你只能勉强运行1个代理,那么你就没有多少能力在这里进行修补。
接下来,我展示epsilon只是为了展示我对更多内容的探索。有时看起来有帮助,有时却没有。
最后是损失率。主要是为了证明没有爆炸。
然后我们可以查看关于奖励的各种统计数据:

我们可以看到,随着时间的推移,最大奖励确实会上升到20万集,并且可能会随着时间的推移而继续上升。最低报酬(即:经纪人做的最差的事)似乎并没有改变趋势,这并不太令人震惊。有时汽车只是掉进了一个不幸的环境中。最后,我们可以看到平均奖励水平持续提高。目前,它已经下滑,但并不一定比历史上几次下滑的时间更长。
总的来说,模型确实有所改进,这个64x3的CNN被证明是我们表现最好的模型,但我们确实尝试了其他一些事情:
更多的城市。游戏中总共有7个城市可供选择,所以我们每隔10集就会随机选择一个城市。我想知道的是,这是否会有助于更一般化,而不是只在一个城市。这似乎没有帮助。
允许更多的行动。所以代理人最初总是全速前进,只能向左,向右,或直走。然后我们给它刹车之类的选项,看看这是否有帮助。事实并非如此。
我们修改了奖励功能,添加了不同的时间和速度元素,创造了比简单的奖励所需的速度阈值更复杂的内容。我们发现最佳agent具有时间加权奖励函数,阈值为50KMH。
最后,可能真的只是需要更多的时间。DQN可以非常擅长学习…不是很快。我想继续训练这个特工一段时间,看看它是否会继续改善,但我最终还是发布了这个更新,我们花时间训练的不只是这个特工。如果您使用了Carla并在任何复杂的env上使用了DQN,那么您就会明白仅仅训练一个模型需要多长时间,更不用说尝试用不同的参数训练许多不同的模型了!仅这一型号就花了125个小时,或超过5天的训练。
如果你想玩一些东西,看看你是否可以做得更好,查看:Carla-RL github。
以上是关于使用 Carla 和 Python 的自动驾驶汽车第 5 部分 —— 长期模型结果的主要内容,如果未能解决你的问题,请参考以下文章