Java:数据结构笔记之LRU缓存机制的简单理解和使用
Posted JMW1407
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java:数据结构笔记之LRU缓存机制的简单理解和使用相关的知识,希望对你有一定的参考价值。
Java LRU缓存机制的简单理解和使用
LRU缓存机制
1、题目
原题链接
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和 写入数据 put 。
获取数据 get(key)- 如果关键字 (key) 存在于缓存中,则获取关键字的值(总是正数),否则返回 -1。写入数据 put(key, value)-如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字/值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。- 你是否可以在
O(1) 时间复杂度内完成这两种操作?
示例:
/* 缓存容量为 2 */
LRUCache cache = new LRUCache(2);
// 你可以把 cache 理解成一个队列
// 假设左边是队头,右边是队尾
// 最近使用的排在队头,久未使用的排在队尾
// 圆括号表示键值对 (key, val)
cache.put(1, 1);
// cache = [(1, 1)]
cache.put(2, 2);
// cache = [(2, 2), (1, 1)]
cache.get(1); // 返回 1
// cache = [(1, 1), (2, 2)]
// 解释:因为最近访问了键 1,所以提前至队头
// 返回键 1 对应的值 1
cache.put(3, 3);
// cache = [(3, 3), (1, 1)]
// 解释:缓存容量已满,需要删除内容空出位置
// 优先删除久未使用的数据,也就是队尾的数据
// 然后把新的数据插入队头
cache.get(2); // 返回 -1 (未找到)
// cache = [(3, 3), (1, 1)]
// 解释:cache 中不存在键为 2 的数据
cache.put(1, 4);
// cache = [(1, 4), (3, 3)]
// 解释:键 1 已存在,把原始值 1 覆盖为 4
// 不要忘了也要将键值对提前到队头
2、思路
什么是 LRU 算法:就是一种缓存淘汰策略。
- 计算机的缓存容量有限,如果缓存满了就要删除一些内容,给新内容腾位置。但问题是,删除哪些内容呢?我们肯定希望删掉哪些没什么用的缓存,而把有用的数据继续留在缓存里,方便之后继续使用。那么,什么样的数据,我们判定为「有用的」的数据呢?
- LRU 缓存淘汰算法就是一种常用策略。
LRU 的全称是 Least Recently Used,也就是说我们认为最近使用过的数据应该是是「有用的」,很久都没用过的数据应该是无用的,内存满了就优先删那些很久没用过的数据。
LRU 算法实际上是让你设计数据结构:
- 首先要接收一个
capacity 参数作为缓存的最大容量,然后实现两个 API, - 一个是
put(key, val)方法存入键值对, - 另一个是
get(key)方法获取 key 对应的 val,如果 key 不存在则返回 -1。
注意哦,get 和 put 方法必须都是 O(1) 的时间复杂度
分析:
哈希表查找快,但是数据无固定顺序;链表有顺序之分,插入删除快,但是查找慢。所以结合一下,形成一种新的数据结构:哈希链表。
- LRU 缓存算法的核心数据结构就是
哈希链表,双向链表和哈希表的结合体。这个数据结构长这样:
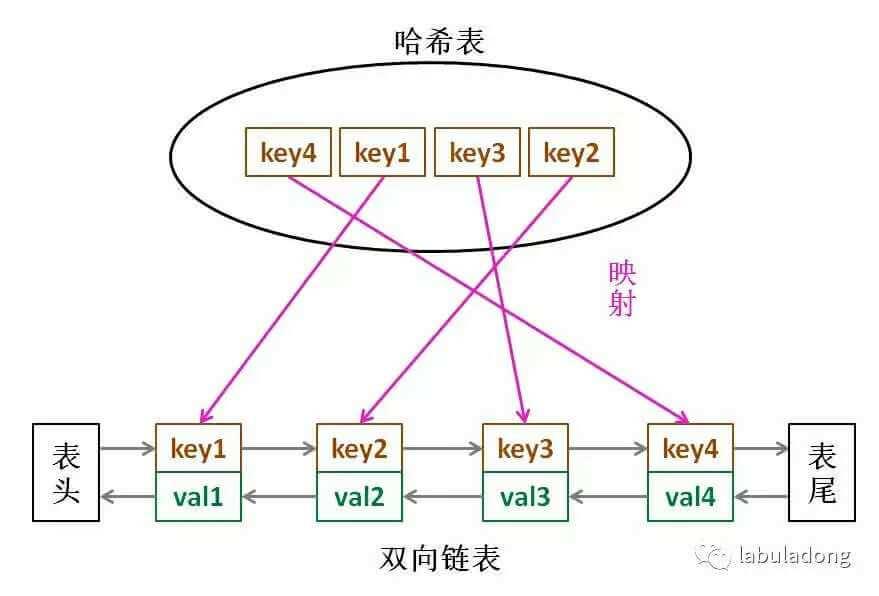
“为什么必须要用双向链表”
- 因为我们需要删除操作。删除一个节点不光要得到该节点本身的指针,也需要操作其前驱节点的指针,而双向链表才能支持直接查找前驱,保证操作的时间复杂度
O(1)。
既然哈希表中已经存了 key,为什么链表中还要存键值对呢,只存值不就行了?
- 当缓存容量已满,我们不仅仅要删除最后一个 Node 节点,还要把 map 中映射到该节点的 key 同时删除,而这个 key 只能由 Node 得到。如果 Node 结构中只存储 val,那么我们就无法得知 key 是什么,就无法删除 map 中的键,造成错误。
3、题解
1、get()操作:两种情况
- 访问的 key 不存在,return -1;
- key 存在,
删除原有(key, value)在 cache 中的位置,把(k, v) 换到队头的新位置,更新map中的key对应的位置
public int get(int key)
Node node = cache.get(key);
if (node == null)
return -1;
// 如果 key 存在,先通过哈希表定位,再移到头部
moveToHead(node);
return node.value;
1、push(k,v)操作:两种情况
- 1、
key 已经存在缓存中,删除原有(key, value)在 cache 中的位置,添加(k,v)在头部,更新map中的key对应的位置 - 2、
key 不存在,判断cache是否已满可以细分为两种情况- cache 没满,
cache添加(k,v)在头部,更新map中的key对应的位置 - cache 已满,
删除map中的cache对应的最后位置的元素,删除list尾部的键值对,cache添加(k,v)在头部,更新map中的key对应的位置
- cache 没满,
public void put(int key, int value)
Node oldNode = cache.get(key);
if (oldNode == null)
Node newNode = new Node(key, value);
cache.put(key, newNode);
addToHead(newNode);
size++;
if (size > capacity)
Node res = removeTail();
cache.remove(res.key);
size--;
else
oldNode.value = value;
moveToHead(oldNode);
综合上述得到:
public class LRUCache
class DLinkedNode
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
public DLinkedNode()
public DLinkedNode(int _key, int _value) key = _key; value = _value;
private Map<Integer, DLinkedNode> cache = new HashMap<Integer, DLinkedNode>();
private int size;
private int capacity;
private DLinkedNode head, tail;
public LRUCache(int capacity)
this.size = 0;
this.capacity = capacity;
// 使用伪头部和伪尾部节点
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.prev = head;
public int get(int key)
DLinkedNode node = cache.get(key);
if (node == null)
return -1;
// 如果 key 存在,先通过哈希表定位,再移到头部
moveToHead(node);
return node.value;
public void put(int key, int value)
DLinkedNode node = cache.get(key);
if (node == null)
// 如果 key 不存在,创建一个新的节点
DLinkedNode newNode = new DLinkedNode(key, value);
// 添加进哈希表
cache.put(key, newNode);
// 添加至双向链表的头部
addToHead(newNode);
++size;
if (size > capacity)
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode tail = removeTail();
// 删除哈希表中对应的项
cache.remove(tail.key);
--size;
else
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
node.value = value;
moveToHead(node);
//节点添加到头部
private void addToHead(DLinkedNode node)
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
//删除任意中间节点
private void removeNode(DLinkedNode node)
node.prev.next = node.next;
node.next.prev = node.prev;
//移动节点到头部
private void moveToHead(DLinkedNode node)
removeNode(node);
addToHead(node);
//删除任意节点,并且返回该节点
private DLinkedNode removeTail()
DLinkedNode res = tail.prev;
removeNode(res);
return res;
以上是关于Java:数据结构笔记之LRU缓存机制的简单理解和使用的主要内容,如果未能解决你的问题,请参考以下文章