人工智能那些事1机器如何完成学习
Posted zstar-_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能那些事1机器如何完成学习相关的知识,希望对你有一定的参考价值。
前言
在上篇文章末尾,我发起了一项投票,调查读者对于人工智能的兴趣程度。调查结果如图所示:
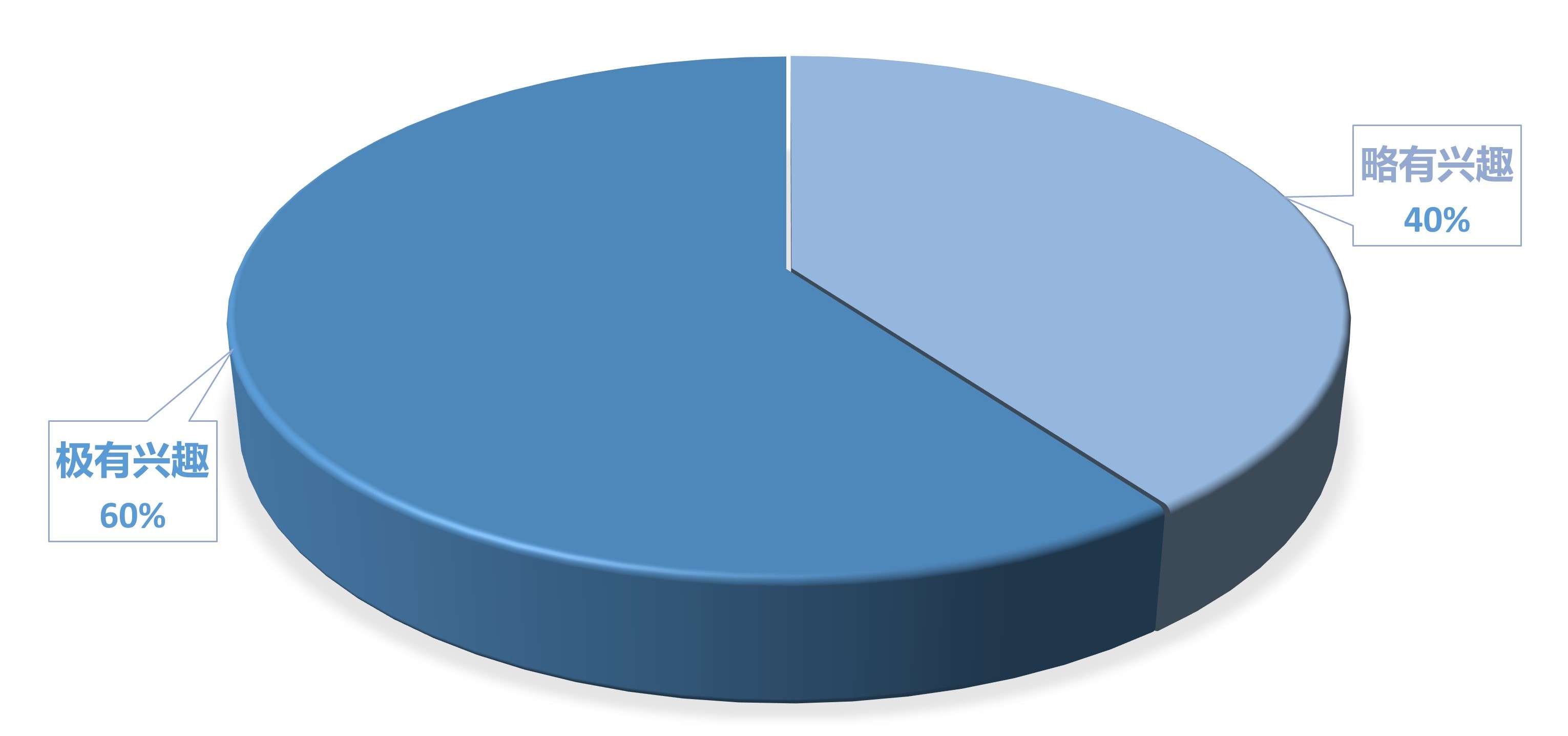
60%的读者表示对人工智能有极度兴趣,40%的读者对此略有兴趣。
为了让该系列的后续文章显得通俗易懂,本篇文章将主要介绍人工智能的背景、发展,以及后面会出现到的一些术语。
人工智能是什么
进入正题,首先需要弄清人工智能是什么。
百科上对此的定义非常浓缩且枯燥,我们使用拆字法的方式可以更容易理解。人工智能可以拆解为“人工”+“智能”,即让计算机完成原本只有人才能做的事情。
人工智能的涵盖很广,具体而言,主要可做下图这样的划分。
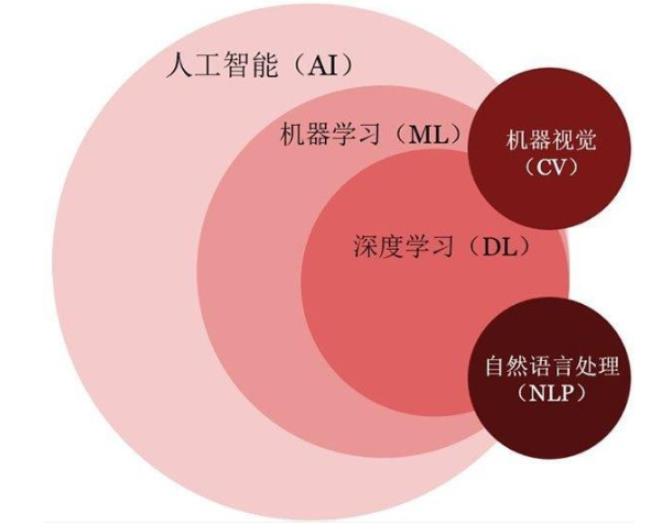
- 最外层:人工智能与机器学习
从图中可以看出,机器学习是人工智能的主要组成部分,其它部分包括一些计算智能的内容。本文我们主要讨论的就是机器学习,在后面会做进一步理解。
- 第二层:机器学习与深度学习
机器学习有很多算法,其中有一种算法称为神经网络。一个基础的神经网络主要包含三部分内容,即输入层,隐藏层,输出层。而深度学习就是就是修改隐藏层的层数,让其不断加深,形成“更深”的神经网络,因此被称为“深度学习”。(这里看不懂没关系,后面会详细讨论神经网络)
- 第三层:深度学习与各领域
虽然图上仅绘制了机器视觉和自然语言处理两个普通领域,事实上还存在诸如推荐系统,语音识别等更多领域。这些领域既用到了深度学习的知识,也和其它科目有交叉。故人工智能是一门”交叉性“学科。
人工智能的起源与发展
大概有了人工智能的概念之后,再对人工智能的发展历程做一个简单的梳理。
人工智能的首次提出是在1956年的达特茅斯会议。之后,人工智能总共经历了三起两落。
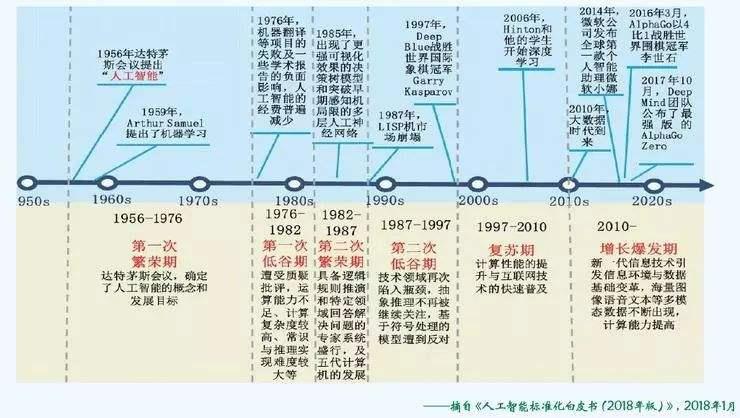
大多数人(包括我)听说人工智能这一概念都是来自于2017年AlphaGo与人类的围棋对弈,而人工智能的发展却已经经历半个世纪,每次陷入低谷,基本上都是由于计算机硬件的不完善。人工智能要想比传统模型有更好的效果,就必须依赖更多的数据。而更多的数据,则需要更好的计算机性能来做支撑。
计算机领域曾有一个著名的”摩尔定律“:当价格不变时,集成电路上可容纳的元器件的数目,约每隔18-24个月便会增加一倍,性能也将提升一倍。换言之,每一美元所能买到的电脑性能,将每隔18-24个月翻一倍以上。当人工智能发展到2010年之后,以前提出的一些算法终于能够被更好的计算机来实现。人工智能从此进入一个新的增长期。
机器是如何进行学习的
下面开始进入机器学习的范围。首先来理解”学习“的概念。
常言道,活到老,学到老。学习是伴随人类一生的东西,或许你会认为学习耳熟能详,上课,写作业都是学习。但了解过机器学习后,或许你会对学习这个概念有个全新的认知。
前面说,人工智能是模拟人的学科,机器学习同样也是如此。因此,想要理解机器是怎么学习的,可以先来考虑,人是怎么学习的。
现在,假如有一个婴儿刚刚降临到世上,你会如何教他认识东西?你可能会拿着一块橡皮让它看,然后告诉他,”这叫做橡皮“。然后过一段时间,再把其他不同的橡皮拿到他面前,他能够说出”这是橡皮“,甚至它看到书上印着橡皮的形状,也会辨识出这就是橡皮。再过一段时间,他学会了画画,让他画一个橡皮,他就能画出类似橡皮的形状。
也许你会觉得上面的例子非常幼稚,但每一句话都包括了机器学习的一个过程。
首先,当你拿起橡皮给他看,并告诉他,这是橡皮。这个过程在机器学习中,被称为 有监督学习,即你不仅把数据(橡皮)输入到了计算机内,并且告诉了它标签(这是橡皮),就像老师监督着自己的学生学习一样的模式。这个过程,称为”模型训练“,输入的数据(橡皮),也被称作训练集。
之后,你把不同的橡皮拿给他看,却不告诉他这是橡皮,而是考验他是否知道这是橡皮。如果他说这是橡皮,那么测试通过,如果他说这不是橡皮,那么测试失败。如果你给他很多个橡皮,他说部分是橡皮,部分不是橡皮。那么我们就可以用准确率来衡量这轮测试的结果,即准确率=答对的个数/总个数。在机器学习中,这个过程被称作“模型测试”,这很多个橡皮被称作测试集。
现在,你已经形象地理解了什么是训练集,什么是测试集,有的时候,你还会在很多书里看到一个概念”验证集“。验证的作用主要是用来筛选/修改模型。还是拿上面这个例子来举例,如果你在拿一堆橡皮(训练集)训练他时,不全部让他过一遍,而是留出一部分来对他进行测试,这部分就是验证集。比如,你让他看了五种牌子的橡皮,告诉他这些都是橡皮,这时候,你再给他看第六块,然后让他判断是不是橡皮,如果他判断错误,可能就是你的教学方式出现了问题。察觉到这一点,或许你就会更改你的教学方式,不仅是只简单地告诉他这是橡皮,而是让他反复端详重复这个概念,从而让他更好地学会辨识橡皮。

测试的手段不仅只是一种,正如上面的例子,你不仅能通过把橡皮(当然这些橡皮是他之前没见过的)拿到它前面进行测试,也可以指着书本上橡皮的图案对他进行测试。如果他的辨认的准确度高,在机器学习上也可称作该模型的泛化能力好。
在上面的过程中,我一直没有强调模型的概念,通过整个训练,验证,测试过程,你或许会认识到,所谓模型就像例子中的那个婴儿。婴儿学习到了如何辨识橡皮,就等同于模型学习了某个知识,该知识就是通过输入的训练数据探索出的某种规律,应用该规律,能够对未知的类似事物进行识别。
过拟合&欠拟合
如果你没被上面的例子绕晕的话,那么你对机器如何实现学习的过程有了充分的了解。现在我们来更进一步,评估一下学习的效果。上文提到,所谓学习,就是掌握知识,从输入的训练集中探索出某种规律。这个学习的过程也可称作拟合。
我们拿一个简单的曲线拟合的例子来举例,假设输入x代表的样本点,一个好的拟合如图所示。

蓝色是拟合线,即学习探索出的规律,该规律能够正确反映样本点的分布。
这是最为理想的情况,更多的时候,由于我们把问题想的过于简单,认为这些样本点可以用一条直线来度量,即下图的这种情况。
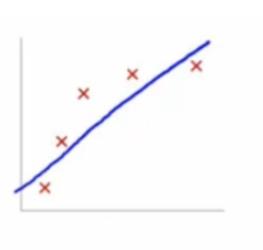
我们发现,虽然曲线拟合了样本点的大致范围,但是却有很多样本点发生偏离。这种情况也被称为**“欠拟合”**。发生这种情况,说明我们学习的不够,还有更多信息没有获取到。
当然,如果达到了最佳拟合的状况时,我们不及时停止,仍然继续学习,这样很可能导致过拟合。
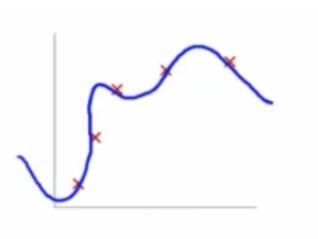
如图所示的这种情况,我们探索出的曲线不仅把每个样本点都精准的探索了出来,然而也把样本自带的噪声学习了进去。所谓噪声,是指样本点自带的误差,比如正确的规律是第一幅图的曲线,样本点由于自身误差,在曲线周边上下波动,这种波动本身是应该忽略的,是干扰数据。而过拟合却把这干扰数据理解为有用的数据,这会导致再新来一个样本点,这个样本点会偏离这条曲线。在模型评估中,往往表现为训练集准确率高,但测试集准确率低。
我们该如何学习
如果上面的例子你没看懂,下面将以更形象的方式来理解什么是过拟合和欠拟合。

现在从机器回到我们人自身,我们在学校上课就是一个学习的过程。我们学习知识,就是在大脑中找到一个规律,这个规律能够正确地拟合课本/上课内容。如果上完课,对课堂讲过的例题大致能理解,但面对课后习题,大脑空空无从下笔,这就是欠拟合。因此,我们需要重新回归课本内容,再次进行学习。如果上完课,对课堂讲过的例题学习得过于透彻了,以至于开始钻牛角尖。面对课后习题,一样的题目只是数据不一样,又不会做,这就是发生了过拟合。这时候就要反思自己是不是没掌握好学习方式。
某种程度上来说,人和机器一样,在没有生理缺陷/机器故障的情况下,任何人只要通过合适的方式都能掌握想学的知识。问题在于,不同人的学习速度不一样,有的人看看课本就能搞懂,有的人听了课还懵懵懂懂。这就可以通过机器学习中的学习率来进行解释。由于该概念和机器学习中的梯度下降法有关,再次不做更深入的展开,后续文章会再会提及。
人工智能的瓶颈
虽然目前是人工智能的繁荣发展期,但人工智能仍然面临着巨大的瓶颈。细心的读者可能会发现,上面我举的橡皮例子中,还有最后一个环节,婴儿学会辨识橡皮之后,不仅仅能够辨识橡皮,而且他能通过别人的语言描述来绘制橡皮,甚至发挥自己的想象力来对橡皮做一个全新的塑造。而这项“简单”的能力对于计算机来说太难了。
前文说过,人工智能的本质就是“模仿”,然而计算机和人类大脑的底层逻辑是完全不一样的。比如,我们思考问题从来不会意识到大脑此刻正在以某种特别的方式处理信息。而计算机做计算时,却仍在内部用二进制传输着数据。
目前的计算机仍坚持冯·诺伊曼结构。
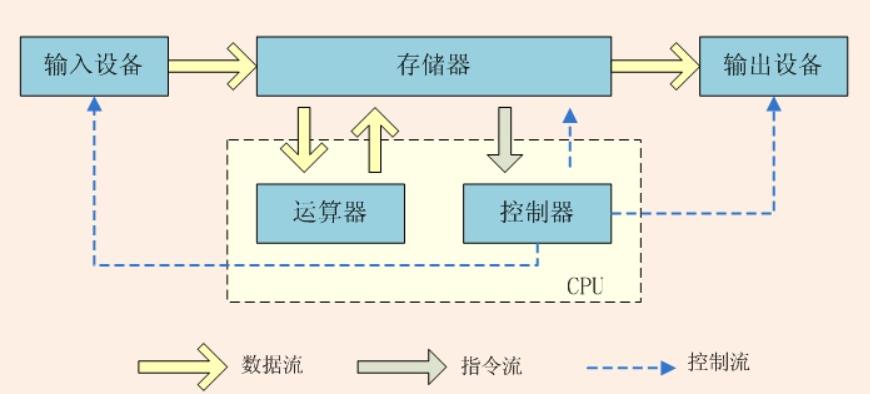
该结构主要存在两点缺陷:
1、将高维信息的处理过程转换成纯时间维度的一维处理过程,其效率低、能耗高;
2、程序或数据往复传输的速率与中央处理器处理信息的速率不匹配导致严重的存储墙效应。
这就导致了计算机的效率远远低于人类。对人类来说,很简单很容易学会的事情,对计算机来说可能需要顶尖硬件支持的计算训练数十个小时。
学习人工智能,你会感受造物主的伟大。虽然AI在某一方面能够击败人类,但它目前始终无法具备人类这样的多重性和创造力。当你阅读这段文字时,数以千计的神经元在你的大脑中进行兴奋传递。而这种信息传递的方式始终未能被成功破解。
或许有一天,类脑计算机出现重大突破,那么人工智能的瓶颈将被突破,繁荣与危机将同时降临。
以上是关于人工智能那些事1机器如何完成学习的主要内容,如果未能解决你的问题,请参考以下文章