数据结构与算法之深入解析“正则表达式匹配”的求解思路与算法示例
Posted Serendipity·y
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法之深入解析“正则表达式匹配”的求解思路与算法示例相关的知识,希望对你有一定的参考价值。
一、题目要求
- 给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 ‘.’ 和 ‘*’ 的正则表达式匹配:
-
- ‘.’ 匹配任意单个字符;
-
- ‘*’ 匹配零个或多个前面的那一个元素。
- 所谓匹配,是要涵盖整个字符串 s 的,而不是部分字符串。
- 示例 1:
输入:s = "aa" p = "a"
输出:false
解释:"a" 无法匹配 "aa" 整个字符串。
- 示例 2:
输入:s = "aa" p = "a*"
输出:true
解释:因为 '*' 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 'a'。因此,字符串 "aa" 可被视为 'a' 重复了一次。
- 示例 3:
输入:s = "ab" p = ".*"
输出:true
解释:".*" 表示可匹配零个或多个('*')任意字符('.')。
- 示例 4:
输入:s = "aab" p = "c*a*b"
输出:true
解释:因为 '*' 表示零个或多个,这里 'c' 为 0 个, 'a' 被重复一次。因此可以匹配字符串 "aab"。
- 示例 5:
输入:s = "mississippi" p = "mis*is*p*."
输出:false
- 提示:
-
- 1 <= s.length <= 20;
-
- 1 <= p.length <= 30;
-
- s 只含小写英文字母;
-
- p 只含小写英文字母,以及字符 . 和 *;
-
- 保证每次出现字符 * 时,前面都匹配到有效的字符。
二、求解算法
① 动态规划
- 明确状态 dp[i][j] 的含义:
dp[i][j]: 表示s的前i个字符与p的前j个字符是否匹配,结果用boolean类型表示。
- 分析状态转移方程:
-
- 对于 p,其只可能有三种情况:
-
-
- 小写字母a-z;
-
-
-
- 点号’.’;
-
-
-
- 星号’*’;
-
-
- p 是小写字母,那么只需要判断 s[i] 是否等于 p[j]:
-
-
- dp[i][j] = dp[i - 1][j - 1]; (s[i] == p[j])
-
-
-
- dp[i][j] = false; (s[i] != p[j])
-
-
- 由于 p == ‘.’,因此 p 可以匹配任一字符,所以:dp[i][j] = dp[i - 1][j - 1];
-
- p 是’ * ',对于 ‘x*’ 意思是:匹配零次或多次 x,因此也是最复杂的情况,对于 s[i] 和 p[j-1],可以再细分为两种情况:
-
-
- s[i] 与 p[j-1] 不匹配:
-
-
-
-
- 对于不匹配来讲,也就是 ‘x*’ 匹配零次,即不使用 ‘x*’,所以此时的状态转移方程为: dp[i][j] = dp[i][j - 2]。
-
-
-
-
-
- 不匹配条件表示为 s[i] != p[j-1],但是只是如此吗?不是的,如果 p[j-1] 是点号’.'的话,那也是匹配的,所以:dp[i][j] = dp[i][j - 2]; (s[i] != p[j-1] && p[j-1] != ‘.’);
-
-
-
-
- s[i] 与 p[j-1] 匹配:
-
-
-
-
- 对于匹配的情况而言,可以是匹配多次(dp[i][j] = dp[i-1][j]),也可以是匹配一次(dp[i][j] = dp[i][j-1]),但是匹配多次是包含了匹配一次的情况,例如:s = “afs”,p = “afs*”,匹配多次:dp[3][4] = dp[2][4],匹配一次:dp[3][4] = dp[3][3];
-
-
-
-
-
- 其实结果上是一样的,都是 true,只不过这里 dp[2][4] 表示不使用 “s*” 时,s 与 p 匹配,而 dp[3][3] 是直接匹配。所以由上得到此种情况下的结论:dp[i][j] = dp[i-1][j]?
-
-
-
-
-
- 显然漏掉一种情况,这里也是最重要的地方,也就是如果 p[j-1] 是 ‘.’ 呢,那既然 '.’ 可以表示任意一段字符串,有什么问题呢?例如:s = “ab”,p = "ab.",dp[2][4] 应该是 true,但是按照上面的写法的话 dp[2][4] = dp[1][4] 就是 false,这里应该匹配零次 “.*”,即:dp[2][4] = dp[2][2]。因此,正确的结论是:dp[i][j] = dp[i-1][j] || dp[i][j - 2];
-
-
- 明确基本情况:
dp[0][0] = true;
dp[i][0] = false; (i > 0)
dp[0][j](j > 0)可能为true
如:s = "", p = "a*"是匹配的
dp[0][0] = true;
for (int j = 1; j <= n; j++)
// dp[0][j]有可能为true,即有x*的时候可以省略
if (p.charAt(j - 1) == '*')
dp[0][j] = dp[0][j - 2];
- Java 示例:
public boolean isMatch(String s, String p)
int m = s.length(), n = p.length();
boolean[][] dp = new boolean[m + 1][n + 1];
// base case
// dp[i][0] = false;
dp[0][0] = true;
for (int j = 1; j <= n; j++)
// dp[0][j]有可能为true,即有x*的时候可以省略
if (p.charAt(j - 1) == '*')
dp[0][j] = dp[0][j - 2];
for (int i = 1; i <= m; i++)
for (int j = 1; j <= n; j++)
char si = s.charAt(i - 1), pj = p.charAt(j - 1);
if ('a' <= pj && pj <= 'z')
if (si == pj)
dp[i][j] = dp[i - 1][j - 1];
else if (pj == '.')
dp[i][j] = dp[i - 1][j - 1];
else
char pre_pj = p.charAt(j - 2);
if (si != pre_pj && pre_pj != '.')
dp[i][j] = dp[i][j - 2];
else
// 这里要加上dp[i][j - 2]是针对于p[j]前一个是'.'的情况
// 如:s = “af”,p = "af.*",dp[2][4]应该是true,所以此时dp[2][4] = dp[2][2];
// 如:s = “afs”,p = "af.*",dp[3][4]也是true,但是此时dp[3][4] = dp[2][4];
dp[i][j] = dp[i - 1][j] || dp[i][j - 2];
return dp[m][n];
② 动态规划(LeetCode 官方解法)
- 题目中的匹配是一个「逐步匹配」的过程:每次从字符串 p 中取出一个字符或者「字符 + 星号」的组合,并在 s 中进行匹配。对于 p 中一个字符而言,它只能在 s 中匹配一个字符,匹配的方法具有唯一性;而对于 p 中字符 + 星号的组合而言,它可以在 s 中匹配任意自然数个字符,并不具有唯一性。因此可以考虑使用动态规划,对匹配的方案进行枚举。
- 用 f[i][j] 表示 s 的前 i 个字符与 p 中的前 j 个字符是否能够匹配,在进行状态转移时,考虑 p 的第 j 个字符的匹配情况:
-
- 如果 p 的第 j 个字符是一个小写字母,那么必须在 s 中匹配一个相同的小写字母,也就是说,如果 s 的第 i 个字符与 p 的第 j 个字符不相同,那么无法进行匹配;否则可以匹配两个字符串的最后一个字符,完整的匹配结果取决于两个字符串前面的部分:
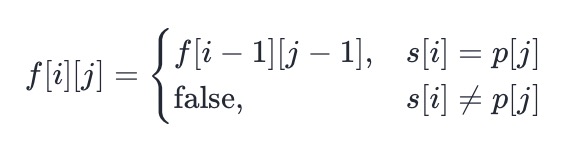
-
- 如果 p 的第 j 个字符是 *,那么就表示可以对 p 的第 j−1 个字符匹配任意自然数次,在匹配 0 次的情况下有:
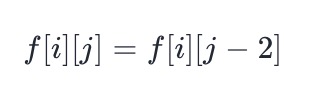
-
-
- 也就是「浪费」了一个字符 + 星号的组合,没有匹配任何 s 中的字符。在匹配 1,2,3,⋯ 次的情况下,类似地有:
-
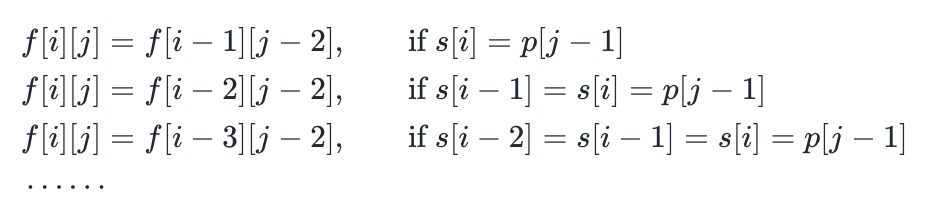
-
-
- 如果通过这种方法进行转移,那么就需要枚举这个组合到底匹配了 s 中的几个字符,会增导致时间复杂度增加,并且代码编写起来十分麻烦。不妨换个角度考虑这个问题:字母 + 星号的组合在匹配的过程中,本质上只会有两种情况:
-
-
-
-
- 匹配 s 末尾的一个字符,将该字符扔掉,而该组合还可以继续进行匹配;
-
-
-
-
-
- 不匹配字符,将该组合扔掉,不再进行匹配。
-
-
-
-
- 如果按照这个角度进行思考,可以写出很精巧的状态转移方程:
-
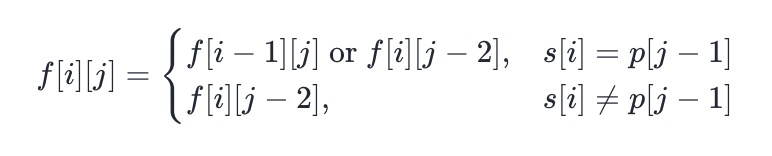
-
- 在任意情况下,只要 p[j] 是 .,那么 p[j] 一定成功匹配 s 中的任意一个小写字母。
- 最终的状态转移方程如下:
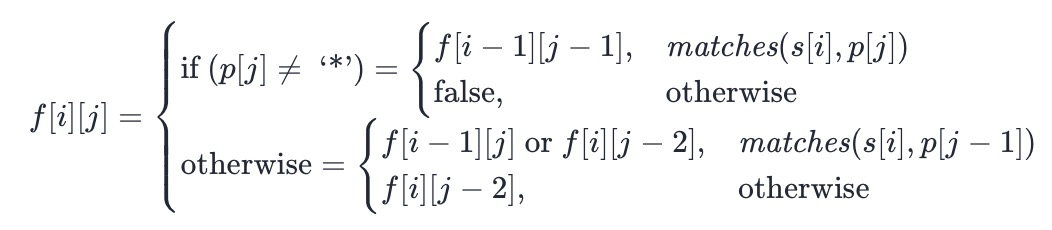
-
- 其中 matches(x,y) 判断两个字符是否匹配的辅助函数。只有当 y 是 . 或者 x 和 y 本身相同时,这两个字符才会匹配。
- 动态规划的边界条件为 f[0][0]=true,即两个空字符串是可以匹配的。最终的答案即为 f[m][n],其中 m 和 n 分别是字符串 s 和 p 的长度。由于大部分语言中,字符串的字符下标是从 0 开始的,因此在实现上面的状态转移方程时,需要注意状态中每一维下标与实际字符下标的对应关系。
- 在上面的状态转移方程中,如果字符串 p 中包含一个「字符 + 星号」的组合(例如 a*),那么在进行状态转移时,会先将 a 进行匹配(当 p[j] 为 a 时),再将 a* 作为整体进行匹配(当 p[j] 为 * 时)。然而,在题目描述中,我们必须将 a* 看成一个整体,因此将 a 进行匹配是不符合题目要求的。
- C++ 示例:
class Solution
public:
bool isMatch(string s, string p)
int m = s.size();
int n = p.size();
auto matches = [&](int i, int j)
if (i == 0)
return false;
if (p[j - 1] == '.')
return true;
return s[i - 1] == p[j - 1];
;
vector<vector<int>> f(m + 1, vector<int>(n + 1));
f[0][0] = true;
for (int i = 0; i <= m; ++i)
for (int j = 1; j <= n; ++j)
if (p[j - 1] == '*')
f[i][j] |= f[i][j - 2];
if (matches(i, j - 1))
f[i][j] |= f[i - 1][j];
else
if (matches(i, j))
f[i][j] |= f[i - 1][j - 1];
return f[m][n];
;
- Java 示例:
class Solution
public boolean isMatch(String s, String p)
int m = s.length();
int n = p.length();
boolean[][] f = new boolean[m + 1][n + 1];
f[0][0] = true;
for (int i = 0; i <= m; ++i)
for (int j = 1; j <= n; ++j)
if (p.charAt(j - 1) == '*')
f[i][j] = f[i][j - 2];
if (matches(s, p, i, j - 1))
f[i][j] = f[i][j] || f[i - 1][j];
else
if (matches(s, p, i, j))
f[i][j] = f[i - 1][j - 1];
return f[m][n];
public boolean matches(String s, String p, int i, int j)
if (i == 0)
return false;
if (p.charAt(j - 1) == '.')
return true;
return s.charAt(i - 1) == p.charAt(j - 1);
- 复杂度分析:
-
- 时间复杂度:O(mn),其中 m 和 n 分别是字符串 s 和 p 的长度,需要计算出所有的状态,并且每个状态在进行转移时的时间复杂度为 O(1)。
-
- 空间复杂度:O(mn),即为存储所有状态使用的空间。
以上是关于数据结构与算法之深入解析“正则表达式匹配”的求解思路与算法示例的主要内容,如果未能解决你的问题,请参考以下文章
数据结构与算法之深入解析“股票的最大利润”的求解思路与算法示例