Python字符串中的'\'输入
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python字符串中的'\'输入相关的知识,希望对你有一定的参考价值。
RT,
引号内放一个反斜杠时报错了,不懂的是放两个反斜杠,返回的字符串里也出来了两个。。。
2.7.5,IDLE
怎么才能只输入一个反斜杠呢
\r : 回车, \n : 换行, \t : 制表符 ..
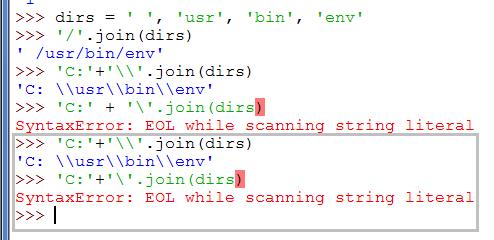
为了表达字符"反斜杠(\)" 需要在其前面在加一个反斜杠 : \\
就是说,你看到的字符串中的 \\ 就是一个 "\".
另:你可以用os.path.join("C:", *dirs)来完成这种路径字符串的连接。 参考技术A 怎样才能只输出一个反斜杠?
因为你用的IDLE
'c:'+'\\'.join(dirs)返回的是字符串而不是输出,所以带有两个反斜杠
用print('c:'+'\\'.join(dirs))就能输出一个反斜杠。
从Python中的字符串中删除所有非数字字符
【中文标题】从Python中的字符串中删除所有非数字字符【英文标题】:Removing all non-numeric characters from string in Python 【发布时间】:2010-11-17 23:24:47 【问题描述】:我们如何从 Python 中的字符串中删除所有非数字字符?
【问题讨论】:
可能重复:***.com/questions/947776/… 【参考方案1】:这应该适用于 Python2 中的字符串和 unicode 对象,以及 Python3 中的字符串和字节:
# python <3.0
def only_numerics(seq):
return filter(type(seq).isdigit, seq)
# python ≥3.0
def only_numerics(seq):
seq_type= type(seq)
return seq_type().join(filter(seq_type.isdigit, seq))
【讨论】:
【参考方案2】:许多正确答案,但如果您希望它直接浮动,而不使用正则表达式:
x= '$123.45M'
float(''.join(c for c in x if (c.isdigit() or c =='.'))
123.45
您可以根据需要更改逗号的点。
如果您知道您的数字是整数,请更改此设置
x='$1123'
int(''.join(c for c in x if c.isdigit())
1123
【讨论】:
【参考方案3】:@Ned Batchelder 和 @newacct 提供了正确的答案,但是 ...
以防万一您的字符串中有逗号(,)小数(。):
import re
re.sub("[^\d\.]", "", "$1,999,888.77")
'1999888.77'
【讨论】:
【参考方案4】:只是为了添加另一个选项,string 模块中有几个有用的常量。虽然在其他情况下更有用,但它们可以在这里使用。
>>> from string import digits
>>> ''.join(c for c in "abc123def456" if c in digits)
'123456'
模块中有几个常量,包括:
ascii_letters (abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ)
hexdigits (0123456789abcdefABCDEF)
如果您大量使用这些常量,则值得将它们转换为frozenset。这样可以进行 O(1) 次查找,而不是 O(n),其中 n 是原始字符串的常量长度。
>>> digits = frozenset(digits)
>>> ''.join(c for c in "abc123def456" if c in digits)
'123456'
【讨论】:
''.join(c for c in "abc123def456" if c.isdigit()) 在我的 python 3.4 中工作【参考方案5】:如果您需要执行不止一个或两个这样的删除操作(或者甚至只是一个,但在一个很长的字符串上!-),最快的方法是依赖字符串的 translate 方法,即使它确实需要一些准备:
>>> import string
>>> allchars = ''.join(chr(i) for i in xrange(256))
>>> identity = string.maketrans('', '')
>>> nondigits = allchars.translate(identity, string.digits)
>>> s = 'abc123def456'
>>> s.translate(identity, nondigits)
'123456'
translate 方法不同,而且在 Unicode 字符串上使用起来可能比在字节字符串上更简单,顺便说一句:
>>> unondig = dict.fromkeys(xrange(65536))
>>> for x in string.digits: del unondig[ord(x)]
...
>>> s = u'abc123def456'
>>> s.translate(unondig)
u'123456'
您可能希望使用映射类而不是实际的 dict,尤其是当您的 Unicode 字符串可能包含具有非常高的 ord 值的字符时(这会使 dict 过大;-)。例如:
>>> class keeponly(object):
... def __init__(self, keep):
... self.keep = set(ord(c) for c in keep)
... def __getitem__(self, key):
... if key in self.keep:
... return key
... return None
...
>>> s.translate(keeponly(string.digits))
u'123456'
>>>
【讨论】:
(1) 不要硬编码幻数; s/65536/sys.maxunicode/ (2) 字典无条件地“过大”,因为输入“可能”包含(sys.maxunicode - number_of_non_numeric_chars) 条目。 (3) 考虑 string.digits 是否可能不足以导致需要破解 unicodedata 模块 (4) 考虑 re.sub(r'(?u)\D+', u'', text) 为简单和潜在速度。【参考方案6】:
>>> import re
>>> re.sub("[^0-9]", "", "sdkjh987978asd098as0980a98sd")
'987978098098098'
【讨论】:
可能是 re.sub(r"\D", "", "sdkjh987978asd098as0980a98sd") 这可能是:从重新导入子 如何将 sub 应用于字符串? @JamesKoss【参考方案7】:不确定这是否是最有效的方法,但是:
>>> ''.join(c for c in "abc123def456" if c.isdigit())
'123456'
''.join 部分意味着将所有生成的字符组合在一起,中间没有任何字符。然后剩下的就是一个列表推导,其中(你可能猜到了)我们只取字符串中匹配条件isdigit的部分。
【讨论】:
反之。我认为您的意思是“不是 c.isdigit()” 删除所有非数字 == 只保留数字。 我喜欢这种方法不需要重新拉入,对于这个简单的功能。 请注意,与使用 str.translate 的实现不同,此解决方案适用于 python 2.7 和 3.4。谢谢! 我更喜欢这种选择。使用正则表达式对我来说似乎有点过头了。以上是关于Python字符串中的'\'输入的主要内容,如果未能解决你的问题,请参考以下文章