深度学习优化算法大全系列1:概览
Posted bitcarmanlee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习优化算法大全系列1:概览相关的知识,希望对你有一定的参考价值。
1.深度学习优化算法概览图
深度学习(其实也包括传统的机器学习)中的优化算法,丰富多彩多种多样。如果没有从逻辑上有条主线理清楚,很容易会陷入混乱。因此我参考前人的总结,特意总结了一张图,将这些优化算法的逻辑关系理顺一下。
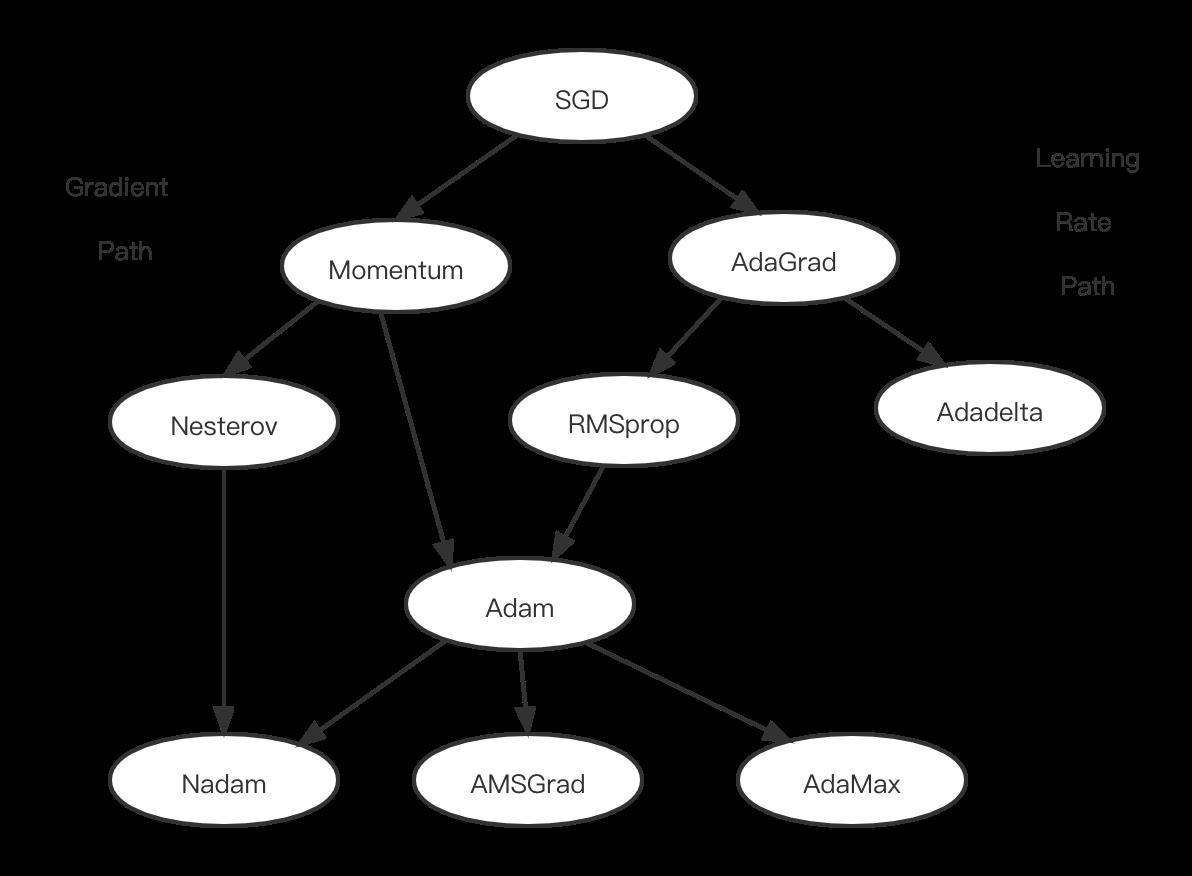
上面的图,从两个方面对优化算法进行逻辑梳理:以最基础的SGD为起点,左半部分针对梯度方向进行优化,右半部分针对学习率进行优化。
根据上面图片,不难看出,深度学习优化算法发展过程基本如下:
SGD->SGDM->Nesterov->AdaGrad->AdaDelta->Adam->Nadam
后面我们针对上述算法将分别介绍。
2.优化算法框架
根据参考文献1,提出用一个框架表述所有的优化算法,个人认为总结很赞,因此贴出来供大家参考:
定义待优化参数
ω
\\omega
ω,目标函数
f
(
ω
)
f(\\omega)
f(ω),初始学习率
α
\\alpha
α。
在每个epoch t进行迭代时:
1.根据目标函数计算当前参数的梯度:
g
t
=
▽
f
(
ω
t
)
g_t=\\bigtriangledown f(\\omega_t)
gt=▽f(ωt)
2.根据历史梯度计算一阶动量与二阶动量
m
t
=
ϕ
(
g
1
,
g
2
,
⋯
,
g
t
)
V
t
=
φ
(
g
1
,
g
2
,
⋯
,
g
t
)
m_t = \\phi(g_1, g_2, \\cdots, g_t)\\\\ V_t = \\varphi(g_1, g_2, \\cdots, g_t)
mt=ϕ(g1,g2,⋯,gt)Vt=φ(g1,g2,⋯,gt)
3.计算当前时刻的下降梯度
η
t
=
α
⋅
m
t
/
V
t
\\eta_t = \\alpha \\cdot m_t / \\sqrtV_t
ηt=α⋅mt/Vt
4.根据下降梯度进行更新
ω
t
+
1
=
ω
t
−
η
t
\\omega_t+1 = \\omega_t - \\eta_t
ωt+1=ωt−ηt
各种优化算法基本都是上述框架,步骤3,4都一致,不同就体现在第1,2两点。
以传统的SGD为例:
m
t
=
g
t
V
t
=
I
2
m_t=g_t\\\\ V_t = I^2
mt=gtVt=I2
则对于步骤三,梯度下降时,
η
t
=
α
⋅
g
t
\\eta_t = \\alpha \\cdot g_t
ηt=α⋅gt
这就是我们见到的传统的最简单梯度下降的方式。
参考文献
1.https://zhuanlan.zhihu.com/p/32230623
以上是关于深度学习优化算法大全系列1:概览的主要内容,如果未能解决你的问题,请参考以下文章