Word转PDF文件,如何在PDF中嵌入字体
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Word转PDF文件,如何在PDF中嵌入字体相关的知识,希望对你有一定的参考价值。
请按照以下操作步骤(以下为通过Microsoft Word 2010输出PDF文件的方法):
使用Word编辑文件;
点击左上角的 “档案”;
选择左边中间偏下的 “保存并发送”;
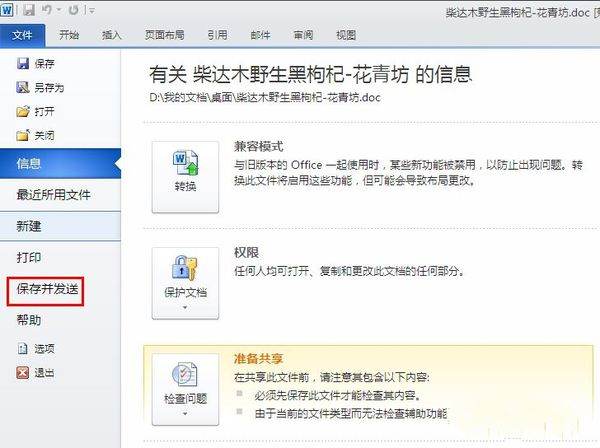
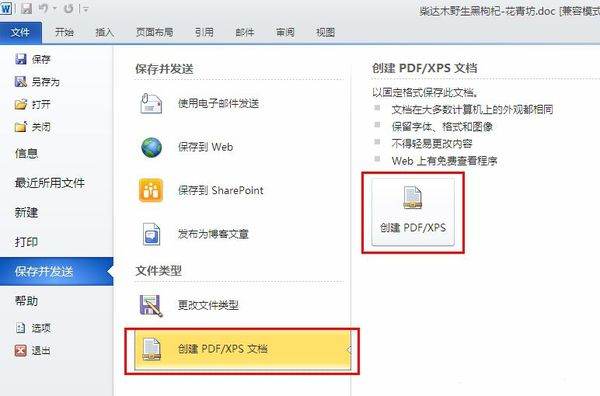
接著点选 “建立PDF/XPS文档”;
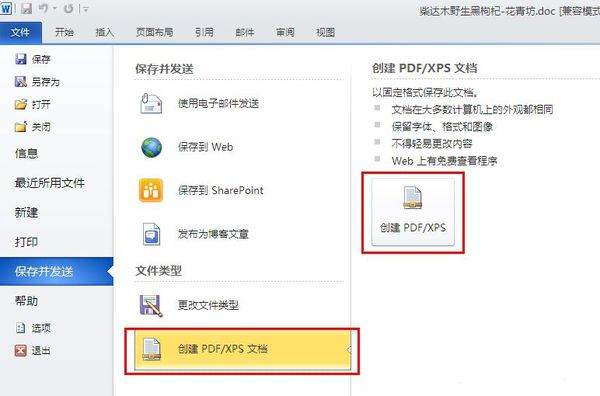
继续往右点选 “建立PDF/XPS”;
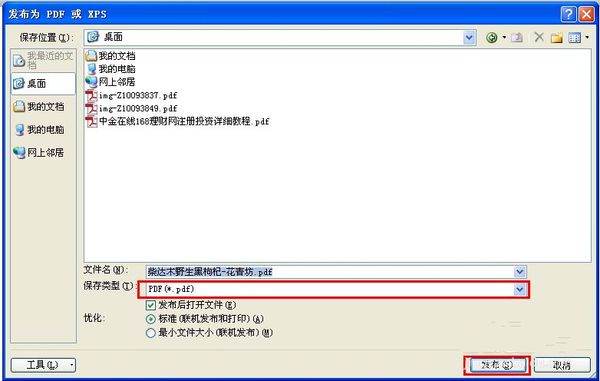
在跳出的窗口中,输入文件名称,并於下方找到 “选项”;
进入选项後,将倒数第二个方格打勾 “无法内迁字型时,使用点阵图文字”;
接著确定并发布即可。
pdf文件不能编辑,所以需要先在word设置好之后再将word转换成pdf,下面是word转pdf格式的方法:
第一步:打开转换器,选择转换格式;
第二步:添加要转的文件并设置保存路径;
第三步:单击开始转换。
参考资料:http://jingyan.baidu.com/article/7f766dafab85e34101e1d0b1.html
参考技术B 做法如下:1.打印-选Adobe PDF,然后点 属性2. 在Adobe PDF设置中,点 “编辑”,会跳出个新窗口。 3. 在新窗口中,选“字体”,在嵌入所有字体前打勾,然后把 字体来源的所有字体都添加到“总是嵌入”,然后按确定,会把这个设定保持成一个名字(可默认也可以自己改名),回到Adobe PDF设置窗口。 4. 然后在默认设置的下拉框中选你刚才设置好的那个字体设置的名字,并且把“不要发送字体到Adobe PDF“前的勾去掉。按"ok",然后按打印。 5.检查所有字体是否都已经嵌入。在打开的PDF文档中,文件-文档属性-字体,看是否所有字体名字的后面是否有“已嵌入子集”,如果都有,那说明所有字体已经嵌入,如果还有字体后面没有出现这些字眼,说明这些字体还未嵌入,要再想办法。6. 如果是用Matlab画的eps图,会出现“Helvetica" 和“Times-Bold ” 字体未嵌入的情况,办法如下:用文本打开eps文件,出现的是图片的源代码,把里面的 “Helvetica”字体换成“ NimbusSanL-Regu”,把“Times-Bold“ 换成“TimesNewRomanPS-BoldMT” 即可。反正就是把这个文档里面不能嵌入的字体换成可以嵌入的字体,可以在刚才上面添加的字体库中去选个合适的字体来替换。本回答被提问者采纳如何在现有 PDF 中嵌入字体?
【中文标题】如何在现有 PDF 中嵌入字体?【英文标题】:How do I embed fonts in an existing PDF? 【发布时间】:2011-05-13 00:17:33 【问题描述】:背景:
我有以编程方式生成的 PDF。我需要能够将 PDF 从服务器直接发送到打印机(而不是通过中间应用程序)。目前我可以执行上述所有操作(生成 PDF,发送到打印机),但由于字体未嵌入到 PDF 中,打印机正在执行字体替换。
为什么字体在生成时没有嵌入:
我正在使用 SQL Reporting Services 2008 创建 PDF。SQL Reporting Services 存在一个已知问题,即它不会嵌入字体(除非满足一系列要求 - http://technet.microsoft.com/en-us/library/ms159713%28SQL.100%29.aspx)。不要问我为什么,PDF 符合 MS 列出的所有要求,并且字体仍然显示为未嵌入 - 无法真正控制字体是否被嵌入,所以我接受了这不起作用并继续前进. Microsoft 建议的解决方法(http://blogs.msdn.com/b/donovans/archive/2007/07/20/reporting-services-pdf-renderer-faq.aspx 在“Reporting Services 何时进行字体嵌入”下)是对 PDF 进行后处理以手动嵌入字体。
目标 获取一个已经生成的 PDF 文档,以编程方式“打开”它并嵌入字体,重新保存 PDF。
接近 我被指向 iTextSharp,但大多数示例都是针对 Java 版本的,我在转换为 iTextSharp 版本时遇到了麻烦(我找不到任何 iTextSharp 文档)。
我正在写这篇文章以完成我需要做的事情:Itext embed font in a PDF。
但是,在我的一生中,我似乎无法使用 ByteArrayOutputStream 对象。它似乎找不到它。我进行了研究和研究,但似乎没有人说它在哪个类或我在哪里找到它,所以我可以将它包含在 using 语句中。我什至破解了打开的反射器,但似乎在任何地方都找不到。
这是我到目前为止所拥有的,它可以编译等等。 (结果是我生成的 PDF 的 byte[])。
PdfReader pdf = new PdfReader(result);
BaseFont unicode = BaseFont.CreateFont("Georgia", BaseFont.IDENTITY_H, BaseFont.EMBEDDED);
// the next line doesn't work as I need a ByteArrayOutputStream variable to pass in
PdfStamper stamper = new PdfStamper(pdf, MISSINGBYTEARRAYOUTPUTSTREAMVARIABLE);
stamper.AcroFields.SetFieldProperty("test", "textfont", unicode, null);
stamper.Close();
pdf.Close();
那么任何人都可以帮助我使用 iTextSharp 将字体嵌入 PDF 或指出正确的方向吗?
我非常乐意使用除 iTextSharp 之外的任何其他解决方案来完成此目标,但它必须是免费的并且能够被企业用于内部应用程序(即 Affero GPL)。
【问题讨论】:
能否给出需要嵌入的字体名称? (某些字体确实具有不允许嵌入的许可证,并且大多数 PDF 处理或创建软件确实尊重字体文件中的相应标志并选择不嵌入它们......) 当然! Georgia 和 Calibri - 我检查了我们是否有 TrueType 版本,并且(根据 Windows)它们都将“字体嵌入性”标签设置为“可编辑”——我认为这是正确的设置?感谢您的帮助! 对于以后阅读本文的任何人,这两种方法都有效。 SQL Reporting Services 在多次更新/修补程序后最终正确嵌入了字体,并且可以直接发送到打印机。此外,使用 .NET 中的 ProcessInfo 调用 Ghostscript 可以对 PDF 进行后处理。 【参考方案1】:这可能不是您正在寻找的答案(因为您希望以编程方式解决问题,而不是通过外部工具)。
但是您可以使用 Ghostscript 命令行将缺少的字体嵌入到没有嵌入它们的 PDF 中:
gs \
-sFONTPATH=/path/to/fonts:/another/dir/with/more/fonts \
-o output-pdf-with-embedded-fonts.pdf \
-sDEVICE=pdfwrite \
-dPDFSETTINGS=/prepress \
input-pdf-where-some-fonts-are-not-embedded.pdf
一件重要的事情是缺少的字体都可以在-sFontPath=... 开关指向的目录之一中找到。
【讨论】:
@hanzworld:你能提供pdffonts.exe original.pdf和pdffonts.exe processed.pdf的输出吗? (pdffonts.exe 是此处提供的 XPDF CLI 实用程序的一部分:foolabs.com/xpdf/download.html
嘿,hanzworld:正如我告诉你的那样——重要的一点是,在-sFONTPATH=... 开关所指向的目录之一中都可以找到丢失的字体。你做了这个了吗?!? Ghostscript 没有找到所需的字体(Calibri,Georgia)。因此,它使用 Helvetica 作为替代字体。只需将 Calibri + Calibri,Bold + Georgia,BoldItalic 复制到任何路径,然后将 -sFONTPATH=/path/to/where/calibri-etc/are/copied/to/ 与您的 Ghostscript 命令一起使用...(注意 -sFONTPATH... 的拼写已更改
在win32上,如果你安装了ghostScript,命令可能如下: gswin32 -sFONTPATH=C:\Windows\Fonts -o output-pdf-with-embedded-fonts.pdf -sDEVICE=pdfwrite -dPDFSETTINGS=/prepress input-pdf-where-some-fonts-are-not-embedded.pdf
这会破坏 PDF 表单字段(如果您正在寻找没有嵌入字体的 PDF 表单的答案)。我想知道是否有 gs 命令参数来保留它?
@Fuhrmanator:FOSS 软件和 PDF 表单——《FOSS 缺失或吸收的重要功能列表》一书中的一长篇......【参考方案2】:
除了 Ghostscript,还可以使用 Poppler 和 Cairo。 Poppler 有一个命令pdftocairo 通过pdftocairo -pdf input.pdf output.pdf 将PDF 转换为PDF。它还考虑在Fontconfig 配置文件中设置的字体替换。如果您的系统上没有 PDF 文件中引用的所有字体,但知道您安装的其他字体是一个好看的替代品,这将非常有用。处理后嵌入替换字体。
【讨论】:
+ 1 : -- 嘿,我不知道! :-) 我现在相信它会像你描述的那样工作。稍后会测试。但如果它不起作用,我将不得不再次收回我的 u p o t e... :-) 这比使用gs 容易得多——我什至可以记住这个命令。
这很好用。只是给 Windows cygwin 用户的注意事项 - 如果您尝试在 cygwin 下运行它,它可能会使用不同的字体来改变图像的外观。从标准命令提示符使用Poppler for Windows 效果很好。感谢您发布此答案。
在 Ubuntu 上完美运行!
poppler 在转换到 cairo 时会保留 PDF 表单结构吗? gs 答案打破了表格。【参考方案3】:
我在 Mac 上遇到了这个问题,我正在提交给 IEEE 的 PDF。使用 Adobe Reader 和 Preview,我能够解决这个问题。如果您在 PC 上,我认为任何 pdf 打印机都可以代替 Preview。
这是我采取的步骤。您可以单独修复每个图形,也可以修复整个文档。
使用 Adobe Reader 打开 pdf 文件。
右键单击图像,然后单击“文档属性”。
单击“字体”。检查字体是否未嵌入。应该说“Courier”或其他字体名称。
如果您的 pdf 不是标准页面大小,请单击“说明”并查看页面大小。把这个写下来。前任。 19.4 x 5.22 英寸。
在预览中打开 pdf。转到文件->打印。如果使用非标准页面大小的 pdf,请单击纸张大小并选择自定义。您将需要创建一个与您在第 4 步中记下的大小相等的自定义页面大小。不要忘记将所有边的边距归零为 0。完成后,您需要在打印对话框中将打印比例设置为 100%。
在打印对话框的左下方(在 Mac 上的预览中),单击“PDF”将 PDF 打印为新的 PDF。选择目的地并打印。
在 Adobe Reader 中打开新的 pdf 并验证字体现在是否已嵌入。
我希望这会有所帮助。
【讨论】:
【参考方案4】:我今天在上传到 lulu.com 以制作打印副本的现有 PDF 时遇到了这个问题。它因未嵌入所有字体而被拒绝。
我发现如果我在 Acrobat X 中打开它并保存为 postscript .ps 文件,然后当我在文件资源管理器中双击这个 .ps 文件时,它会在 Acrobat X Distiller 中打开,这会自动创建一个新的 PDF 文件嵌入所有字体!
当然,这意味着您必须拥有计算机上所需的所有字体。否则,像 InFix 这样的程序可以进行字体替换。
【讨论】:
以上是关于Word转PDF文件,如何在PDF中嵌入字体的主要内容,如果未能解决你的问题,请参考以下文章