DDD课程学习思考
Posted hanruikai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DDD课程学习思考相关的知识,希望对你有一定的参考价值。
领域驱动设计
软件复杂度成因:
规模:分解
结构:边界
变化:顺应变化方向
隔离业务复杂度与技术复杂度;
业务与技术是正交的。
如果不用DDD,我们基本是
- 数据建模,然后数据驱动设计。数据仅仅提供信息,实体是协作关系。
- 事务模型和贫血脚本
根据模块划分的架构,对变化响应能力不足。
DDD 的核心思想就是要避免业务逻辑的复杂度与技术实现的复杂度混淆在一起,确定业务逻辑与技术实现的边界,从而隔离各自的复杂度,业务逻辑并不关心技术是如何实现的。无论采用何种技术,只要业务需求不变,业务规则就不会变化。理想状态下,应该保证业务逻辑与技术实现是正交的。
DDD 通过分层架构与六边形架构确保业务逻辑与技术实现的隔离。
全局分析阶段
统一语言UL
领域和子领域
根据业务流程,梳理领域和子领域
架构映射阶段
识别BC,限界上下文,每一个BC其实就是一个业务单元。
六边形架构

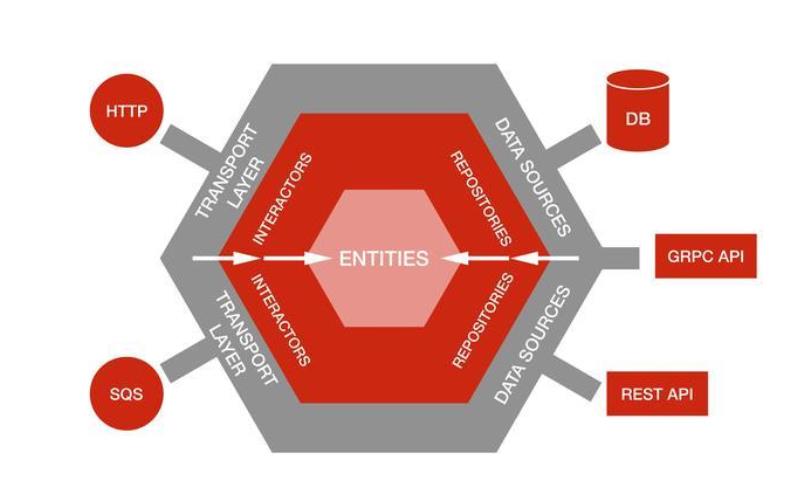
六边形每条不同的边代表了不同类型的端口,端口要么处理输入,要么处理输出。对于每种外界类型,都有一个适配器与之对应,外界通过应用层API与内部进行交互。
上图中有3个客户请求均抵达相同的输入端口(适配器A、B和C),另一个客户请求使用了适配器D。假设前3个请求使用了HTTP协议(浏览器、REST和SOAP等),而后一个请求使用了AMQP协议(比如RabbitMQ)。
端口并没有明确的定义,它是一个非常灵活的概念。无论采用哪种方式对端口进行划分,当客户请求到达时,都应该有相应的适配器对输入进行转化,然后端口将调用应用程序的某个操作或者向应用程序发送一个事件,控制权由此交给内部区域。应用程序通过公共API接收客户请求,使用领域模型来处理请求。我们可以将DDD战术设计的建模元素Repository的实现看作是持久化适配器,该适配器用于访问先前存储的聚合实例或者保存新的聚合实例。正如图中的适配器E、F和G所展示的,我们可以通过不同的方式实现资源库,比如关系型数据库、基于文档的存储、分布式缓存或内存存储等。如果应用程序向外界发送领域事件消息,我们将使用适配器H进行处理。该适配器处理消息输出,而上面提到的处理AMQP消息的适配器则是处理消息输入的,因此应该使用不同的端口。
六边形架构还是一种分层架构,如上图所示,它被分为了三层:端口适配器、应用层与领域层。而端口又可以分为输入端口和输出端口。
-
输入端口
用于系统提供服务时暴露API接口,接受外部客户系统的输入,并客户系统的输入转化为程序内部所能理解的输入。系统作为服务提供者是对外的接入层可以看成是输入端口。 -
输出端口
为系统获取外部服务提供支持,如获取持久化状态、对结果进行持久化,或者发布领域状态的变更通知(如领域事件)。系统作为服务的消费者获取服务是对外的接口(数据库、缓存、消息队列、RPC调用)等都可以看成是输入端口。 -
应用层
定义系统可以完成的工作,很薄的一层。它并不处理业务逻辑通过协调领域对象或领域服务完成业务逻辑,并通过输入端口输出结果。也可以在这一层进行事物管理。 -
领域层
负责表示业务概念、规则与状态,属于业务的核心。
应用层与领域层的不变性可以保证核心领域不受外部的干扰,而端口的可替换性可以很方便的对接不用的外部系统。
参考文章:https://www.jianshu.com/p/c2a361c2406c
六边形架构的初衷是为了解决技术与业务系统的解耦合问题,以及技术与技术间的解耦合问题,这一架构从设计模式中来,从业务的实体服务出发,将面向接口的设计具体化的端口协议和适配器实现,将业务实体实现自服务的完备性,可以看作是微服务的一个理论基础吧。
六边形架构的依赖图向内收缩
在传统的分层架构中,我们所有的依赖项都会指向一个方向,上面的每一层都会依赖自己下面的层。传输层会依赖交互器,而交互器会依赖持久存储层。
在六边形架构中,所有依赖项都指向中心方向。我们的核心业务逻辑对传输层或数据源一无所知。但传输层仍然知道如何使用交互器,数据源也知道如何对接存储库接口。
DDD vs 数据模型驱动
传统的业务开发模式里,研发受到关系型数据库设计范式、ER 图等影响深远,在做软件详细设计过程中往往先想到如何设计对应的表结构,由此倒推出业务逻辑代码该如何组织。这就是典型的数据模型驱动设计,或者叫面向数据表设计编程。数据模型设计关注的是数据存储,数据尽量不要冗余,控制表数量不膨胀,更多考虑数据的扩展性,比如新加一个字段尽量不要在几张表都加,能用一个字段表达就不用两个字段。
这样的思维跟 DDD 是相反的,DDD 优先考虑领域概念的业务语义表达,具有独立业务概念的东西会尽量抽象成一个内聚的领域对象。领域对象不仅仅有属性,还有该有的行为。
因此,基于数据模型驱动的设计结果往往是:
1. 业务逻辑代码非常过程式,领域实体只包含一堆属性,只是数据表的映射,没有业务行为。也就是常说的只有 getter 和 setter 方法的贫血对象。非常缺乏领域概念的表达,业务逻辑散乱。比如值对象的设计在 DDD 里是一个类,在数据模型设计里往往是其他类的几个属性。
2. 聚合是 DDD 最小的复用单元,粒度更粗。数据模型设计里领域实体的数量跟表数量一一对应,数据表是最小的复用单元,粒度太细。导致业务逻辑对应的实现类需要访问很多的领域实体,实现类之间的调用关系发散而错综复杂。下图是贫血模型和 DDD 富血模型的区别。
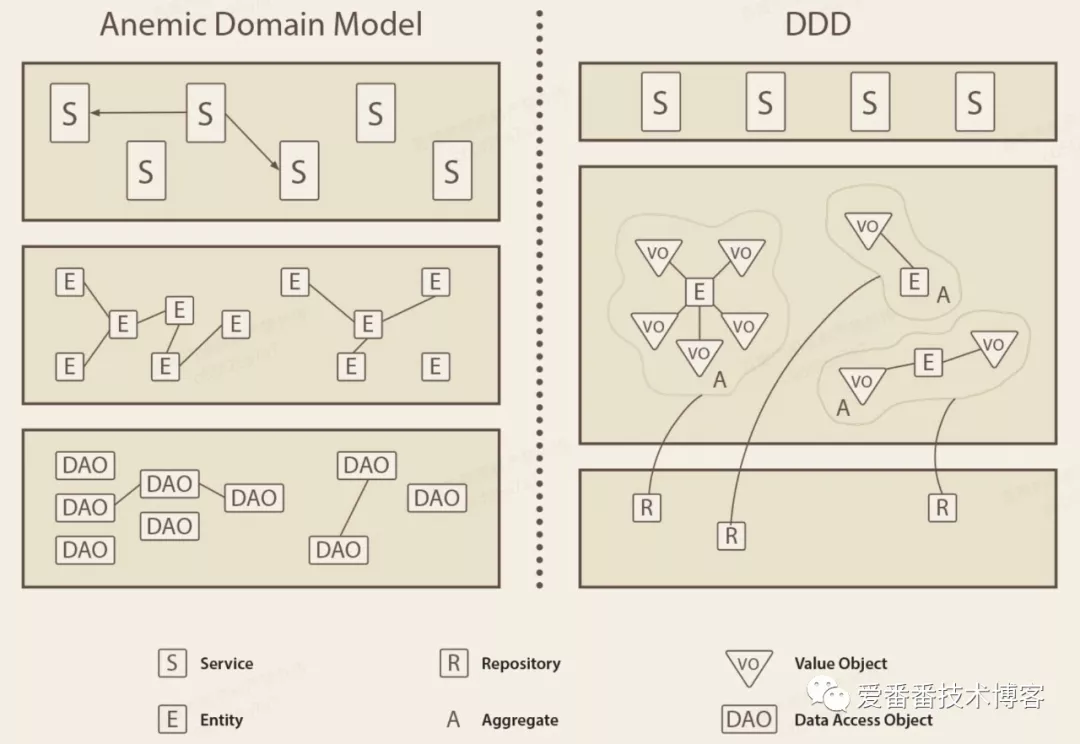
3. 数据表的关系表达很受限,具有主从关系的表之间很难看出主从。在 DDD 里聚合和聚合内的实体、值对象之间的关系在代码层面有显示的表达。
当然,DDD 思想里不是说不用考虑数据表设计,而是要优先考虑领域概念的识别和建模。表设计需要服务于领域模型的设计,是技术实现的细节。因此明白 DDD 和数据模型驱动设计的区别反过来能更好地理解 DDD。
基于事件风暴的结果,需要把领域名词和规则等划分到合适的限界上下文。根据前面介绍的如何划分限界上下文的方法,线索相关功能划分为几个限界上下文合适呢?这个时候需要看业务逻辑的复杂程度,还要结合团队规模大小。由于线索功能包含很多业务逻辑,线索归集和创建、线索的分配、线索的跟进等都可以成为一个独立的限界上下文。定义好限界上下文后还需要定义不同限界上下文的协作关系。一般情况下如果业务允许的情况尽量选择通过领域事件来协作。根据《领域驱动设计》所述常见的协作关系还包括开放主机服务(即通过暴露接口)、共享内核、防腐层等 9 种。
微服务架构下的限界上下文之间的关系比较常见的有领域事件、开放主机服务、防腐层等。
https://xie.infoq.cn/article/bf97ac8a495f9e8e9f8bb0d77
以上是关于DDD课程学习思考的主要内容,如果未能解决你的问题,请参考以下文章