Elasticsearch:使用 Elasticsearch Transforms 进行产品推荐
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:使用 Elasticsearch Transforms 进行产品推荐相关的知识,希望对你有一定的参考价值。
这篇博文将引导你完成从包含订单项的索引创建产品推荐的步骤。 推荐在很多的 eCommerce 网站上可以看到:
这篇文章展示了如何使用转换(transforms)从不断更新的订单项目中自动创建此数据,并在索引新产品时利用丰富处理器来存储推荐。

为了开始,我使用 File Visualizer 从 kaggle 导入电子商务数据集。 我下载了 olist_order_items_dataset,其中包含一个带有订单项的 CSV 文件。
如果你不关心我们的示例数据的导入,请直接跳到转换数据的步骤部分。
安装
我们首先需要安装 Elasticsearch 及 Kibana。当然最容易的方法是启动 Elastic Cloud 。你只需要花几分钟的实践就可以启动一个 Elasticsearch 的集群。你可以有14天的试用期,而不用提供任何的信用卡之类的付费信息。对于国内的开发者来说,你可以在阿里巴巴及腾讯云上启动 Elasticsearch 集群,并试用。具体文章可以参阅:
如果你想自己部署 Elasticsearch,请参阅我之前的文章:
对于喜欢 docker 部署的开发者来说,请参阅我的文章
使用 File Visualizer 工具导入数据
打开 Kibana:
在上面,我们选择下载的文件 olist_order_items_dataset.csv:
使用文件可视化工具,你可以在导入前查看一些导入统计信息。点击上面的 Import 按钮:
在上面,我们选上 Create index pattern,这样我们可以不用之后再单独去为这个索引创建一个 index pattern。有了 index pattern,我们可以在 Kibana 的 Discover 中进行查看数据。
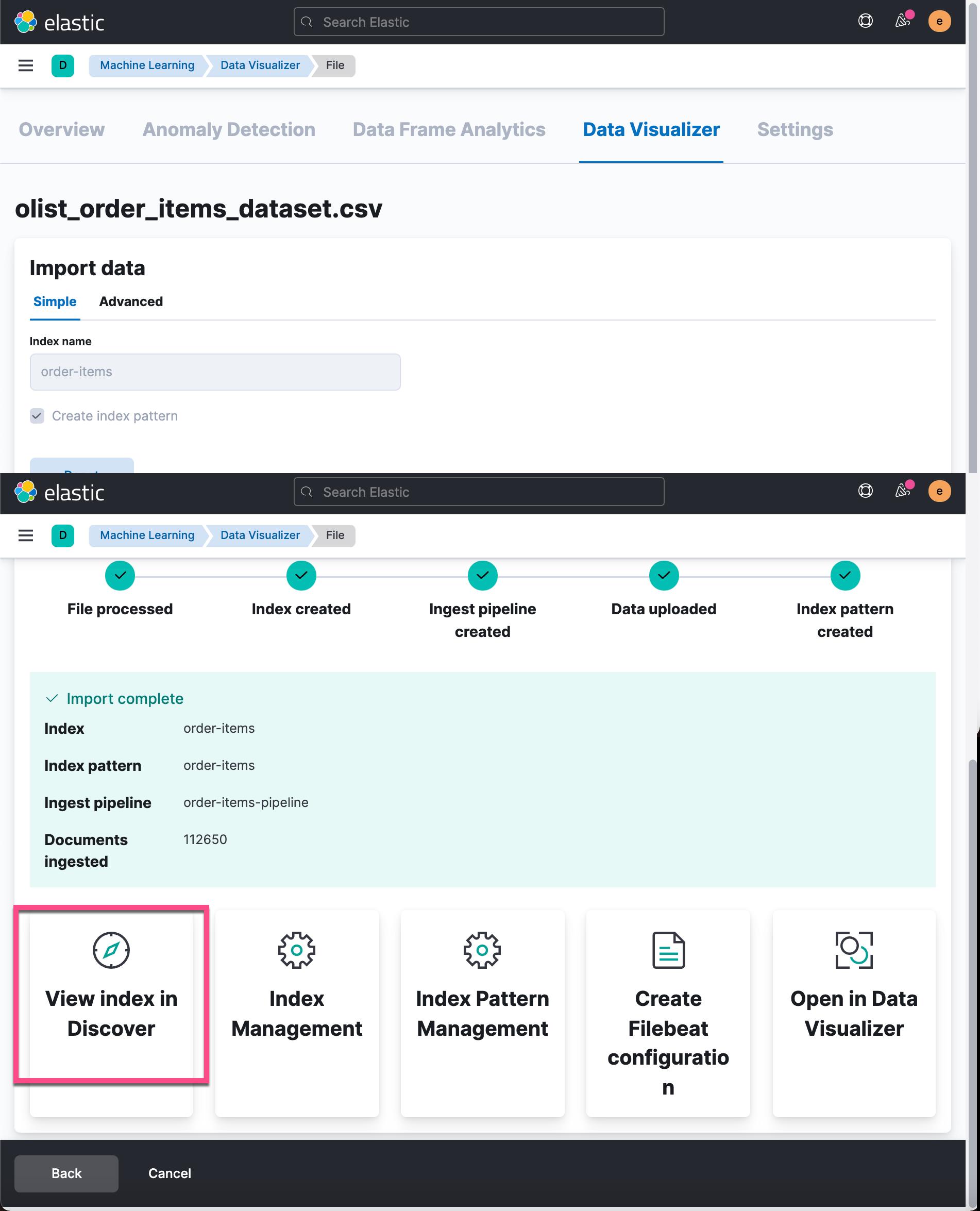
从上面的过程中,我们可以看得出来 import complete。为了查看摄入的数据,我们可以点击 View index in Discover:
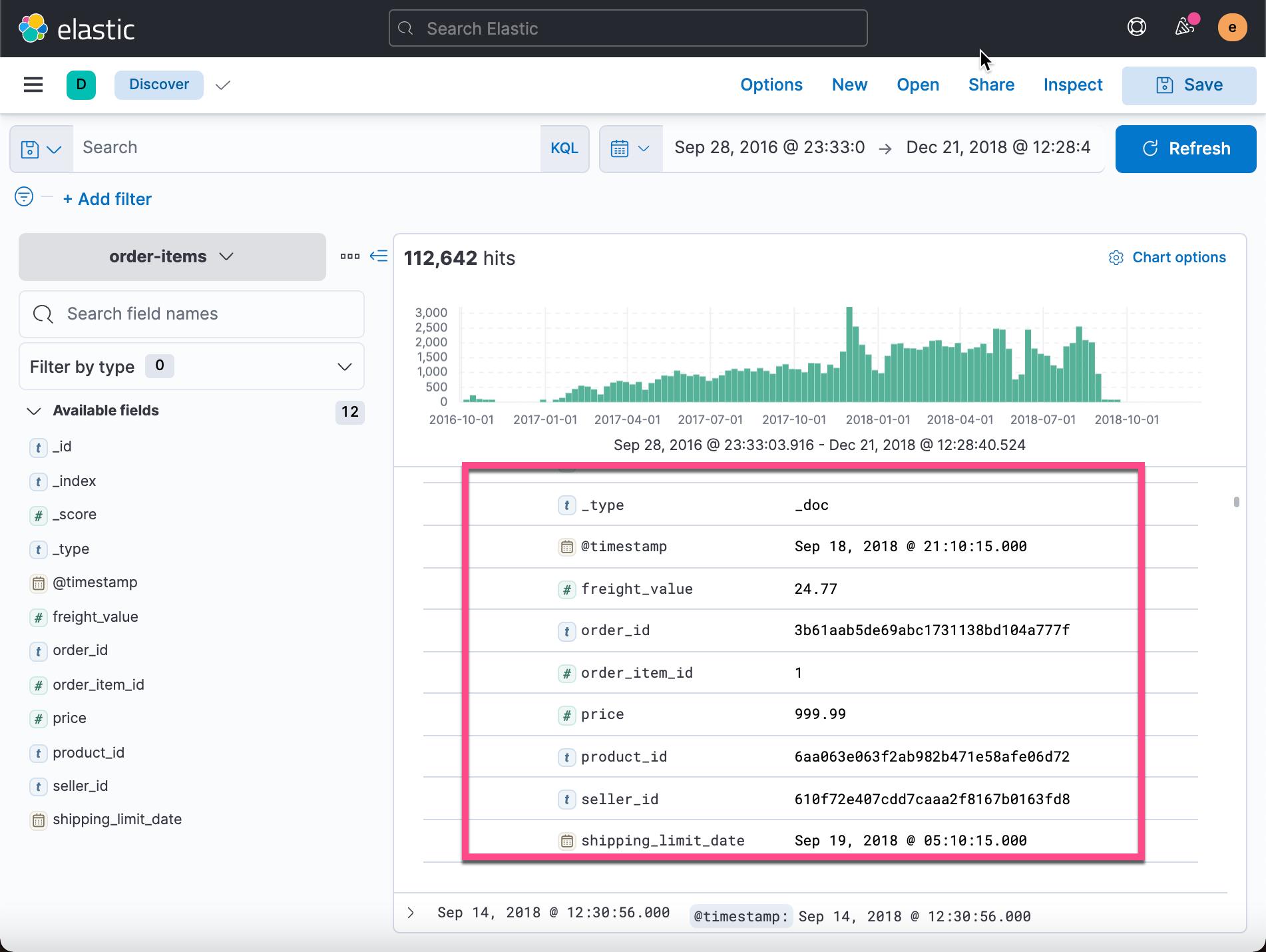
从上面的显示中我们可以看出来每个文档的一些字段(除去以 _ 开头的元字段): freight_value,order_id,order_item_id,price,product_id,seller_id,shipping_limit_date。
到此为止,我们已经完成了数据的摄入工作。
转换数据的步骤
数据集包含订单项目,因此订单的每个项目都有一个文档。 看起来像这样:
"order_item_id" : 1,
"@timestamp" : "2017-09-26T02:11:19.000+02:00",
"price" : 89.9,
"product_id" : "764292b2b0f73f77a0272be03fdd45f3",
"order_id" : "4427e7da064254d8af538aca447a560c",
"freight_value" : 12.97,
"seller_id" : "bd23da7354813347129d751591d1a6e2",
"shipping_limit_date" : "2017-09-26 02:11:19"
对于 Transforms 来说,它是针对每个 entity 来进行的转换。显然上面能够代表这个数据的 entity 是 product_id 及 order_id。这里有两个字段对我们很重要,即 order_id 和 product_id。
那么,我们如何从这样的数据集中获得基于每个产品的建议的能力? 通过根据不同的分组标准从该数据创建新索引。 所以基本上我们需要从 order_id->product_id 映射到 product_id->recommend_ids 映射,完全独立于产品订单。 让我们尝试像这样转换数据两次:

从订单项目转变为产品推荐
那么,这张图是什么意思呢? 首先,我们将未分组的订单商品列表转换为订单列表,其中包含属于该订单的产品。
我们的第二步将是类似产品的文档索引,其中包含已一起订购的产品列表。
转换为 orders
为了理解问题,我们尝试手动查找一起订购的产品。
首先,找到购买最多的产品:
GET order-items/_search
"size": 0,
"aggs":
"by_product_id":
"terms":
"field": "product_id",
"size": 10
上面的搜索显示:
"aggregations" :
"by_product_id" :
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 108777,
"buckets" : [
"key" : "aca2eb7d00ea1a7b8ebd4e68314663af",
"doc_count" : 527
,
"key" : "99a4788cb24856965c36a24e339b6058",
"doc_count" : 488
,
"key" : "422879e10f46682990de24d770e7f83d",
"doc_count" : 484
,
"key" : "389d119b48cf3043d311335e499d9c6b",
"doc_count" : 392
,
"key" : "368c6c730842d78016ad823897a372db",
"doc_count" : 388
,
"key" : "53759a2ecddad2bb87a079a1f1519f73",
"doc_count" : 373
,
"key" : "d1c427060a0f73f6b889a5c7c61f2ac4",
"doc_count" : 343
,
"key" : "53b36df67ebb7c41585e8d54d6772e08",
"doc_count" : 323
,
"key" : "154e7e31ebfa092203795c972e5804a6",
"doc_count" : 281
,
"key" : "3dd2a17168ec895c781a9191c1e95ad7",
"doc_count" : 274
]
最多的一个产品被购买 527 次。我们可以使用如下的命令来查看所有的订单:
GET order-items/_search
"query":
"term":
"product_id":
"value": "aca2eb7d00ea1a7b8ebd4e68314663af"
所以这会从 527 个结果中返回 10 个订单项。 我们可以天真地通过以下方式收集客户端的所有订单 IDs:
GET order-items/_search?filter_path=**.order_id
"size": 10000,
"query":
"term":
"product_id":
"value": "aca2eb7d00ea1a7b8ebd4e68314663af"
上述命令将返回类似如下的结果:
"hits" :
"hits" : [
"_source" :
"order_id" : "b9a3648dcf60f6b902216e563c539244"
,
"_source" :
"order_id" : "b9d5bea267e1dd6838786cc12ba40ceb"
,
"_source" :
"order_id" : "ba2018431e2b0cec56147edc7a0627a5"
,
...然后使用术语过滤器通过将先前响应中的所有 order_id 添加到以下查询中的术语过滤器来过滤那些:
GET order-items/_search
"size": 0,
"query":
"bool":
"filter": [
"terms":
"order_id": [
"44676f5946200b6318a3a13b081396bc",
"..."
]
]
,
"aggs":
"by_order":
"terms":
"field": "product_id",
"size": 10
这将在 aggs 响应中为我们提供三个产品 ID 的列表
"aggregations" :
"by_order" :
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
"key" : "aca2eb7d00ea1a7b8ebd4e68314663af",
"doc_count" : 527
,
"key" : "28b4eced95a52d9c437a4caf9d311b95",
"doc_count" : 1
,
"key" : "7fb7c9580222a2af9eb7a95a6ce85fc5",
"doc_count" : 1
]
第一个搜索到的是产品本身,需要删除。 这给我们留下了一起购买的两种产品。 我们参与了很多查询。 让我们尝试用这个转换来解决并逐步解释它:
PUT _ingest/pipeline/orders-set-id
"description": "Sets _id to order id",
"processors": [
"script":
"lang": "painless",
"source": "ctx._id = ctx.order_id;"
]
PUT _transform/order-item-transform-to-orders
"source": "index": "order-items" ,
"dest": "index": "orders", "pipeline": "orders-set-id" ,
"frequency": "1h",
"pivot":
"group_by":
"order_id":
"terms":
"field": "order_id"
,
"aggregations":
"products":
"scripted_metric":
"init_script": "state.docs = [:];state.docs.products = []",
"map_script": """
state.docs.products.add(doc['product_id'].value);
""",
"combine_script": "return state.docs",
"reduce_script": """
def products = new HashSet();
for (state in states)
products.addAll(state.products);
return ['ids': products, 'length':products.size()];
"""
POST _transform/order-item-transform-to-orders/_start
# wait a second for the first run to finish, then run
GET orders/_count依次运行上面的命令。过一会儿后,最后一个命令给出来的结果是:
"count" : 98666,
"_shards" :
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
通过数据集,我们有 112650 个初始订单项。 将它们简化为订单列表会导致 98666 个订单。 所以我们的大部分订单都是单品订单。
让我们一步一步地解释上面的转换。 首先,我们定义一个 source.index 来获取数据,以及一个 dest.index 来写入数据。 然后频率决定变换在后台运行的频率。 pivot.group_by 条件是分组依据的字段。 由于我们要按订单分组以收集所有产品 ID,因此 order_id 是初始分组条件。
现在是花哨的部分 - scripted metric aggregation。 一种以最自定义的方式为聚合收集数据的非常强大的方法。 如果你对这个不是很明白的话,请参阅我之前的文章 “Elasticsearch:Script aggregation (2)”。scripted metric aggregation 由四个阶段组成,每个阶段都是可编写脚本的。 第一阶段允许初始化在其他阶段重用的数据结构。 在此示例中,在 init_script 中创建了一个示例文档映射,其中包含一个空的 products 数组。
state.docs = [:];
state.docs.products = [];下一个阶段是 map_script,它为每个匹配查询的文档执行一次(所以在这个例子中的每个文档都会被执行)。
state.docs.products.add(doc['product_id'].value);下一个名为 combine_script 的阶段对每个分片(shard)执行一次,并允许通过在发送之前做一些更多的工作来减少发送到协调节点(coordinating node)的数据。
return state.docs;最后一步是从所有订单项目的不同分片中收集所有数据,并为该单个订单创建最终数据结构。 在此示例中,我们将产品 ID 收集到一个集合中(以防止重复),并存储该集合的大小以允许更轻松的范围查询。
def products = new HashSet();
for (state in states)
products.addAll(state.products);
return ['ids': products, 'length':products.size()];我们来首先看看一个 orders 索引里的一个文档是啥样的:
GET orders/_search
"size": 1
上面的命令显示:
"took" : 15,
"timed_out" : false,
"_shards" :
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
,
"hits" :
"total" :
"value" : 10000,
"relation" : "gte"
,
"max_score" : 1.0,
"hits" : [
"_index" : "orders",
"_type" : "_doc",
"_id" : "00010242fe8c5a6d1ba2dd792cb16214",
"_score" : 1.0,
"_source" :
"order_id" : "00010242fe8c5a6d1ba2dd792cb16214",
"products" :
"length" : 1,
"ids" : [
"4244733e06e7ecb4970a6e2683c13e61"
]
]
显示的订单由单个订单项目组成。有了这个索引,只要我们知道一个产品 ID,就可以通过这个索引找到一起订购的产品,例如本例中的 0bcc3eeca39e1064258aa1e932269894。
GET orders/_search
"size": 0,
"query":
"bool":
"filter": [
"term":
"products.ids.keyword": "0bcc3eeca39e1064258aa1e932269894"
]
,
"aggs":
"products":
"terms":
"field": "products.ids.keyword",
"size": 10
这将返回以下聚合响应:
"aggregations" :
"products" :
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 4,
"buckets" : [
"key" : "0bcc3eeca39e1064258aa1e932269894",
"doc_count" : 100
,
"key" : "422879e10f46682990de24d770e7f83d",
"doc_count" : 6
,
"key" : "368c6c730842d78016ad823897a372db",
"doc_count" : 4
,
"key" : "389d119b48cf3043d311335e499d9c6b",
"doc_count" : 3
,
"key" : "53759a2ecddad2bb87a079a1f1519f73",
"doc_count" : 3
,
"key" : "b0961721fd839e9982420e807758a2a6",
"doc_count" : 3
,
"key" : "3773a3773f5978591cff7b3e614989b3",
"doc_count" : 1
,
"key" : "4b5df063d69ffafb87c279672ecb4191",
"doc_count" : 1
,
"key" : "4e1346d7b7e02c737a366b086462e33e",
"doc_count" : 1
,
"key" : "774e21c631ca26cba7b5606bdca7460f",
"doc_count" : 1
]
所以,我们用这个产品买了一堆其他的产品! 第一个产品是我们查询的产品 - 你可以手动过滤掉它或更改聚合以排除它,如下所示:
"aggs":
"products":
"terms":
"field": "products.ids.keyword",
"size": 10,
"exclude": "0bcc3eeca39e1064258aa1e932269894"
该列表的其余部分是一个排序列表,其中包含一起购买的产品,包括基于这些文档组合的订单数量的权重。 挺整洁的!
我们还可以要求最小文档计数,以便像这样出现在结果列表中:
"aggs":
"products":
"terms":
"field": "products.ids.keyword",
"size": 10,
"exclude": "0bcc3eeca39e1064258aa1e932269894",
"min_doc_count": 2
在这个例子中,这会将我们的结果减少到五个,并确保购买的产品之间存在更强的相关性。
所以,基本上我们现在已经完成了,不是吗? 如果您有一个小数据集,这可能足以在每次用户观看你的页面(包括此类推荐)时运行聚合。 你也可以简单地将上述结果缓存 10 分钟,以防止当许多用户查看同一产品时出惊群效应(thundering herd)问题。
然而,我们也可以继续,而不是基于订单的数据,我们可以有一个以产品为中心的索引。 只需再变换一次!
转化为产品推荐
为了节省你一些时间摆弄,让我们先添加一个摄入管道,以解决一些小问题
PUT _ingest/pipeline/products-remove-own-id-pipeline
"description": "Removes the own product id from the list of recommended product ids and renames the 'ids' field",
"processors": [
"script":
"lang": "painless",
"source": """
ctx.ids.removeAll([ctx.product_id]);
ctx['recommendation_ids'] = ctx.remove('ids');
ctx._id = ctx.product_id;
"""
]
此管道删除 ids 元素中的重复项,然后将 ids 重命名为 Recommendation_ids。 最后一部分是将 _id 设置为产品的 id 而不是自动生成的。
好的,现在让我们使用先前转换创建的索引作为输入来创建一个转换:
PUT _transform/orders-transform-to-products
"source":
"index": "orders",
"query":
"range":
"products.length":
"gt": 1
,
"dest":
"index": "product-recommendations",
"pipeline" : "products-remove-own-id-pipeline"
,
"frequency": "1h",
"pivot":
"group_by":
"product_id":
"terms":
"field": "products.ids.keyword"
,
"aggregations":
"ids":
"scripted_metric":
"init_script": "state.docs = [:];state.docs.products = []",
"map_script": """
for (def i = 0; i< doc['products.ids.keyword'].size();i++)
def id = doc['products.ids.keyword'].get(i);
state.docs.products.add(id);
""",
"combine_script": "return state.docs",
"reduce_script": """
def products = new HashSet();
for (state in states)
products.addAll(state.products);
return products;
"""
POST _transform/orders-transform-to-products/_start这里的主要区别是包含大部分逻辑的 map_script 以及 group_by 分组标准。 首先,使用 orders 索引,但只有那些具有多个订单项的订单才用作输入,否则将不会有其他产品的链接。 这次 group_by 标准是产品 id,因为这是我们希望成为新索引的基础。
由于 product.length 查询过滤器,我们已经知道 product.ids 数组将大于单个元素。 因此,在 map_script 中,我们遍历该数组,对于找到的每个产品 ID,我们将其附加到 stats.docs.products 数组。 在有多个分片的情况下,最后的减少发生在减少脚本中,通过再次使用集合来防止重复。
是时候看看我们上面使用的产品了:
GET product-recommendations/_doc/0bcc3eeca39e1064258aa1e932269894上述命令将生成:
"_index" : "product-recommendations",
"_type" : "_doc",
"_id" : "0bcc3eeca39e1064258aa1e932269894",
"_version" : 1,
"_seq_no" : 227,
"_primary_term" : 1,
"found" : true,
"_source" :
"recommendation_ids" : [
"dfc9d9ea4c2fbabe7abb0066097d9905",
"368c6c730842d78016ad823897a372db",
"98e0de96ebb0711db1fc3d1bad1a902f",
"3773a3773f5978591cff7b3e614989b3",
"4e1346d7b7e02c737a366b086462e33e",
"4b5df063d69ffafb87c279672ecb4191",
"53759a2ecddad2bb87a079a1f1519f73",
"b0961721fd839e9982420e807758a2a6",
"389d119b48cf3043d311335e499d9c6b",
"9d1893083966b9c51109f0dc6ab0b0d9",
"422879e10f46682990de24d770e7f83d",
"774e21c631ca26cba7b5606bdca7460f",
"d1c427060a0f73f6b889a5c7c61f2ac4"
],
"product_id" : "0bcc3eeca39e1064258aa1e932269894"
你可以看到摄取管道已经工作,因为 _id 等于 product_id 并且 product_id 不是 Recommendation_ids 数组的一部分。
与之前的查询相比,这种特定方法有一个弱点:我们失去了所有权重。 与查询相比,没有任何迹象表明一个产品是否被一起购买过一次或八次,并且推荐 ID 字段也未按此排序。 我们应该先解决这个问题,然后再进一步。
在变换中添加回权重
看起来,我们只需要一张带有计数的 map。 因此,让我们通过预览功能处理转换(如果稍后运行,请不要忘记存储转换,本文未显示):
一、停止变换,删除变换,删除索引
POST _transform/orders-transform-to-products/_stop
DELETE _transform/orders-transform-to-products
DELETE product-recommendations由于数据结构不同,而不仅仅是 id 数组,因此接下来更新摄取管道:
PUT _ingest/pipeline/products-remove-own-id-pipeline
"description": "Removes the own product id from the list of recommended product ids and renames the 'ids' field",
"processors": [
"script":
"lang": "painless",
"source": """
ctx.ids.removeIf(p -> p.id.equals(ctx.product_id));
ctx['recommendation_ids'] = ctx.remove('ids');
ctx._id = ctx.product_id;
"""
]
现在让我们调整 transform:
POST _transform/_preview
"source":
"index": "orders",
"query":
"range":
"products.length":
"gt": 1
,
"dest":
"index": "product-recommendations",
"pipeline": "products-remove-own-id-pipeline"
,
"frequency": "1h",
"pivot":
"group_by":
"product_id":
"terms":
"field": "products.ids.keyword"
,
"aggregations":
"ids":
"scripted_metric":
"init_script": "state.docs = [:];state.docs.products = [:]",
"map_script": """
// push all products into an array
for (def i = 0; i< doc['products.ids.keyword'].size();i++)
def id = doc['products.ids.keyword'].get(i);
state.docs.products.compute(id, (k, v) -> (v == null) ? [ 'id':id, 'count': 1L] : [ 'id':id, 'count': v.count+1]);
""",
"combine_script": "return state.docs",
"reduce_script": """
// merge same ids together
def products = [];
for (state in states)
for (product in state.products.values())
def id = product.id;
def optional = products.stream().filter(p -> id.equals(p.id)).findFirst();
if (optional.isPresent())
optional.get().count += product.count;
else
products.add(product);
// sort list by count of products!
Collections.sort(products, (o1,o2) -> o2.count.compareTo(o1.count));
return products;
"""
# Change the above request to save the transform instead of preview, then start
PUT _transform/orders-transform-to-products
..
POST _transform/orders-transform-to-products/_start现在重新启动转换后,我们可以对产品 ID 运行一个简单的 GET 请求:
GET product-recommendations/_doc/0bcc3eeca39e1064258aa1e932269894
"_index" : "product-recommendations",
"_type" : "_doc",
"_id" : "0bcc3eeca39e1064258aa1e932269894",
"_version" : 1,
"_seq_no" : 227,
"_primary_term" : 1,
"found" : true,
"_source" :
"product_id" : "0bcc3eeca39e1064258aa1e932269894",
"recommendation_ids" : [
"count" : 6,
"id" : "422879e10f46682990de24d770e7f83d"
,
"count" : 4,
"id" : "368c6c730842d78016ad823897a372db"
,
"count" : 3,
"id" : "53759a2ecddad2bb87a079a1f1519f73"
,
"count" : 3,
"id" : "b0961721fd839e9982420e807758a2a6"
,
"count" : 3,
"id" : "389d119b48cf3043d311335e499d9c6b"
,
// more documents with a count of 1
]
现在通过检索这样的文档,客户端可以决定计数 1 是否足以显示产品。
将其放入自己的索引还有一个好处。 由于能够查询包含其一起购买的产品的文档,我们甚至可以进一步在索引时添加此信息,当使用丰富策略对产品进行索引时。
如果你想获得有关转换的更多统计信息,可以运行:
GET _transform/order-item-transform-to-orders/_stats
GET _transform/orders-transform-to-products/_stats创建丰富策略
想象一下,我们将店面的产品存储在产品索引中。 每当组件更新产品时,我们都可以使用一起购买的产品的 ID 来丰富它。 现在我们有了一个现成的产品推荐指数,下一步是创建一个丰富的策略。
PUT /_enrich/policy/product-recommendation-policy
"match":
"indices": "product-recommendations",
"match_field": "product_id",
"enrich_fields": ["recommendation_ids"]
POST /_enrich/policy/product-recommendation-policy/_execute这会在该策略中创建一个中间索引。 请注意,这需要在更改后执行,以便策略与后台的索引保持同步。
接下来是一个摄取管道,它使用文档的 _id 字段查询上述策略。 重命名和删除处理器只是为了对数据结构进行一些清理,但完全是可选的。
PUT _ingest/pipeline/product-recommendations-pipeline
"processors": [
"enrich":
"policy_name": "product-recommendation-policy",
"field": "_id",
"target_field": "ids"
,
"rename":
"field": "ids.recommendation_ids",
"target_field": "recommendation_ids"
,
"remove":
"field": "ids"
]
最后是一些索引的时间,然后检索文档以查看管道是否正确应用:
PUT products/_doc/0bcc3eeca39e1064258aa1e932269894?pipeline=product-recommendations-pipeline
"title" : "My favourite product"
GET products/_doc/0bcc3eeca39e1064258aa1e932269894上面命令的输出为:
"_index" : "products",
"_type" : "_doc",
"_id" : "0bcc3eeca39e1064258aa1e932269894",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" :
"title" : "My favourite product",
"recommendation_ids" : [
"count" : 6, "id" : "422879e10f46682990de24d770e7f83d" ,
"count" : 4, "id" : "368c6c730842d78016ad823897a372db" ,
"count" : 3, "id" : "53759a2ecddad2bb87a079a1f1519f73" ,
"count" : 3, "id" : "b0961721fd839e9982420e807758a2a6" ,
"count" : 3, "id" : "389d119b48cf3043d311335e499d9c6b" ,
"count" : 1, "id" : "dfc9d9ea4c2fbabe7abb0066097d9905" ,
"count" : 1, "id" : "3773a3773f5978591cff7b3e614989b3" ,
"count" : 1, "id" : "98e0de96ebb0711db1fc3d1bad1a902f" ,
"count" : 1, "id" : "4e1346d7b7e02c737a366b086462e33e" ,
"count" : 1, "id" : "4b5df063d69ffafb87c279672ecb4191" ,
"count" : 1, "id" : "9d1893083966b9c51109f0dc6ab0b0d9" ,
"count" : 1, "id" : "774e21c631ca26cba7b5606bdca7460f" ,
"count" : 1, "id" : "d1c427060a0f73f6b889a5c7c61f2ac4"
]
重新过一遍上面的过程
所以,这真是太棒了,让我们快速重申一下我们在这里做了什么 - 以及我们为什么这样做。
- 导入订单项目的 CSV 数据,每个项目一行导致每个订单项目一个文档
- 使用转换将订单商品分组为单个订单,能够汇总通过查询一起购买的产品
- 使用转换将已购买的产品组合在一起,这样只需检索单个文档即可
- 改造转换以获取信息,哪个产品与其他产品一起购买了多少次,将大多数购买的产品组合在一起
- 根据最终转换索引创建丰富策略,以便可以在索引时间使用一起购买的产品丰富产品

考虑 recency
Recency 是我们在这个例子中还没有考虑到的东西,以保持它很小。在这个例子中,我们使用了 order-items 索引中的所有数据来创建一个 orders 索引。我们可以使用最近 1d 的数据作为范围查询,以便只考虑最近的订单项目。此外,每个转换都支持 retention_policy 字段,允许您删除早于某个时间戳的数据。如果你还更改了用于存储文档中 ctx._timestamp 字段的两个管道,那么你就会知道文档何时太旧。
另一方面,可能有一段时间未购买的产品的用例,以保留历史数据,而不是根本不提供任何建议,以及排除订单项目的某些日期(黑色星期五或圣诞节,或者当你做那个电视广告时)如果想排除这些数据以不歪曲结果 - 我总是会包括在内。
概括
像往常一样,总结是关于深思熟虑的。第一部分不是关于技术问题,例如聚合中的低效脚本,这些问题还有改进的余地。
最大的障碍可能是数据质量和数据可信度。
第一,数据质量。您是否有足够的订单和订单项目,这样的丰富实际上是有意义的?你确定你的数据没有被十几个人订购同样的东西所歪曲吗?
第二,数据可信。这实际上是要查找的正确数据吗?你是想显示订单推荐,还是根据用户访问的内容显示推荐,而不是购买,因为你可能拥有更多此类数据,从而更早地执行此操作。
第三,这是一个经典的“赢家通吃”的推荐方法,如果你只查看过去的数据,很难让新产品得分。此外,如果你有一些总是一起购买的常见商品(例如食品店中的牛奶和面包),那么尽管它们并不适合一起购买,但这些商品的结果会完全偏向于这些常见商品。这就是重要的术语聚合可以用来代替的 - 当前转换中不支持它,需要另一个过程来创建这些建议。
这种方法的一个优点是具有闭环。当你索引集群中的所有订单项时,你基本上拥有创建这些转换的闭环 - 即使创建丰富策略仍然是一项手动任务,你需要通过 cronjob 触发它。
运行最新的订单商品数据也可以考虑退货,因此当产品经常与另一种产品组合退货时(可能两者不合适),你可以忽略这些数据。
目前的方法有一些限制。首先,不可能将转换链接起来,一个接一个地运行,这样一旦你需要触发丰富策略,你就可以确保您在最新数据上运行。其次,正如已经提到的,你需要一个 cronjob 来触发策略丰富。
还有一件事:这种方法假设产品索引经常更新,否则那些推荐不会得到更新并且对产品推荐索引的查询更有效。请记住,即使使用单个转换,我们也已经处于通过查询检索推荐的阶段。
希望这可以帮助你了解,为了扩展你自己的数据,你还可以用转换做什么。
许多常见的例子都讨论了 Web 服务器日志(和创建总结会话),但转换 - 特别是多阶段的 - 更强大,并且可能会在你不知道的数据中显示信息。
快乐 transforming!
以上是关于Elasticsearch:使用 Elasticsearch Transforms 进行产品推荐的主要内容,如果未能解决你的问题,请参考以下文章